kafka
特性
用处
技术优势
适应人群
课程亮点
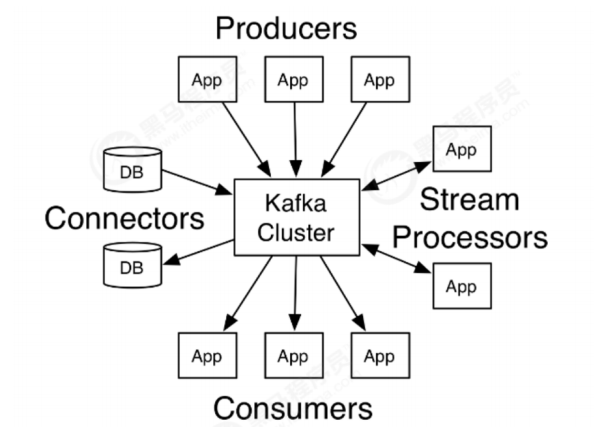
1.1 概念详解

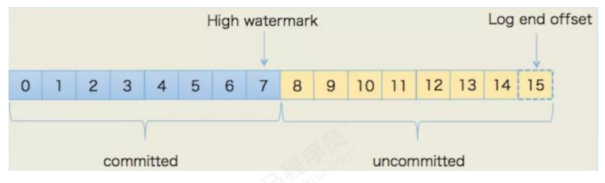
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的
partition。
1.2 安装与配置
1.2.1 java环境


1.2.2 ZooKeeper的安装


# The number of milliseconds of each tick # zk服务器的心跳时间 tickTime=2000 # The number of ticks that the initial # synchronization phase can take # 投票选举新Leader的初始化时间 initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. # 数据目录 dataDir=temp/zookeeper/data # 日志目录 dataLogDir=temp/zookeeper/log # the port at which the clients will connect # Zookeeper对外服务端口,保持默认 clientPort=2181
itcast@Server-node:/mnt/d/zookeeper-3.4.14$ bin/zkServer.sh start ZooKeeper JMX enabled by default Using config: /mnt/d/zookeeper-3.4.14/bin/../conf/zoo.cfg //启动成功 Starting zookeeper ... STARTED itcast@Server-node:/mnt/d/zookeeper-3.4.14$
1.2.3 Kafka的安装与配置



1.2.4 Kafka测试消息生产与消费
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic heima --partitions 2 --replication-factor 1 //主题创建成功 Created topic heima. itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper localhost:2181 --list heima itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic heima Topic:heima PartitionCount:2 ReplicationFactor:1 Configs: Topic: heima Partition: 0 Leader: 0 Replicas: 0 Isr: 0 Topic: heima Partition: 1 Leader: 0 Replicas: 0 Isr: 0 itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$
启动消费端接收消息
命令:bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic heima
--bootstrap-server 指定了连接Kafka集群的地址
--topic 指定了消费端订阅的主题
如:
1.3 Java第一个程序
1.3.1 准备
<properties>
<scala.version>2.11</scala.version>
<slf4j.version>1.7.21</slf4j.version>
<kafka.version>2.0.0</kafka.version>
<lombok.version>1.18.8</lombok.version>
<junit.version>4.11</junit.version>
<gson.version>2.2.4</gson.version>
<protobuff.version>1.5.4</protobuff.version>
<spark.version>2.3.1</spark.version>
</properties>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
1.3.2 创建生产者
/** * Kafka 消息生产者 */ public class ProducerFastStart { // Kafka集群地址 private static final String brokerList = "localhost:9092"; // 主题名称-之前已经创建 private static final String topic = "heima"; public static void main(String[] args) { Properties properties = new Properties(); // 设置key序列化器 properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //另外一种写法 //properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 设置重试次数 properties.put(ProducerConfig.RETRIES_CONFIG, 10); // 设置值序列化器 properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 设置集群地址 properties.put("bootstrap.servers", brokerList); // KafkaProducer 线程安全 KafkaProducer<String, String> producer = new KafkaProducer<> (properties); ProducerRecord<String, String> record = new ProducerRecord<>(topic, "Kafka-demo-001", "hello, Kafka!"); try { producer.send(record); } catch (Exception e) { e.printStackTrace(); } producer.close(); } }
1.3.3 创建消费者
*/ public class ProducerFastStart { // Kafka集群地址 private static final String brokerList = "localhost:9092"; // 主题名称-之前已经创建 private static final String topic = "heima"; public static void main(String[] args) { Properties properties = new Properties(); // 设置key序列化器 properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //另外一种写法 //properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); // 设置重试次数 properties.put(ProducerConfig.RETRIES_CONFIG, 10); // 设置值序列化器 properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 设置集群地址 properties.put("bootstrap.servers", brokerList); // KafkaProducer 线程安全 KafkaProducer<String, String> producer = new KafkaProducer<> (properties); ProducerRecord<String, String> record = new ProducerRecord<>(topic, "Kafka-demo-001", "hello, Kafka!"); try { producer.send(record); } catch (Exception e) { e.printStackTrace(); } producer.close(); } }
/** * Kafka 消息消费者 */ public class ConsumerFastStart { // Kafka集群地址 private static final String brokerList = "127.0.0.1:9092"; // 主题名称-之前已经创建 private static final String topic = "heima"; // 消费组 private static final String groupId = "group.demo"; public static void main(String[] args) { Properties properties = new Properties(); properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); operties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.put("bootstrap.servers", brokerList); properties.put("group.id", groupId); KafkaConsumer<String, String> consumer = new KafkaConsumer<> (properties); consumer.subscribe(Collections.singletonList(topic)); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.println(record.value()); } } } }
1.3.4 效果展示


1.4 服务端常用参数配置
broker.id=0
# listeners = listener_name://host_name:port
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://:9092
# it uses the value for "listeners" if configured. Otherwise, it will use the value
#advertised.listeners=PLAINTEXT://your.host.name:9092
#log.dirs=/tmp/kafka-logs
log.dirs=/tmp/kafka/log
# Zookeeper connection string (see zookeeper docs for details).
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
broker.id=0 listeners=PLAINTEXT://:9092 log.dirs=/tmp/kafka/log zookeeper.connect=localhost:2181 zookeeper.connection.timeout.ms=6000
1.4.1 zookeeper.connect
1.4.2 listeners
1.4.3 broker.id
1.4.4 log.dirs
1.4.5 message.max.bytes
第2章 生产者详解
2.1 消息发送
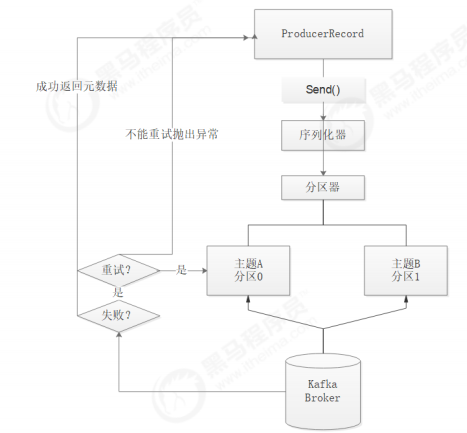
2.1.1 Kafka Java客户端数据生产流程解析
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_${scala.version}</artifactId> <version>${kafka.version}</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> </exclusions> </dependency>
2.1.2 必要参数配置
public static Properties initConfig() { Properties props = new Properties(); // 该属性指定 brokers 的地址清单,格式为 host:port。清单里不需要包含所有的 broker 地址, // 生产者会从给定的 broker 里查找到其它 broker 的信息。——建议至少提供两个 broker 的信息,因为一旦其中一个宕机,生产者仍然能够连接到集群上。 props.put("bootstrap.servers", brokerList); // 将 key 转换为字节数组的配置,必须设定为一个实现了 org.apache.kafka.common.serialization.Serializer 接口的类, // 生产者会用这个类把键对象序列化为字节数组。 // ——kafka 默认提供了 StringSerializer和 IntegerSerializer、 ByteArraySerializer。当然也可以自定义序列化器。 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 和 key.serializer 一样,用于 value 的序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); 生成一个非空字符串。 // 内容形式如:"producer-1" props.put("client.id", "producer.client.id.demo"); return props; } Properties props = initConfig(); KafkaProducer<String, String> producer = new KafkaProducer<>(props); // KafkaProducer<String, String> producer = new KafkaProducer<>(props, // new StringSerializer(), new StringSerializer()); //生成 ProducerRecord 对象,并制定 Topic,key 以及 value ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello, Kafka!"); try { // 发送消息 producer.send(record); }
2.13 发送类型
2.1.4 序列化器
2.1.5 自定义序列化器
/** * 自定义序列化器 */ public class CompanySerializer implements Serializer<Company> { @Override public void configure(Map configs, boolean isKey) { } @Override public byte[] serialize(String topic, Company data) { if (data == null) { return null; } byte[] name, address; try { if (data.getName() != null) { name = data.getName().getBytes("UTF-8"); } else { name = new byte[0]; } if (data.getAddress() != null) { address = data.getAddress().getBytes("UTF-8"); } else { address = new byte[0]; } ByteBuffer buffer = ByteBuffer. allocate(4 + 4 + name.length + address.length); buffer.putInt(name.length); buffer.put(name); buffer.putInt(address.length); buffer.put(address); return buffer.array(); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } return new byte[0]; } @Override public void close() { } }
public class ProducerDefineSerializer { public static final String brokerList = "localhost:9092"; public static final String topic = "heima"; public static void main(String[] args) throws ExecutionException, InterruptedException { Properties properties = new Properties(); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, CompanySerializer.class.getName()); // properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, // ProtostuffSerializer.class.getName()); properties.put("bootstrap.servers", brokerList); KafkaProducer<String, Company> producer = new KafkaProducer<>(properties); Company company = Company.builder().name("kafka") .address("北京").build(); // Company company = Company.builder().name("hiddenkafka") // .address("China").telphone("13000000000").build(); ProducerRecord<String, Company> record = new ProducerRecord<>(topic, company); producer.send(record).get(); } }
2.1.6 分区器.
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (keyBytes == null) { int nextValue = this.nextValue(topic); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return ((PartitionInfo)availablePartitions.get(part)).partition(); } else { return Utils.toPositive(nextValue) % numPartitions; } } else { return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } }
/** * 自定义分区器 */ public class DefinePartitioner implements Partitioner { private final AtomicInteger counter = new AtomicInteger(0); @Override public int partition(String topic, Object key, byte[] keyBytes, List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (null == keyBytes) { return counter.getAndIncrement() % numPartitions; } else return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } @Override public void close() { } @Override public void configure(Map<String, ?> configs) { } }
2.1.7 拦截器
package com.hainei.netty_test.test.kafka; /** * Created with IntelliJ IDEA. * User:wq * Date:2021/8/27 * Time: 14:52 * Description: No Description */ import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Map; /** * 自定义拦截器 */ public class ProducerInterceptorPrefix implements ProducerInterceptor<String, String> { private volatile long sendSuccess = 0; private volatile long sendFailure = 0; @Override public ProducerRecord<String, String> onSend( ProducerRecord<String, String> record) { String modifiedValue = "prefix1-" + record.value(); return new ProducerRecord<>(record.topic(), record.partition(), record.timestamp(), record.key(), modifiedValue, record.headers()); // if (record.value().length() < 5) { // throw new RuntimeException(); // } // return record; } @Override public void onAcknowledgement( RecordMetadata recordMetadata, Exception e) { if (e == null) { sendSuccess++; } else { sendFailure++; } } @Override public void close() { double successRatio = (double) sendSuccess / (sendFailure + sendSuccess); System.out.println("[INFO] 发送成功率=" + String.format("%f", successRatio * 100) + "%"); } @Override public void configure(Map<String, ?> map) { } }
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,ProducerDefineSerializer.class.getName());


2.2 发送原理剖析

2.3 其他生产者参数
2.3.1 acks
2.3.2 retries
2.3.3 batch.size
2.3.4 max.request.size
第3章 消费者详解
3.1 概念入门
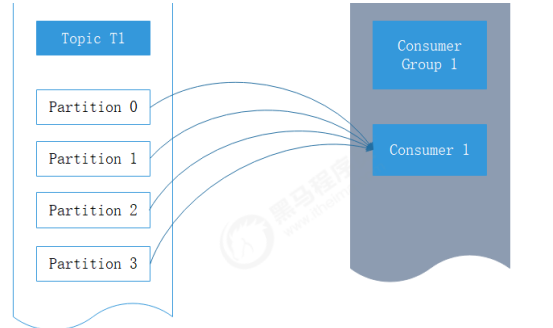
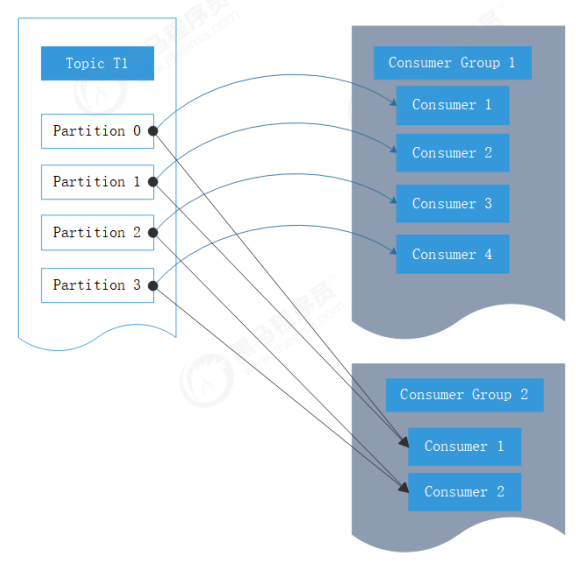
3.1.1 消费者和消费组
public static Properties initConfig() { Properties props = new Properties(); // 与KafkaProducer中设置保持一致 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 必填参数,该参数和KafkaProducer中的相同,制定连接Kafka集群所需的broker地址清 单,可以设置一个或者多个 props.put("bootstrap.servers", brokerList); // 消费者隶属于的消费组,默认为空,如果设置为空,则会抛出异常,这个参数要设置成具有一 定业务含义的名称 props.put("group.id", groupId); // 指定KafkaConsumer对应的客户端ID,默认为空,如果不设置KafkaConsumer会自动生成 一个非空字符串 props.put("client.id", "consumer.client.id.demo"); return props; }
3.2.2 订阅主题和分区
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic));
consumer.subscribe(Pattern.compile("heima*"));
consumer.assign(Arrays.asList(new TopicPartition("topic0701", 0)));
3.2.2 反序列化
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
3.2.3 位移提交
public static Properties initConfig() { Properties props = new Properties(); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // 手动提交开启 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); return props; } while (true) { ConsumerRecords<String, String> records = consumer.poll(1000); if (records.isEmpty()) { break; } List<ConsumerRecord<String, String>> partitionRecords = records.records(tp); lastConsumedOffset = partitionRecords.get(partitionRecords.size() - 1).offset(); consumer.commitSync();//同步提交消费位移 }
try { while (running.get()) { ConsumerRecords<String, String> records = consumer.poll(1000); for (ConsumerRecord<String, String> record : records) { //do some logical processing. } // 异步回调 consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { if (exception == null) { System.out.println(offsets); } else { log.error("fail to commit offsets {}", offsets, exception); } } }); } } finally { consumer.close(); }
3.2.4 指定位移消费
/** * 指定位移消费 */ public class SeekDemo extends ConsumerClientConfig { public static void main(String[] args) { Properties props = initConfig(); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); // timeout参数设置多少合适?太短会使分区分配失败,太长又有可能造成一些不必要的等待 consumer.poll(Duration.ofMillis(2000)); // 获取消费者所分配到的分区 Set<TopicPartition> assignment = consumer.assignment(); System.out.println(assignment); for (TopicPartition tp : assignment) { // 参数partition表示分区,offset表示指定从分区的哪个位置开始消费 consumer.seek(tp, 10); } // consumer.seek(new TopicPartition(topic,0),10); while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); //consume the record. for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value()); } } }
public static void main(String[] args) { Properties props = initConfig(); afkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); long start = System.currentTimeMillis(); Set<TopicPartition> assignment = new HashSet<>(); while (assignment.size() == 0) { consumer.poll(Duration.ofMillis(100)); assignment = consumer.assignment(); } long end = System.currentTimeMillis(); System.out.println(end - start); System.out.println(assignment); for (TopicPartition tp : assignment) { consumer.seek(tp, 10); } while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); //consume the record. for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value()); } } }
Map<TopicPartition, Long> offsets = consumer.endOffsets(assignment); for (TopicPartition tp : assignment) { consumer.seek(tp, offsets.get(tp)); }
for (TopicPartition tp : assignment) { //consumer.seek(tp, offsets.get(tp)); consumer.seek(tp, offsets.get(tp) + 1); }
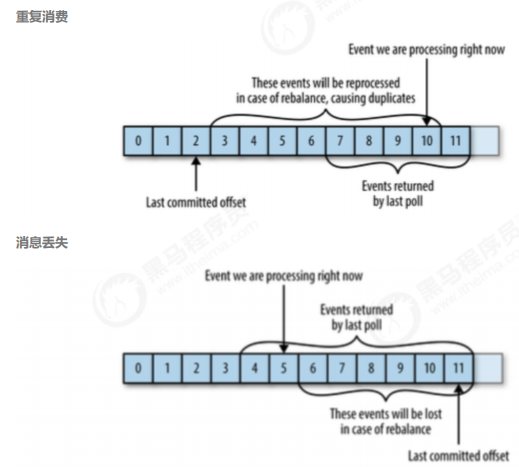
3.2.4 再均衡监听器
public static void main(String[] args) { Properties props = initConfig(); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>(); consumer.subscribe(Arrays.asList(topic), new ConsumerRebalanceListener() { @Override public void onPartitionsRevoked(Collection<TopicPartition> partitions) { // 劲量避免重复消费 consumer.commitSync(currentOffsets); } @Override public void onPartitionsAssigned(Collection<TopicPartition> partitions) { //do nothing. } }); try { while (isRunning.get()) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + ":" + record.value()); // 异步提交消费位移,在发生再均衡动作之前可以通过再均衡监听器的 onPartitionsRevoked回调执行commitSync方法同步提交位移。 currentOffsets.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset() + 1)); } consumer.commitAsync(currentOffsets, null); } } finally { consumer.close(); } }
3.2.5 消费者拦截器
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) { System.out.println("before:" + records); long now = System.currentTimeMillis(); Map<TopicPartition, List<ConsumerRecord<String, String>>> newRecords= new HashMap<>(); for (TopicPartition tp : records.partitions()) { List<ConsumerRecord<String, String>> tpRecords =records.records(tp); List<ConsumerRecord<String, String>> newTpRecords = new ArrayList<>(); for (ConsumerRecord<String, String> record : tpRecords) { if (now - record.timestamp() < EXPIRE_INTERVAL) { newTpRecords.add(record); } } if (!newTpRecords.isEmpty()) { newRecords.put(tp, newTpRecords); } } return new ConsumerRecords<>(newRecords); }
props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,ConsumerInterceptorTTL.class.getName());
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "Kafka-demo- 001", "hello, Kafka!"); ProducerRecord<String, String> record2 = new ProducerRecord<>(topic, 0, System.currentTimeMillis() - 10 * 1000, "Kafka-demo-001", "hello, Kafka!->超时");

3.2.6 消费者参数补充
第4章 主题
4.1 管理
4.1.1 创建主题
itcast@Server-node: /mnt/d/zookeeper-3.4.14$ bin/zkCli.sh -server localhost:2181
4.1.2 查看主题
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --list -- zookeeper localhost:2181
4.1.4 删除主题
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --delete -- zookeeper localhost:2181 --topic heima
4.2 增加分区
4.5 KafkaAdminClient应用
/** * KafkaAdminClient应用 */ public class KafkaAdminConfigOperation { public static void main(String[] args) throws ExecutionException, InterruptedException { // describeTopicConfig(); // alterTopicConfig(); addTopicPartitions(); } //Config(entries=[ConfigEntry(name=compression.type, value=producer, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=leader.replication.throttled.replicas, value=, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=message.downconversion.enable, value=true, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=min.insync.replicas, value=1, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.jitter.ms, value=0, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=cleanup.policy, value=delete, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=flush.ms, value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=follower.replication.throttled.replicas, value=, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.bytes, value=1073741824, source=STATIC_BROKER_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=retention.ms, value=604800000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=flush.messages, value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=message.format.version, value=2.0-IV1, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=file.delete.delay.ms, value=60000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=max.message.bytes, value=1000012, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=min.compaction.lag.ms, value=0, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=message.timestamp.type, value=CreateTime, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=preallocate, value=false, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=min.cleanable.dirty.ratio, value=0.5, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=index.interval.bytes, value=4096, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=unclean.leader.election.enable, value=false, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=retention.bytes, value=-1, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=delete.retention.ms, value=86400000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.ms, value=604800000, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=message.timestamp.difference.max.ms, value=9223372036854775807, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[]), ConfigEntry(name=segment.index.bytes, value=10485760, source=DEFAULT_CONFIG, isSensitive=false, isReadOnly=false, synonyms=[])]) public static void describeTopicConfig() throws ExecutionException, InterruptedException { String brokerList = "localhost:9092"; String topic = "heima"; Properties props = new Properties(); props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000); AdminClient client = AdminClient.create(props); ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC, topic); DescribeConfigsResult result = client.describeConfigs(Collections.singleton(resource)); Config config = result.all().get().get(resource); System.out.println(config); client.close(); } public static void alterTopicConfig() throws ExecutionException, InterruptedException { String brokerList = "localhost:9092"; String topic = "heima"; Properties props = new Properties(); props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000); AdminClient client = AdminClient.create(props); ConfigResource resource = new ConfigResource(ConfigResource.Type.TOPIC, topic); ConfigEntry entry = new ConfigEntry("cleanup.policy", "compact"); Config config = new Config(Collections.singleton(entry)); Map<ConfigResource, Config> configs = new HashMap<>(); configs.put(resource, config); AlterConfigsResult result = client.alterConfigs(configs); result.all().get(); client.close(); } public static void addTopicPartitions() throws ExecutionException, InterruptedException { String brokerList = "localhost:9092"; String topic = "heima"; Properties props = new Properties(); props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 30000); AdminClient client = AdminClient.create(props); NewPartitions newPartitions = NewPartitions.increaseTo(5); Map<String, NewPartitions> newPartitionsMap = new HashMap<>(); newPartitionsMap.put(topic, newPartitions); CreatePartitionsResult result = client.createPartitions(newPartitionsMap); result.all().get(); client.close(); } }
第5章 分区
5.1 副本机制
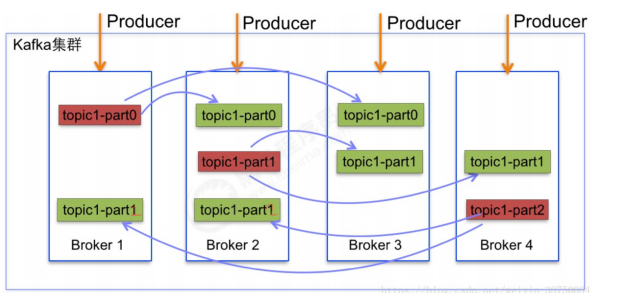
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic heima
5.2 分区Leader选举
5.3 分区重新分配
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic heima-par --partitions 3 --replication-factor 3
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic heima-par
- 第二步:主题heima-par再添加一个分区
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic heima-par --partitions 4
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic heima-par
- 第三步:再添加一个broker节点
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-topics.sh --describe -zookeeper localhost:2181 --topic heima-par
- 第四步:重新分配
{ "version": 1, "partitions": [ { "topic": "heima-par", "partition": 0, "replicas": [ 1, 2, 3 ], "log_dirs": [ "any", "any", "any" ] }, { "topic": "heima-par", "partition": 2, "replicas": [ 3, 0, 1 ], "log_dirs": [ "any", "any", "any" ] }, { "topic": "heima-par", "partition": 1, "replicas": [ 2, 3, 0 ], "log_dirs": [ "any", "any", "any" ] }, { "topic": "heima-par", "partition": 3, "replicas": [ 0, 1, 2 ], "log_dirs": [ "any", "any", "any" ] } ] }
5.5 分区分配策略

面各个示例中的整套逻辑是按照Kafka中默认的分区分配策略来实施的。
Kafka提供了消费者客户端参数partition.assignment.strategy用来设置消费者与订阅主题之间的分区分配策略。默认情况下,此参数的值为:org.apache.kafka.clients.consumer.RangeAssignor,
即采用RangeAssignor分配策略。除此之外,Kafka中还提供了另外两种分配策略: RoundRobinAssignor和StickyAssignor。消费者客户端参数partition.asssignment.strategy可以配置多个分配策略,彼此之间以逗号分隔。
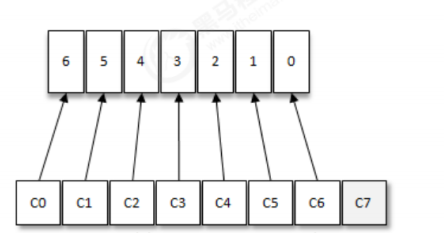
RangeAssignor分配策略
参考源码:org.apache.kafka.clients.consumer.RangeAssignor
RangeAssignor策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按
照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每一个topic,
RangeAssignor策略会将消费组内所有订阅这个topic的消费者按照名称的字典序排序,然后为每个消费
者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
假设n=分区数/消费者数量,m=分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面的(消费者数量-m)个消费者每个分配n个分区。
假设消费组内有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有4个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t0p3、t1p0、t1p1、t1p2、t1p3。最终的分配结果为:
消费者C0:t0p0、t0p1、t1p0、t1p1
消费者C1:t0p2、t0p3、t1p2、t1p3
假设上面例子中2个主题都只有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、
t1p0、t1p1、t1p2。最终的分配结果为:
消费者C0:t0p0、t0p1、t1p0、t1p1
消费者C1:t0p2、t1p2
可以明显的看到这样的分配并不均匀,如果将类似的情形扩大,有可能会出现部分消费者过载的情况。
RoundRobinAssignor分配策略
参考源码:org.apache.kafka.clients.consumer.RoundRobinAssignor
RoundRobinAssignor策略的原理是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序,然后通过轮询方式逐个将分区以此分配给每个消费者。RoundRobinAssignor策略对应的partition.assignment.strategy参数值为:
org.apache.kafka.clients.consumer.RoundRobinAssignor。
假设消费组中有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
消费者C0:t0p0、t0p2、t1p1
消费者C1:t0p1、t1p0、t1p2
如果同一个消费组内的消费者所订阅的信息是不相同的,那么在执行分区分配的时候就不是完全的轮询分配,有可能会导致分区分配的不均匀。如果某个消费者没有订阅消费组内的某个topic,那么在分配分区的时候此消费者将分配不到这个topic的任何分区。
假设消费组内有3个消费者C0、C1和C2,它们共订阅了3个主题:t0、t1、t2,这3个主题分别有1、2、3个分区,即整个消费组订阅了t0p0、t1p0、t1p1、t2p0、t2p1、t2p2这6个分区。具体而言,消费者C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2,那么最终的分配结果为:
消费者C0:t0p0
消费者C1:t1p0
消费者C2:t1p1、t2p0、t2p1、t2p2
可以看到RoundRobinAssignor策略也不是十分完美,这样分配其实并不是最优解,因为完全可以将分区t1p1分配给消费者C1。
StickyAssignor分配策略
参考源码:org.apache.kafka.clients.consumer.StickyAssignor
Kafka从0.11.x版本开始引入这种分配策略,它主要有两个目的:
分区的分配要尽可能的均匀; 分区的分配尽可能的与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标。鉴于这两个目标,StickyAssignor策略的具体实现
要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多。
假设消费组内有3个消费者:C0、C1和C2,它们都订阅了4个主题:t0、t1、t2、t3,并且每个主题有2个分区,也就是说整个消费组订阅了t0p0、t0p1、t1p0、t1p1、t2p0、t2p1、t3p0、t3p1这8个分
区。最终的分配结果如下:
消费者C0:t0p0、t1p1、t3p0
消费者C1:t0p1、t2p0、t3p1
消费者C2:t1p0、t2p1
假设此时消费者C1脱离了消费组,那么消费组就会执行再平衡操作,进而消费分区会重新分配。如果采用RoundRobinAssignor策略,那么此时的分配结果如下:
消费者C0:t0p0、t1p0、t2p0、t3p0
消费者C2:t0p1、t1p1、t2p1、t3p1
如分配结果所示,RoundRobinAssignor策略会按照消费者C0和C2进行重新轮询分配。而如果此时使用的是StickyAssignor策略,那么分配结果为:
消费者C0:t0p0、t1p1、t3p0、t2p0
消费者C2:t1p0、t2p1、t0p1、t3p1
可以看到分配结果中保留了上一次分配中对于消费者C0和C2的所有分配结果,并将原来消费者C1的“负担”分配给了剩余的两个消费者C0和C2,最终C0和C2的分配还保持了均衡。
自定义分配策略
需实现:org.apache.kafka.clients.consumer.internals.PartitionAssignor
继承自:org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor
第6张 Kafka存储
6.1 存储结构概述
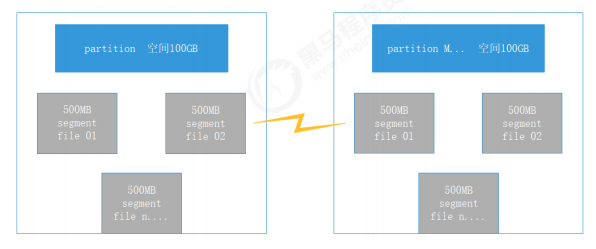
6.2 日志索引
6.2.1 数据文件的分段
6.2.2 偏移量索引

6.3 日志清理
6.3.1 日志删除

6.4 磁盘存储优势
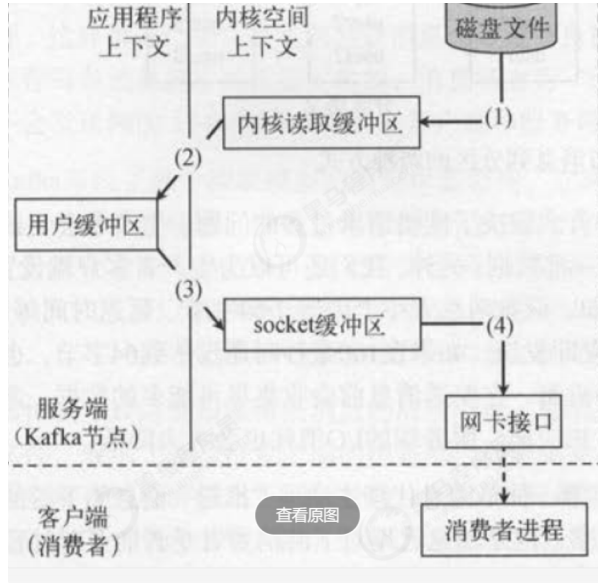
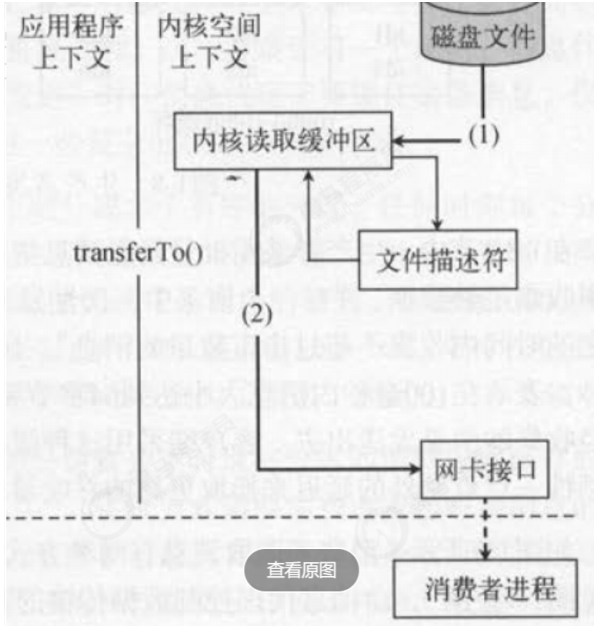
第7章 稳定性
7.1 幂等性
7.2 事务
初始化事务,前提是配置了transactionalIdpublic void initTransactions()//开启事务public void beginTransaction()//为消费者提供事务内的位移提交操作public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId)//提交事务public void commitTransaction()//终止事务,类似于回滚public void abortTransaction()
/** * Kafka Producer事务的使用 */ public class ProducerTransactionSend { public static final String topic = "topic-transaction"; public static final String brokerList = "localhost:9092"; public static final String transactionId = "transactionId"; public static void main(String[] args) { Properties properties = new Properties(); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, transactionId); KafkaProducer<String, String> producer = new KafkaProducer<> (properties); producer.initTransactions(); producer.beginTransaction(); try { //处理业务逻辑并创建ProducerRecord ProducerRecord<String, String> record1 = new ProducerRecord<>(topic, "msg1"); producer.send(record1); ProducerRecord<String, String> record2 = new ProducerRecord<>(topic, "msg2"); producer.send(record2); ProducerRecord<String, String> record3 = new ProducerRecord<>(topic, "msg3"); producer.send(record3); //处理一些其它逻辑 producer.commitTransaction(); } catch (ProducerFencedException e) { producer.abortTransaction(); } producer.close(); } }
try { //处理业务逻辑并创建ProducerRecord ProducerRecord<String, String> record1 = new ProducerRecord<>(topic, "msg1"); producer.send(record1); //模拟事务回滚案例 System.out.println(1/0); ProducerRecord<String, String> record2 = new ProducerRecord<>(topic, "msg2"); producer.send(record2); ProducerRecord<String, String> record3 = new ProducerRecord<>(topic, "msg3"); producer.send(record3); //处理一些其它逻辑 producer.commitTransaction(); } catch (ProducerFencedException e) { producer.abortTransaction(); }
7.3 控制器
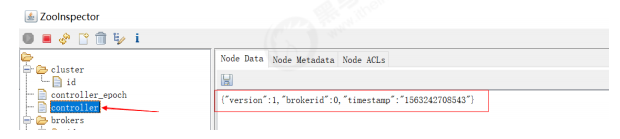

7.4 可靠性保证

7.5 一致性保证
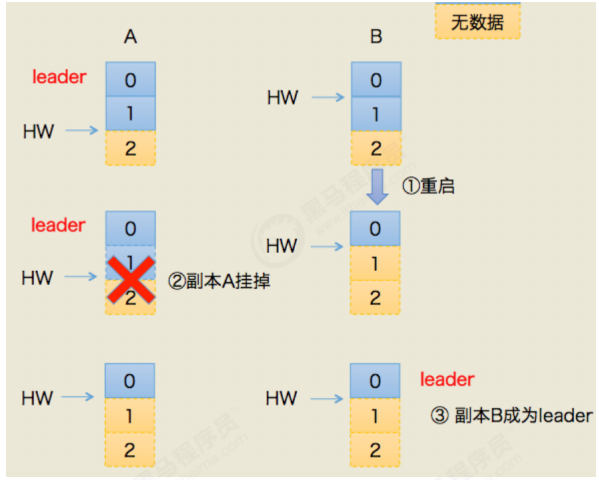
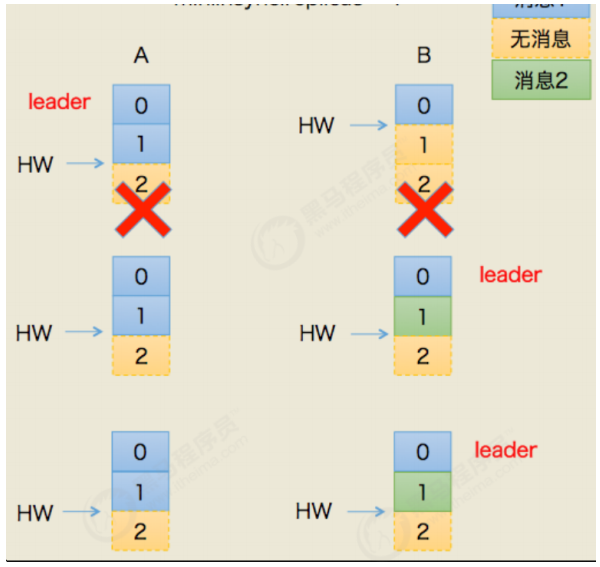
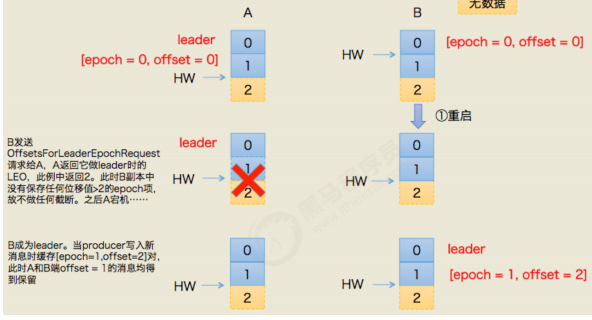

7.6 消息重复的场景及解决方案
7.6.1 生产者端重复
7.6.2 消费者端重复
7.7 __consumer_offffsets
7.7.1 何时创建


第8章 高级应用
8.1 命令行工具
8.1.1 消费组管理
8.1.2 消费位移管理
8.2 数据管道Connect
8.2.1 概述

8.2.2 独立模式--文件系统
8.2.3 信息流--ElasticSearch
8.4 流式处理Spark
8.4.1 Spark安装与应用
8.4.3 Spark和Kafka整合
8.5 SpringBoot Kafka
8.5.1 创建SpringBoot项目
8.5.2 Springboot整合Kafka
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>2.2.6.RELEASE</version> </dependency>
spring.kafka.producer.bootstrap-servers=127.0.0.1:9092
/** * 发送消息 */ @GetMapping("/send/{input}") public String sendToKafka(@PathVariable String input) { this.template.send(topic, input); return "send success"; }
/** * 接收消息 */ @KafkaListener(id = "", topics = topic, groupId = "group.demo") public void listener(String input) { logger.info("input value:{}", input); }
8.5.3 事务操作
// 事务操作 template.executeInTransaction(t -> { t.send(topic, input); if ("error".equals(input)) { throw new RuntimeException("input is error"); } t.send(topic, input + " anthor"); return true; }); return "send success";
8.6 消息中间件选型对比
第9章 集群管理
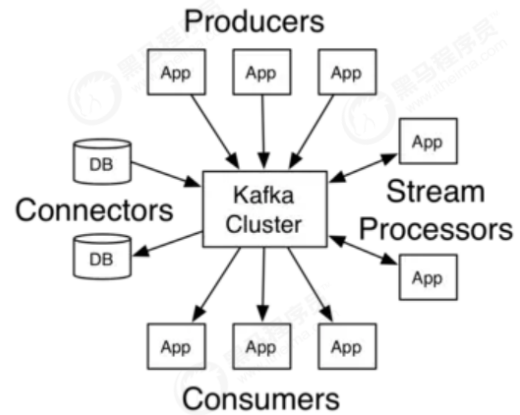
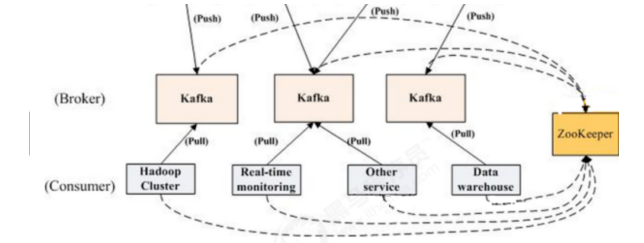
9.1 集群使用场景
9.2 集群搭建
9.2.1 ZooKeeper集群搭建
9.2.2 Kafka集群搭建
9.3 多集群同步
9.3.1 配置
9.3.2 调优
第10章 监控
10.1 监控度量指标
10.1.1 JMX
