Newsgroups数据集研究
1.数据集介绍
20newsgroups数据集是用于文本分类、文本挖据和信息检索研究的国际标准数据集之一。
数据集收集了大约20,000左右的新闻组文档,均匀分为20个不同主题的新闻组集合。
一些新闻组的主题特别相似(e.g. comp.sys.ibm.pc.hardware/ comp.sys.mac.hardware),还有一些却完全不相关 (e.g misc.forsale /soc.religion.christian)。
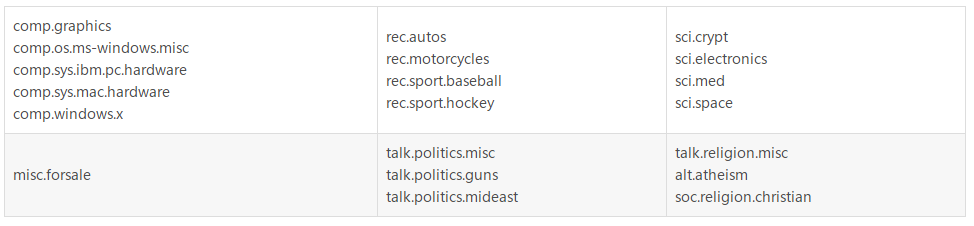
20newsgroups数据集有三个版本:
第一个版本19997是原始的并没有修改过的版本:20news-19997.tar.gz –原始20 Newsgroups数据集
第二个版本bydate是按时间顺序分为训练(60%)和测试(40%)两部分数据集,不包含重复文档和新闻组名(新闻组,路径,隶属于,日期):20news-bydate.tar.gz –按时间分类; 不包含重复文档和新闻组名(18846 个文档)
第三个版本18828不包含重复文档,只有来源和主题:20news-18828.tar.gz– 不包含重复文档,只有来源和主题 (18828 个文档)
在sklearn中,该模型有两种装载方式:
第一种是sklearn.datasets.fetch_20newsgroups,返回一个可以被文本特征提取器(如sklearn.feature_extraction.text.CountVectorizer)自定义参数提取特征的原始文本序列;
第二种是sklearn.datasets.fetch_20newsgroups_vectorized,返回一个已提取特征的文本序列,即不需要使用特征提取器。
2.数据集下载
使用ptyhon进行下载:
from sklearn.datasets import fetch_20newsgroups corpus_path = './corpora_data' data_train = fetch_20newsgroups(data_home=corpus_path, subset='train', categories=categories, shuffle=True, random_state=0, remove=remove) data_test = fetch_20newsgroups(data_home=corpus_path, subset='test', categories=categories, shuffle=True, random_state=0, remove=remove)
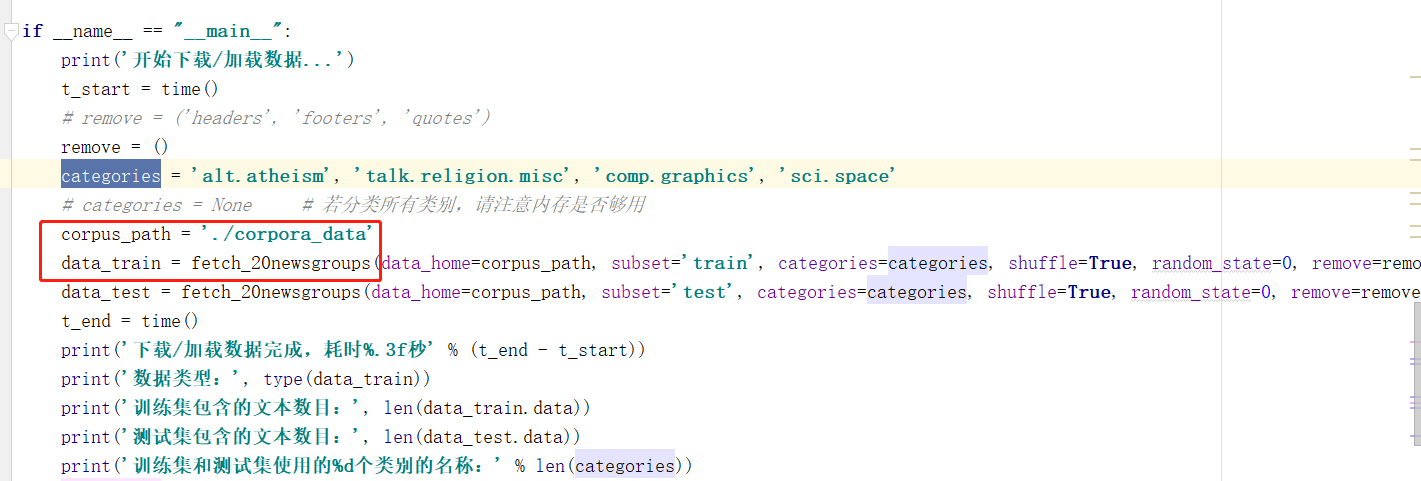
发现真的很卡。。。放弃
3.使用本地数据集
采取第二种方案:
1.下载文件
点击它给出的链接:20news-bydate.tar.gz –按时间分类; 不包含重复文档和新闻组名(18846 个文档)
2.路径修改
(1)下载后直接放在d:盘路径下
(2)
- 找到文件Anaconda3\Lib\site-packages\sklearn\datasets\twenty_newsgroups.py
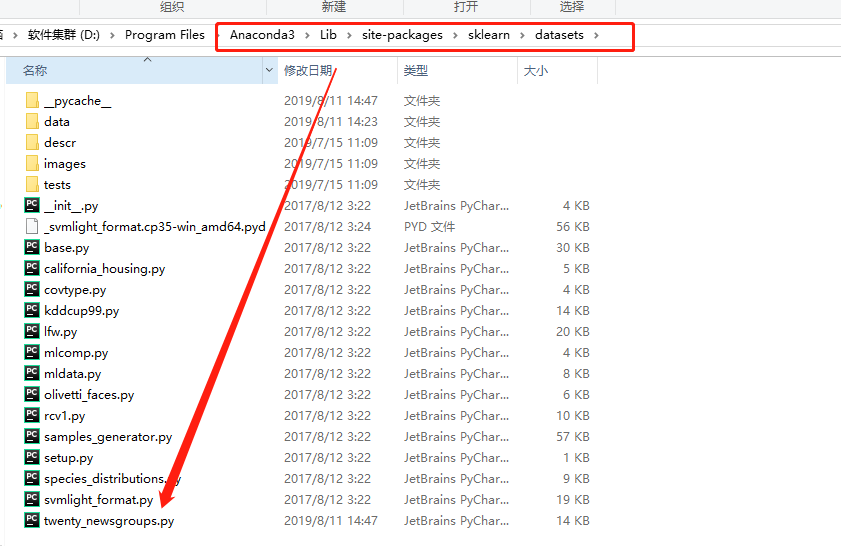
- 修改把在下载的代码注销(红色),增加路径(蓝色)
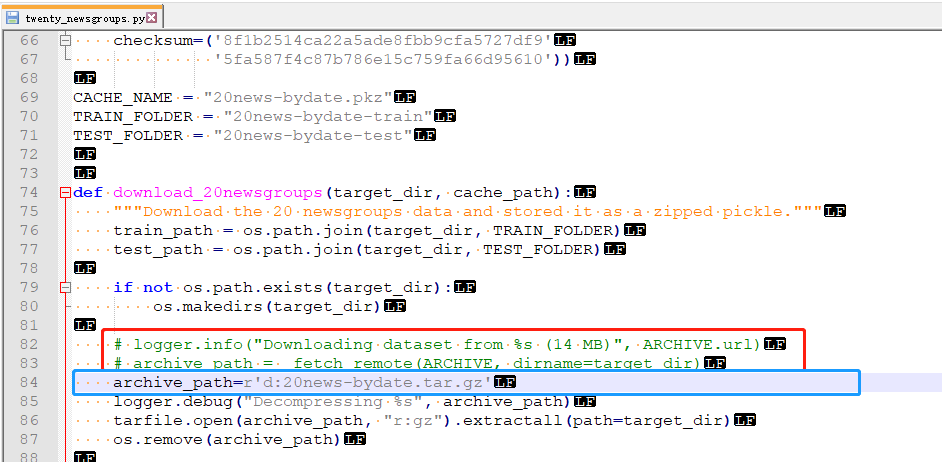
- 检查是否成功:如果在当前项目有如下路径则成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号