hadoop序列化
1.序列化
所谓的序列化,就是将结构化对象转化为字节流,以便在网络上传输或是写道磁盘进行永久存储。
反序列化,就是将字节流转化为结构化对象。
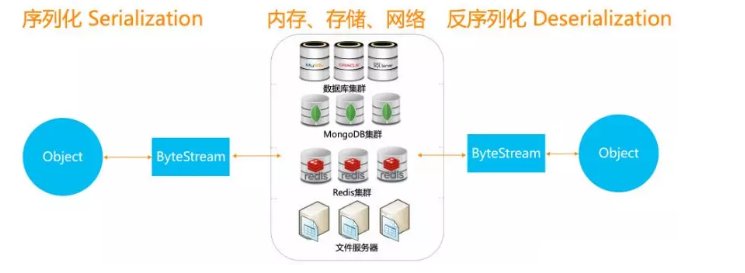
序列化在分布式数据处理的两大领域经常出现:进程间通信和永久存储。
在Hadoop中,系统中多个节点上进程间的通信是通过“远程过程调用”(remote procedure call, RPC)实现的。RPC将消息序列化成二进制流后发送到远程节点,远程节点接着将二进制流饭序列化为原始消息。通常情况下,RPC序列化格式许紧凑、快速、可扩展、和胡操作!紧凑的格式能够使我们充分利用数据中心中最稀缺的资源——网络带宽。
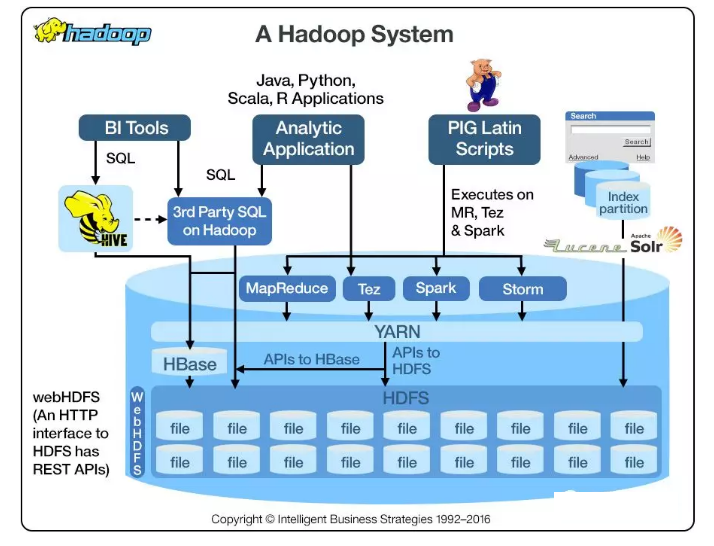
在Hadoop中,它使用自己的序列化框架Writable。
2.hadoop序列化框架
Writable接口也就是org.apache.hadoop.io。
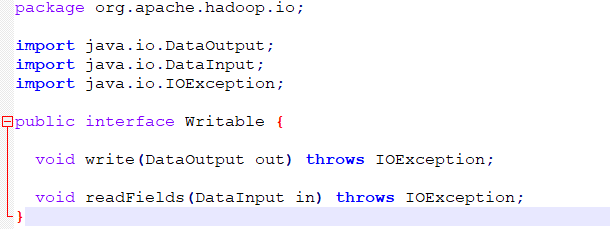
Writable接口定义了两个方法,一个是将其状态写如到DataOutput二进制流的write方法,另一个是从DataInput中读取结构化对象的readFields方法。
Hadoop的所有可序列化对象都必须实现这个接口。 Java的API提供了Comparable接口,也就是java.lang.Comparable接口。这个接口只有一个方法,就是compareTo,用于比较两个对象。
WritableComparable接口同时继承了Writable和Comparable这两个接口。
WritableComparable接口:继承自Writable接口 和 Comparable<T>接口;即有序列功能,也有比较排序功能;

RawComparator接口,该接口允许实现比较数据流中的记录,而不用把数据流反序列化为对象,从而避免了新建对象的额外开销;( 可实现Hadoop自定义比较排序接口连接)
public interface RawComparable { /** * Get the underlying byte array. * * @return The underlying byte array. */ abstract byte[] buffer(); /** * Get the offset of the first byte in the byte array. * * @return The offset of the first byte in the byte array. */ abstract int offset(); /** * Get the size of the byte range in the byte array. * * @return The size of the byte range in the byte array. */ abstract int size(); }
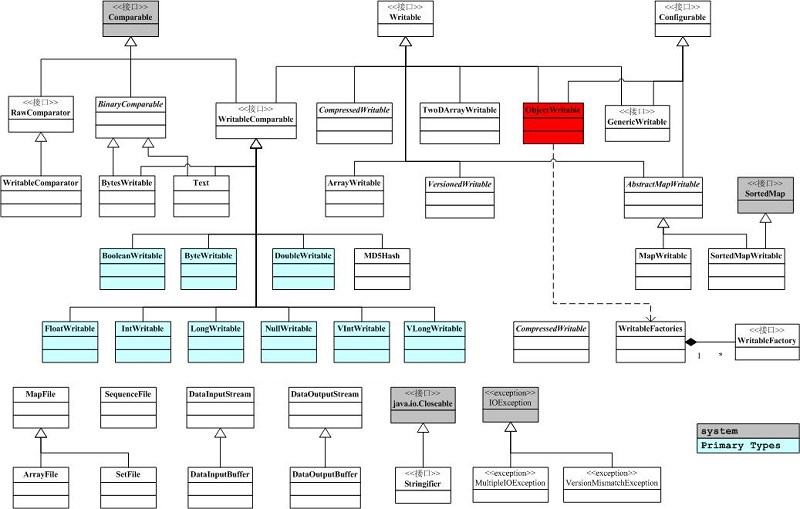
3.序列化框架实现子类介绍
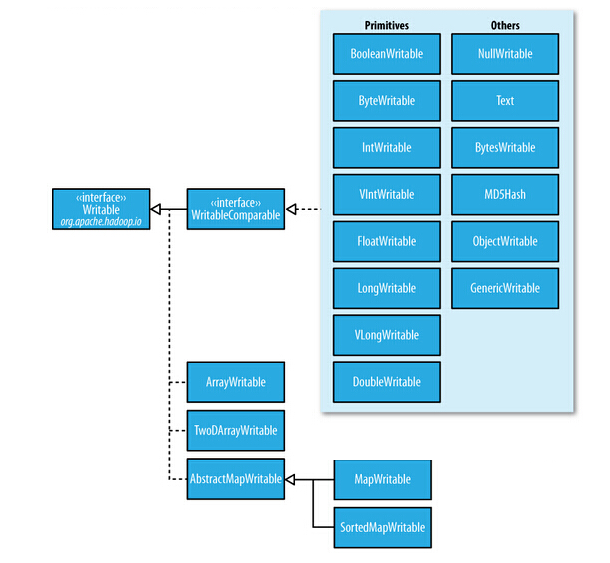
Hadoop序列化类
实现了WritableComparable接口的类
基础类:BooleanWritable,ByteWritable,IntWritable,VIntWritable,
FIntWritable,LongWritbale,VLongWritavle,DoubleWritable
高级类:NullWritable,Text,BytesWritable,MDSHash,ObjectWritable,
GenericWritable
仅实现了Writable接口的类:
数组:AbstractWritable,TwoDArrayWritable
映射:AbstractMapWritable,MapWritable,SortedMapWritable
我们主要介绍如绿色的几个:
LongWritable

Text

IntWritbale

NullWritable


 浙公网安备 33010602011771号
浙公网安备 33010602011771号