txNLP 262-282

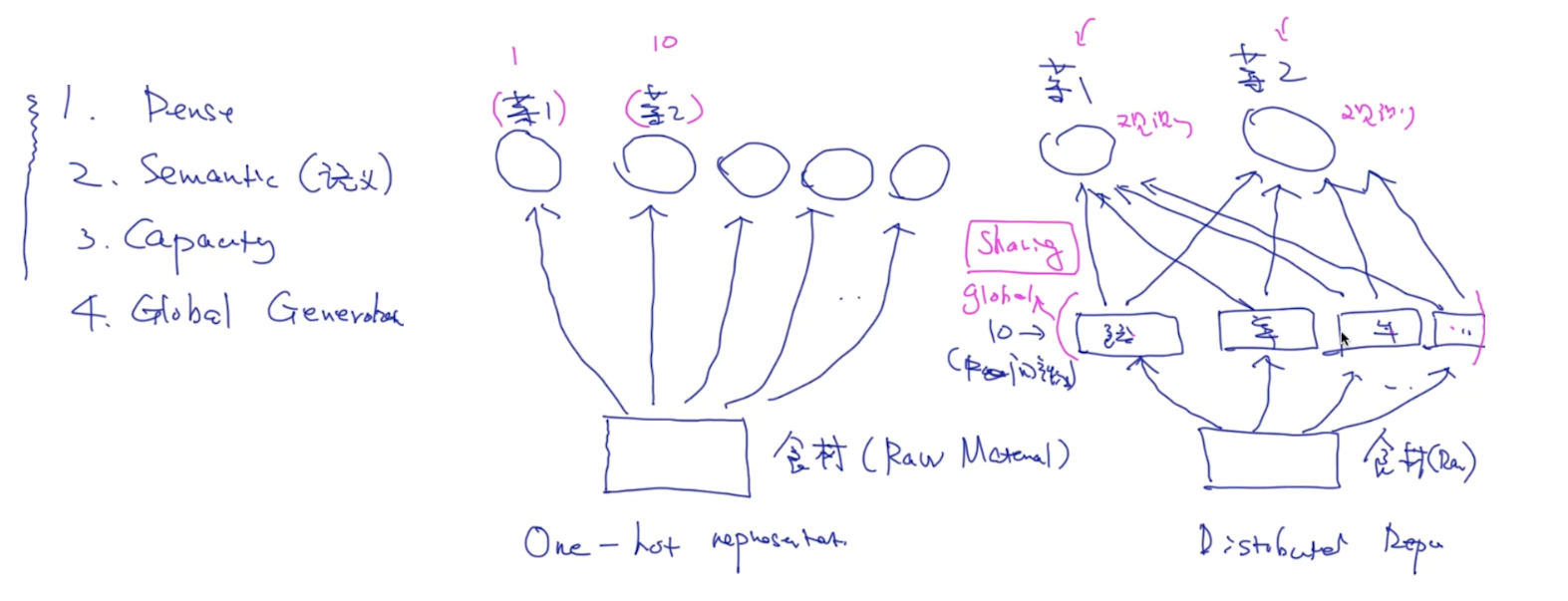
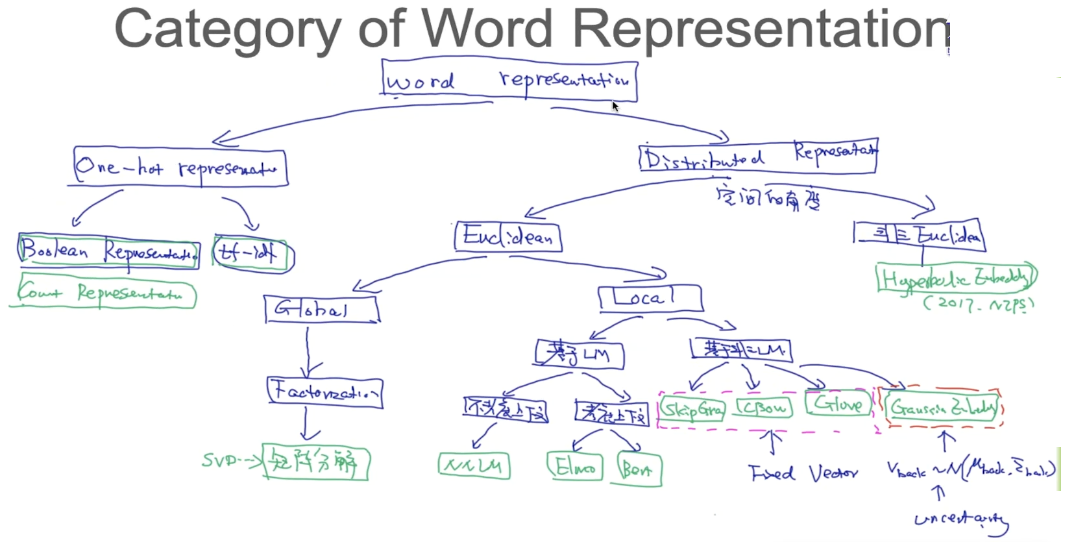
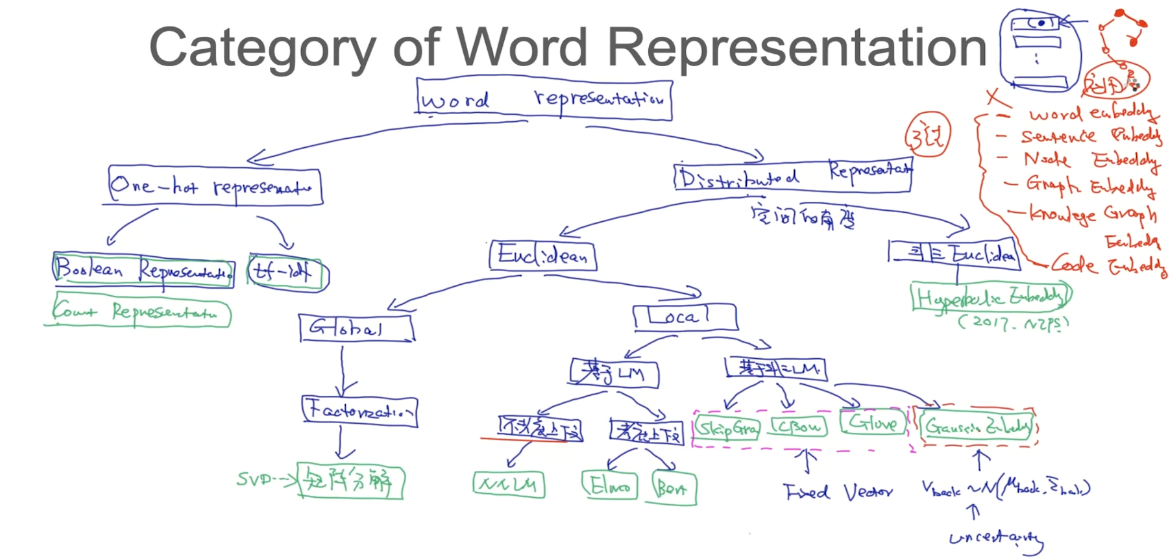
one-hot中只有一个非零向量,相对集中。而对于分布式表示,向量中有大量的非零向量,相对分散,把词的信息分布到各个向量中去了。这一点跟并行计算里的分布式并行相像。
Global Generation of Distributed Representation

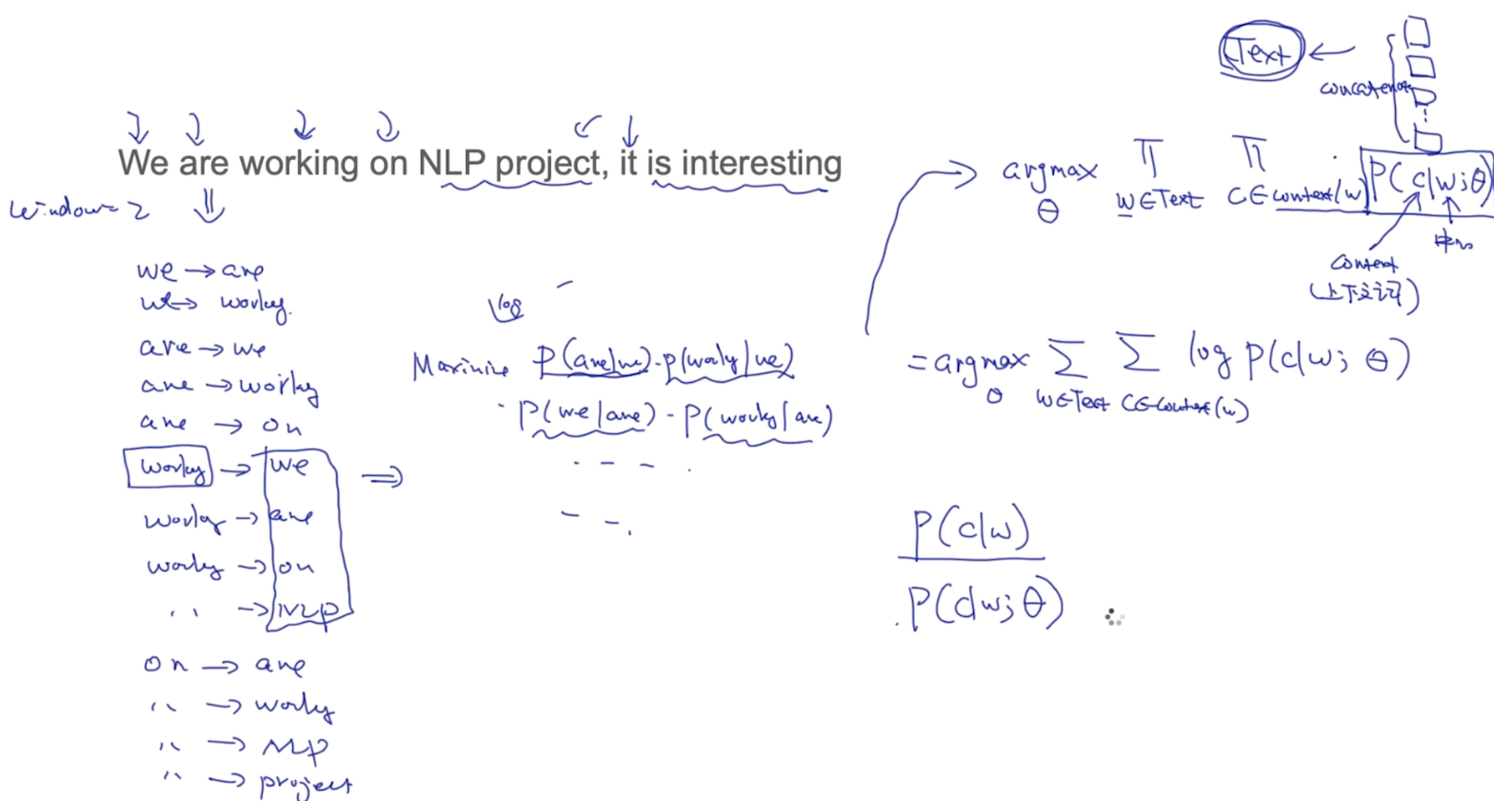

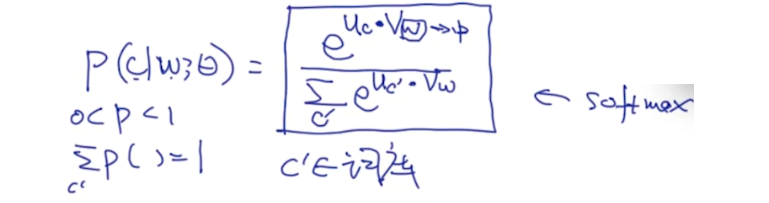
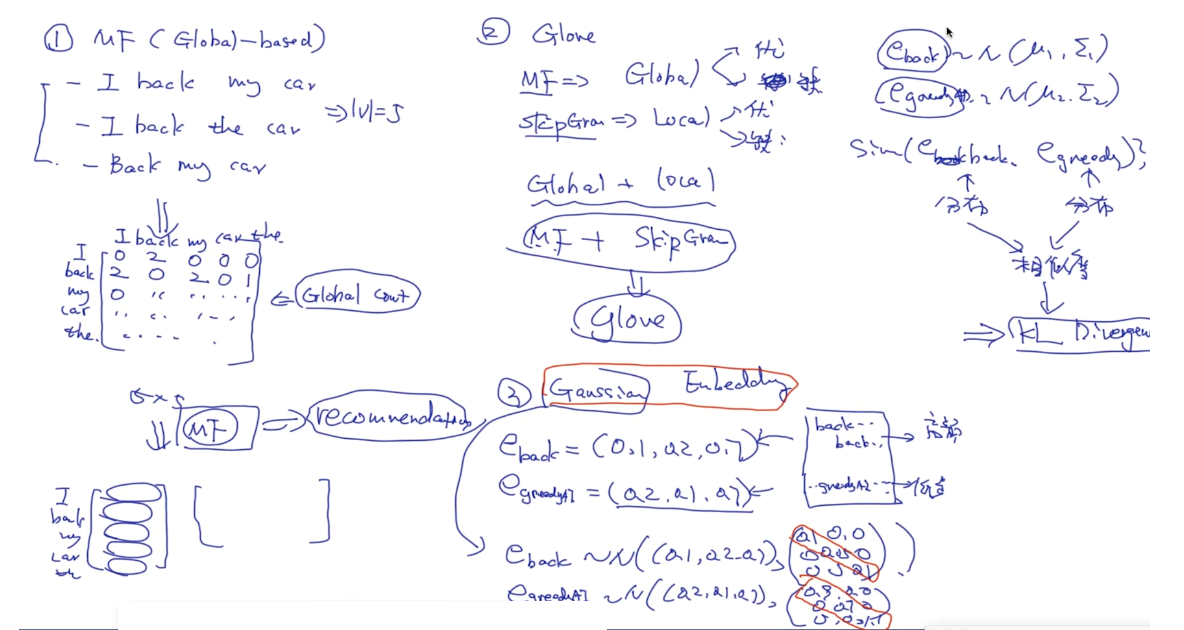
在cs224n中Richard Socher说他们实验后发现是U+V的效果比较好

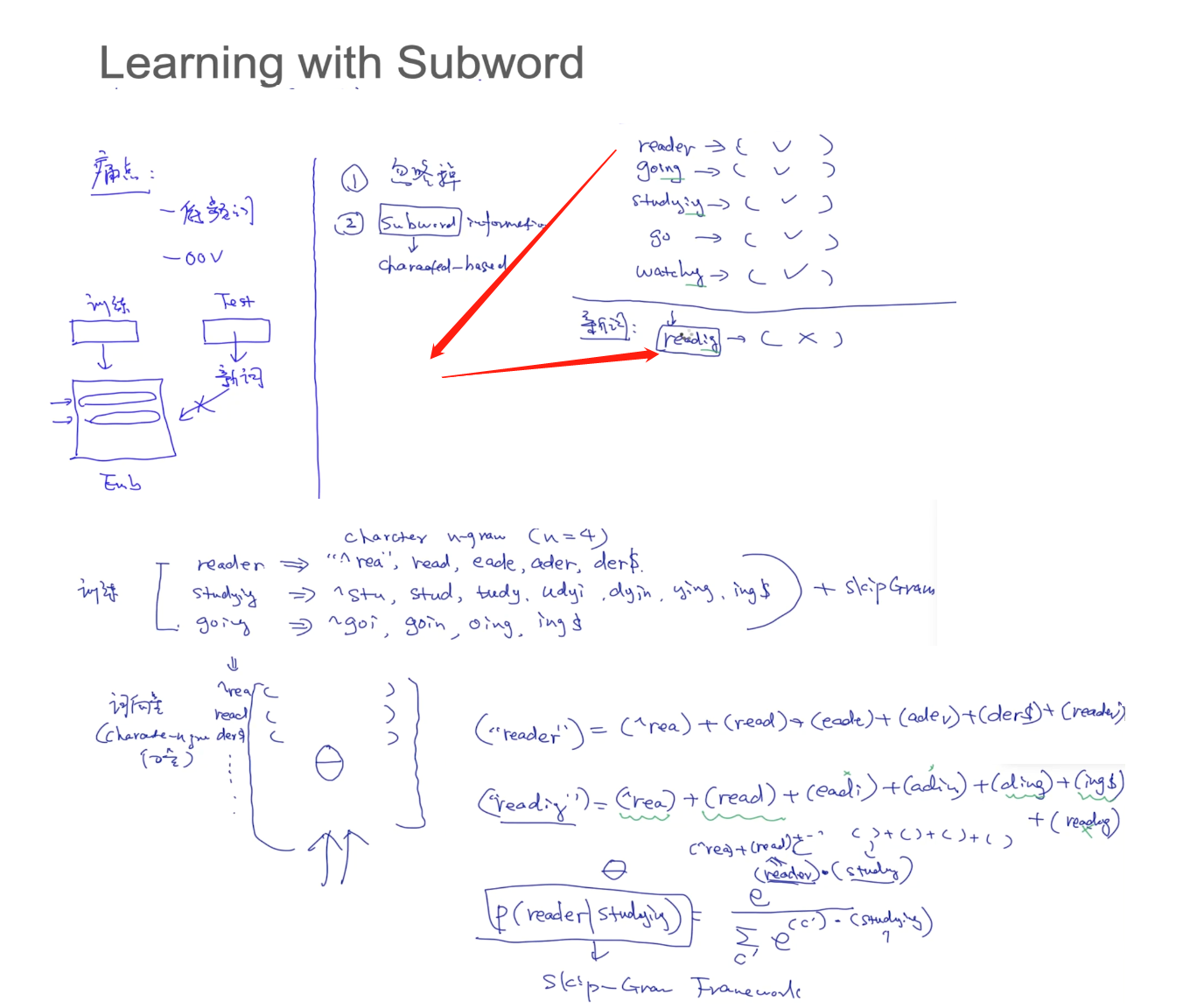
D=1以上下文方式出现在语料库中,D=0没有以上下文方式出现在语料库中。

负样本过大,需要抽样。







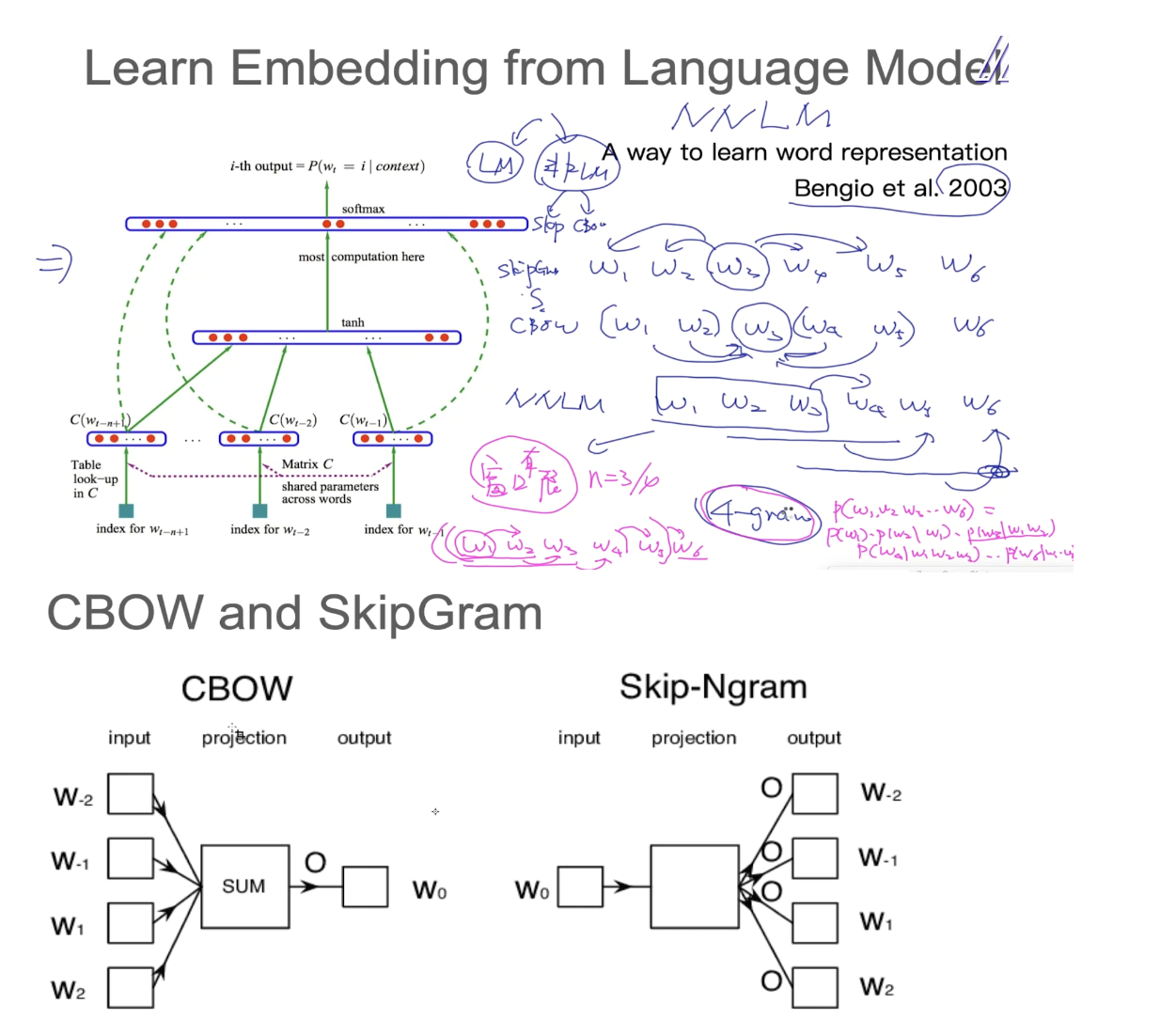
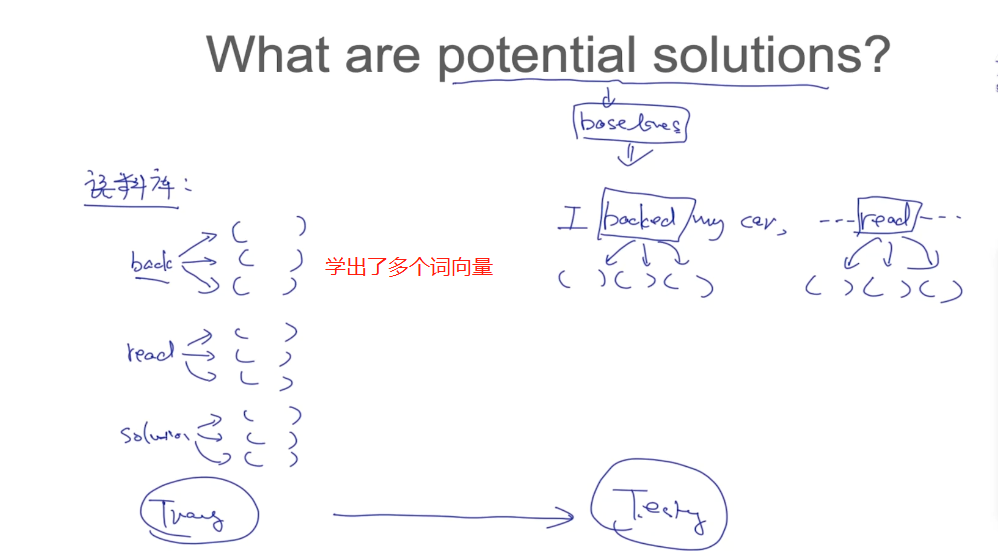
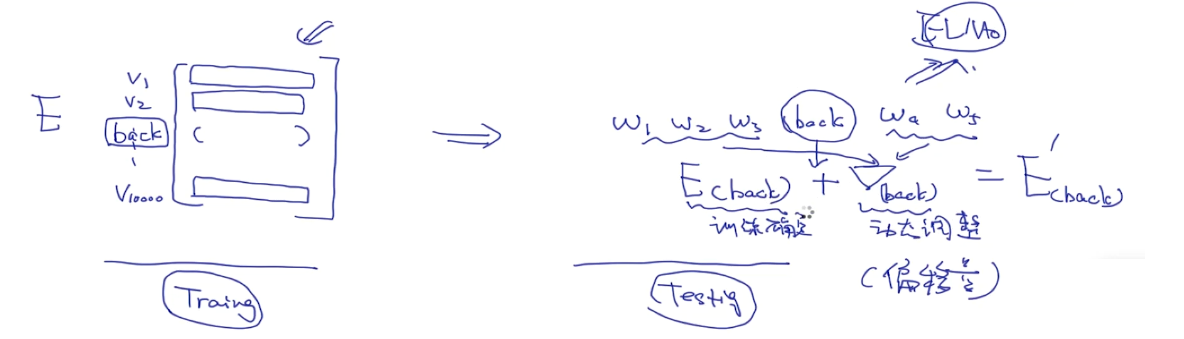
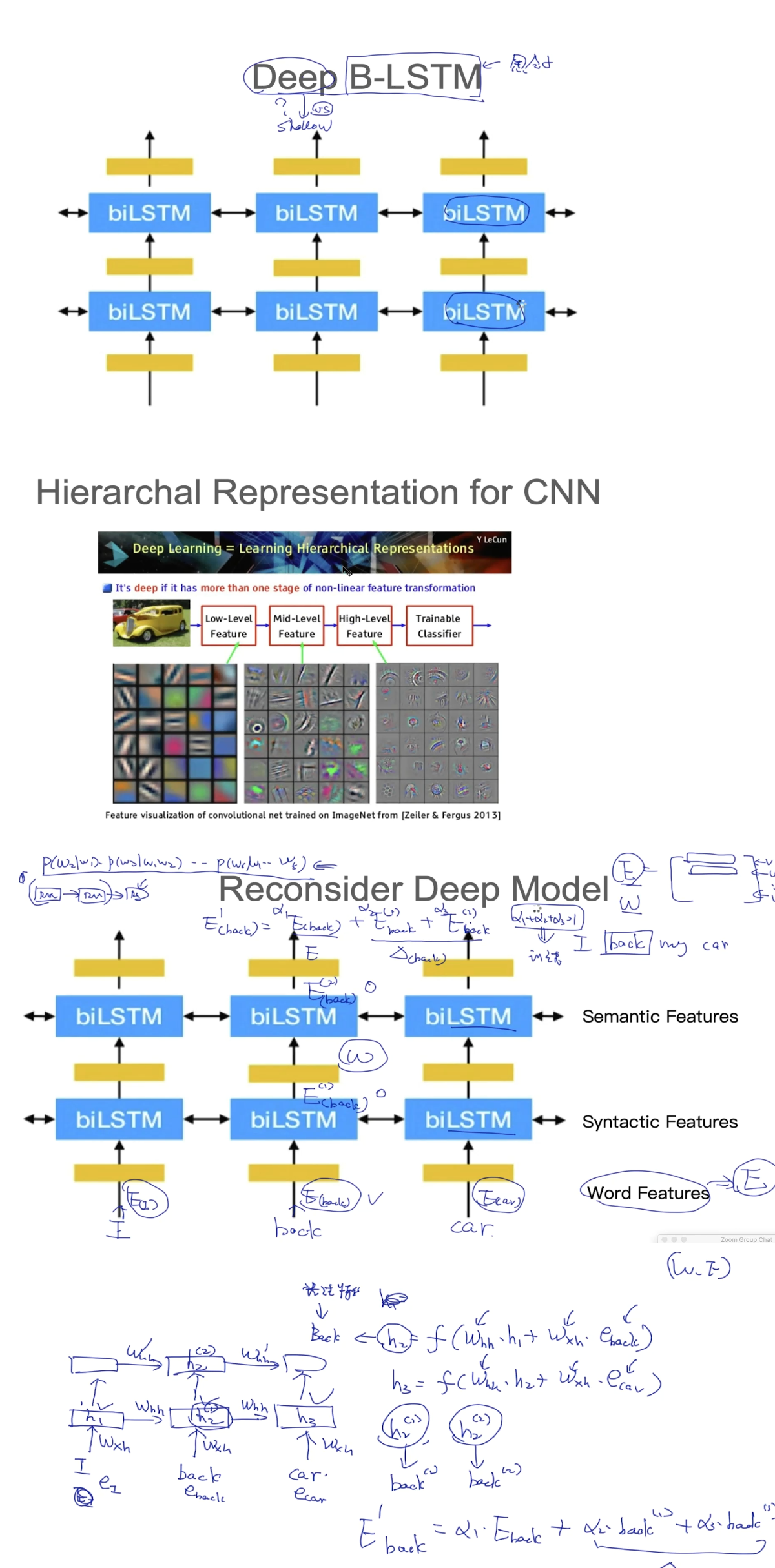
大多数人都以为是才智成就了科学家,他们错了,是品格。---爱因斯坦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号