
hadoop-hdfs分布式文件系统
- SecondaryNameNode 在一定程度上可以对NameNode进行备份,但不是热备。
- Block的副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在与第一个副本不同的机架的节点上。
- 第三个副本:与第二个副本相同机架的节点。(在同一个机架上可以保证传输速度,同一个机架一般是一个交换机)
- 更多副本:随机节点

- HDFS读流程

- 1.客户端发送请求,通过调用API 发送请求给NameNode
- 2.获得相应block的位置信息
- 3.通过API 并发的读各个block
- 4,5 并发的读block (block的副本有多个,只读一个从空闲的机器上)
- 6. 返回给客户端,并关闭流
- 注意,这个一般不会读一个超大的文件
- HDFS 写流程
-
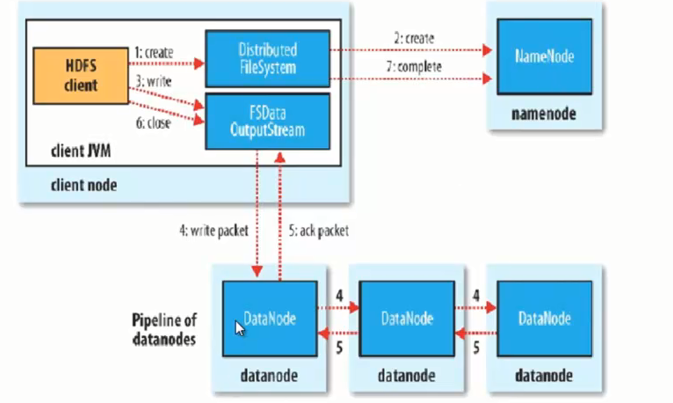
- 注意:副本产生机制是datanode自己进行复制的,不是客户端写三份,dataNode会启动新的线程,进行副本的拷贝。
-
使用3台机器搭建hdfs完全分布式集群 201(NameNode),202(DataNode),203(DataNode)
整体架构
NameNode(192.168.1.201)
DataNode(192.168.1.202,192.168.1.203)
SecondaryNameNode(192.168.1.202)
1.从官网上下载hadoop包,并上传到linux系统上
hadoop-1.2.1.tar.gz
解压
tar -zxvf hadoop-1.2.1.tar.gz linux服务器上需要jdk环境
由于名字长,可以加一条软连
ln -sf /root/hodoop-1.2.1 /home/hodoop-1.2
2.修改 core-site.xml配置文件
vi /home/hadoop-1.2/conf
配置NameNode主机及端口号,配置工作目录
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.201:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-1.2</value>
</property>
</configuration>
默认的工作目录在tmp目录下,linux系统重新启东时会清空tmp目录
在解压hadoop压缩包后
/hadoop-1.2.1/docs/core-default.html
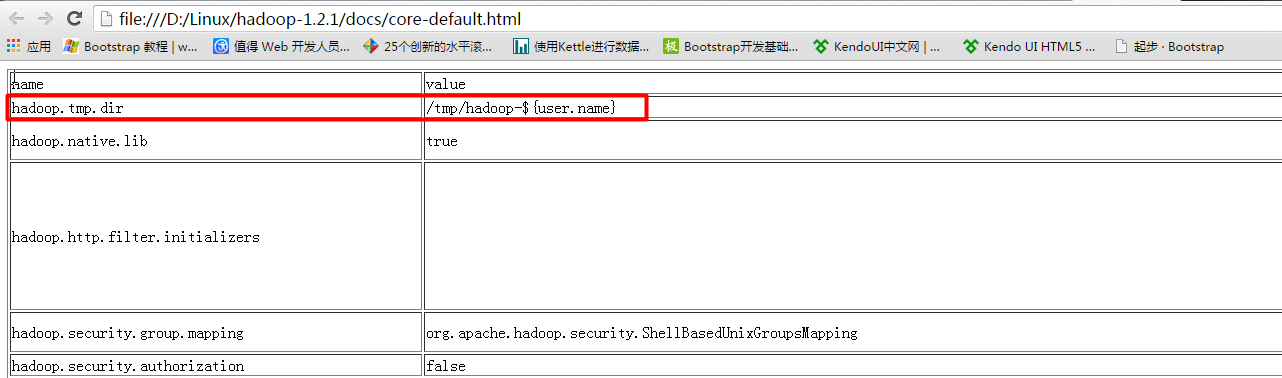
hdfs的工作目录是以tmp临时目录为基础的
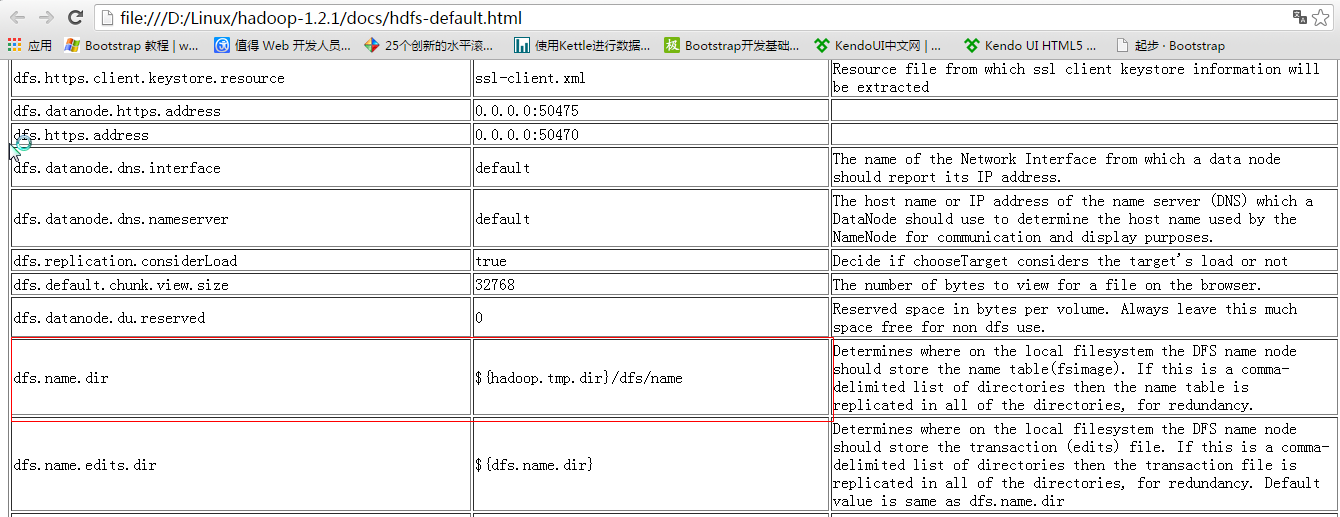
3.配置conf/hdfs-site.xml
配置dfs.replication,配置DataNode的副本个数 202,203作为dataNode,所以副本个数 <= 2
同样的副本不能再同一台机器上,副本个数一定是<=DataNode个数
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4.配置dataNode节点
vi /conf/slaves (可以不使用ip地址,使用主机名)

5.配置SecondaryNameNode,注意不能与NameNode在同一台机器上
vi /conf/masters
192.168.1.202
6.配置免密码登录
免密码登录可以在任意一台机器上输入命令,可以启动所有机器上的进程
如果不做免密码登录,需要在每一台机器上输入启动进程命令
配置201上的免密码登录
在201上生成秘钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在.ssh目录下生成
[root@bogon .ssh]# ls
authorized_keys id_dsa id_dsa.pub known_hosts
[root@bogon .ssh]#
id_dsa 为私钥,id_dsa.pub为公钥
配置单台机器的免密码登录
执行下列命令
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
配置跨节点的免密码登录
先执行
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
生成id_dsa.pub公钥
将id_dsa.pub拷贝到将要免密码登录的那台机器上
scp id_dsa.pub root@192.168.1.202:~
在 192.168.1.202 上将id_dsa.pub追加到 authorized_keys 日子文件上
$ cat ~/id_dsa.pub >> ~/.ssh/authorized_keys
使用 more authorized_keys 查看
在201上使用 ssh 192.168.1.202:22 登录到202上
需要先做本地免密码登录,然后做跨节点免密码登录
配置结果为 201-->202,201-->203, 如果需要相反,则主要重复上边相反过程
7.所有节点进行相同配置
拷贝压缩包
scp -r ~/hadoop-1.2.1.tar.gz root@192.168.1.202:~/
解压
tar -zxvf hadoop-1.2.1.tar.gz
创建软连
ln -sf /root/hadoop-1.2.1 /home/hodoop-1.2
进行格式化
[root@bogon bin]# ./hadoop namenode -format
配置JAVA_HOME
[root@bogon conf]# vi hadoop-env.sh
# Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # The java implementation to use. Required. export JAVA_HOME=/usr/java/jdk1.7.0_75 # Extra Java CLASSPATH elements. Optional. # export HADOOP_CLASSPATH= # The maximum amount of heap to use, in MB. Default is 1000. # export HADOOP_HEAPSIZE=2000 # Extra Java runtime options. Empty by default. # export HADOOP_OPTS=-server # Command specific options appended to HADOOP_OPTS when specified "hadoop-env.sh" 57L, 2433C
将已配置好的配置文件拷贝到其他机器上(需要拷贝到202,203上)
[root@bogon conf]# scp ./* root@192.168.1.202:/home/hadoop-1.2/conf/
启动
[root@bogon bin]# ./start-dfs.sh
在启动前需要关闭防火墙
service iptables stop
启动后可以使用 jps 查看是否启动成功

