缓存行对齐
先看一个小程序,2个线程同时对数组array的第1个,第2个元素进行修改,每个线程修改1千万次。
public class Cacheline_notPadding {
public static class T {
private volatile long x = 0L;// 占8字节
}
private static T[] array = new T[2];
static {
array[0] = new T();
array[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
array[0].x = i;// 伪共享问题+缓存一致性协议在修改数据时会消耗额外的时间
}
});
Thread thread2 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
array[1].x = i;// 伪共享问题+缓存一致性协议在修改数据时会消耗额外的时间
}
});
long startTime = System.nanoTime();
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("总计消耗时间:" + (System.nanoTime() - startTime) / 100_000);
}
}
执行该小程序,总计消耗时间为:2565。实际上,该小程序存在一个细节问题,是可以进行优化的。这个细节问题就是缓存行伪共享问题。
缓存行伪共享问题
众所周知,cpu将数据加载到缓存中的最小数据单位是行,缓存中也是以缓存行为单位进行存储的。缓存行的大小一般为32-256个字节,最常见的缓存行大小是64个字节(本文中的示例环境中的缓存行大小为64个字节)。缓存行的容量限制带来了一个问题,就是伪共享问题。如下图所示,在本文的小程序中,我们假设线程thread1,thread2分别修改的是缓存C1,C2中的array[0],array[1]。虽然线程thread1只是修改array[0],但是因为缓存行的容量是64字节,而new T()中只有一个占8字节的属性x,所以C1中的array[0]所在的缓存行在加载时也加载了array[1];C2中的array[1]所在的缓存行也是同理。但是实际上C1中的array所在的缓存行在计算时是不需要array[1]的,C2中的array所在的缓存行在计算时也不需要array[0]。这样在缓存一致性协议作用下(这里以MESI协议为例),当线程thread1修改了C1中的array[0],那么势必会通过总线通知C2作废array[1]所在的缓存行,线程thread2修改array[1]时也是如此,缓存一致性协议所带来的操作势必会带来额外的性能消耗。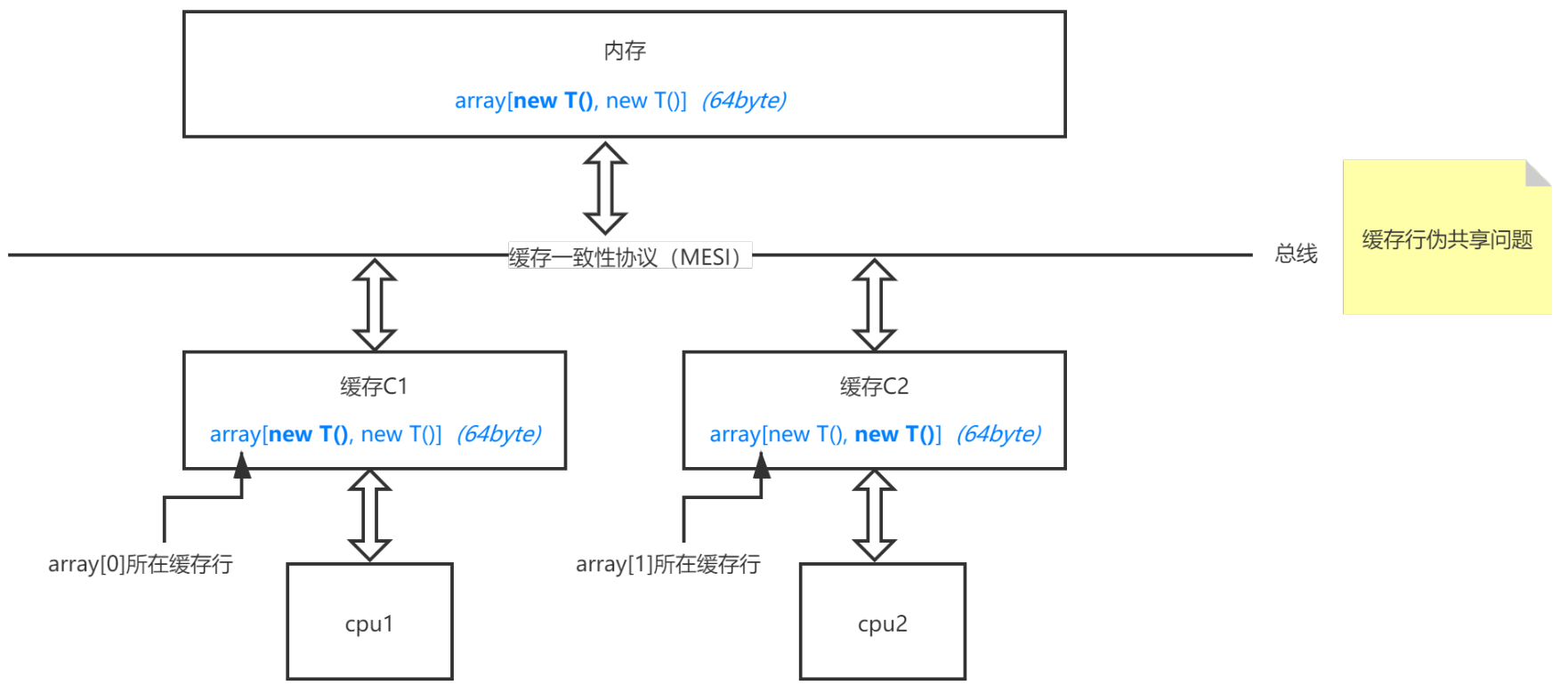
缓存行对齐
那么怎么解决由于缓存行伪共享+缓存一致性协议带来的额外的性能消耗呢?答案就是“缓存行对齐”。如下图所示,如果让缓存C1中的array[0]及C2中的array[1]各占一个缓存行,那么在计算时就互不影响了。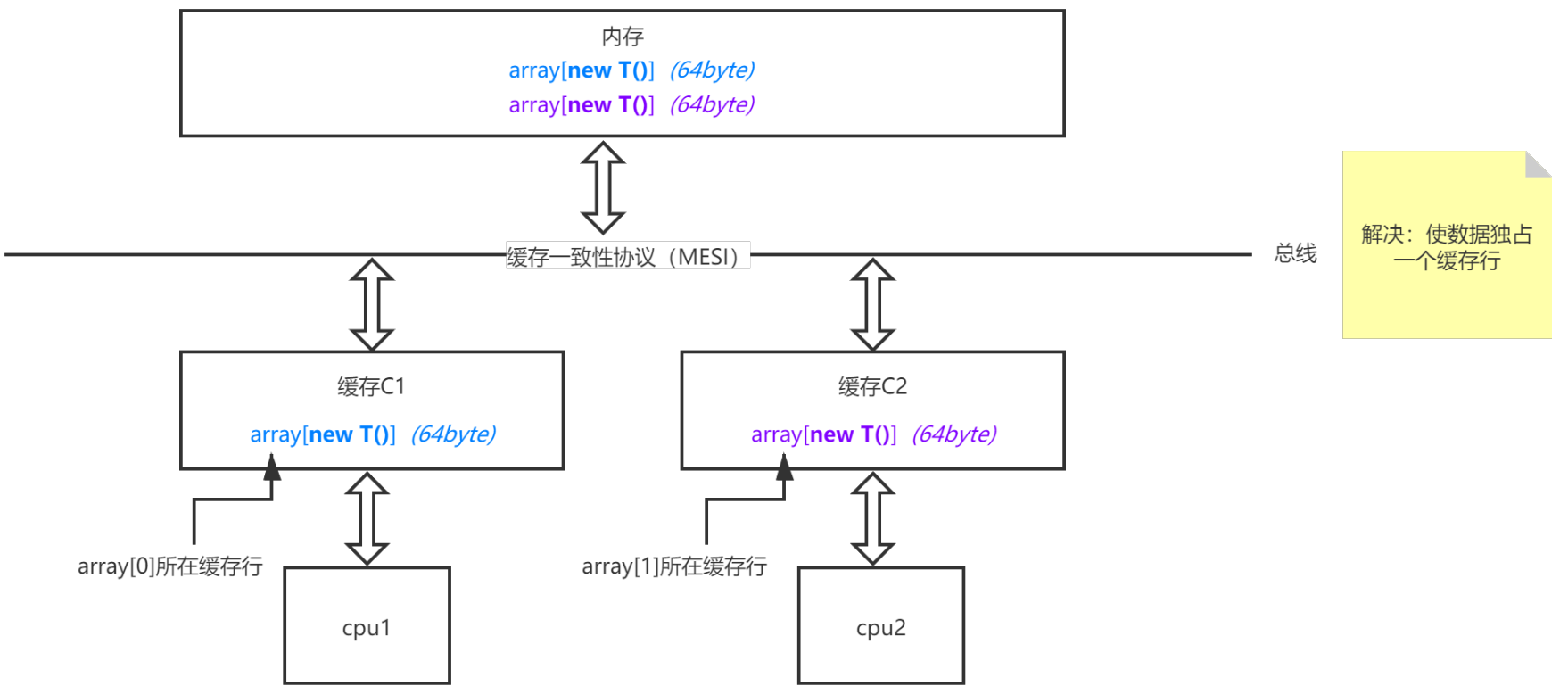
针对本文的小程序,采用缓存行对齐优化后的代码如下:
在类T中,除了成员属性x(占8个字节),再定义无任何使用意义的7个long类型的成员属性p1...p7(占56个字节),这样就会让一个T对象至少占满8+56=64个字节,这样array每个元素所在的缓存行只能容下一个T对象了,由于array中的两个元素各自独占一个缓存行,那么线程thread1和thread2在计算时就不会互相影响了。
public class Cacheline_Padding {
public static class T {
private long p1, p2, p3, p4, p5, p6, p7;// 占7*8字节 缓存行对齐
private long x = 0L;// 占8字节
}
private static T[] array = new T[2];
static {
array[0]=new T();
array[1]=new T();
}
public static void main(String[]args)throws InterruptedException{
Thread thread1=new Thread(()->{
for(long i=0;i< 1000_0000L;i++){
array[0].x=i;// array[0]独占一个缓存行
}
});
Thread thread2=new Thread(()->{
for(long i=0;i< 1000_0000L;i++){
array[1].x=i;// array[1]独占一个缓存行
}
});
long startTime=System.nanoTime();
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("总计消耗时间:"+(System.nanoTime()-startTime)/100_000);
}
}
执行程序,总计消耗时间:99
实际上,本文这样定义无实际使用意义的成员属性来达到缓存行对齐的方式在一些框架源码中是有运用的,如在JDK7的LinkedBlockingQueue源码及Disruptor框架。
缓存行对齐的其他方式
到了JDK8,对于缓存行对齐有了一种更加优雅的解决方式,那就是sun.misc.Contended注解,这个注解直接在类上定义就可以了。
@sun.misc.Contended// 缓存行对齐 每个T对象占64字节
public static class T {
private long x = 0L;
}
注意:如果此注解无效,需要在JVM启动时设置-XX:-RestrictContended。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号