如何加速pandas的DataFrame
使用pandarallel模块对 Pandas加速
python的dataFrame确实好用,但是明显只能单核运算
使用pandas,当您运行以下行时:
# Standard apply
df.apply(func)
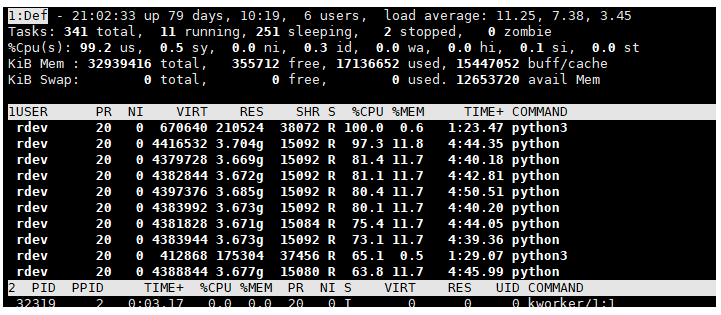
得到这个CPU使用率:

即使计算机有多个CPU,也只有一个完全专用于计算。
最近受群友推荐开始找到这个加速器,真的牛叉!!!可以真正体验到用python也可单机核力全开,八核起飞的快感!!
【Pandaral·lel 】的想法是将pandas计算分布在计算机上所有可用的CPU上,以显着提高速度。
安装:
$ pip install pandarallel [--user]
导入和初始化:
导入:
from pandarallel import pandarallel
Initialization
pandarallel.initialize()
用法十分简单:
用法:
使用带有pandas DataFrame的简单用例df和要应用的函数func,只需替换经典apply的parallel_apply。
# Standard pandas apply
df.apply(func)
# Parallel apply
df.parallel_apply(func)
shm_size_mb: Deprecated.nb_workers: Number of workers used for parallelization. (int) If not set, all available CPUs will be used.progress_bar: Display progress bars if set toTrue. (bool,Falseby default)verbose: The verbosity level (int,2by default)- 0 - don't display any logs
- 1 - display only warning logs
- 2 - display all logs
use_memory_fs: (bool,Noneby default)- If set to None and if memory file system is available, Pandarallel will use it to transfer data between the main process and workers. If memory file system is not available, Pandarallel will default on multiprocessing data transfer (pipe).
- If set to True, Pandarallel will use memory file system to transfer data between the main process and workers and will raise a
SystemErrorif memory file system is not available. - If set to False, Pandarallel will use multiprocessing data transfer (pipe) to transfer data between the main process and workers
With df a pandas DataFrame, series a pandas Series, func a function to apply/map, args, args1, args2 some arguments, and col_name a column name:
| Without parallelization | With parallelization |
|---|---|
df.apply(func) |
df.parallel_apply(func) |
df.applymap(func) |
df.parallel_applymap(func) |
df.groupby(args).apply(func) |
df.groupby(args).parallel_apply(func) |
df.groupby(args1).col_name.rolling(args2).apply(func) |
df.groupby(args1).col_name.rolling(args2).parallel_apply(func) |
series.map(func) |
series.parallel_map(func) |
series.apply(func) |
series.parallel_apply(func) |
series.rolling(args).apply(func) |
series.rolling(args).parallel_apply(func) |
You will find a complete example here for each row in this table.
报错修复:pandarallel cannot find context for ‘fork‘
进入到pandarallel 的包文件里,就是pandarallel 安装的位置就是xxx:xxx/site-packages\pandarallel\pandarallel.py
把fork改成spawn就行
# Python 3.8 on MacOS by default uses "spawn" instead of "fork" as start method for new # processes, which is incompatible with pandarallel. We force it to use "fork" method. context = get_context("spawn")
使用 joblib 模块对 Pandas加速
如果需要对一个很大的数据集进行操作,而基于一列数据生成新的一列数据可能都需要耗费很长时间。
于是可以使用 joblib 进行并行处理。
假设我们有一个 dataframe 变量 data,要基于它的 source 列生成新的一列 double,其实就是把原来的 source 列做了个平方运算。
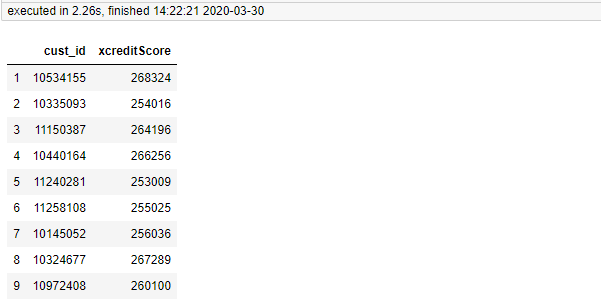
pandas中原生apply实现
import pandas as pd from sqlalchemy import create_engine mysql_engine=create_engine("""mysql+pymysql://root:xxxx@127.0.0.0.1:3306/tmp""") df=pd.read_sql("ipesa_apply_a_loan_new",mysql_engine) def double_func(xcreditScore): return pow(xcreditScore,2) df["xcreditScore"] = df["xcreditScore"].apply(double_func) df[['cust_id','xcreditScore']][1:10]
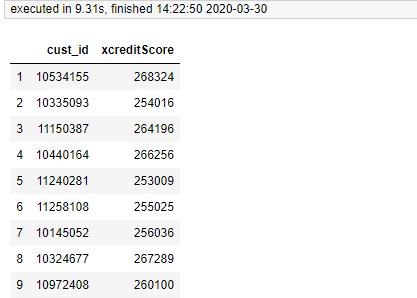
加速
from joblib import Parallel, delayed import pandas as pd from sqlalchemy import create_engine mysql_engine=create_engine("""mysql+pymysql://root:xxxx@127.0.0.0.1:3306/tmp""") df=pd.read_sql("ipesa_apply_a_loan_new",mysql_engine) def double_func(xcreditScore): return pow(xcreditScore,2) def key_func(subset): subset["xcreditScore"] = subset["xcreditScore"].apply(double_func) return subset data_grouped = df.groupby(df.index) results = Parallel(n_jobs=8)(delayed(key_func)(group) for index,group in data_grouped) pd.concat(results)[['cust_id','xcreditScore']][1:10]
1.基本原理就是把整个 dataframe 根据 index,每行生成了一个子数据集。--使用df.groupby()函数使迭代返回值维持dataFrame的格式。
2.而把每个子数据集作为子任务使用多进程运行,最终生成 results 是多进程运行生成的结果的 list,使用 concat 重新把单个df组合起来。
但是结果其实是耗时更长。我感觉很大原因是groupby聚合后迭代以及concat过程严重耗时。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号