
过采样算法之SMOTE
SMOTE(Synthetic Minority Oversampling Technique),合成少数类过采样技术.它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,具体如下图所示,算法流程如下。
- (1)对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
- (2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为o。
- (3)对于每一个随机选出的近邻o,分别与原样本按照公式o(new)=o+rand(0,1)*(x-o)构建新的样本。


Smote算法的思想其实很简单,先随机选定n个少类的样本,如下图
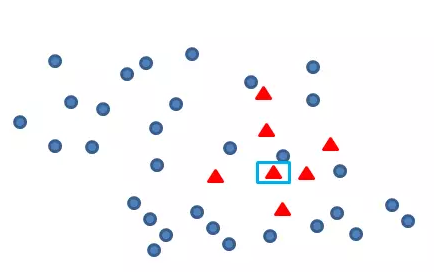
再找出最靠近它的m个少类样本,如下图
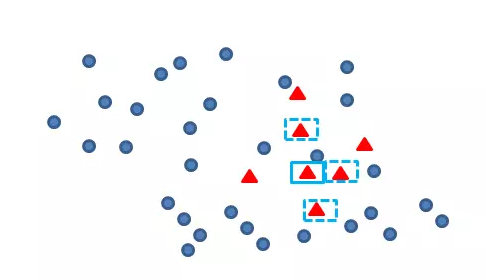
再任选最临近的m个少类样本中的任意一点,
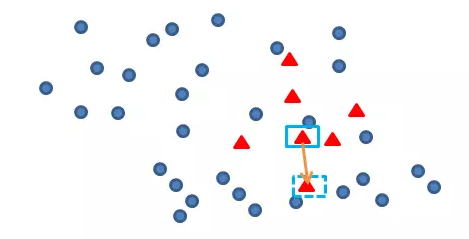
在这两点上任选一点,这点就是新增的数据样本

# -*- coding: utf-8 -*- import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from numpy import * import matplotlib.pyplot as plt #读数据 data = pd.read_table('supermarket_second_man_clothes_train.txt', low_memory=False) #简单的预处理 test_date = pd.concat([data['label'], data.iloc[:, 7:10]], axis=1) test_date = test_date.dropna(how='any')
结果:
test_date.head() Out[1]: label max_date_diff max_pay cnt_time 0 0 23.0 43068.0 15 1 0 10.0 1899.0 2 2 0 146.0 3299.0 21 3 0 30.0 31959.0 35 4 0 3.0 24165.0 98 test_date['label'][test_date['label']==0].count()/test_date['label'][test_date['label']==1].count() Out[2]: 67
label是样本类别判别标签,0:1=67:1,需要对label=1的数据进行扩充
# 筛选目标变量 aimed_date = test_date[test_date['label'] == 1] # 随机筛选少类扩充中心 index = pd.DataFrame(aimed_date.index).sample(frac=0.1, random_state=1) index.columns = ['id'] number = len(index) # 生成array格式 aimed_date_new = aimed_date.ix[index.values.ravel(), :]
随机选取了全量少数样本的10%作为数据扩充的中心点
# 自变量标准化 sc = StandardScaler().fit(aimed_date_new) aimed_date_new = pd.DataFrame(sc.transform(aimed_date_new)) sc1 = StandardScaler().fit(aimed_date) aimed_date = pd.DataFrame(sc1.transform(aimed_date)) # 定义欧式距离计算 def dist(a, b): a = array(a) b = array(b) d = ((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2 + (a[2] - b[2]) ** 2 + (a[3] - b[3]) ** 2) ** 0.5 return d
下面定义距离计算的方式,所有算法中,涉及到距离的地方都需要标准化去除冈量,也同时加快了计算的速度
这边采取了欧式距离的方式
# 统计所有检验距离样本个数 row_l1 = aimed_date_new.iloc[:, 0].count() row_l2 = aimed_date.iloc[:, 0].count() a = zeros((row_l1, row_l2)) a = pd.DataFrame(a) # 计算距离矩阵 for i in range(row_l1): for j in range(row_l2): d = dist(aimed_date_new.iloc[i, :], aimed_date.iloc[j, :]) a.ix[i, j] = d b = a.T.apply(lambda x: x.min())
调用上面的计算距离的函数,形成一个距离矩阵
# 找到同类点位置 h = [] z = [] for i in range(number): for j in range(len(a.iloc[i, :])): ai = a.iloc[i, j] bi = b[i] if ai == bi: h.append(i) z.append(j) else: continue new_point = [0, 0, 0, 0] new_point = pd.DataFrame(new_point) for i in range(len(h)): index_a = z[i] new = aimed_date.iloc[index_a, :] new_point = pd.concat([new, new_point], axis=1) new_point = new_point.iloc[:, range(len(new_point.columns) - 1)]
再找到位置的情况下,再去原始的数据集中根据位置查找具体的数据
import random r1 = [] for i in range(len(new_point.columns)): r1.append(random.uniform(0, 1)) new_point_last = [] new_point_last = pd.DataFrame(new_point_last) # 求新点 new_x=old_x+rand()*(append_x-old_x) for i in range(len(new_point.columns)): new_x = (new_point.iloc[1:4, i] - aimed_date_new.iloc[number - 1 - i, 1:4]) * r1[i] + aimed_date_new.iloc[number - 1 - i, 1:4] new_point_last = pd.concat([new_point_last, new_x], axis=1) print new_point_last
最后,再根据smote的计算公式new_x=old_x+rand()*(append_x-old_x),计算出新的点即可。
smote算法的伪代码如下:
import random from sklearn.neighbors import NearestNeighbors import numpy as np class Smote: def __init__(self,samples,N=1,k=5): self.n_samples,self.n_attrs=samples.shape self.N=N self.k=k self.samples=samples self.newindex=0 # self.synthetic=np.zeros((self.n_samples*N,self.n_attrs)) def over_sampling(self): N=int(self.N) self.synthetic = np.zeros((self.n_samples * N, self.n_attrs)) neighbors=NearestNeighbors(n_neighbors=self.k).fit(self.samples) print('neighbors',neighbors) for i in range(len(self.samples)): nnarray=neighbors.kneighbors(self.samples[i].reshape(1,-1),return_distance=False)[0] #print nnarray self._populate(N,i,nnarray) return self.synthetic # for each minority class samples,choose N of the k nearest neighbors and generate N synthetic samples. def _populate(self,N,i,nnarray): for j in range(N): nn=random.randint(0,self.k-1) dif=self.samples[nnarray[nn]]-self.samples[i] gap=random.random() self.synthetic[self.newindex]=self.samples[i]+gap*dif self.newindex+=1 a=np.array([[1,2,3],[4,5,6],[2,3,1],[2,1,2],[2,3,4],[2,3,4]]) s=Smote(a,N=2) #a为少数数据集,N为倍率,即从k-邻居中取出几个样本点 print(s.over_sampling())
该算法主要存在两方面的问题:一是在近邻选择时,存在一定的盲目性。从上面的算法流程可以看出,在算法执行过程中,需要确定K值,即选择多少个近邻样本,这需要用户自行解决。从K值的定义可以看出,K值的下限是M值(M值为从K个近邻中随机挑选出的近邻样本的个数,且有M< K),M的大小可以根据负类样本数量、正类样本数量和数据集最后需要达到的平衡率决定。但K值的上限没有办法确定,只能根据具体的数据集去反复测试。因此如何确定K值,才能使算法达到最优这是未知的。
另外,该算法无法克服非平衡数据集的数据分布问题,容易产生分布边缘化问题。由于负类样本的分布决定了其可选择的近邻,如果一个负类样本处在负类样本集的分布边缘,则由此负类样本和相邻样本产生的“人造”样本也会处在这个边缘,且会越来越边缘化,从而模糊了正类样本和负类样本的边界,而且使边界变得越来越模糊。这种边界模糊性,虽然使数据集的平衡性得到了改善,但加大了分类算法进行分类的难度.
针对SMOTE算法存在的边缘化和盲目性等问题,很多人纷纷提出了新的改进办法,在一定程度上改进了算法的性能,但还存在许多需要解决的问题。
Han等人Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning在SMOTE算法基础上进行了改进,提出了Borderhne.SMOTE算法,解决了生成样本重叠(Overlapping)的问题该算法在运行的过程中,查找一个适当的区域,该区域可以较好地反应数据集的性质,然后在该区域内进行插值,以使新增加的“人造”样本更有效。这个适当的区域一般由经验给定,因此算法在执行的过程中有一定的局限性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号