
数据采集与融合术作业三
数据采集与融合技术作业三
作业1:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
代码和结果
class ChinaWeatherSpider(scrapy.Spider):
name = 'china_weather'
allowed_domains = ['www.weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
# 根据网站结构提取图片URL
for img_url in response.css('img::attr(src)').getall():
yield WeatherImageItem(image_urls=[img_url])
# 控制爬取页数和图片数量
page = 1
student_id_suffix = 102202107
max_pages = int(student_id_suffix[-2:])
max_images = int(student_id_suffix[-3:])
count = 0
while page <= max_pages and count < max_images:
# 构造下一页URL并爬取
next_page = response.urljoin('/changepage.shtml?pg={}'.format(page))
yield response.follow(next_page, self.parse, meta={'page': page + 1, 'count': count})
page += 1
count += len(response.css('img::attr(src)').getall())
运行结果:
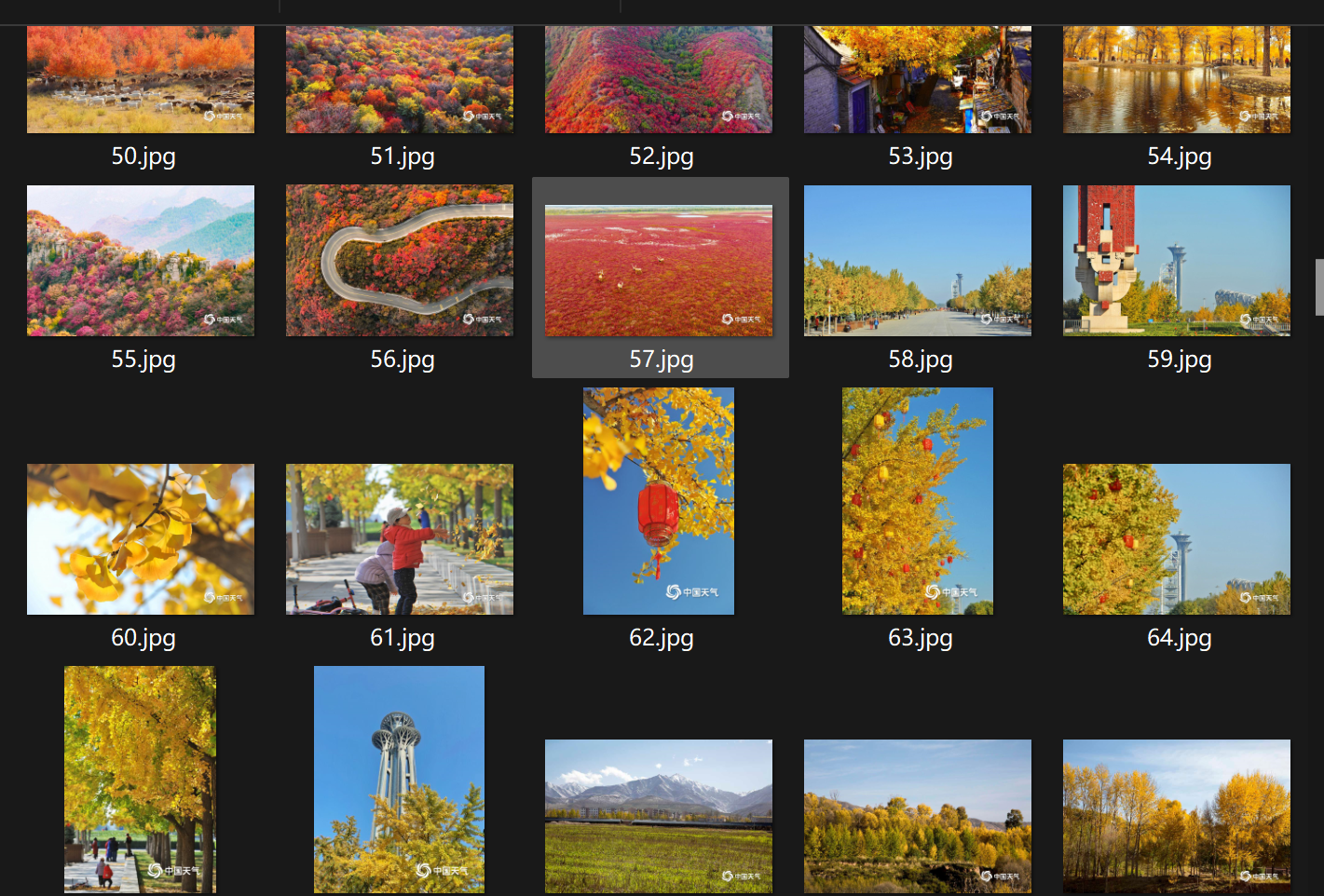
心得体会:
学习使用Scrapy框架进行网站图片爬取,让我对Python编程和网络爬虫有了更深入的理解。通过实践单线程和多线程爬取,我掌握了如何控制爬取速度和数量,以遵守网站的使用协议,保护网站资源。这个过程不仅锻炼了我的编程技能,还增强了我对网络伦理的认识。
作业2
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
代码和结果
stock_spider.py
self.page_num = response.meta.get('page_num', 1)
if self.page_num < 3:
self.page_num += 1
next_page = f"https://69.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404359196896638151_1697701391202&pn={self.page_num}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697701391203"
yield scrapy.Request(url=next_page, callback=self.parse, meta={'page_num': self.page_num})
items.py
import scrapy
class StockItem(scrapy.Item):
code = scrapy.Field()
name = scrapy.Field()
latest_price = scrapy.Field()
change_degree = scrapy.Field()
change_amount = scrapy.Field()
count = scrapy.Field()
money = scrapy.Field()
zfcount = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
运行结果:
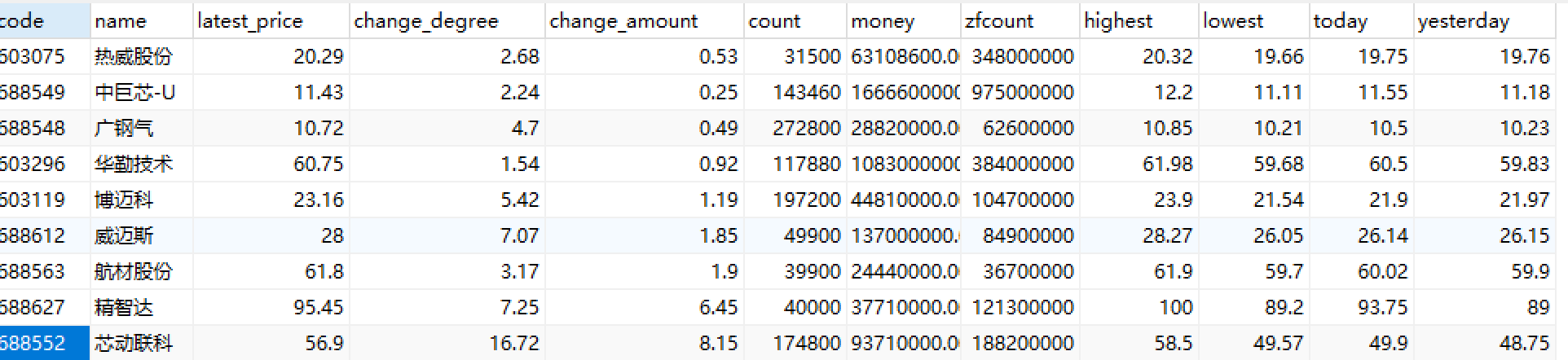
作业链接
心得体会:
做这次作业由于过度请求,短时间爬取太多次,违反了robot.txt的规定让我认识到爬虫时应该小心注意不要违反规定
作业3:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
代码和结果
boc_spider.py
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 使用XPath提取数据
for row in response.xpath('//table/tr'):
item = ForexItem()
item['currency'] = row.xpath('./td[1]/text()').get()
item['tbp'] = row.xpath('./td[2]/text()').get()
item['cbp'] = row.xpath('./td[3]/text()').get()
item['tsp'] = row.xpath('./td[4]/text()').get()
item['csp'] = row.xpath('./td[5]/text()').get()
item['time'] = row.xpath('./td[6]/text()').get()
yield item
items.py
import scrapy
class ForexItem(scrapy.Item):
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
tsp = scrapy.Field()
time = scrapy.Field()
运行结果
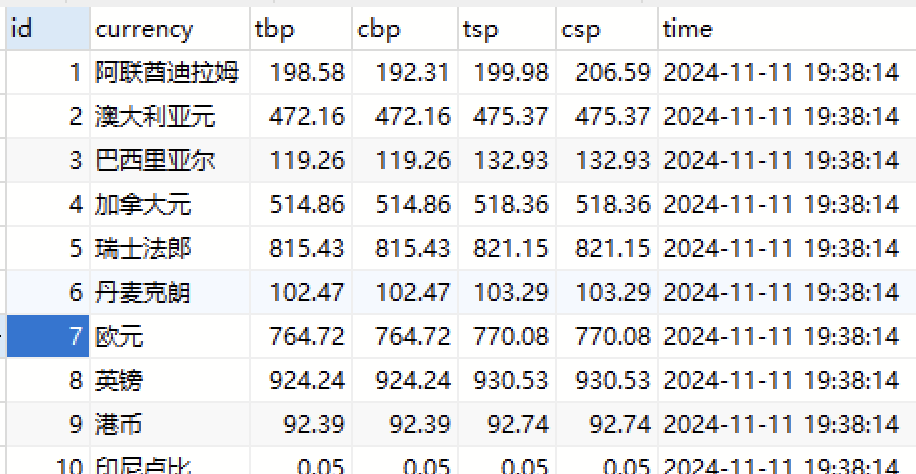
心得体会:
我学会了如何使用XPath来精确提取外汇网站的数据,并将这些数据通过Pipeline存储到MySQL数据库中。
作业链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号