java线程池理解
Java 线程的创建非常昂贵,需要 JVM 和 OS(操作系统)配合完成大量的工作:
- (1)必须为线程堆栈分配和初始化大量内存块,其中包含至少 1M 的栈内存。
- (2)需要进行系统调用,以便在 OS(操作系统)中创建和注册本地线程。
Java 高并发应用频繁创建和销毁线程的操作将是非常低效的,而且是不被编程规范所允许的。
如何降低 Java 线程的创建成本,就必须使用到线程池。线程池主要解决了以下两个问题:
- (1)提升性能:线程池能独立负责线程的创建、维护、分配。在执行大量异步任务时,可
以不需要自己创建线程,而是将任务交给线程池去调度。线程池能尽可能去使用空闲的线程,去
执行异步任务,最大限度地对已经创建的线程进行复用,使得性能提升明显。
- (2)线程管理:每个 Java 线程池会保持一些基本的线程统计信息,例如完成的任务数量、
空闲时间等,以便对线程进行有效管理,使得能对所接收到异步任务进行高效调度。
说明:在主要大厂的编程规范中,不允许在应用中自行显式的创建线程池,线程必须通过线程池提供。由于创建和销毁线程上需要时间以及系统资源开销,使用线程池的好处是减少这些开销,解决资源不足的问题。
JUC 的线程池架构
在多线程编程中,任务都是一些抽象且离散的工作单元,而线程是使任务异步执行的基本机制。随着应用的扩张,线程和任务管理也变得非常复杂,为了简化这些复杂的线程管理模式,我们需要一个“管理者”来统一管理线程及任务分配,这就是线程池。
在 JUC 中有关线程池的类与接口的架构图,大致如图 1-14 所示。
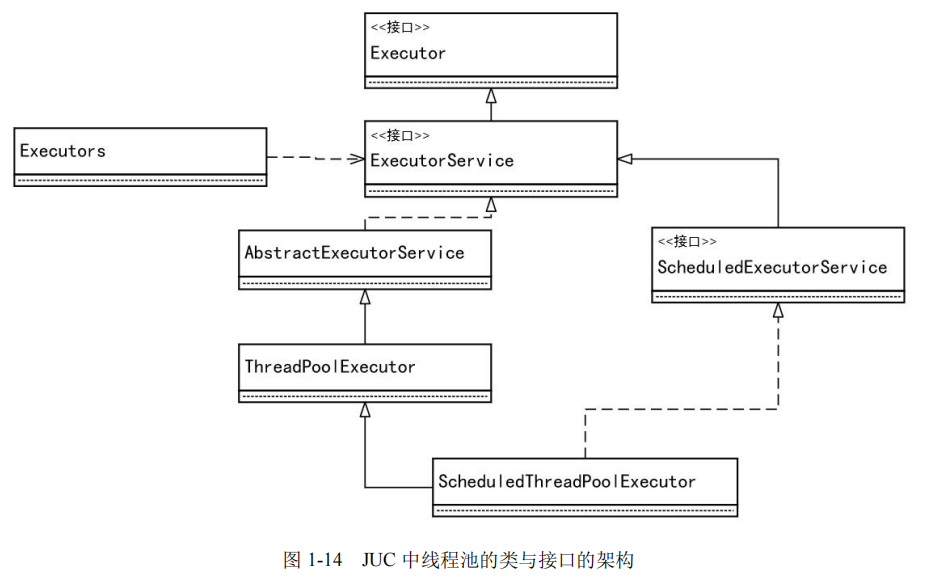
说明:JUC就是java.util.concurrent工具包的简称,该工具包是从JDK1.5开始加入到JDK,用于完成高并发、处理多线程的一个工具包。
1. Executor
它是 Java 异步目标任务的“执行者”接口,其目标是来执行目标任务。“执行者”Executor 提供了 execute()接口来执行已提交的 Runnable 执行目标实例。Executor 作为执行者的角色,存在的目的是“任务提交者”与“任务执行者”分离开来的机制。它只包含一个函数式方法:
void execute(Runnable command)
2. ExecutorService
ExecutorService 继承于 Executor。它是 Java 异步目标任务的“执行者服务“接口,它对外提供异步任务的接收服务,ExecutorService 提供了“接收异步任务、并转交给执行者”的方法,如submit 系列方法、invoke 系列方法等等。具体如下:
//向线程池提交单个异步任务 <T> Future<T> submit(Callable<T> task); //向线程池提交批量异步任务 <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
3. AbstractExecutorService
AbstractExecutorService 是 一 个 抽 象 类 , 它 实 现 了 ExecutorService 接 口 。AbstractExecutorService 存在的目的是为 ExecutorService 中的接口提供了默认实现。
4. ThreadPoolExecutor
ThreadPoolExecutor 就是大名鼎鼎的“线程池”实现类,它继承于 AbstractExecutorService 抽象类。
ThreadPoolExecutor 是 JUC 线程池的核心实现类。线程的创建和终止需要很大的开销,线程池中预先提供了指定数量的可重用线程,所以使用线程池会节省系统资源,并且每个线程池都维护了一些基础的数据统计,方便线程的管理和监控。
5. ScheduledExecutorService
ScheduledExecutorService 是一个接口,它继承于于 ExecutorService。它是一个可以完成“延时”“周期性”任务的调度线程池接口,其功能和 Timer/TimerTask 类似。
6. ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 继承于 ThreadPoolExecutor,它提供了 ScheduledExecutorService线程池接口中“延时执行”和“周期执行”等抽象调度方法的具体实现。
ScheduledThreadPoolExecutor 类 似 于 Timer , 但 是 在 高 并 发 程 序 中 ,ScheduledThreadPoolExecutor 的性能要优于 Timer。
7. Executors
Executors 是 个 静 态 工 厂 类 , 它 通 过 静 态 工 厂 方 法 返 回 ExecutorService 、ScheduledExecutorService 等线程池示例对象,这些静态工厂方法可以理解为一些快捷的创建线程池的方法。
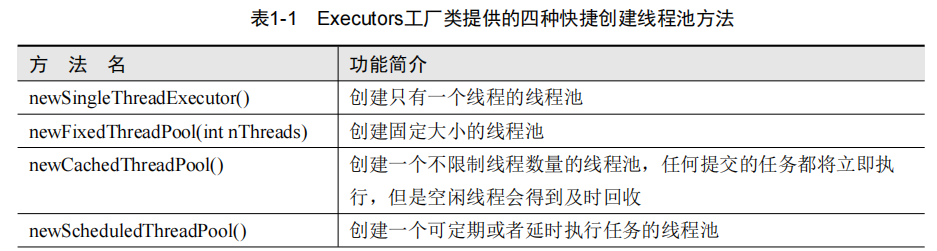
Executors 四个快捷创建线程池方法
Java 通过 Executors 工厂类提供四种快捷创建线程池的方法,具体如表 1-1 所示。
1. newSingleThreadExecutor 创建“单线程化线程池”
该方法用于创建一个“单线程化线程池”,也就是只有一条线程的线程池,所创建的线程池用唯一的工作线程来执行任务,使用此方法创建的线程池,能保证所有任务按照指定顺序(如FIFO)执行。
使用 Executors.newSingleThreadExecutor ()快捷工厂方法去创建一个“单线程化线程池”的测试用例,其代码具体如下:

package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { public static final int SLEEP_GAP = 500; //异步任务的执行目标类 static class TargetTask implements Runnable { static AtomicInteger taskNo = new AtomicInteger(1); private String taskName; public TargetTask() { taskName = "task-" + taskNo.get(); taskNo.incrementAndGet(); } public void run() { Print.tco("任务:" + taskName + " doing"); // 线程睡眠一会 sleepMilliSeconds(SLEEP_GAP); Print.tco(taskName + " 运行结束."); } } //测试用例:只有一条线程的线程池 @Test public void testSingleThreadExecutor() { ExecutorService pool = Executors.newSingleThreadExecutor(); for (int i = 0; i < 5; i++) { pool.execute(new TargetTask()); pool.submit(new TargetTask()); } sleepSeconds(1000); //关闭线程池 pool.shutdown(); } }
运行以上代码,部分结果截取如下:
[pool-1-thread-1]:任务:task-1 doing
[pool-1-thread-1]:task-1 运行结束.
[pool-1-thread-1]:任务:task-2 doing
……
[pool-1-thread-1]:任务:task-10 doing
[pool-1-thread-1]:task-10 运行结束.
从以上输出中可以看出,该线程池有以下特点:
- (1)单线程化的线程池中的任务,是按照提交的次序,顺序执行的。
- (2)池中的唯一线程的存活时间是无限的。
- (3)当池中的唯一线程正繁忙时,新提交的任务实例会进入内部的阻塞队列中,并且其阻塞队列是无界的。
总体来说,单线程化的线程池所适用的场景是:任务按照提交次序,一个任务一个任务逐个执行的场景。以上用例在最后使用 shutdown()方法用来关闭线程池。执行 shutdown()方法后,线程池状态变为 SHUTDOWN 状态,此时,线程池将拒绝新任务,不能再往线程池中添加新任务,否则会抛出 RejectedExecutionException 异常。此时,线程池不会立刻退出,直到添加到线程池中的任务都已 经 处 理 完 成 才 会 退 。 还 有 一 个 与 shutdown() 类 似 的 方 法 , 叫 做 shutdownNow() , 执 行shutdownNow()方法后,线程池状态会立刻变成 STOP 状态,并试图停止所有正在执行的线程,并且不再处理还在阻塞队列中等待的任务,会返回那些未执行的任务。
2. newFixedThreadPool 创建“固定数量的线程池”
该方法用于创建一个“固定数量的线程池”,其唯一的参数用于设置池中线程的“固定数量”。使用 Executors.newFixedThreadPool (int threads)快捷工厂方法去创建“固定数量的线程池”的测试用例,其代码具体如下:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { public static final int SLEEP_GAP = 500; //异步任务的执行目标类 static class TargetTask implements Runnable { ...为节约篇幅,省略重复内容 } //测试用例:只有 3 条线程固定大小的线程池 @Test public void testNewFixedThreadPool() { ExecutorService pool = Executors.newFixedThreadPool(3); for (int i = 0; i < 5; i++) { pool.execute(new TargetTask()); pool.submit(new TargetTask()); } sleepSeconds(1000); //关闭线程池 pool.shutdown(); } ...省略其他 }
执行以上测试用例,部分结果截取如下:
[pool-1-thread-3]:任务:task-3 doing
[pool-1-thread-2]:任务:task-2 doing
[pool-1-thread-1]:任务:task-1 doing
[pool-1-thread-1]:task-1 运行结束.
[pool-1-thread-1]:任务:task-4 doing
[pool-1-thread-2]:task-2 运行结束.
……
[pool-1-thread-3]:任务:task-8 doing
[pool-1-thread-2]:任务:task-9 doing
[pool-1-thread-1]:task-7 运行结束.
[pool-1-thread-1]:任务:task-10 doing
[pool-1-thread-3]:task-8 运行结束.
[pool-1-thread-2]:task-9 运行结束.
[pool-1-thread-1]:task-10 运行结束.
在测试用例中,创建了一个线程数为 3 的“固定数量线程池”,然后向其中提交了 10 个任务。从输出结果可以看到,该线程池同时只能执行 3 个任务,剩余的任务会排队等待。“固定数量的线程池”的特点,大致如下:
- (1)如果线程数没有达到“固定数量”,则每次提交一个任务池内就创建一个新线程,直到线程达到线程池的固定的数量。
- (2)线程池的大小一旦达到“固定数量”就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
- (3)在接收异步任务的执行目标实例时,如果池中的所有线程均在繁忙状态,对于新任务会进入阻塞队列中(无界的阻塞队列)。
“固定数量的线程池”的适用场景:需要任务长期执行的场景。“固定数量的线程池”的线程数能够比较稳定保证一个数,能够避免频繁回收线程和创建线程,故适用于处理 CPU 密集型的任务,在 CPU 被工作线程长时间使用的情况下,能确保尽可能少的分配线程。
“固定数量的线程池”的弊端:内部使用无界队列来存放排队任务,当大量任务超过线程池最大容量需要处理时,队列无线增大,使服务器资源迅速耗尽。
3. newCachedThreadPool 创建“可缓存线程池”
该方法用于创建一个“可缓存线程池”,如果线程池内的某些线程无事可干成为空闲线程,“可缓存线程池”可灵活回收这些空闲线程。
使用 Executors.newCachedThreadPool()快捷工厂方法去创建一个“可缓存线程池”的测试用例,其代码具体如下:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { public static final int SLEEP_GAP = 500; //异步任务的执行目标类 static class TargetTask implements Runnable { ...为节约篇幅,省略重复内容 } //测试用例:“可缓存线程池” @Test public void testNewCacheThreadPool() { ExecutorService pool = Executors.newCachedThreadPool(); for (int i = 0; i < 5; i++) { pool.execute(new TargetTask()); pool.submit(new TargetTask()); } sleepSeconds(1000); //关闭线程池 pool.shutdown(); } ...省略其他 }
运行以上测试用例,结果如下:
[pool-1-thread-9]:任务:task-9 doing
[pool-1-thread-2]:任务:task-2 doing
[pool-1-thread-7]:任务:task-7 doing
[pool-1-thread-5]:任务:task-5 doing
[pool-1-thread-8]:任务:task-8 doing
[pool-1-thread-3]:任务:task-3 doing
[pool-1-thread-1]:任务:task-1 doing
[pool-1-thread-4]:任务:task-4 doing
[pool-1-thread-6]:任务:task-6 doing
[pool-1-thread-10]:任务:task-10 doing
[pool-1-thread-5]:task-5 运行结束.
[pool-1-thread-3]:task-3 运行结束.
[pool-1-thread-7]:task-7 运行结束.
[pool-1-thread-4]:task-4 运行结束.
[pool-1-thread-8]:task-8 运行结束.
[pool-1-thread-9]:task-9 运行结束.
[pool-1-thread-1]:task-1 运行结束.
[pool-1-thread-2]:task-2 运行结束.
[pool-1-thread-10]:task-10 运行结束.
[pool-1-thread-6]:task-6 运行结束.
“可缓存线程池”的特点,大致如下:
- (1)在接收新的异步任务 target 执行目标实例时,如果池内所有线程繁忙,此线程池会添加新线程来处理任务。
- (2)此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。
- (3)如果部分线程空闲,也就是存量线程的数量超过了处理任务数量,那么就会回收空闲(60 秒不执行任务)线程。
“可缓存线程池”的适用场景:需要快速处理突发性强、耗时较短的任务场景,如 Netty 的NIO 处理场景、REST API 接口的瞬时削峰场景。“可缓存线程池”的线程数量不固定,只要有空闲线程就会被回收;接收到的新异步任务执行目标,查看是否有线程处于空闲状态,如果没有就直接创建新的线程。
“可缓存线程池”的弊端:线程池没有最大线程数量限制,如果大量的异步任务执行目标实例同时提交,可能导致创线程过多会而导致资源耗尽。
4. newScheduledThreadPool 创建“可调度线程池”
该方法用于创建一个“可调度线程池”,一个提供“延时”和“周期性”任务的调度功能的ScheduledExecutorService 类型的线程池。Executors 提供了多个创建“可调度线程池”工厂方法,部分如下:
//方法一:创建一个可调度线程池,池内仅含有一条线程
public static ScheduledExecutorService newSingleThreadScheduledExecutor();
//方法二:创建一个可调度线程池,池内含有 N 条线程,N 的值为输入参数 corePoolSize
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) ;
newSingleThreadScheduledExecutor 工厂方法所创建的仅含有一条线程的可调度线程池,适用于 调 度 串 行 化 任 务 , 也 就 是 一 个 一 个 任 务 的 串 行 化 调 度 执 行 。 使 用Executors.newScheduledThreadPool(int corePoolSize)快捷工厂方法创建一个“可调度线程池”的测试用例,其代码具体如下:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { public static final int SLEEP_GAP = 500; //异步任务的执行目标类 static class TargetTask implements Runnable { ...为节约篇幅,省略重复内容 } //测试用例:“可调度线程池” @Test public void testNewScheduledThreadPool() { ScheduledExecutorService scheduled = Executors.newScheduledThreadPool(2); for (int i = 0; i < 2; i++) { scheduled.scheduleAtFixedRate(new TargetTask(), 0, 500, TimeUnit.MILLISECONDS); //以上的参数中: // 0 表示首次执行任务的延迟时间,500 表示每次执行任务的间隔时间 //TimeUnit.MILLISECONDS 执行的时间间隔数值单位为毫秒 } sleepSeconds(1000); //关闭线程池 scheduled.shutdown(); } ...省略其他 }
运行程序,部分结果截取如下:
[pool-1-thread-2]:任务:task-2 doing
[pool-1-thread-1]:任务:task-1 doing
……
[pool-1-thread-1]:任务:task-1 doing
[pool-1-thread-2]:任务:task-2 doing
[pool-1-thread-1]:task-1 运行结束.
[pool-1-thread-2]:task-2 运行结束.
newScheduledThreadPool工厂方法可以创建一个执行“延时”和“周期性”任务可调度线程池,所创建的线程池为ScheduleExecutorService类型的实例。ScheduleExecutorService接口中有多个重要的接收被调目标任务方法,其中 scheduleAtFixedRate和scheduleWithFixedDelay使用比较多。
ScheduleExecutorService 接收被调目标任务方法之一,scheduleAtFixedRate 方法的定义如下:
public ScheduledFuture<?> scheduleAtFixedRate( Runnable command, //异步任务 target 执行目标实例; long initialDelay, //首次执行延时; long period, //两次开始执行最小间隔时间; TimeUnit unit //所设置的时间的计时单位,如 TimeUnit.SECONDS 常量; );
ScheduleExecutorService接收被调目标任务方法之二,scheduleWithFixedDelay方法的定义如下:
public ScheduledFuture<?> scheduleWithFixedDelay( Runnable command,//异步任务 target 执行目标实例; long initialDelay, //首次执行延时; long delay, //前一次执行结束到下一次执行开始的间隔时间(间隔执行延迟时间); TimeUnit unit //所设置的时间的计时单位,如 TimeUnit.SECONDS 常量; );
当被调任务的执行时间大于指定的间隔时间时,ScheduleExecutorService 并不会在创建一个新的线程去并发执行这个任务,而是等待前一次调度执行完毕。
“可调度线程池”的适用场景:周期性执行任务的场景。SpringBoot 中的任务调度器,底层借助了 JUC 的 ScheduleExecutorService“可调度线程池”实现,并且可以通过@Configuration 配置类型的 Bean,对“可调度线程池”实例进行配置,下面是一个例子:
@Configuration public class ScheduledConfig implements SchedulingConfigurer { @Override public void configureTasks( ScheduledTaskRegistrar scheduledTaskRegistrar) { Method[] methods = BatchProperties.Job.class.getMethods(); int defaultPoolSize = 4; //默认的线程数为 4 int corePoolSize = 0; // 扫描配置了@Scheduled 调度注解的方法 //根据需要调度的方法数,配置线程池中的线程数 if (methods != null && methods.length > 0) { for (Method method : methods) { Scheduled annotation = method.getAnnotation(Scheduled.class); if (annotation != null) { corePoolSize++; } } if (defaultPoolSize > corePoolSize) { corePoolSize = defaultPoolSize; } } scheduledTaskRegistrar.setScheduler( Executors.newScheduledThreadPool(corePoolSize)); } }
以上是通过 JUC 的 Executors 四个主要的快捷创建线程池方法。为何 JUC 要提供工厂方法呢?原因是使用 ThreadPoolExecutor、ScheduledThreadPoolExecutor 构造器去创建普通线程池、可调度线程池比较复杂,这些构造器会涉及到大量的复杂参数。尽管 Executors 的工厂方法使用方便,但是在生产场景被很多企业(尤其是大厂)的开发规范所禁用。
线程池的标准创建方式
大部分企业的开发规范,都会禁止使用快捷线程池(具体原因稍后介绍),要求通过标准构造器 ThreadPoolExecutor 去构造工作线程池。实质上,Executors 工厂类中创建线程池的快捷工厂方法,实际上是调用了ThreadPoolExecutor(定时任务使用 ScheduledThreadPoolExecutor )线程池的构造方法完成的。ThreadPoolExecutor 构造方法有多个重载版本,其中一个比较重要的构造器如下:
// 使用标准构造器,构造一个普通的线程池
public ThreadPoolExecutor(
int corePoolSize, // 核心线程数,即使线程空闲(Idle),也不会回收;
int maximumPoolSize, // 线程数的上限;
long keepAliveTime, TimeUnit unit, // 线程最大空闲(Idle)时长
BlockingQueue<Runnable> workQueue, // 任务的排队队列
ThreadFactory threadFactory, // 新线程的产生方式
RejectedExecutionHandler handler) // 拒绝策略
很无奈,构造一个线程池竟然有 7 个参数,但是确实需要这么多参数。接下来对这些参数做一下具体介绍。
1. 核心和最大线程数量
参数 corePoolSize 用于设置核心(Core)线程池数量,参数 maximumPoolSize 用于设置最大
线程数量。线程池执行器将会根据 corePoolSize 和 maximumPoolSize 自动地维护线程池中的工作
线程,大致的规则为:
- (1)当在线程池接收到的新任务,并且当前工作线程数少于 corePoolSize 时,即使其他工作
线程处于空闲状态,也会创建一个新线程来处理该请求,直到线程数达到 corePoolSize。
- (2)如果当前工作线程数多于 corePoolSize 数量,但小于 maximumPoolSize 数量,则仅当
任务排队队列已满时,才会创建新线程。 通过设置 corePoolSize 和 maximumPoolSize 相同,可以
创建一个固定大小的线程池。
- (3)当 maximumPoolSize 被设置为无界值(如 Integer.MAX_VALUE)时,线程池可以接收
任意数量的并发任务。
- ( 4 ) corePoolSize 和 maximumPoolSize 不 仅 能 在 线 程 池 构 造 时 设 置 , 也 可 以 使 用
setCorePoolSize 和 setMaximumPoolSize 两个方法进行动态更改。
2. BlockingQueue
BlockingQueue(阻塞队列)的实例用于暂时接收到的异步任务,如果线程池的核心线程都在忙,则所接收到的目标任务,缓存在阻塞队列中。
3. keepAliveTime
线程构造器的 keepAliveTime(空闲线程存活时间)参数,用于设置池内线程最大 Idle(空闲)时长或者说保活时长,如果超过这个时间,默认情况下 Idle、非 Core 线程会被回收。
如果池在使用过程中,提交任务的频率变高,也可以使用方法 setKeepAliveTime(long,TimeUnit)进行线程存活时间的动态调整,可以时长延长。如果需要防止 Idle(空闲)线程被终止,可以将 Idle(空闲)时间设置为无限大,具体如下:
setKeepAliveTime(Long.MAX_VALUE,TimeUnit.NANOSECONDS);
默认情况下,Idle 超时策略仅适用于存在超过 corePoolSize 线程的情况。 但是如果调用了allowCoreThreadTimeOut(boolean)方法,并且传入了参数 true,则 keepAliveTime 参数所设置的 Idle 超时策略也将被应用于核心线程。
向线程池提交任务的两种方式
向线程池提交任务的两种方式,大致如下:
方式一:使用 execute 方法
//Executor 接口中的方法
void execute(Runnable command);
方式二:使用 submit 方法
//ExecutorService 接口中的方法
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
以上的 submit 和 execute 两类方法区别在哪里呢?两者的区别大致有三点:
- (1)二者所接受的参数不一样
execute 方法只能接收 Runnable 类型的参数,而 submit 方法可以接收 Callable、Runnable 两种类型的参数。Callable 类型的任务是可以返回执行结果的,而 Runnable 类型的任务是不可以返
回执行结果的。
Callable 是 JDK1.5 加入的执行目标接口,作为 Runnable 的一种补充,允许有返回值,允许抛出异常。Runnable 和 Callable 的主要区别如下:Callable 允许有返回值,Runnable 不允许有返回值;Runnable 不允许抛出异常,Callable 允许抛出异常。
- (2)submit 提交任务后会有返回值,而 execute 没有
execute 方法主要用于启动任务的执行,而任务的执行结果和可能的异常,调用者并不关心。而 submit 方法也用于启动任务的执行,但是启动之后会返回 Future 对象,代表一个异步执行实例,可以通过该异步执行实例去结果的获取。
- (3)submit 方便 Exception 处理
execute 方法在启动任务的执行后,任务执行过程中可能发生的异常,调用者并不关心。而通过 submit 方法所返回 Future 对象(异步执行实例),可以进行异步执行过程中的异常捕获。
1. 通过 submit 返回的 Future 对象获取结果
submit()方法自身并不会传递结果,而是返回一个 Future 异步执行实例,处理过程的结果被包装到 Future 实例中,调用者可以通过 Future.get()方法。通过 submit 返回的 Future 对象获取异步执行结果,演示代码如下:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { ...省略其他 //测试用例:获取异步调用的结果 @Test public void testSubmit2() { ScheduledExecutorService pool = Executors.newScheduledThreadPool(2); Future<Integer> future = pool.submit(new Callable<Integer>() { @Override public Integer call() throws Exception { //返回 200 - 300 之间的随机数 return RandomUtil.randInRange(200, 300); } }); try { Integer result = future.get(); Print.tco("异步执行的结果是:" + result); } catch (InterruptedException e) { Print.tco("异步调用被中断"); e.printStackTrace(); } catch (ExecutionException e) { Print.tco("异步调用过程中,发生了异常"); e.printStackTrace(); } sleepSeconds(10);
//关闭线程池
pool.shutdown();
}
}
运行以上程序,执行的结果如下:
[main]:异步执行的结果是:220
2. 通过 submit 返回的 Future 对象获取结果
submit()方法自身并不会传递异常,处理过程中的异常都被包装到 Future 实例中,调用者在使用 Future.get()方法获取执行结果时,可以捕获异步执行过程中的抛出的受检异常和运行时异常,并进行对应的业务处理。演示代码如下:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { //异步任务的执行目标类 static class TargetTask implements Runnable { ...为节约篇幅,省略重复内容 } //异步的执行目标类:执行过程中将发生异常 static class TargetTaskWithError extends TargetTask { public void run() { super.run(); throw new RuntimeException("Error from " + taskName); } } //测试用例:提交和执行 @Test public void testSubmit() { ScheduledExecutorService pool = Executors.newScheduledThreadPool(2); pool.execute(new TargetTaskWithError()); /** * submit(Runnable x) 返回一个 future */ Future future = pool.submit(new TargetTaskWithError()); try { //如果异常抛出,会在调用 Future.get()时传递给调用者 if (future.get() == null) { //如果 Future 的返回为 null,任务完成 Print.tco("任务完成"); } } catch (Exception e) { Print.tco(e.getCause().getMessage()); } sleepSeconds(10); //关闭线程池 pool.shutdown(); } ...省略其他 }
运行以上用例,执行结果如下:
[pool-1-thread-2]:任务:task-2 doing
[pool-1-thread-1]:任务:task-1 doing
[pool-1-thread-2]:task-2 运行结束.
[pool-1-thread-1]:task-1 运行结束.
[main]:Error from task-2
在 ThreadPoolExecutor 类的实现中,内部的最核心的任务提交方法是 execute()方法,虽然用户程序通过 submit 也可以提交任务,但是实际上 submit 方法里面最终调用的还是 execute()方法。
线程池的任务调度流程
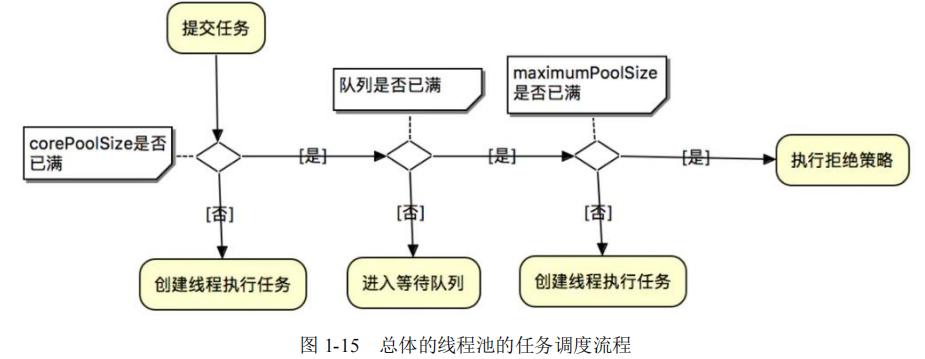
线程池的任务调度流程(包含接收新任务和执行下一个任务),大致如下:
- (1)如果当前工作线程数量小于核心线程池数量,执行器总是优先创建一个任务线程,而不是从线程队列中取一个空闲线程。
- (2)如果线程池中总的任务数量大于核心线程池数量,新接收的任务将被加入到阻塞队列中,一直到阻塞队列已满。在核心线程池数量已经用完、阻塞队列没有满的场景下,线程池不是为新任务创建一个新线程。
- (3)当完成一个任务的执行时,执行器总是优先从阻塞队列中取下一个任务,并开始其执行,一直到阻塞队列为空,其中所有的缓存任务被取光。
- (4)在核心线程池数量已经用完、阻塞队列也已经满了的场景下,如果线程池接收到新的任务,将会为新任务创建一个线程(非核心线程),并且立即开始执行新任务。
- (5)在核心线程都用完、阻塞队列已满的情况下,一直会创建新线程去执行新任务,直到池内的线程总数超出 maximumPoolSize。如果线程池的线程总数超时 maximumPoolSize,则线程池会拒绝接收任务,当新任务过来时,会为新任务执行拒绝策略。
总体的线程池的任务调度流程,大致如图 1-15 所示。
在创建线程池时,如果线程池的参数如核心线程数量、最大线程数量、BlockingQueue 等配置不合理,就会出现任务不能被正常调度的问题。
下面是一个错误的线程池配置示例:
标准线程池创建的错误案例:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { @org.junit.Test public void testThreadPoolExecutor() { ThreadPoolExecutor executor = new ThreadPoolExecutor( 1, //corePoolSize 100, //maximumPoolSize 100, //keepAliveTime 空闲保活时长 TimeUnit.SECONDS, //空闲保活时长的单位 new LinkedBlockingDeque<>(100));//workQueue //提交 5 个任务 for (int i = 0; i < 5; i++) { final int taskIndex = i; executor.execute(() -> { Print.tco("taskIndex = " + taskIndex); try { //极端测试:无限制睡眠 Thread.sleep(Long.MAX_VALUE); } catch (InterruptedException e) { e.printStackTrace(); } }); } while (true) { //每隔 1 秒,输出线程池的工作任务数量、总计的任务数量 Print.tco("- activeCount:" + executor.getActiveCount()+ " - taskCount:" + executor.getTaskCount()); sleepSeconds(1); } } ...省略其他 }
运行程序,结果如下:
[main]:- activeCount:1 - taskCount:5
[pool-1-thread-1]:taskIndex = 0
[main]:- activeCount:1 - taskCount:5
[main]:- activeCount:1 - taskCount:5
[main]:- activeCount:1 - taskCount:5
[main]:- activeCount:1 - taskCount:5
[main]:- activeCount:1 - taskCount:5
[main]:- activeCount:1 - taskCount:5
……
以上示例创建了最大线程数量 maximumPoolSize 为 100 的线程池,仅仅向其中提交了 5 个任务,理论上,这 5 个任务都会被执行到。奇怪的是:示例中仅仅 1 个任务在执行,其他的 4 个任务都在等待。其他任务被加入到了阻塞队列中,需要等 pool-1-thread-1 线程执行完成第一个任务后,才能依次从阻塞队列取出执行。可是,实例中的第一个任务是一个永远也没有办法完成的任务,所以其他的 4 个任务也只能永远在阻塞队列里边呆着。由于参数配置得不合理,就出现了以上的奇怪现象。
为什么会出现上面奇怪的现象呢? 因为例子中的 corePoolSize 为 1,阻塞队列的大小为 100,按照线程创建的规则,需要等阻塞队列已满,才会为去创建新的线程。例子中加入 5 个任务,阻
塞队列大小为 4(<100),所以线程池的调度器不会去创建新的线程,后面的 4 个任务只能等待。以上的示例,其目的是希望能传递两个知识点:
- (1)核心和最大线程数量、BlockingQueue 队列等参数,如果配置不合理,可以会造成异步任务得不到预期的并发执行,造成严重的排队等待现象。
- (2)线程池的调度器创建线程的一条重要的规则是:在 corePoolSize 已满之后,还需要等阻塞队列已满,才会为去创建新的线程。
ThreadFactory 线程工厂
ThreadFactory是java线程工厂接口,这是一个非常简单的接口,具体如下:
package java.util.concurrent; public interface ThreadFactory { //唯一的方法:创建一条新线程 Thread newThread(Runnable target); }
在使用ThreadFactory的唯一方法newThread()创建新线程时,可以更改所创建新线程的名称、线程组、优先级、守护进程状态等。如果newThread()返回值为null,表示线程工厂未能成功创建线程,则线程池可能无法执行任何任务。
使用Executors创建新的线程池时,也可以基于ThreadFactory(线程工厂)创建,在创建新线程池时可以指定将使用的ThreadFactory实例。只不过,如果没有指定的话,则会使用Executors.defaultThreadFactory默认实例。使用默认的线程工厂实例所创建的线程,全部位于同一个ThreadGroup(线程组)中,具有相同的 NORM_PRIORITY(优先级为 5),而且都是非守护进程状态。
说明:这里提到了两个工厂类,比较容易混淆,故做出说明。Executors 为线程池工厂类,用于快捷创建线程池(Thread Pool);ThreadFactory 为线程工厂类,用于创建线程(Thread)。
基于自定义的 ThreadFactory 实例创建线程池,首先需要实现一个 ThreadFactory 实现类,实现其唯一的抽象方法 newThread(Runnable)。下面的例子,首先现一个简单的线程工厂,然后基于该线程工厂快捷创建线程池,具体的代码如下:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { //一个简单的线程工厂 static public class SimpleThreadFactory implements ThreadFactory { static AtomicInteger threadNo = new AtomicInteger(1); //实现其唯一的创建线程方法 @Override public Thread newThread(Runnable target) { String threadName = "simpleThread-" + threadNo.get(); Print.tco("创建一条线程,名称为:" + threadName); threadNo.incrementAndGet(); //设置线程名称,和异步执行目标 Thread thread = new Thread(target,threadName); //设置为守护线程 thread.setDaemon(true); return thread; } } //线程工厂的测试用例 @org.junit.Test public void testThreadFactory() { //使用自定义线程工厂,快捷创建一个固定大小线程池 ExecutorService pool = Executors.newFixedThreadPool(2,new SimpleThreadFactory()); for (int i = 0; i < 5; i++) { pool.submit(new TargetTask()); } //等待 10 秒 sleepSeconds(10); Print.tco("关闭线程池"); pool.shutdown(); } ...省略其他 }
运行以上代码,其输出如下:
[main]:创建一条线程,名称为:simpleThread-1
[main]:创建一条线程,名称为:simpleThread-2
[simpleThread-1]:任务:task-1 doing
[simpleThread-2]:任务:task-2 doing
[simpleThread-1]:task-1 运行结束.
[simpleThread-1]:任务:task-3 doing
[simpleThread-2]:task-2 运行结束.
[simpleThread-2]:任务:task-4 doing
[simpleThread-2]:task-4 运行结束.
[simpleThread-1]:task-3 运行结束.
[simpleThread-2]:任务:task-5 doing
[simpleThread-2]:task-5 运行结束.
[main]:关闭线程池
从结果输出看到,新建池中的线程名称,都不是默认的 pool-1-thread-1 形式,是线程工厂所
更改后的形式。
任务阻塞队列
Java 中的阻塞队列(BlockingQueue)与普通队列相比,有一个重要的特点:在阻塞队列为空时,会阻塞当前线程的元素获取操作。具体来说,在一个线程从一个空的阻塞队列中取元素时,线程会被阻塞,直到阻塞队列中有了元素;当队列中有元素后,被阻塞的线程会自动被唤醒(唤醒过程不需要用户程序干预)。
Java 线程池使用 BlockingQueue 实例暂时接收到的异步任务,BlockingQueue 是 JUC 包的一
个超级接口,比较常用的实现类有:
- (1)ArrayBlockingQueue:是一个数组实现的有界阻塞队列 (有界队列),队列中元素按 FIFO排序;ArrayBlockingQueue 在创建时必须设置大小,接收的任务超出 corePoolSize 数量时,则任务被缓存到该阻塞队列中,任务缓存的数量只能为创建时设置的大小;若该阻塞队列满,则会为新的任务则创建线程,直到线程池中的线程总数> maximumPoolSize。
- (2)LinkedBlockingQueue:是一个基于链表实现的阻塞队列,按 FIFO 排序任务,可以设置容量(有界队列),不设置容量则默认使用 Integer.Max_VALUE 作为容量 (无界队列)。该队列的吞吐量高于 ArrayBlockingQueue。如果不设置 LinkedBlockingQueue 的容量(无界队列),当接收的任务数量超出 corePoolSize数量时,则新任务可以被无限制地缓存到该阻塞队列中,直到资源耗尽。有两个快捷创建线程池的工厂方法 Executors.newSingleThreadExecutor、Executors.newFixedThreadPool,使用了这个队列,并且都没有设置容量(无界队列)。
- (3)PriorityBlockingQueue:是具有优先级的无界队列。
- (4)DelayQueue:这是一个无界阻塞延迟队列,底层基于 PriorityBlockingQueue 实现的,队列中每个元素都有过期时间,当从队列获取元素(元素出队)时,只有已经过期的元素才会出队,而队列头部的元素是过期最快的元素。快捷工厂方法 Executors.newScheduledThreadPool 所创建的线程池使用此队列。
- (5)SynchronousQueue:(同步队列) 是一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程的调用移除操作,否则插入操作一直处于阻塞状态,其吞吐量通常高于LinkedBlockingQueue。 快捷工厂方法 Executors.newCachedThreadPool 所创建的线程池使用此队列。与前面的队列相比,这个队列比较特殊,它不会保存提交的任务,而是将直接新建一个线程来执行新来的任务。
调度器的钩子方法
ThreadPoolExecutor 线 程 池 调 度 器 为 每 个 任 务 执 行 前 后 , 都 提 供 了 钩 子 方 法 。ThreadPoolExecutor 类提供了三个钩子方法(空方法),这三个空方法一般用作被子类重写,具
体如下:
//任务执行之前的钩子方法(前钩子) protected void beforeExecute(Thread t, Runnable r) { } //任务执行之后的钩子方法(后钩子) protected void afterExecute(Runnable r, Throwable t) { } //线程池终止时的钩子方法(停止钩子) protected void terminated() { }
(1)beforeExecute:异步任务执行之前的钩子方法
线程池工作线程在异步执行完成的目标实例(如 Runnable 实例)前,调用此钩子方法。此方法仍然由执行任务的工作线程调用。默认实现不执行任何操作,但可以在子类中对其进行自定义。此方法由执行目标实例的工作线程调用,可用于重新初始化 ThreadLocal 线程本地变量实例、更新日志记录、开始计时统计、更新上下文变量等等。
(2)afterExecute:异步任务执行之后的钩子方法
线程池工作线程在异步执行完成的目标实例后,调用此钩子方法。此方法仍然由执行任务的工作线程调用。此钩子方法的默认实现不执行任何操作,可以在调度器子类中对其进行自定义。此方法由执行目标实例的工作线程调用,可用于清除 ThreadLocal 线程本地变量、更新日志
记录、收集统计信息、更新上下文变量等等。
(3)terminated:线程池终止时的钩子方法terminated 钩子方法在 Executor 终止时调用,默认实现不执行任何操作。
说明:beforeExecute 和 afterExecute 两个方法在每个任务执行前后被调用,如果钩子(回调方法)引发异常,内部工作线程可能进而失败并突然终止。


为线程池定制钩子方法的示例,具体代码如下:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { @org.junit.Test public void testHooks() { ExecutorService pool = new ThreadPoolExecutor(2, //coreSize 4, //最大线程数 60,//空闲保活时长 TimeUnit.SECONDS, new LinkedBlockingQueue<>(2)) //等待队列 { //继承:调度器终止钩子 @Override protected void terminated() { Print.tco("调度器已经终止!"); } //继承:执行前钩子 @Override protected void beforeExecute(Thread t, Runnable target) { Print.tco( target +"前钩被执行"); //记录开始执行时间 startTime.set(System.currentTimeMillis()); super.beforeExecute(t, target); } //继承:执行后钩子 @Override protected void afterExecute(Runnable target, Throwable t) { super.afterExecute(target, t); //计算执行时长 long time = (System.currentTimeMillis() - startTime.get()) ; Print.tco( target + " 后钩被执行, 任务执行时长(ms):" + time); //清空本地变量 startTime.remove(); } }; for (int i = 1; i <= 5; i++) { pool.execute(new TargetTask()); } //等待 10 秒 sleepSeconds(10); Print.tco("关闭线程池"); pool.shutdown(); } ......省略其他 }
运行以上示例代码,输出的结果如下:
[pool-1-thread-3]:TargetTask{task-5}前钩被执行
[pool-1-thread-1]:TargetTask{task-1}前钩被执行
[pool-1-thread-2]:TargetTask{task-2}前钩被执行
[pool-1-thread-2]:任务:task-2 doing
[pool-1-thread-1]:任务:task-1 doing
[pool-1-thread-3]:任务:task-5 doing
[pool-1-thread-3]:task-5 运行结束.
[pool-1-thread-2]:task-2 运行结束.
......
[pool-1-thread-3]:TargetTask{task-4} 后钩被执行, 任务执行时长(ms):515
[main]:关闭线程池
[pool-1-thread-3]:调度器已经终止!
示例代码在 beforeExecute(前钩子)方法中,通过 startTime 线程局部变量暂存了异步目标任务(如 Runnable 实例)的开始执行时间(起始时间);在 afterExecute(后钩子)方法中,通过startTime 线程局部变量获取了之前暂存的起始时间,然后计算与系统当前时间(结束时间)之间
的时间差,从而得出异步目标任务的执行时长。
线程池的拒绝策略
在线程池的任务缓存队列为有界队列(有容量限制的队列)的时候,如果队列满了,提交任务到线程池的时候就会被拒绝。总体来说,任务被拒绝有两种情况:
- (1)线程池已经被关闭。
- (2)工作队列已满且 maximumPoolSize 已满。
无 论 以 上 哪 种 情 况 任 务 被 拒 , 线 程 池 都 会 调 用 RejectedExecutionHandler 实 例 的rejectedExecution 方法。RejectedExecutionHandler 是拒绝策略的接口,JUC 为该接口提供了以下几种实现:
- AbortPolicy:拒绝策略
- DiscardPolicy:抛弃策略
- DiscardOldestPolicy:抛弃最老任务策略
- CallerRunsPolicy:调用者执行策略
- 自定义策略
JUC 线程池拒绝策略的接口与类之间的关系图,具体如图 1-16 所示。
- (1)AbortPolicy
使用该策略时,如果线程池队列满了则新任务被拒绝,并且会抛出 RejectedExecutionException异常。该策略是线程池的默认的拒绝策略。
- (2)DiscardPolicy
该策略是 AbortPolicy 的 Silent(安静)版本,如果线程池队列满了,新任务会直接被丢掉,并且不会有任何异常抛出。
- (3)DiscardOldestPolicy
抛弃最老任务策略,也就是说如果队列满了,会将最早进入队列的任务抛弃,从队列中腾出空间,再尝试加入队列。因为队列是队尾进队头出,队头元素是最老的,所以每次都是移除对头元素后再尝试入队。
- (4)CallerRunsPolicy
调用者执行策略。在新任务被添加到线程池时,如果添加失败,那么提交任务线程会自己去执行该任务,不会使用线程池中的线程去执行新任务。在以上的四种内置策略中,线程池默认的拒绝策略为 AbortPolicy,如果提交的任务被拒绝,
线程池抛出 RejectedExecutionException 异常,该异常是非受检异常(运行时异常),很容易忘记捕获。如果关心任务被拒绝的事件,需要在提交任务时捕获 RejectedExecutionException 异常。
- (5)自定义策略
如果以上拒绝策略都不符合需求,则可自定义一个拒绝策略,实现 RejectedExecutionHandler接口的 rejectedExecution 方法即可。
下面给出一个自定义拒绝策略的例子,代码如下:
自定义拒绝策略的标准线程池创建:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { //一个简单的线程工厂 static public class SimpleThreadFactory implements ThreadFactory { ...为节约篇幅,省略重复内容 } //自定义拒绝策略 public static class CustomIgnorePolicy implements RejectedExecutionHandler { public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { // 可做日志记录等 Print.tco(r + " rejected; " + " - getTaskCount: " + e.getTaskCount()); } } @org.junit.Test public void testCustomIgnorePolicy() { int corePoolSize = 2; //核心线程数 int maximumPoolSize = 4; //最大线程数 long keepAliveTime = 10; TimeUnit unit = TimeUnit.SECONDS; //最大排队任务数 BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2); //线程工厂 ThreadFactory threadFactory = new SimpleThreadFactory(); //拒绝和异常处理策略 RejectedExecutionHandler policy = new CustomIgnorePolicy(); ThreadPoolExecutor pool = new ThreadPoolExecutor( corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, policy); // 预启动所有核心线程 pool.prestartAllCoreThreads(); for (int i = 1; i <= 10; i++) { pool.execute(new TargetTask()); } //等待 10 秒 sleepSeconds(10); Print.tco("关闭线程池"); pool.shutdown(); } ...省略其他 }
运行以上代码,大致结果如下:
[main]:创建一条线程,名称为:simpleThread-1
[main]:创建一条线程,名称为:simpleThread-2
[main]:创建一条线程,名称为:simpleThread-3
[simpleThread-1]:任务:task-1 doing
[simpleThread-2]:任务:task-2 doing
[main]:创建一条线程,名称为:simpleThread-4
[simpleThread-3]:任务:task-3 doing
[simpleThread-4]:任务:task-6 doing
[main]:TargetTask{task-7} rejected; - getTaskCount: 6
[main]:TargetTask{task-8} rejected; - getTaskCount: 6
[main]:TargetTask{task-9} rejected; - getTaskCount: 6
[main]:TargetTask{task-10} rejected; - getTaskCount: 6
[simpleThread-1]:task-1 运行结束.
[simpleThread-2]:task-2 运行结束.
[simpleThread-1]:任务:task-4 doing
[simpleThread-2]:任务:task-5 doing
[simpleThread-2]:task-5 运行结束.
[simpleThread-4]:task-6 运行结束.
[simpleThread-3]:task-3 运行结束.
[simpleThread-1]:task-4 运行结束.
[main]:关闭线程池
线程池的优雅关闭
一般情况下,线程池启动后建议手动关闭。在介绍线线程池的优雅关闭之前,我们先了解一下线程池状态。线程池总共存在 5 种状态,定义在 ThreadPoolExecutor 类中,具体代码如下:
package java.util.concurrent; ...省略 import public class ThreadPoolExecutor extends AbstractExecutorService { // runState is stored in the high-order bits private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS; …省略其他 }
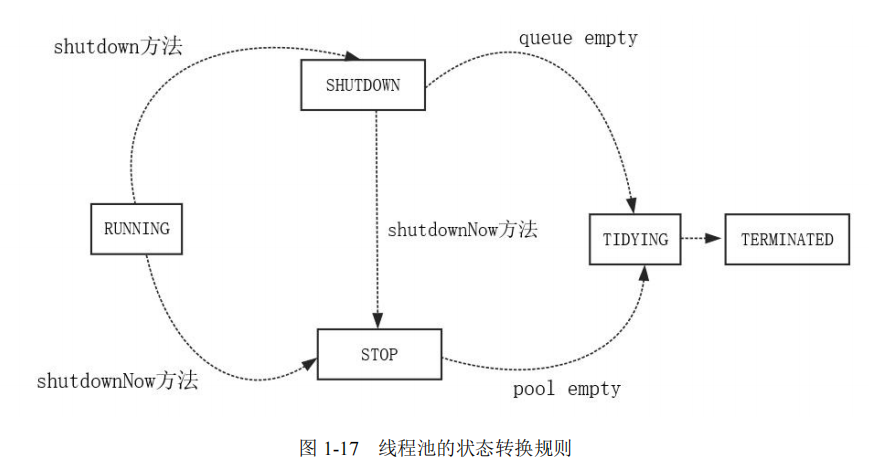
线程池的 5 种状态,具体如下:
- (1)RUNNING:线程池创建之后的初始状态,这种状态下可以执行任务。
- (2)SHUTDOWN:该状态下线程池不再接受新任务,但是会将工作队列中的任务执行完毕。
- (3)STOP:该状态下线程池不再接受新任务,也不会处理工作队列中的剩余任务,并且将会中断所有工作线程。
- (4)TIDYING:该状态下所有任务都已终止或者处理完成,将会执行terminated( )钩子方法。
- (5)TERMINATED:执行完terminated( )钩子方法之后的状态。
线程池的状态转换规则为:
- (1)线程池创建之后状态为 RUNNING。
- (2)执行线程池的 shutdown 实例方法,会使线程池状态从 RUNNING 转变为 SHUTDOWN。
- (3)执行线程池的 shutdownNow 实例方法,会使线程池状态从 RUNNING 转变为 STOP。
- (4)当线程池处于 SHUTDOWN 状态,执行器 shutdownNow 方法,会将其状态转变为 STOP状态。
- (5)等待线程池的所有工作线程停止,工作队列清空之后,线程池状态会从 STOP 转变为TIDYING。
- (6)执行完 terminated( ) 钩子方法之后,线程池状态从 TIDYING 转变为 TERMINATED 。
线程池的状态之间的转换规则,具体如图 1-17 所示。
优雅关闭线程池主要涉及到的方法有 3 个:
- (1)shutdown:是 JUC 提供一个有序关闭线程池的方法,此方法会等待当前工作队列中的剩余任务全部执行完成之后,才会执行关闭,但是此方法被调用之后线程池的状态转为SHUTDOWN,线程池不会再接收新的任务。
- (2)shutdownNow:是 JUC 提供一个立即关闭线程池的方法,此方法会打断正在执行的工作线程,并且会清空当前工作队列中的剩余任务,返回的是尚未执行的任务。
- (3)awaitTermination:等待线程池完成关闭。在调用线程池的 shutdown 与 shutdownNow 方法时,用于程序会立即返回,不会一直等待直到线程池完成关闭。如果需要等到线程池关闭完成,可以调用 awaitTermination 方法。
1. shutdown 方法原理
shutdown 方法的源码大致如下:
public void shutdown()
{
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try
{
// 检查权限
checkShutdownAccess();
// 设置线程池状态
advanceRunState(SHUTDOWN);
// 中断空闲线程
interruptIdleWorkers();
// 钩子函数,主要用于清理一些资源
onShutdown();
} finally
{
mainLock.unlock();
}
tryTerminate();
}
shutdown 方法首先加锁,其次检查调用者是否用于执行线程池关闭的 Java Security 权限。接着就 shutdown 方法会将线程池状态变为 SHUTDOWN,在这之后线程池不再接受提交的新任务。
此时如果还继续往线程池提交任务,将会使用线程池拒绝策略响应,默认的拒绝策略将会使用ThreadPoolExecutor.AbortPolicy,接收新任务时会抛出 RejectedExecutionException 异常。
2. shutdownNow 方法原理
shutdownNow 方法的源码大致如下:
public List<Runnable> shutdownNow()
{
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try
{
// 检查状态
checkShutdownAccess();
// 将线程池状态变为 STOP
advanceRunState(STOP);
// 中断所有线程,包括工作线程以及空闲线程
interruptWorkers();
// 丢弃工作队列中剩余任务
tasks = drainQueue();
} finally
{
mainLock.unlock();
}
tryTerminate();
return tasks;
}
shutdownNow 方法将会把线程池状态设置为 STOP,然后中断所有线程(包括工作线程以及空闲线程),最后清空工作队列中,取出工作队列所有未完成的任务返回给调用者。与有序的shutdown 方法相比,shutdownNow 方法比较粗暴,直接中断工作线程。不过这里需要注意,中
断线程并不代表线程立刻结束,只是通过工作线程的 interrupt()实例方法设置了中断状态,这里需要用户程序主动配合线程进行中断操作。
3. awaitTermination 方法的使用
调用了线程池 shutdown与 shutdownNow方法之后,用户程序都不会主动等待线程池关闭完成,如果需要等到线程池完成关闭,需要调用awaitTermination进行主动等待。调用方法大致如下:
threadPool.shutdown(); try { //一直等待,直到线程池完成关闭 while (!threadPool.awaitTermination(60,TimeUnit.SECONDS)){ System.out.println("线程池任务还未执行结束"); } } catch (InterruptedException e) { e.printStackTrace(); }
如果线程池完成关闭,awaitTermination 方法将会返回 true,否则当等待时间超过指定时间后将会返回 false。如果需要使用 awaitTermination,建议不是永久等待,而是设置一定重试次数。下面的代码,参考了 Dubbo 框架的线程池关闭源码中的部分代码,
具体如下:
if(!threadPool.isTerminated()) { try { for (int i = 0; i < 1000; i++) //循环关闭 1000 次,每次等待 10 毫秒 { if (threadPool.awaitTermination(10, TimeUnit.MILLISECONDS)) { break; } threadPool.shutdownNow(); } } catch (InterruptedException e) { System.err.println(e.getMessage()); } catch (Throwable e) { System.err.println(e.getMessage()); } }
4. 优雅关闭线程池
大家可以结合 shutdown、shutdownNow、awaitTermination 三个方法去优雅关闭一个线程池,
大致分为以下几步:
- (1)执行 shutdown 方法,拒绝新任务的提交,并等待所有任务有序执行完毕。
- (2)执行 awaitTermination(long timeout,TimeUnit unit)方法,指定超时时间,判断是否已
经关闭所有任务,线程池关闭完成。
- (3)如果 awaitTermination 方法返回 fasle,或者被中断。调用 shutDownNow 方法立即关闭
线程池所有任务。
- (4)补充执行 awaitTermination(long timeout,TimeUnit unit)方法,判断线程池是否关闭完
成。如果超时,则可以进入循环关闭,循环一定的次数(如 1000 次),不断关闭线程池,直到
其关闭或者循环结束。
优雅关闭线程池的参考代码,具体如下:
package com.crazymakercircle.util; ...省略 import public class ThreadUtil { public static void shutdownThreadPoolGracefully( ExecutorService threadPool) { //已经关闭则返回 if (!(threadPool instanceof ExecutorService) || threadPool.isTerminated()) { return; } try { threadPool.shutdown(); //拒绝接受新任务 } catch (SecurityException e) { return; } catch (NullPointerException e) { return; } try { // 等待 60 s,等待线程池中的任务完成执行 if (!threadPool.awaitTermination(60, TimeUnit.SECONDS)) { // 调用 shutdownNow 取消正在执行的任务 threadPool.shutdownNow(); // 再次等待 60 s,如果还未结束,可以再次尝试,或则直接放弃 if (!threadPool.awaitTermination(60, TimeUnit.SECONDS)) { System.err.println("线程池任务未正常执行结束"); } } } catch (InterruptedException ie) { // 捕获异常,重新调用 shutdownNow threadPool.shutdownNow(); } //仍然没有关闭,循环关闭 1000 次,每次等待 10 毫秒 if (!threadPool.isTerminated()) { try { for (int i = 0; i < 1000; i++) { if (threadPool.awaitTermination(10,TimeUnit.MILLISECONDS)) { break; } threadPool.shutdownNow(); } } catch (InterruptedException e) { System.err.println(e.getMessage()); } catch (Throwable e) { System.err.println(e.getMessage()); } } } …省略不相干代码 }
5. 注册 JVM 钩子函数自动关闭线程池
如果使用了线程池,可以在 JVM 注册一个钩子函数,在 JVM 进程关闭之前,由钩子函数自动将线程池优雅关闭,以确保资源正常释放。下面的例子,使用 JVM 钩子函数关闭了一个定义在随书源码的 ThreadUtil 辅助类中用于执行定时、顺序任务的线程池,
具体代码如下:
package com.crazymakercircle.util; ...省略 import public class ThreadUtil { //懒汉式单例创建线程池:用于执行定时、顺序任务 static class SeqOrScheduledTargetThreadPoolLazyHolder { //线程池:用于定时任务、顺序排队执行任务 static final ScheduledThreadPoolExecutor EXECUTOR = new ScheduledThreadPoolExecutor( 1, new CustomThreadFactory("seq")); static { //注册 JVM 关闭时的钩子函数 Runtime.getRuntime().addShutdownHook( new ShutdownHookThread("定时和顺序任务线程池", new Callable<Void>() { @Override public Void call() throws Exception { //优雅关闭线程池 shutdownThreadPoolGracefully(EXECUTOR); return null; } })); } } ...省略不相干代码 }
Executors 快捷创建线程池的潜在问题
在很多公司(如阿里、华为等)的编程规范中,非常明确的禁止使用 Executors 快捷创建线程池,为什么呢?这里从源码讲起,介绍一下使用 Executors 工厂方法快捷创建线程池将会面临的潜在问题。
1. 使用 Executors 创建“固定数量的线程池”的潜在问题
使用 newFixedThreadPool 工厂方法“固定数量的线程池”的源码如下:
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor( nThreads,// 核心线程数 nThreads,// 最大线程数 0L,// 线程最大空闲(Idle)时长 TimeUnit.MILLISECONDS,//时间单位:毫秒 new LinkedBlockingQueue<Runnable>()//任务的排队队列,无界队列 ); }
newFixedThreadPool工厂方法返回一个ThreadPoolExecutor实例,该线程池实例的corePoolSize数量为参数 nThread,其 maximumPoolSize 数量也为参数 nThread,其 workQueue 属性的值为LinkedBlockingQueue<Runnable>() 无界阻塞队列。
使用Executors创建的“固定数量的线程池”的潜在问题主要存在于其workQueue 上,其值为LinkedBlockingQueue(无界阻塞队列)。如果任务提交速度持续大于任务处理速度,会造成队列中大量的任务等待。如果队列很大,很有可能导致JVM出现OOM异常,甚至造成内存资源耗尽。
2. 使用 Executors 创建“单线程化线程池”的潜在问题
使用 newSingleThreadExecutor 工厂方法“单线程化线程池”的源码如下:
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor( 1,// 核心线程数 1,// 最大线程数 0L,// 线程最大空闲(Idle)时长 TimeUnit.MILLISECONDS, //时间单位:毫秒 new LinkedBlockingQueue<Runnable>()//无界队列 )); }
以上代码首先通过调用工厂方法 newFixedThreadPool(1)创建一个数量为 1 的“固定大小线程
池”,然后,使用 FinalizableDelegatedExecutorService 对该“固定大小线程池”进行包装,这一
层包装的作用,就是防止线程池的 corePoolSize 被动态的修改。
为了演示“单线程化线程池”的 corePoolSize 始终保持为 1 而不能被修改,接下来首先使用
newSingleThreadExecutor()工厂方法创建一个“单线程化线程池”,然后企图修改其 corePoolSize
属性,具体的代码如下:
@org.junit.Test public void testNewFixedThreadPool2() { //创建一个固定大小线程池 ExecutorService fixedExecutorService = Executors.newFixedThreadPool(1); ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) fixedExecutorService; Print.tco(threadPoolExecutor.getMaximumPoolSize()); //设置核心线程数 threadPoolExecutor.setCorePoolSize(8); //创建一个单线程化的线程池 ExecutorService singleExecutorService = Executors.newSingleThreadExecutor(); //转换成普通线程池, 会抛出运行时异常 java.lang.ClassCastException ((ThreadPoolExecutor) singleExecutorService).setCorePoolSize(8); }
以上代码在运行时会抛出异常。观察所抛出的异常,可以知道 FinalizableDelegatedExecutorService实例无法被转型为 ThreadPoolExecutor 类型,所以也就无法修改其 corePoolSize 属性,从而确保“单线程化线程池”在运行过程中 corePoolSize 不会被调整,其线程数始终唯一,做到了真正的
Single 。 反 过 来 说 , 如 果 没 有 被 FinalizableDelegatedExecutorService 包 装 , 原 始 的ThreadPoolExecutor 实例是可以动态调整 corePoolSize 属性的。
使用 Executors 创建的“单线程化线程池”与“固定大小线程池”一样,其潜在问题仍然存在与其 workQueue 属性上,该属性的值为 LinkedBlockingQueue(无界阻塞队列)。如果任务提交速度持续大于任务处理速度,会造成队列大量阻塞。如果队列很大,很有可能导致 JVM 的 OOM
异常,甚至造成内存资源耗尽。
3. 使用 Executors 创建“可缓存线程池”的潜在问题
使用 newCachedThreadPool 工厂方法“可缓存线程池”的源码如下:
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor( 0, // 核心线程数 Integer.MAX_VALUE, // 最大线程数 60L, // 线程最大空闲(Idle)时长 TimeUnit.MILLISECONDS, //时间单位:毫秒 new SynchronousQueue<Runnable>() //任务的排队队列,无界队列 ); }
以上代码通过调用 ThreadPoolExecutor 标准构造器创建一个核心线程数为 0、最大线程数不设限制的线程池。所以,理论上“可缓存线程池”可以拥有无数个工作线程,即线程数量几乎无限制。“可缓存线程池”的 workQueue 为 SynchronousQueue 同步队列,这个队列类似于一个接力
棒,入队出队必须同时传递,正因为“可缓存线程池”可以无限制创建线程,不会有任务等待,所以才使用 SynchronousQueue。
当“可缓存线程池”有新任务到来时,新任务会被插入到 SynchronousQueue 实例中,由于SynchronousQueue 是同步队列,因此会在池中寻找可用线程来执行,若有可以线程则执行,若没有可用线程,则线程池会创建一个线程来执行该任务。
SynchronousQueue 是一个比较特殊的阻塞队列实现类, SynchronousQueue 没有容量,每一个插入操作都要等待对应的删除操作,反之一个删除操作都要等待对应的插入操作。也就是说,如果使用 SynchronousQueue,提交的任务不会被真实保存,而是将新任务交给空闲线程执行,如
果没有空闲线程,则创建线程,如果线程数都已经大于最大线程数,则执行拒绝策略。使用这种队列,需要将 maximumPoolSize 设置的非常大,从而使得新任务不会被拒绝。
使用 Executors 创建的“可缓存线程池”的潜在问题,存在于其最大线程数量不设限上。由于其 maximumPoolSize 的值为 Integer.MAX_VALUE 非常大,可以认为是可以无限创建线程的,如果任务提交较多,会造成大量的大量线程被启动,很有可能造成 OOM 异常,甚至导致 CPU 线
程资源耗尽。
4. 使用 Executors 创建“可调度线程池”的潜在问题
使用 newScheduledThreadPool 工厂方法“可调度线程池”的源码如下:
public static ScheduledExecutorService newScheduledThreadPool( int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); }
Executors 的 newScheduledThreadPool 工厂方法调用了 ScheduledThreadPoolExecutor 实现类的构造方法,而 ScheduledThreadPoolExecutor 继承了 ThreadPoolExecutor 普通线程池类,在其构造内部进一步调用了该父类的构造方法,具体的代码如下:
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, // 核心线程数 Integer.MAX_VALUE, // 最大线程数 0, // 线程最大空闲(Idle)时长 NANOSECONDS,//时间单位 new DelayedWorkQueue() //任务的排队队列 ); }
以 上 代 码 创 建 一 个 ThreadPoolExecutor 实 例 : 其 corePoolSize 为 传 递 来 的 参 数 ,maximumPoolSize 为 Integer.MAX_VALUE 表 示 线 程 数 不 设 上 限 , 其 workQueue 为 一 个DelayedWorkQueue 实例,这是一个按到期时间升序排序的阻塞队列。
使用 Executors 创建的“可缓存线程池”的潜在问题,存在于其最大线程数量不设限上。由于其线程数量不设限制,如果到期任务太多就会导致的 CPU 的线程资源耗尽。
以上的内容分别梳理了 Executors 四个工厂方法所创建的线程池将面临的潜在问题。总结起来,使用 Executors 去创建线程池,其主要的弊端如下:
(1)FixedThreadPool 和 SingleThreadPool:
这两工厂方法所创建的线程池,工作队列(任务排队的队列)长度都为 Integer.MAX_VALUE,可能会堆积大量的任务,从而导致 OOM 甚至耗尽内存资源;
(2)CachedThreadPool 和 ScheduledThreadPool :
这两工厂方法所创建的线程池,允许创建的线程数量为 Integer.MAX_VALUE,可能会导致创建大量的线程,从而导致 OOM 甚至耗尽 CPU 资源。虽然 Executors 工厂类提供了构造线程池的便捷方法,但是对于服务器程序而言,大家应该杜
绝使用这些便捷方法,而是直接使用线程池 ThreadPoolExecutor 的构造方法,从而有效避免由于使用无界队列可能导致的内存资源耗尽,或者由于对线程个数不做限制而导致的 CPU 资源耗尽等问题。
所以,大厂的编程规范都不允许使用 Executors 去创建线程池,而是要求使用标准构造器ThreadPoolExecutor 去创建线程池。
确定线程池的线程数
使用线程池的好处主要有以下三点:
- (1)降低资源消耗:线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,通过重复利用已创建的线程,可以降低线程创建和销毁造成的消耗。
- (2)提高响应速度:当任务到达时,可以不需要等待线程创建就能立即执行。
- (3)提高线程的可管理性:线程池提供了一种限制、管理资源的策略,维护一些基本的线程统计信息,如已完成任务的数量等。通过线程池可以对线程资源进行统一的分配,监控和调优。虽然使用线程池的好处很多,但是如果其线程数配置不合理,不仅可能达不到预期效果,反
而可能降低应用的性能。
按照任务类型对线程池进行分类
使用标准构造器 ThreadPoolExecutor 去创建线程池线程池时,会涉及到线程数的配置,而线程数的配置与异步任务类型是分不开的。这里将线程池的异步任务大致分为以下三类:
- (1)IO 密集型任务
此类任务主要是执行 IO 操作。由于执行 IO 操作的时间较长,导致 CPU 的利用率不高,这类任务 CPU 常处于空闲状态。Netty 的 IO 读写操作,为此类任务的典型例子。
- (2)CPU 密集型任务
此类任务主要是执行计算任务。由于响应时间很快,CPU 一直在运行,这种任务 CPU 的利用率很高。
- (3)混合型任务
此类任务既要执行逻辑计算,又要进行 IO 操作(如 RPC 调用、数据库访问)。相对来说由于执行 IO 操作的耗时较长(一次网络往返往往在数百毫秒级别),这类任务 CPU 利用率也不是太高。Web 服务器的 HTTP 请求处理操作,为此类任务的典型例子。
一般情况下,针对以上不同类型的异步任务,需要创建不同类型的线程池,并进行针对性的参数配置。
为 IO 密集型任务确定线程数
由于 IO 密集型任务的 CPU 使用率较低,导致线程空余时间很多,所以通常就需要开 CPU核心数两倍的线程。当 IO 线程空闲时,可以启用其他线程继续使用 CPU,以提高 CPU 的使用率。
Netty 的 IO 处理任务,就是典型的 IO 密集型任务。所以,Netty 的 Reactor 反应器实现类(定制版的线程池)的 IO 处理线程数,默认正好为 CPU 核数的 2 倍,以下是其相关的代码:
//多线程版本 Reactor 反应器组 public abstract class MultithreadEventLoopGroup extends MultithreadEventExecutorGroup implements EventLoopGroup { //IO 事件处理线程数,反应器数量 private static final int DEFAULT_EVENT_LOOP_THREADS; //IO 事件处理线程数默认值:CPU 核数的 2 倍 static { DEFAULT_EVENT_LOOP_THREADS = Math.max(1, SystemPropertyUtil.getInt("io.netty.eventLoopThreads", Runtime.getRuntime().availableProcessors() * 2)); } /** *构造器 */ protected MultithreadEventLoopGroup(int nThreads, ThreadFactory threadFactory, Object... args) { super(nThreads == 0? DEFAULT_EVENT_LOOP_THREADS : nThreads, threadFactory, args); } ...省略其他 }
说明:Netty 是基于 Java 实现的高性能传输框架,基于 Reactor 模式实现,是目前非常火热的高性能传输中间件,在大量的著名框架中被使用,也是 Java 工程师、架构师必知必会的基础框架。
本书的在随书源码的 ThreadUtil 类中,为 IO 密集型任务的创建了一个简单的参考线程池,
具体代码如下:
package com.crazymakercircle.util; ...省略 import public class ThreadUtil { //CPU 核数 private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors(); //IO 处理线程数 private static final int IO_MAX = Math.max(2, CPU_COUNT * 2); /** * 空闲保活时限,单位秒 */ private static final int KEEP_ALIVE_SECONDS = 30; /** * 有界队列 size */ private static final int QUEUE_SIZE = 128; //懒汉式单例创建线程池:用于 IO 密集型任务 private static class IoIntenseTargetThreadPoolLazyHolder { //线程池: 用于 IO 密集型任务 private static final ThreadPoolExecutor EXECUTOR = new ThreadPoolExecutor( IO_MAX, //CPU 核数*2 IO_MAX, //CPU 核数*2 KEEP_ALIVE_SECONDS, TimeUnit.SECONDS, new LinkedBlockingQueue(QUEUE_SIZE), new CustomThreadFactory("io")); static { EXECUTOR.allowCoreThreadTimeOut(true); //JVM 关闭时的钩子函数 Runtime.getRuntime().addShutdownHook( new ShutdownHookThread("IO 密集型任务线程池", new Callable<Void>() { @Override public Void call() throws Exception { //优雅关闭线程池 shutdownThreadPoolGracefully(EXECUTOR); return null; } })); } } ...省略不相干代码 }
在以上的参考代码中,有以下几个要点需要进行特别说明:
- (1)为参考的 IO 线程池调用了 allowCoreThreadTimeOut(…)方法,并且传入了参数 true,则 keepAliveTime 参数所设置的 Idle 超时策略也将被应用于核心线程,当池中的线程长时间空闲时,可以自行销毁。
- (2)使用有界队列缓冲任务而不是无界队列,如果 128 太小可以根据具体需要进行增大,但是不能使用无界队列。
- (3)corePoolSize、maximumPoolSize 保持一致,使得在接收到新任务时,如果没有空闲工作线程,则优先创建新的线程去执行新任务,而不是优先加入阻塞队列,等待现有工作线程空闲后再执行。
- (4)使用懒汉式单例模式创建线程池,如果代码没有用到此线程池,也不会立即创建。
- (5)使用 JVM 关闭时的钩子函数,优雅的自动关闭线程池。
为 CPU 密集型任务确定线程数
CPU 密集型任务也叫计算密集型任务,其特点是要进行大量计算而需要消耗 CPU 资源,比如计算圆周率、对视频进行高清解码等等。CPU 密集型任务虽然也可以并行完成,但是并行的任务越多,花在任务切换的时间就越多,CPU 执行任务的效率就越低,所以,要最高效地利用 CPU,
CPU 密集型任务的并行执行的数量应当等于 CPU 的核心数。
比如说 4 个核心的 CPU,通过 4 个线程并行执行 4 个 CPU 密集型任务,此时的效率是最高的。但是如果线程数远远超出 CPU 核心数量,需要频繁的切换线程,线程上下文切换时需要消耗时间的,反而会使得任务效率下降。因此对于 CPU 密集型的任务来说,线程数等于 CPU 数就行。
本书的在随书源码的 ThreadUtil 类中,为 CPU 密集型任务的创建了一个简单的参考线程池,具体代码如下:
package com.crazymakercircle.util; ...省略 import public class ThreadUtil { //CPU 核数 private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors(); private static final int MAXIMUM_POOL_SIZE = CPU_COUNT; //懒汉式单例创建线程池:用于 CPU 密集型任务 private static class CpuIntenseTargetThreadPoolLazyHolder { //线程池: 用于 CPU 密集型任务 private static final ThreadPoolExecutor EXECUTOR = new ThreadPoolExecutor( MAXIMUM_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE_SECONDS, TimeUnit.SECONDS, new LinkedBlockingQueue(QUEUE_SIZE), new CustomThreadFactory("cpu")); static { EXECUTOR.allowCoreThreadTimeOut(true); //JVM 关闭时的钩子函数 Runtime.getRuntime().addShutdownHook( new ShutdownHookThread("CPU 密集型任务线程池", new Callable<Void>() { @Override public Void call() throws Exception { //优雅关闭线程池 shutdownThreadPoolGracefully(EXECUTOR); return null; } })); } } ...省略不相干代码 }
为混合型任务确定线程数
混合型任务既要执行逻辑计算,又要进行大量非 CPU 耗时操作(如 RPC 调用、数据库访问、
网络通信等),所以,混合型任务 CPU 利用率不是太高,非 CPU 耗时往往是 CPU 耗时的数倍。
比如在 Web 应用处理 HTTP 请求处理时,一次请求处理会包括 DB 操作、RPC 操作、缓存操作等
多种耗时操作。一般来说,一次 Web 请求的 CPU 计算耗时往往较少,大致在 100ms-500ms 之间,
而其他耗时操作会占用 500ms-1000ms 甚至更多的时间。
在为混合型任务创建线程池时,如何确定线程数呢?业界有一个比较成熟的估算公式,具体
如下:
最佳线程数 = ((线程等待时间+线程 CPU 时间)/线程 CPU 时间 )* CPU 核数
经过简单的换算,以上公式可进一步转换为:
最佳线程数目 =(线程等待时间与线程 CPU 时间之比 + 1)* CPU 核数
通过公式可以看出:等待时间所占比例越高,需要越多线程;CPU 耗时所占比例越高,需要越少线程。下面举个例子:比如在 Web 服务器处理 HTTP 请求时,假设平均线程 CPU 运行时间为 100ms,而线程等待时间(比如包括 DB 操作、RPC 操作、缓存操作等)为 900ms,如果 CPU
核数为 8,那么根据上面这个公式,估算如下:
(900ms+100ms)/100ms*8= 10*8 = 80
经过计算,以上案例中需要的线程数为 80。很多的小伙伴认为,线程数越高越好。那么,使用很多线程是否就一定比单线程高效呢?答案是否定的,比如大名鼎鼎的 Redis 就是单线程的,但它却非常高效,基本操作都能达到十万量级/秒。
说明:为什么 Redis 使用单线程也如此之快,原因在于:Redis 基本都是内存操作,这种情况下单线程可以很高效地利用 CPU,多线程带来线程上下文切换开销,单线程就没有这种开销。有关 Redis 的知识,请参考笔者的另一本书《Java 高并发核心
编程卷 1》。
由于 Redis 基本都是内存操作,这种情况下单线程可以很高效地利用 CPU,多线程反而不是太适用。多线程适用场景一般是:存在相当比例非 CPU 耗时操作,如 IO、网络操作,需要尽量
提高并行化比率提升 CPU 的利用率。
以上公式的估算结果,仅仅是理论最佳值,在生产环境使用也仅供参考。生产环境需要结合系统网络环境和硬件情况(CPU、内存、硬盘读写速度)不断尝试,获取一个符合实际的线程数值。
本书的在随书源码的 ThreadUtil 类中,为混合型任务的创建了一个简单的参考线程池,具体
代码如下:
package com.crazymakercircle.util; ...省略 import public class ThreadUtil { private static final int MIXED_MAX = 128; //最大线程数 private static final String MIXED_THREAD_AMOUNT = "mixed.thread.amount"; //懒汉式单例创建线程池:用于混合型任务 private static class MixedTargetThreadPoolLazyHolder { //首先从环境变量 mixed.thread.amount 中获取预先配置的线程数 //如果没有对 mixed.thread.amount 做配置,则使用常量 MIXED_MAX 作为线程数 private static final int max = (null != System.getProperty(MIXED_THREAD_AMOUNT)) ? Integer.parseInt(System.getProperty(MIXED_THREAD_AMOUNT)) : MIXED_MAX; //线程池: 用于混合型任务 private static final ThreadPoolExecutor EXECUTOR = new ThreadPoolExecutor( max, max, KEEP_ALIVE_SECONDS, TimeUnit.SECONDS, new LinkedBlockingQueue(QUEUE_SIZE), new CustomThreadFactory("mixed")); static { EXECUTOR.allowCoreThreadTimeOut(true); //JVM 关闭时的钩子函数 Runtime.getRuntime().addShutdownHook( new ShutdownHookThread("混合型任务线程池", new Callable<Void>() { @Override public Void call() throws Exception { //优雅关闭线程池 shutdownThreadPoolGracefully(EXECUTOR); return null; } })); } } ...省略不相干代码 }
在使用如上代码的创建混合型线程池时,建议按照前面的最佳线程数估算公式,提前预估好
线程数(如 80),然后设置在环境变量 mixed.thread.amount 中,如下面的测试用例所示:
package com.crazymakercircle.mutithread.basic.create3; ...省略 import public class CreateThreadPoolDemo { @org.junit.Test public void testMixedThreadPool() { System.getProperties().put("mixed.thread", 600); // 获取自定义的混合线程池 ExecutorService pool = ThreadUtil.getMixedTargetThreadPool(); for (int i = 0; i < 1000; i++) { try { sleepMilliSeconds(10); pool.submit(new TargetTask()); } catch (RejectedExecutionException e) { ...异常处理 } } //等待 10s sleepSeconds(10); Print.tco("关闭线程池"); } ...省略其他 }
学习资源来源于疯狂创客圈:
个人学习笔记,记录日常学习,便于查阅及加深,仅为方便个人使用。
分类:
知识储备 / 疯狂创客圈
, 知识储备 / 面试及原理理解


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
2018-12-09 双列集合Map
2018-12-09 java基础-集合