
数据采集与融合技术作业四
数据采集与融合技术作业四
作业1:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
代码和结果
数据存储:
def store_data(self, data):
sql = """
INSERT INTO stockinfo (bStockNo, bStockName, bLastPrice, bPriceChange, bPriceChangeAmount, bVolume, bTurnover, bAmplitude, bHigh, bLow, bOpen, bPrevClose)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
try:
self.cursor.execute(sql, data)
self.db.commit()
except mysql.connector.Error as err:
print("Error inserting data into MySQL:", err)
数据抓取与处理:
def processspider(self):
self.connect_to_database()
trs = WebDriverWait(self.driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, "//table[@id='table_wrapper-table']/tbody/tr"))
)
for tr in trs:
# Extract data from each row
data = (
tr.find_element(By.XPATH, "./td[position()=2]/a").text,
tr.find_element(By.XPATH, "./td[position()=3]/a").text,
tr.find_element(By.XPATH, "./td[position()=5]/span").text,
tr.find_element(By.XPATH, "./td[position()=6]/span").text,
tr.find_element(By.XPATH, "./td[position()=7]/span").text,
tr.find_element(By.XPATH, "./td[position()=8]").text,
tr.find_element(By.XPATH, "./td[position()=9]").text,
tr.find_element(By.XPATH, "./td[position()=10]").text,
tr.find_element(By.XPATH, "./td[position()=11]/span").text,
tr.find_element(By.XPATH, "./td[position()=12]/span").text,
tr.find_element(By.XPATH, "./td[position()=13]/span").text,
tr.find_element(By.XPATH, "./td[position()=14]").text
)
self.store_data(data)
运行结果:
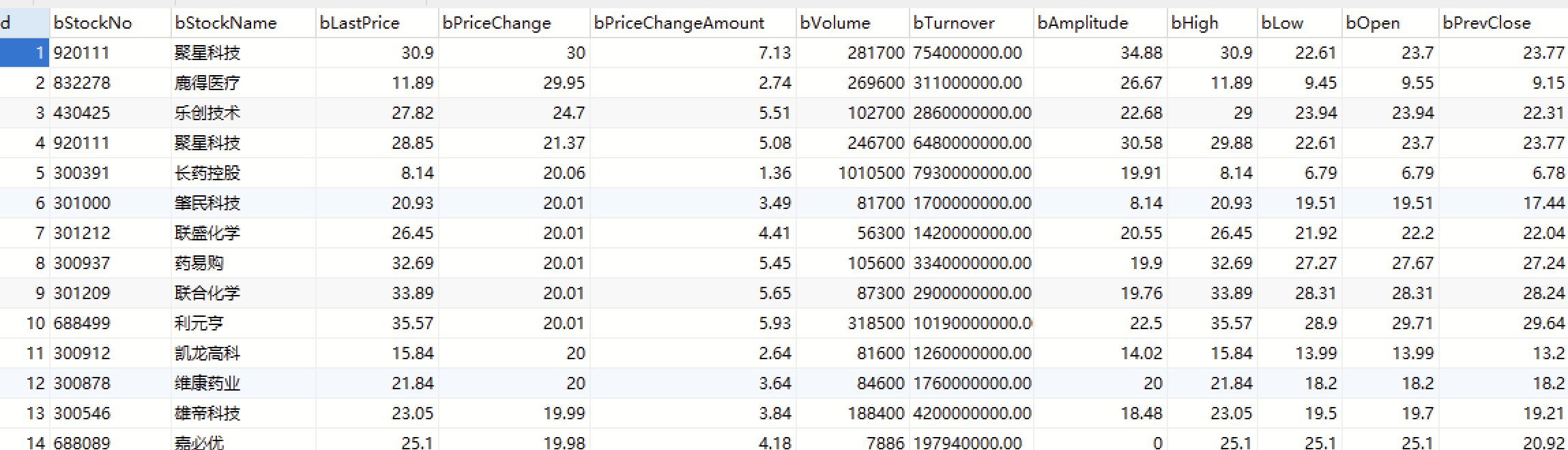
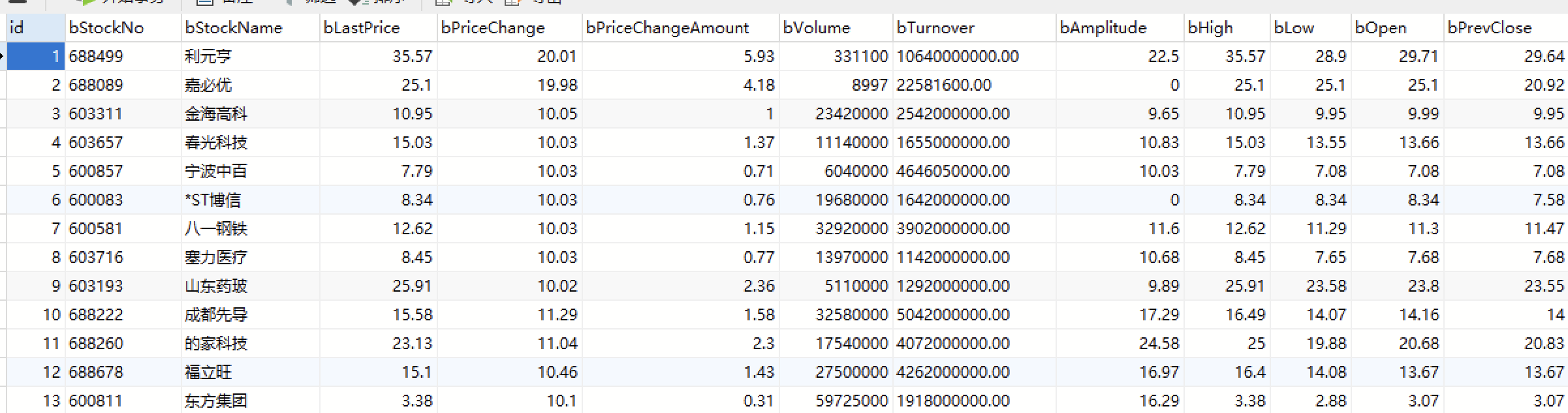
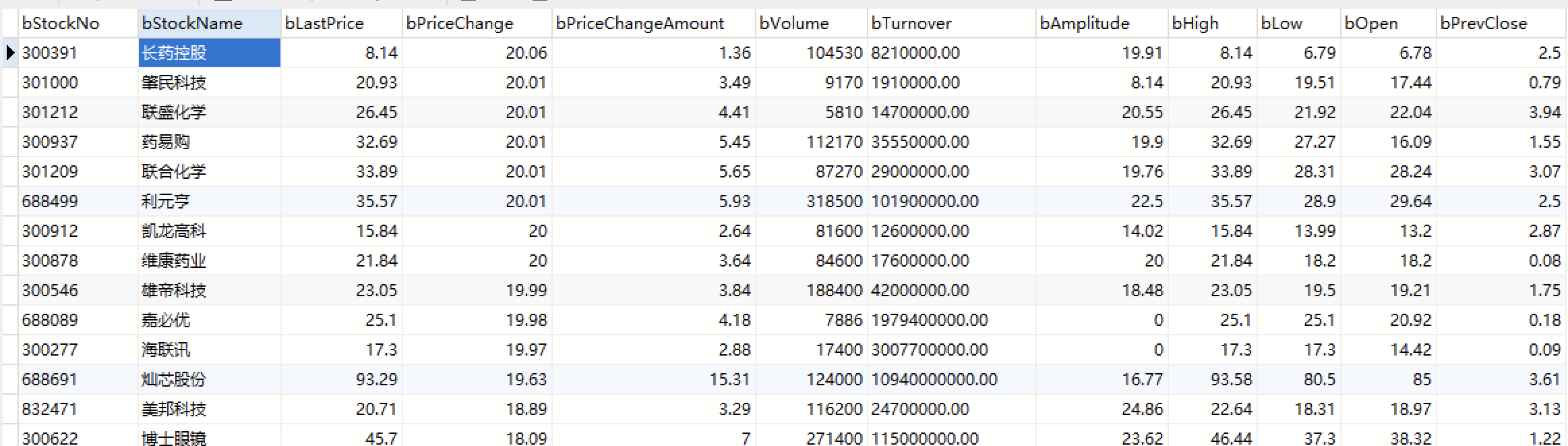
心得体会:
加深了我对XPath的理解,能够更灵活地运用它,无论是在Selenium还是其他框架中。通过将抓取到的数据存储到数据库,我对数据库的操作也更加熟练了。从连接数据库、执行SQL语句到数据的增删改查
作业2
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
代码和结果
访问中国MOOC网站,模拟用户登录和点击“我的课程”按钮
def scrape_mooc_data(self):
# 访问中国MOOC网站
url = "https://www.icourse163.org"
self.browser.get(url)
time.sleep(1) # 等待网页加载
# 等待并点击登录按钮
wait = WebDriverWait(self.browser, 10)
button1 = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div'))) # 登录按钮
button1.click()
time.sleep(5) # 等待扫码登录
# 等待并点击我的课程按钮
button2 = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[4]/div'))) # 我的课程按钮
button2.click()
抓取数据方法
# 获取数据
data = []
courses = self.browser.find_elements(By.XPATH, '//*[@id="j-coursewrap"]/div/div[1]/div')
for i in range(len(courses)):
course = courses[i].find_element(By.XPATH, './/div[1]/a/div[2]/div[1]/div[1]/div/span[2]').text
college = courses[i].find_element(By.XPATH, './/div[1]/a/div[2]/div[1]/div[2]/a').text
teacher = courses[i].find_element(By.XPATH, './/div[1]/a/div[2]/div[1]/div[3]/a').text # 假设教师信息在这个地方
team = courses[i].find_element(By.XPATH, './/div[1]/a/div[2]/div[1]/div[4]/a').text # 假设团队成员信息在这个地方
count = courses[i].find_element(By.XPATH, './/div[1]/a/div[2]/div[2]/div[1]/div[1]/div[1]/a/span').text
process = courses[i].find_element(By.XPATH, './/div[1]/a/div[2]/div[2]/div[2]').text
brief = courses[i].find_element(By.XPATH, './/div[1]/a/div[2]/div[3]').text
data.append([course, college, teacher, team, count, process, brief])
# 插入数据到数据库
self.insert_database(data)
# 关闭浏览器
self.browser.quit()
运行结果:

心得体会:
使用Selenium可以轻松实现浏览器的自动化操作,如页面导航、元素点击等,大大简化了网页数据抓取的过程。在数据库操作中,异常处理非常重要。通过捕获并处理异常,可以确保程序在遇到错误时不会崩溃,同时也能提供有用的错误信息。
作业3:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务


实时分析开发实战:
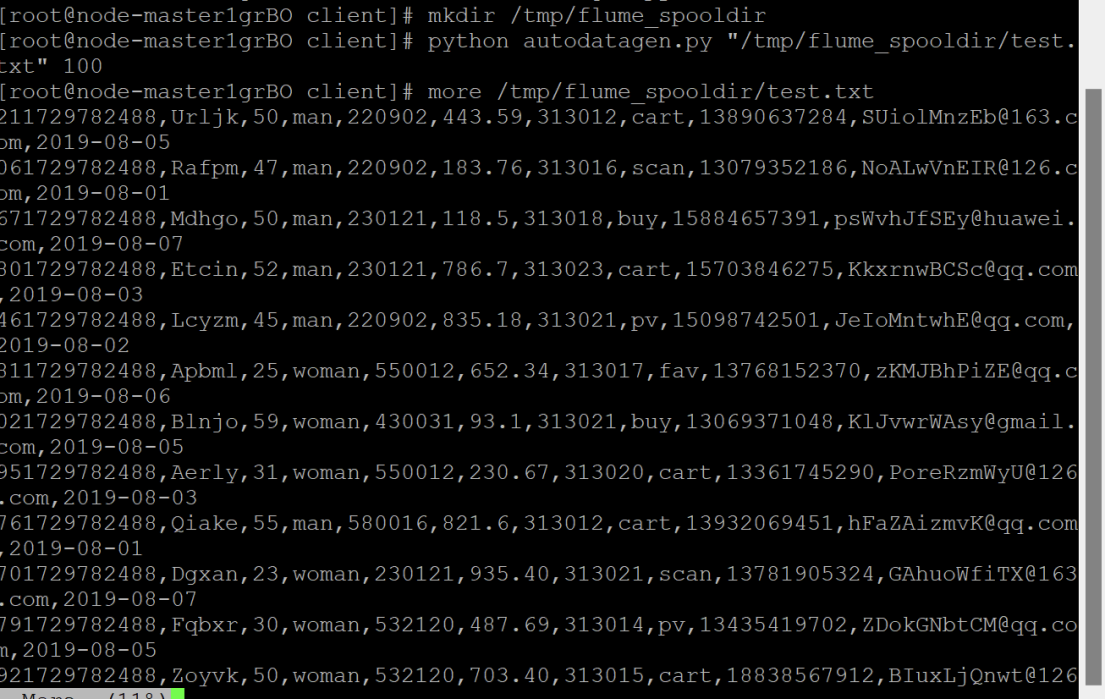
任务一:Python脚本生成测试数据
任务二:配置Kafka

任务三: 安装Flume客户端
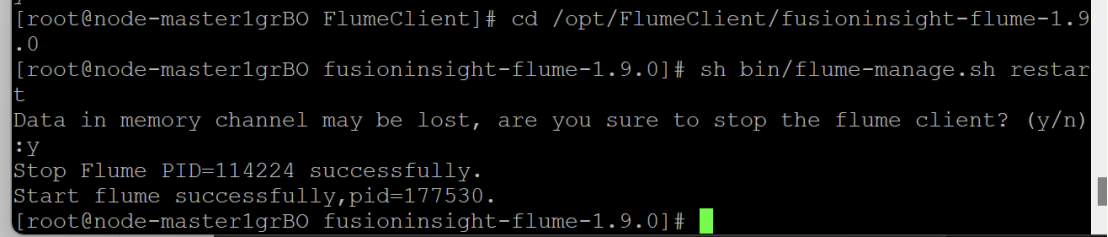
任务四:配置Flume采集数据
心得体会:
在配置Kafka时,由于对Kafka的配置参数不够熟悉,我花费了大量时间来调试和优化,通过使用Xshell进行远程连接和操作,我提高了自己的动手能力和问题解决能力。在实验中,我学会了如何快速定位问题并寻找解决方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号