
网络虚拟化
虚拟化:
http://icyfenix.cn/immutable-infrastructure/network/linux-vnet.html
vlan:
https://cloud.tencent.com/developer/article/1412795
linux网络协议栈
分层次实现每个协议。数据也是依次流入每个栈。用户态内核态的拷贝,缓存,零拷贝。数据保护,防窃取伪造。
应用层->socket(文件)->tcp/udp->ip->driver(mac帧)->device
Netfilter
PREROUTING:来自设备的数据包进入协议栈后立即触发此钩子。PREROUTING 钩子在进入 IP 路由之前触发,这意味着只要接收到的数据包,无论是否真的发往本机,都会触发此钩子。一般用于目标网络地址转换(Destination NAT,DNAT)。
INPUT:报文经过 IP 路由后,如果确定是发往本机的,将会触发此钩子,一般用于加工发往本地进程的数据包。
FORWARD:报文经过 IP 路由后,如果确定不是发往本机的,将会触发此钩子,一般用于处理转发到其他机器的数据包。
OUTPUT:从本机程序发出的数据包,在经过 IP 路由前,将会触发此钩子,一般用于加工本地进程的输出数据包。
POSTROUTING:从本机网卡出去的数据包,无论是本机的程序所发出的,还是由本机转发给其他机器的,都会触发此钩子,一般用于源网络地址转换(Source NAT,SNAT)。

iptables
iptables 的设计意图是因为 Netfilter 的钩子回调虽然很强大,但毕竟要通过程序编码才能够使用,并不适合系统管理员用来日常运维,而它的价值便是以配置去实现原本用 Netfilter 编码才能做到的事情。iptables 先把用户常用的管理意图总结成具体的行为预先准备好,然后在满足条件时自动激活行为。以下列出了部分 iptables 预置的行为:
-
DROP:直接将数据包丢弃。
-
REJECT:给客户端返回 Connection Refused 或 Destination Unreachable 报文。
-
QUEUE:将数据包放入用户空间的队列,供用户空间的程序处理。
-
RETURN:跳出当前链,该链里后续的规则不再执行。
-
ACCEPT:同意数据包通过,继续执行后续的规则。
-
JUMP:跳转到其他用户自定义的链继续执行。
-
REDIRECT:在本机做端口映射。
-
MASQUERADE:地址伪装,自动用修改源或目标的 IP 地址来做 NAT
-
LOG:在/var/log/messages 文件中记录日志信息。
-
……
iptables 进行了一层额外抽象,不是把行为与链直接挂钩,而是根据这些底层操作的目的,先总结为更高层次的规则。举个例子,假设你挂载规则目的是为了实现网络地址转换(NAT),那就应该对符合某种特征的流量(譬如来源于某个网段、从某张网卡发送出去)、在某个钩子上(譬如做 SNAT 通常在 POSTROUTING,做 DNAT 通常在 PREROUTING)进行 MASQUERADE 行为,这样具有相同目的的规则,就应该放到一起才便于管理,由此便形成“规则表”的概念。如下所列:
-
raw 表:用于去除数据包上的
-
mangle 表:用于修改数据包的报文头信息,如服务类型(Type Of Service,ToS)、生存周期(Time to Live,TTL)以及为数据包设置 Mark 标记,典型的应用是链路的服务质量管理(Quality Of Service,QoS)。
-
nat 表:用于修改数据包的源或者目的地址等信息,典型的应用是网络地址转换(Network Address Translation)。
-
filter 表:用于对数据包进行过滤,控制到达某条链上的数据包是继续放行、直接丢弃或拒绝(ACCEPT、DROP、REJECT),典型的应用是防火墙。
-
security 表:用于在数据包上应用
network namespace
ip netns命令
一个全新的network namespace会附带创建一个本地回环地址。除此之外,没有任何其他的网络设备。如果想访问本地回环地址,首先需要进入netns1这个network namespace,把设备状态设置成UP。
非root进程被分配到network namespace后只能访问和配置已经存在于该network namespace的设备。当然,root进程可以在network namespace里创建新的网络设备。除此之外,network namespace里的root进程还能把本network namespace的虚拟网络设备分配到其他network namespace——这个操作路径可以从主机的根network namespace到用户自定义network namespace,反之亦可。
有两种途径索引network namespace:名字(例如netns1)或者属于该namespace的进程PID
每个Linux进程都拥有一个属于自己的/proc/PID/ns,这个目录下的每个文件都代表一个类型的namespace。
Linux内核提供的黑科技允许:只要打开文件描述符,不需要进程存在也能保持namespace存在
进程可以通过Linux系统调用clone()、unshare()和setns进入network namespace。
clone:只要在clone()设置了其中一个标志位CLONE_NEW,系统就会创建一个新的对应类型的namespace及一个新的进程,并且会把这个进程放到这个新创建的namespace中
setns:把一个进程加入一个已经存在的namespace中
ushare:用于帮助进程“逃离”namespace。unshare()系统调用的工作机制是:先通过指定的flags(即CLONE_NEW*bit位的组合)创建相应的namespace,再把这个进程挪到这些新创建的namespace中,于是也就完成了进程从原先namespace的撤离。unshare()提供的功能其实很像clone(),区别在于unshare()作用在一个已存在的进程上,而clone()会创建一个新的进程。
虚拟网卡tun/tap
https://en.wikipedia.org/wiki/TUN/TAP
https://cloud.tencent.com/developer/article/2063424
Tun/tap 驱动程序中包含两个部分,一部分是字符设备驱动,还有一部分是网卡驱动部分。利用网卡驱动部分接收来自TCP/IP协议栈的网络分包并发送或者反过来将接 收到的网络分包传给协议栈处理,而字符驱动部分则将网络分包在内核与用户态之间传送,模拟物理链路的数据接收和发送。
struct tun_struct {
char name[8]; //设备名
unsigned long flags; //区分tun和tap设备
struct fasync_struct *fasync; //文件异步通知结构
wait_queue_head_t read_wait; //等待队列
struct net_device dev; //linux 抽象网络设备结构
struct sk_buff_head txq; //网络缓冲区队列
struct net_device_stats stats; //网卡状态信息结构
};
struct net_device结构是linux内核提供的统一网络设备结构,定义了系统统一的访问接口。

创建点对点隧道

绕过防火墙
结合路由规则和IPTables规则,可以将VPN服务器端的主机作为连接外部网络的网关,以绕过防火墙对客户端的一些外部网络访问限制。

桥接站点

假设192.168.0.5发出了一个对192.168.0.3的ARP请求,该ARP请求在网络中经过的路径如下:
-
192.168.0.5发出ARP请求,询问192.168.0.3的MAC地址。
-
该ARP请求将被发送到以太网交换机上。
-
以太网交换机对该请求进行泛洪,发送到其包括Eth1在内的所有端口上。
-
由于Eth1被加入了V**主机上的Linux Bridge,因此Linux Bridge收到该ARP请求。
-
Linux Bridge对该ARP请求进行泛洪,发送到连到其上面的Tap虚拟网卡上。
-
Vpn程序通过/dev/net/tun字符设备读取到该ARP请求,然后封装到TCP/UDP包中,发送到对端站点的Vpn主机。
-
对端站点的V**程序通过监听TCP/UDP端口接收到封装的ARP请求,将ARP请求通过/dev/net/tun字符设备写入到Tap设备中。
-
Linux Bridge泛洪,将ARP请求发送往Eth1,由于Eth1连接到了以太网交换机上,以太网交换机接收到了该ARP请求。
-
以太网交换机进行泛洪,将ARP请求发送给了包括192.168.0.3的所有主机。
-
192.168.0.3收到了APR请求,判断iP地址和自己相同,对此请求进行响应。
-
同理,ARP响应包也可以按照该路径返回到图左边包括192.168.0.5在内的站点中。
从站点主机的角度来看,上面图中两个VPN主机之间的远程连接可以看作一条虚拟的网线,这条网线将两个Linux Bridge连接起来。这两个Linux Bridge和两个以太网交换机一起将左右两个站点的主机连接在一起,形成了一个局域网。

在linux下,要实现核心态和用户态数据的 交互,有多种方式:
1、可以通用socket创建特殊套接字,利用套接字实现数据交互;
2、通过proc文件系统创建文件来进行数据交互
3、还可以使用设备文件的方 式,访问设备文件会调用设备驱动相应的例程,设备驱动本身就是核心态和用户态的一个接口
veth pair
https://www.cnblogs.com/bakari/p/10613710.html
The VETH (virtual Ethernet) device is a local Ethernet tunnel. Devices are created in pairs, as shown in the diagram below.
Packets transmitted on one device in the pair are immediately received on the other device. When either device is down, the link state of the pair is down.
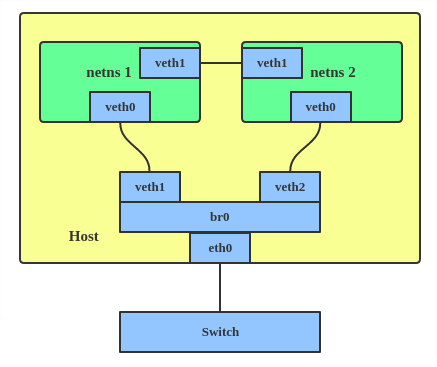
# ip netns add net1
# ip netns add net2
# ip link add veth1 netns net1 type veth peer name veth2 netns net2
linux bridge
A Linux bridge behaves like a network switch. It forwards packets between interfaces that are connected to it. It's usually used for forwarding packets on routers, on gateways, or between VMs and network namespaces on a host. It also supports STP, VLAN filter, and multicast snooping.
表现的跟switch一样了。
当有二层数据包(以太帧)从网卡进入 Linux Bridge,它将根据数据包的类型和目标 MAC 地址,按如下规则转发处理:
-
如果数据包是广播帧,转发给所有接入网桥的设备。
-
如果数据包是单播帧:
-
且 MAC 地址在地址转发表中不存在,则
-
且 MAC 地址在地址转发表中已存在,则直接转发到地址表中指定的设备。
-
-
如果数据包是此前转发过的,又重新发回到此 Bridge,说明冗余链路产生了环路。由于以太帧不像 IP 报文那样有 TTL 来约束,因此一旦出现环路,如果没有额外措施来处理的话就会永不停歇地转发下去。对于这种数据包就需要交换机实现
对于通过brctl命令显式接入网桥的设备,Linux Bridge 与物理交换机的转发行为是完全一致的,也不允许给接入的设备设置 IP 地址,因为网桥是根据 MAC 地址做二层转发的,就算设置了三层的 IP 地址也毫无意义
Linux Bridge 有一个与自己名字相同的隐藏端口,隐式地连接了创建它的那台 Linux 主机。因此,Linux Bridge 允许给自己设置 IP 地址,比普通交换机多出一种特殊的转发情况:
-
如果数据包的目的 MAC 地址为网桥本身,并且网桥有设置了 IP 地址的话,那该数据包即被认为是收到发往创建网桥那台主机的数据包,此数据包将不会转发到任何设备,而是直接交给上层(三层)协议栈去处理。
设置这条特殊转发规则的好处是:只要通过简单的 NAT 转换,就可以实现一个最原始的单 IP 容器网络
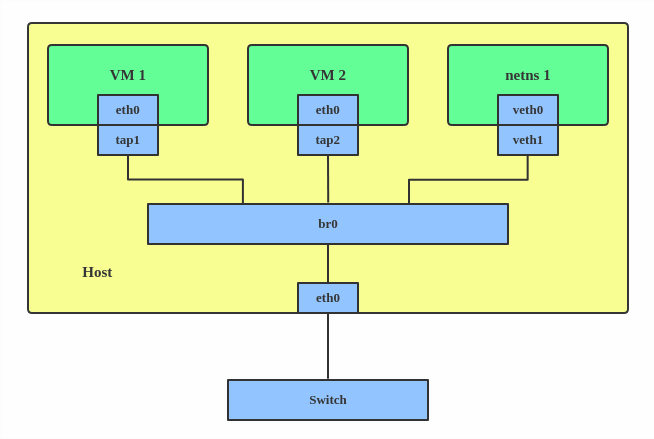
# ip link add br0 type bridge
# ip link set eth0 master br0
# ip link set tap1 master br0
# ip link set tap2 master br0
# ip link set veth1 master br0
ipip
Linux原生支持下列5种L3隧道:
ipip:即IPv4 in IPv4,在IPv4报文的基础上封装一个IPv4报文;
GRE:即通用路由封装(Generic Routing Encapsulation),定义了在任意一种网络层协议上封装其他任意一种网络层协议的机制,适用于IPv4和IPv6;
sit:和ipip类似,不同的是sit用IPv4报文封装IPv6报文,即IPv6 over IPv4;
ISATAP:即站内自动隧道寻址协议(Intra-Site Automatic Tunnel Addressing Protocol),与sit类似,也用于IPv6的隧道封装;
VTI:即虚拟隧道接口(Virtual Tunnel Interface),是思科提出的一种IPSec隧道技术。下面我们以ipip为例,介绍Linux隧道通信的基本原理。
Linux L3隧道底层实现原理都基于tun设备
vxlan
https://support.huawei.com/enterprise/zh/doc/EDOC1100087027
https://zhuanlan.zhihu.com/p/130277008
大二层
vlan id
多租网隔离
VLAN 有两个明显的缺陷, VLAN Tag 的设计,跨数据中心传递。由于云计算的发展普及,大型分布式系统已不局限于单个数据中心,完全有跨数据中心运作的可能性,此时如何让 VLAN Tag 在两个数据中心间传递又成了不得不考虑的麻烦事。
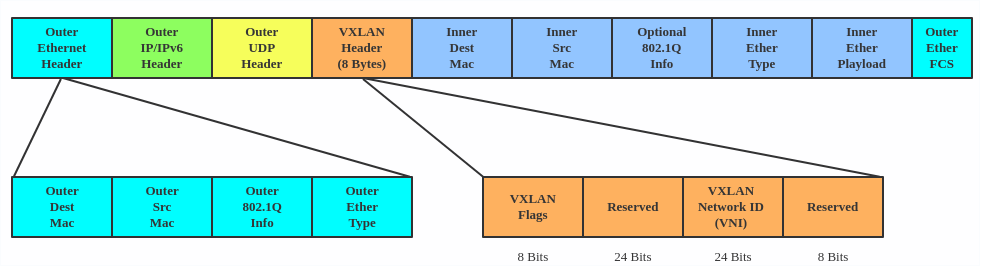
VXLAN 采用 L2 over L4 (MAC in UDP)的报文封装模式,把原本在二层传输的以太帧放到四层 UDP 协议的报文体内,同时加入了自己定义的 VXLAN Header。在 VXLAN Header 里直接就有 24 Bits 的 VLAN ID,同样可以存储 1677 万个不同的取值,VXLAN 让二层网络得以在三层范围内进行扩展,不再受数据中心间传输的限制。
VXLAN报文的转发过程就是:原始报文经过VTEP,被Linux内核添加上VXLAN包头及外层的UDP头部,再发送出去,对端VTEP接收到VXLAN报文后拆除外层UDP头部,并根据VXLAN头部的VNI把原始报文发送到目的服务器。
第一次通信之前有以下问题待解决:·哪些VTEP需要加到一个相同的VNI组?·发送方如何知道对方的MAC地址?·如何知道目的服务器在哪个节点上?
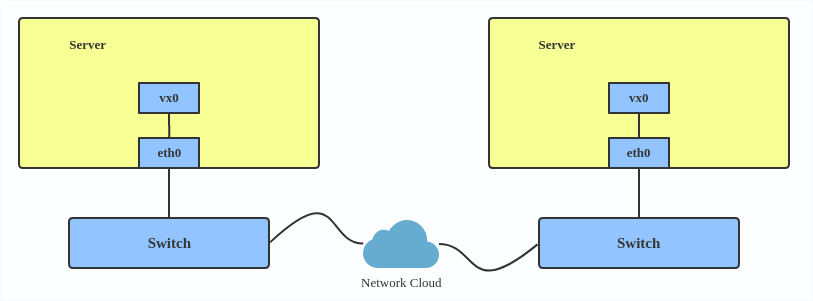
# ip link add vx0 type vxlan id 100 local 1.1.1.1 remote 2.2.2.2 dev eth0 dstport 4789
id vni id 1-2^24
dstport vtep通信端口4789,默认8472
remote 2.2.2.2 对端vtep地址
local 当前vtep使用的ip
dev eth0 用于vtep通信的网卡设备,这个和local 相同,二选一。
这样vx0网卡配置成功,接下来就可以配置ip并up。执行成功后,会增加路由表和转发表
多播,增加一个group参数
macvlan
Macvlan接口可以看作是物理以太网接口的虚拟子接口。Macvlan允许用户在主机的一个网络接口上配置多个虚拟的网络接口,每个Macvlan接口都有自己的区别于父接口的MAC地址,并且可以像普通网络接口一样分配IP地址。因此,使用Macvlan技术带来的效果是一块物理网卡上可以绑定多个IP地址,每个IP地址都有自己的MAC地址。用Macvlan虚拟出来的虚拟网卡,在逻辑上和物理网卡是对等的,应用程序可以像使用物理网卡的IP地址那样使用Macvlan设备的IP地址。
Macvlan的主要用途是网络虚拟化(包括容器和虚拟机)。另外,有一些比较特殊的场景,例如,keepalived使用虚拟MAC地址。需要注意的是,使用Macvlan的虚拟机或者容器网络与主机在同一个网段,即同一个广播域中。Macvlan支持5种模式,分别是bridge、VEPA、Private、Passthru和Source模式。
Macvlan是将虚拟机或容器通过二层连接到物理网络的一个不错的方案,但它也有一些局限性,例如:·因为每个虚拟网卡都要有自己的MAC地址,所以Macvlan需要大量的MAC地址,而Linux主机连接的交换机可能会限制一个物理端口的MAC地址数量上限,而且许多物理网卡的MAC地址数量也有限制,超过这个限制就会影响到系统的性能;·IEEE 802.11标准(即无线网络)不喜欢同一个客户端上有多个MAC地址,这意味着你的Macvlan子接口没法在无线网卡上通信。
ipvlan
https://www.cnblogs.com/lovezbs/p/14609276.html
IPvlan所有的虚拟接口都有相同的MAC地址,而IP地址却各不相同。因为所有的IPvlan虚拟接口共享MAC地址,所以特别需要注意DHCP使用的场景。DHCP分配IP地址的时候一般会用MAC地址作为机器的标识。因此,在使用Macvlan的情况下,客户端动态获取IP的时候需要配置唯一的Client ID,并且DHCP服务器也要使用该字段作为机器标识,而不是使用MAC地址。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)