数据库
1. 数据库相关概念
1.1 数据(Data)
用于描述事务的符号, 例如: 文本, 图形, 音频, 视频等
1.2 数据库(DB)
DataBase, 简称 DB, 用于存储和管理数据的仓库
1.3 数据库管理系统(DBMS)
DataBase Management System, 简称 DBMS, 用于科学的组织
和存储数据, 高效快捷的管理和维护数据.
1.4 数据库应用系统(DBAS)
DataBase Application System, 简称 DBAS, 面向最终用户的
应用程序
1.5 数据库管理员(DBA)
DataBase Administrator, 简称 DBA, DBMS 的使用者
1.6 数据库系统(DBS)
DB+DBMS+DBAS+DBA+最终用户, 构成 DBS
2.数据库发展过程
2.1 关系数据库
a) 当前主流的数据库
b) 通过二维表存储和管理数据
c) 通过结构化查询语言(SQL)操作数据
2.2 对象数据库
a) 处于研发阶段, 没有广泛使用
b) 把面向对象的方法和数据库技术结合起来
2.3 NOSQL 数据库
a) 泛指非关系数据库, 例如 Redis, MongoDB
b) 用于解决大规模和高并发的应用
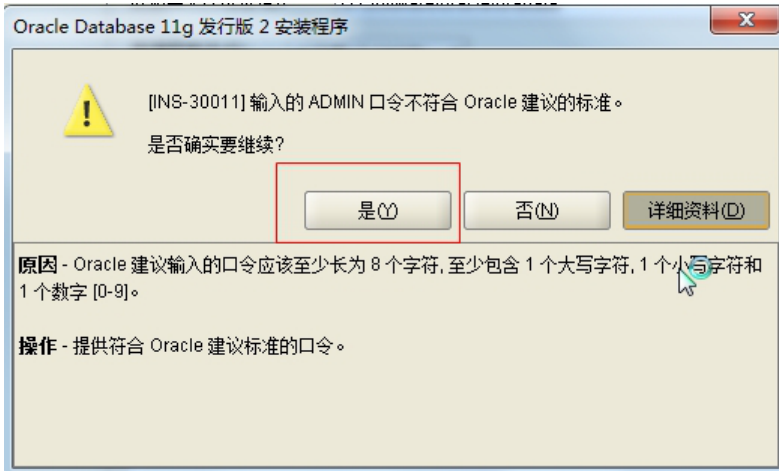
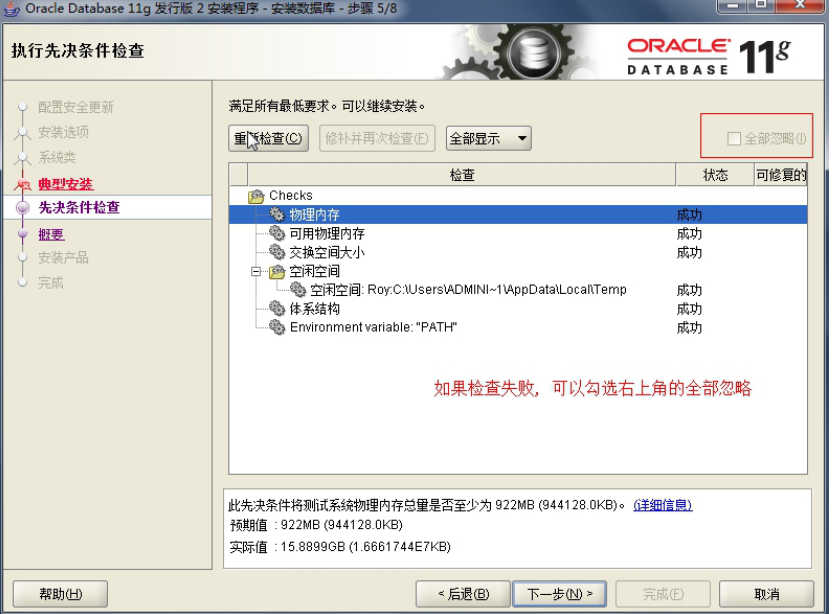
3. Oracle 安装过程
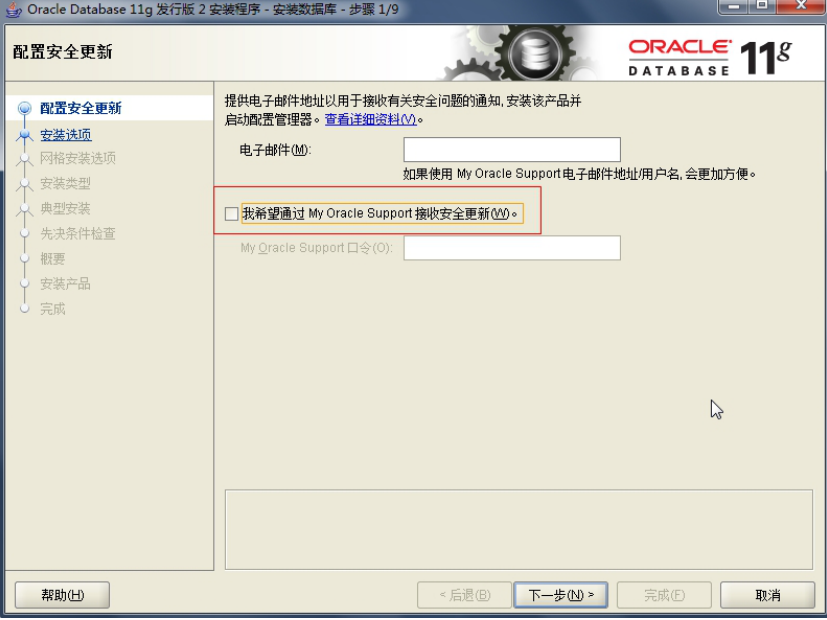
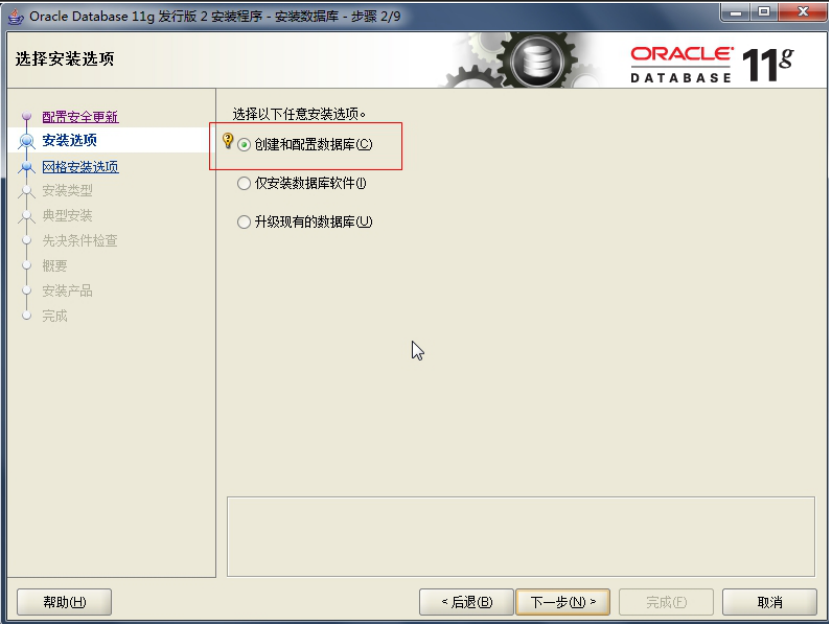
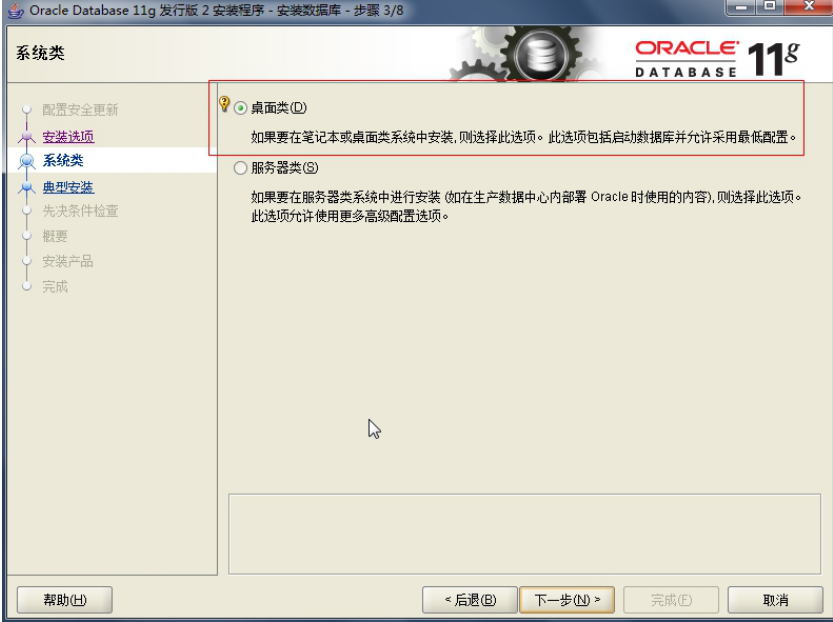
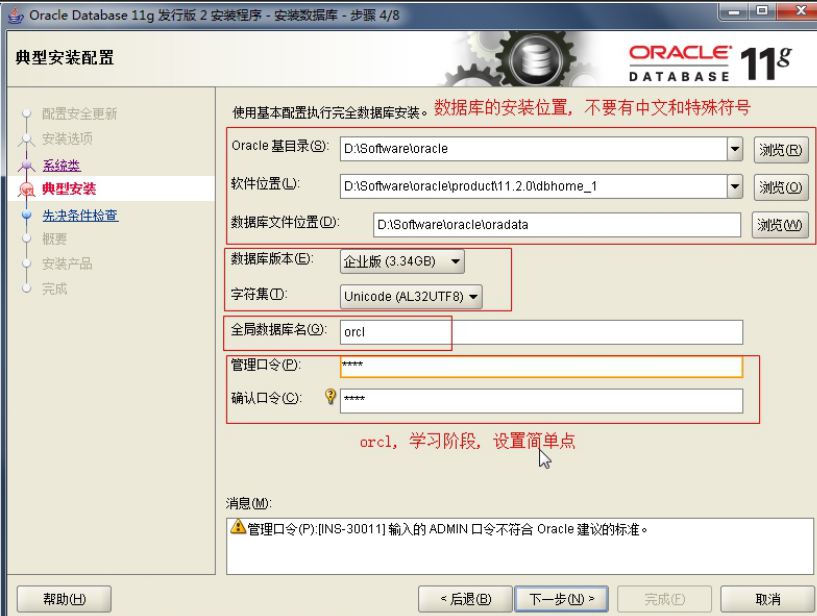

4. Oracle 目录结构和系统用户
4.1 目录结构
- a) D:\Software\oracle\oradata\orcl, 是用于存放 Oracle数据文件的目录
- b) D:\Software\oracle\product\11.2.0\dbhome_1, 数 据库安装位置
- c) D:\Software\oracle\product\11.2.0\dbhome_1\jdbc\lib, 存放 jdbc 数据库连接的驱动位置
- d) D:\Software\oracle\product\11.2.0\dbhome_1\jdk, Oracle 内置的 java 开发工具集
- e) D:\Software\oracle\product\11.2.0\dbhome_1\NETWORK\ADMIN,存放 Oracle 的配置信息(监听配置和本地网络服务名配置)
4.2 Oracle 的系统用户
- a) Oracle 数据库是基于用户的, 使用数据库时, 必须先登录要操作的用户.
- b) Oracle 安装完成后, 自带一些用户, 被称之为系统用户
- c) SYS, 是 Oracle 中权限最高的账户, 理解为超级管理员
- d) SYSTEM, 是管理员(DBA), 权限比 SYS 少, 普通管理员
- e) SCOTT, 是 Oracle 提供的一个测试用户, 其中自带了四张测试用表格, 可以供用户学习使用. SCOTT 用户的密码通常是 tiger(老虎)
4.3 Oracle 服务介绍
- a) OracleServiceORCL, 数据库的实例服务, 是 Oracle 的核心服务,Oracle 要使用, 必须开启这个服务.
- b) OracleOraDb11g_home1TNSListener, 数据库监听服务, 用来监听Oracle 数据库

5. Oracle 客户端
5.1 SQL Plus
是一个命令行客户端, Oracle 自带, 不需要安装其他的软件. 使用效果不好.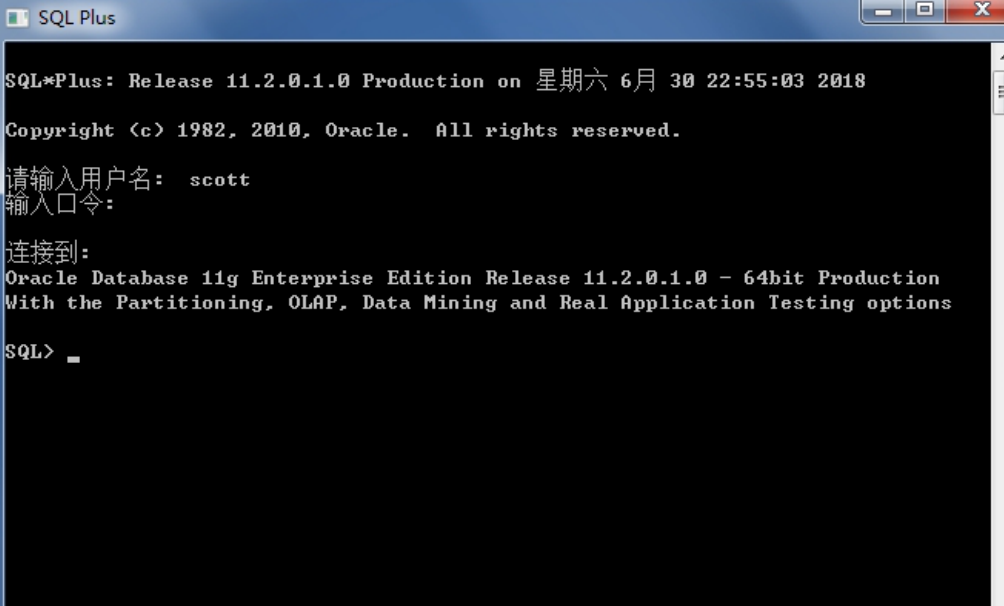
5.2 PLSQL Developer
图形界面客户端, 第三方专门给 Oracle 数据库提供的客户端. 必须安装软件, 使用效果较好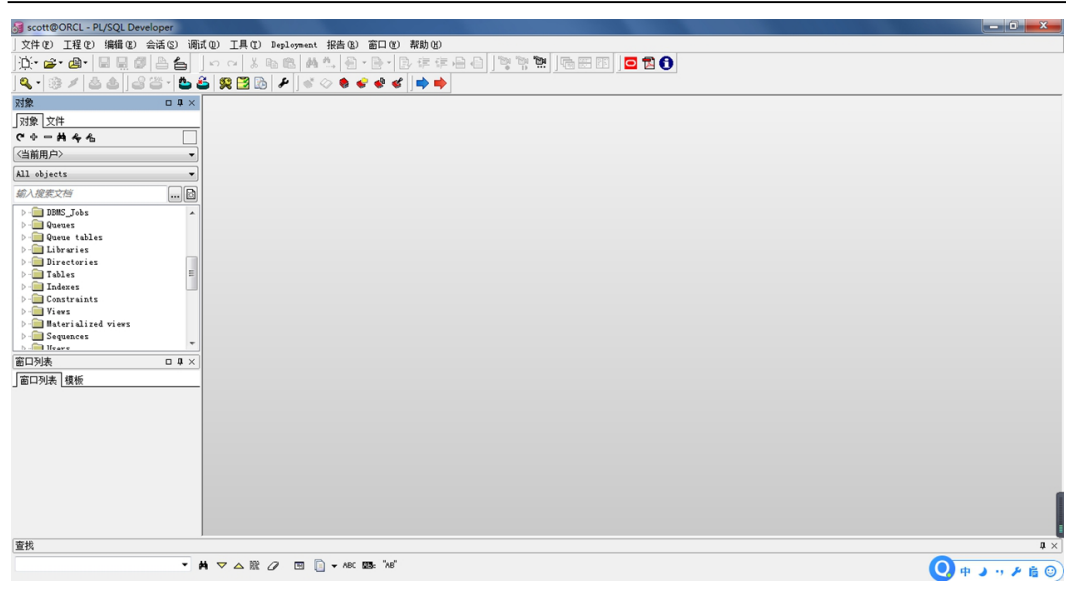
6. SCOTT 下的表格
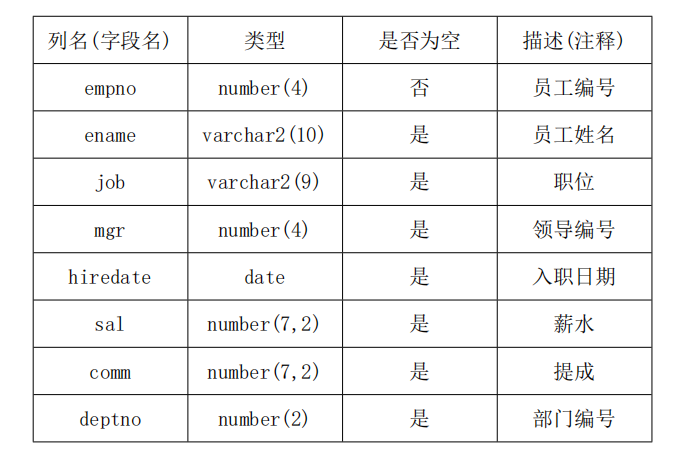
6.1 EMP(员工表, 雇员表) employee
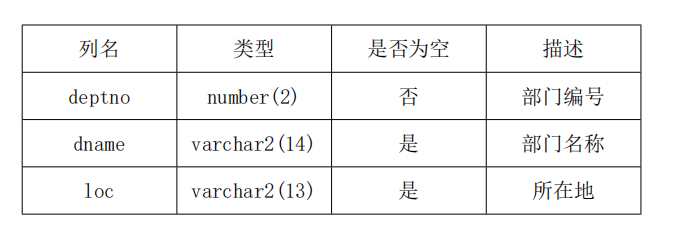
6.2 DEPT(部门表) department
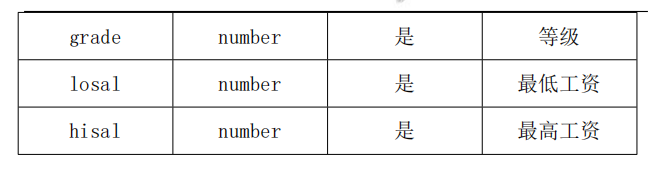
6.3 SALGRADE(薪资等级表) salary grade
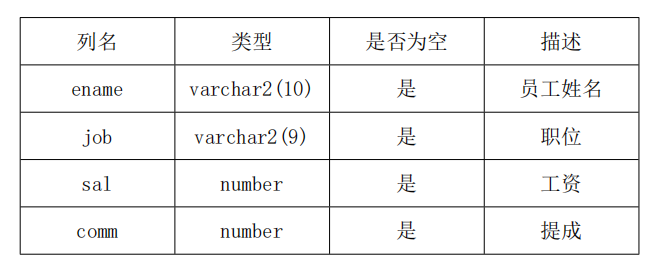
6.4 BONUS(津贴表)
7. Oracle 中常用的命令
7.1 查看用户所有的表格
select * from tab;
7.2 查看表结构
desc 表名;
7.3 查询表格数据
select * from 表名;
7.4 显示当前登录的用户
show user;
7.5 退出
exit
8. Oracle 连 接 配 置 (listenter.ora,tnsnames.ora)
8.1 协议适配器错误
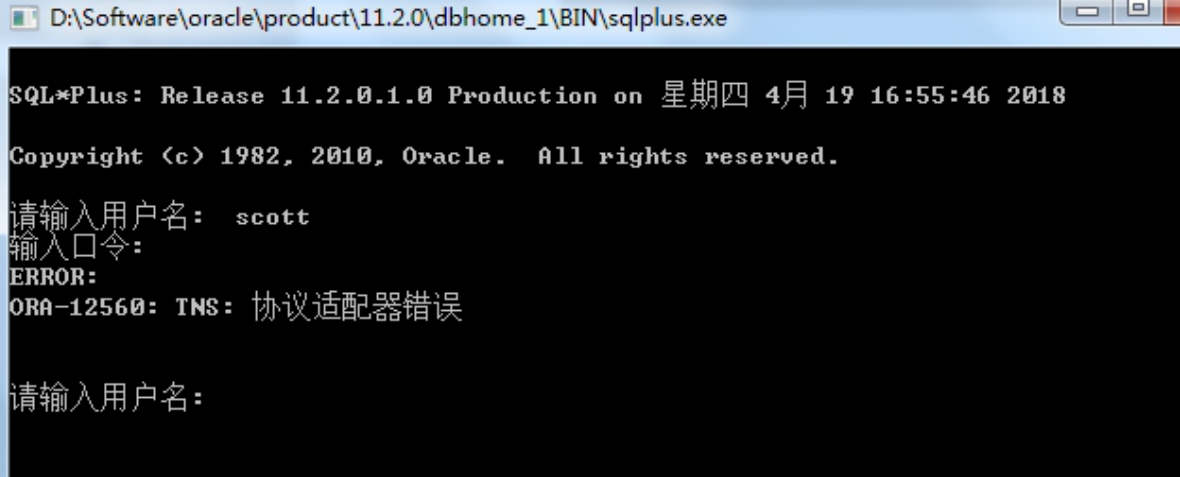
原因是数据库的实例服务没有启动, 启动实例服务即可解决
8.2 无监听程序
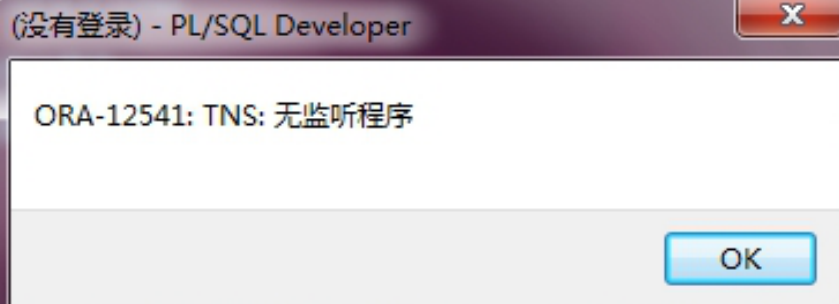
原因是没有启动监听服务, 启动监听服务即可解决
8.3 监听程序当前无法识别连接描述符中请求的服务
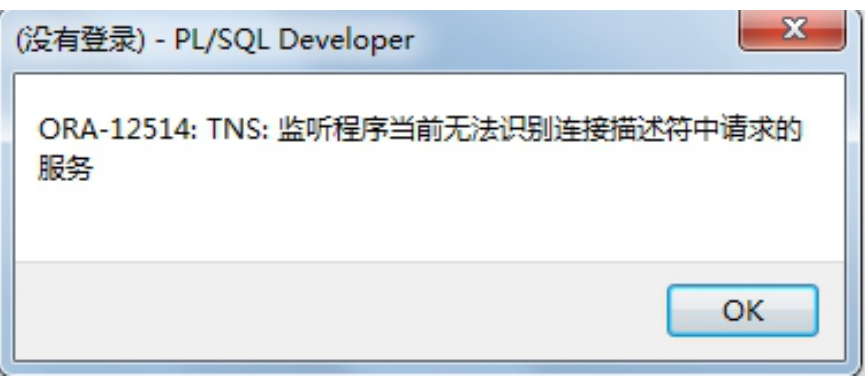
原因:
a)监听服务刚启动, 还没有反应过来
b)配置信息可能读取不到了, 需要重新配置 Oracle 连接
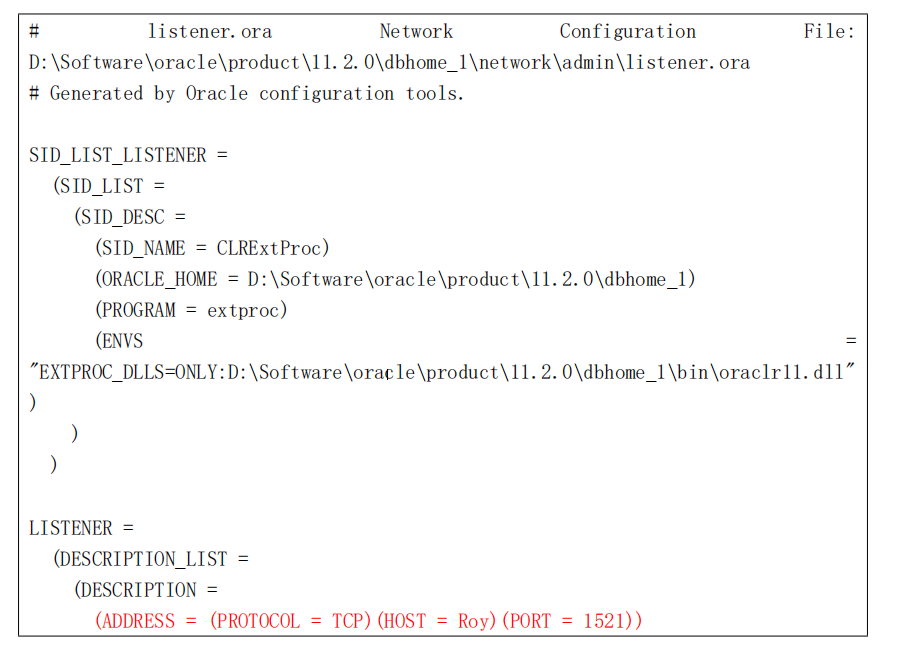
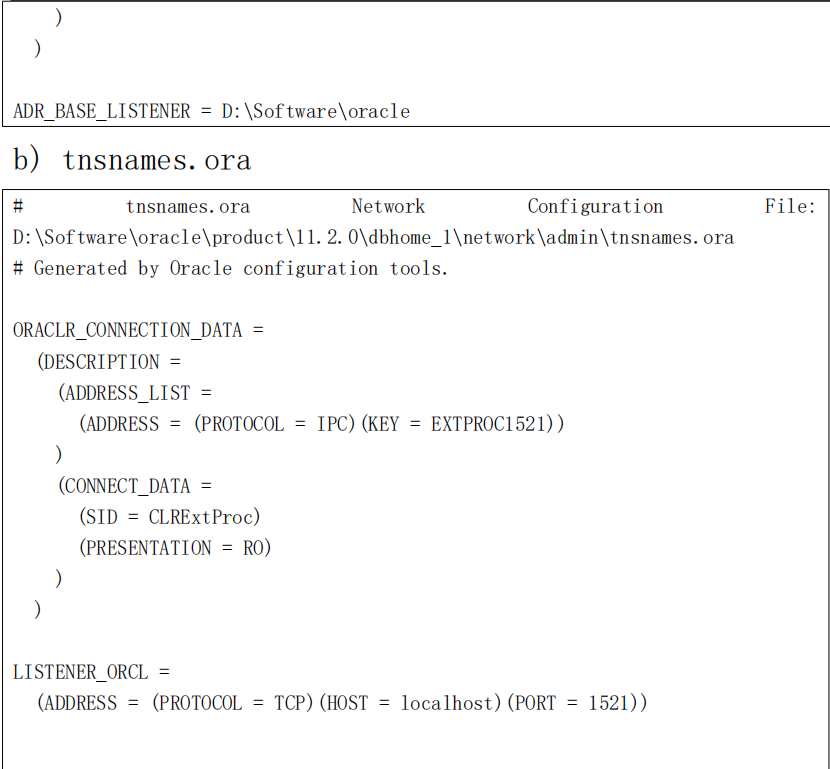
8.4 配置文件的详细信息
a) listener.ora
• 先睹为快
• select * from emp; • select * from emp order by sal desc ;
• select * from emp where ename like 'S%';
• select avg(sal), max(sal), min(sal), sum(sal) from emp;
• select deptno, avg(sal) from emp group by deptno;
• insert into student (id,name,age) values(2,'lkl',45);
• update student set score=88 where id=2;
• delete from student where id=2;
• CREATE USER bjsxt IDENTIFIED BY bjsxt;
• GRANT connect,resource TO bjsxt;
什么是SQL语言
• 结构化查询语言(Structured Query Language)(发音ˈes kjuːˈ)
• SQL是最重要的关系数据库操作语言,是所有关系数据库管理系统的标准语言
• 许多数据库厂商在使用SQL的同时,都对SQL进行了扩展,比如ORACLE的PL/SQL语言,MS
SQL-Server的T-SQL语言
• SQL语言是一种非过程化语言,只需要提出”做什么”,而不需要指明“怎么做” • SQL可以做什么
• 数据库数据的增删改查操作(CRUD)
• 数据库对象的创建,修改和删除操作
• 用户权限/角色的授予和取消
• 事务控制
SQL语言的分类
• DQL(数据查询语言)
- select
- • DML(数据操作语言)
• DDL(数据定义语言)
- • create、alter、drop
• DCL(数据控制语言)
- • grant、revoke
• TCL(事务控制语言)
- • SAVEPOINT 、 ROLLBACK、SET TRANSACTION ,COMMIT• 数据操作语言针对表中的数据,而数据定义语言针对数据库对象(表、索引、视图、触发器、存储过程、函数、表空间等)
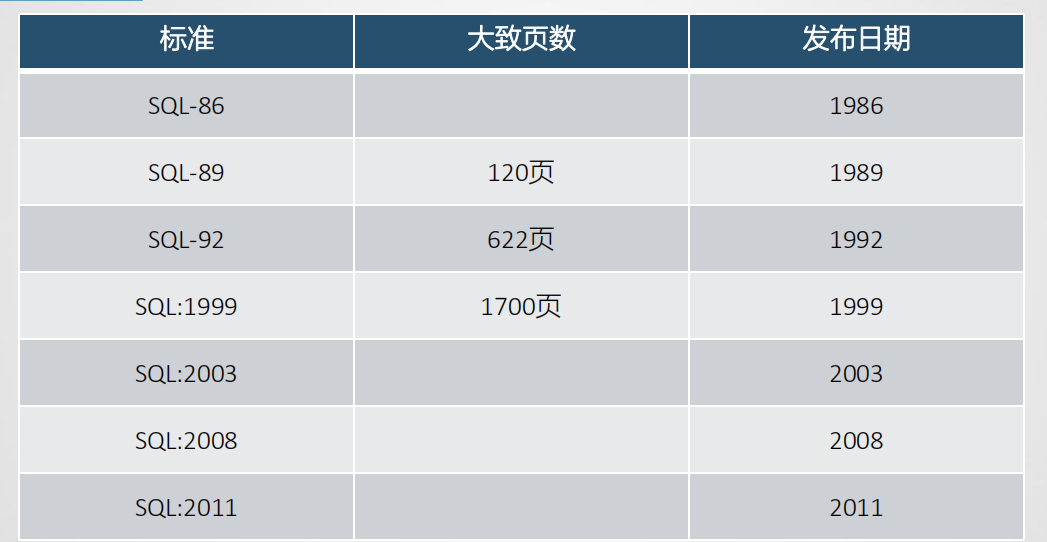
• SQL标准发展
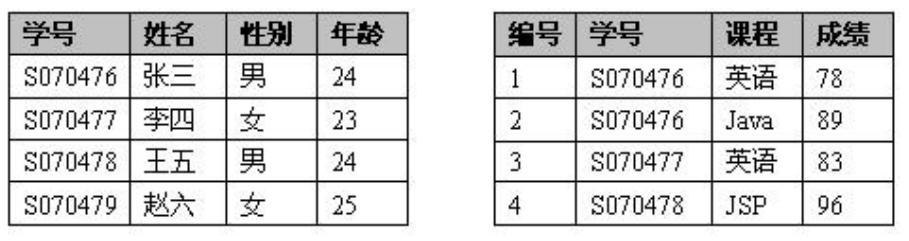
关系数据库基本概念
• 关系:整个二维表
• 关系名:表格名称
• 元组:行数据(记录)
• 属性:列数据(字段)
• 属性名:列名称(字段名)
• 主键:唯一确定元组的属性组(关键字)
• 域:属性的取值范围
最简单的查询方式
• select * from emp; • select * from dept; • select empno, ename,sal from emp;
• 使用算术表达式
• select empno, ename,sal,sal*1.08 from emp; • select empno, ename,sal, sal*12 from emp; • select empno, ename,sal, sal*12 +1000 from emp;
• 注:在Select语句中,对数值型数据可以使用算术运算符创建表达式
使用字段别名
• select empno as 员工编号, ename 员工姓名, sal*12 年薪 from emp;
• select empno, ename "Ename", sal*12 "Anual Salary" from emp;
• select sal*12+5000 as "年度工资(加年终奖)" from emp; • 字段别名
• 重命名查询结果中的字段,以增强可读性
• 别名如果含有空格或其他特殊字符或大小写敏感,需用双引号引起来。
• AS可以省略
• 缺省情况下,查询结果中包含所有符合条件的记录行,包括重复行
• select deptno from emp; • 使用DISTINCT关键字可从查询结果中清除重复行
• select distinct deptno from emp; • select distinct job from emp; • DISTINCT的作用范围是后面所有字段的组合
• select, distinct deptno job from emp;
使用order by 子句对查询结果进行排序
• 排序方式包括升序(asc,缺省)和降序(desc)两种:
• select empno, ename, sal from emp order by sal; • select empno, ename, sal from emp order by sal desc ; • 按多字段排序
• select deptno, empno, ename, sal from emp order by deptno, sal; • 使用字段别名排序
• select empno, ename, sal*12 annsal from emp order by annsal
指定查询条件使用where子句
• 用法举例
• select * from emp where deptno=10; • select * from emp where ename = 'SMITH'; • select * from emp where hiredate = '02-4月-81'; • 注意:
• 字符串和日期值要用单引号扩起来
• 字符串大小写敏感
• 日期值格式敏感,缺省的日期格式是'DD-MON-RR‘
查询条件中可以使用比较运算符
• select * from emp where sal > 2900;
• select * from emp where deptno <> 30;//不等于
• select * from emp where sal between 1600 and 2900;
• select * from emp where ename in('SMITH','CLARK','KING');
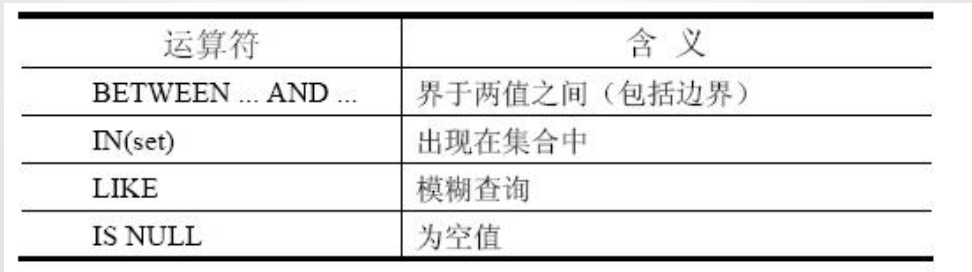
使用LIKE运算符执行模糊查询(通配查询)
• % 表示零或多个字符 _ 表示一个字符
• 对于特殊符号可使用ESCAPE 标识符来查找
用法举例
• select * from emp where ename like 'S%';
• select * from emp where ename like '_A%';
• select * from emp where ename like '%\_%' escape '\';
使用IS NULL运算符进行空值判断
用法举例
• select * from emp where comm is null;
• select * from emp where comm is not null;
查询条件中可以使用逻辑运算符
• select * from emp where deptno = 10 and sal > 1000;
• select * from emp where deptno = 10 or job = ‘CLERK’;
• select * from emp where sal not in (800, 1500, 2000);
SQL优化问题:
• AND: 把检索结果较少的条件放到后面
• OR: 把检索结果较多的条件放到后面
• 共计四种运算符:算术>连接>比较>逻辑

可使用小括号强行改变运算顺序
• select * from emp where job='SALESMAN' or job='CLERK' and sal>=1280;
• select * from emp where (job='SALESMAN' or job='CLERK') and sal>=1280;
使用函数可以大大提高SELECT语句操作数据库的能力;它给数据的转换和处理提供了方便。
• 函数只是将取出的数据进行处理,不会改变数据库中的值。
• Oracle函数分为单行函数和多行函数两大类
• 单行函数分类
• 字符函数 数值函数 日期函数
• 转换函数 通用函数
• 多行函数
• sum() avg() 仅适用数值型
• count() max() min() 适用任何类型数据
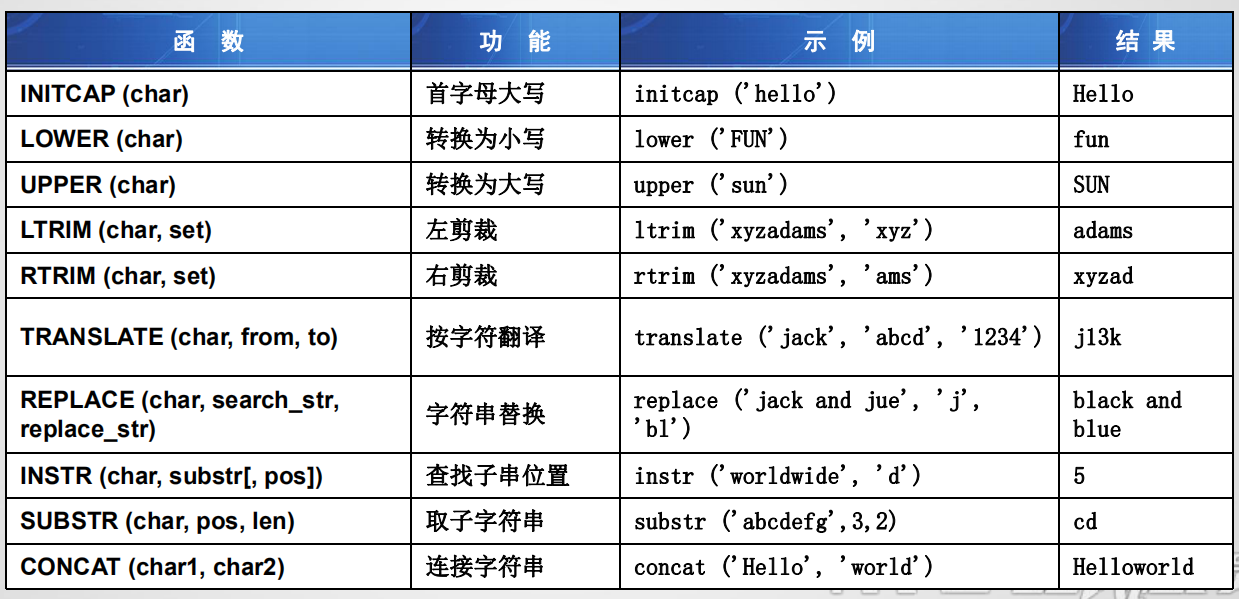
字符函数
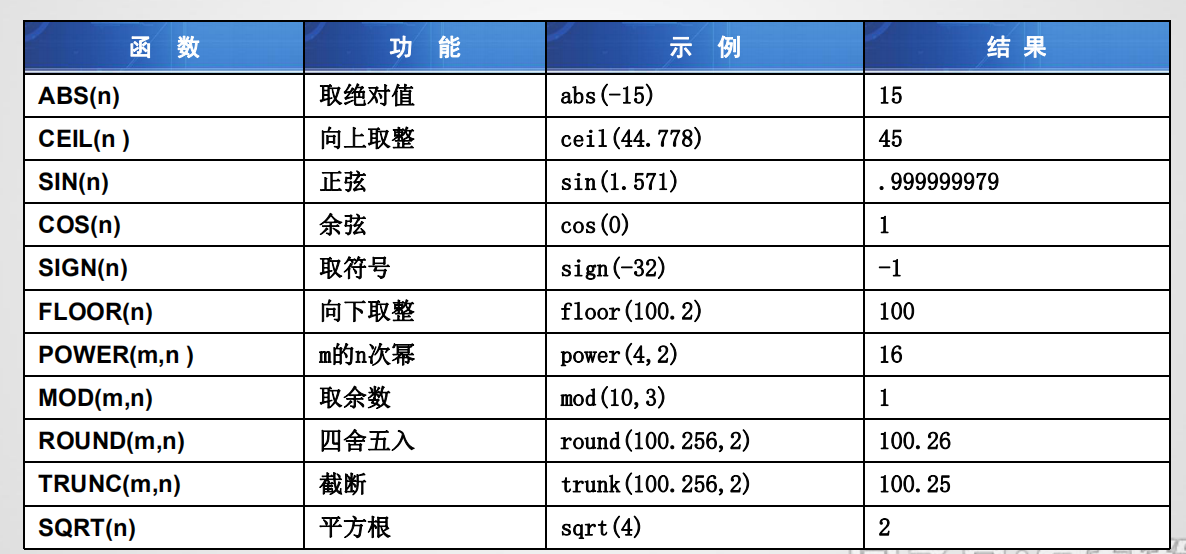
数值函数
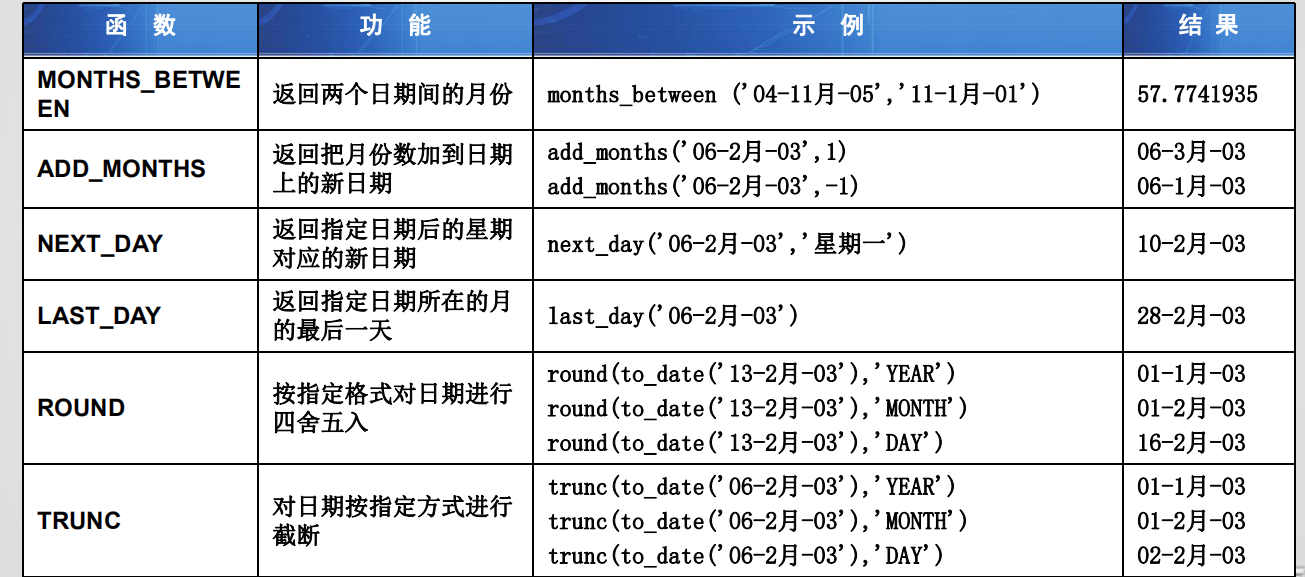
日期函数
转换函数
• Oracle的类型转换分为自动类型转换和强制类型转换。
• select '12.5'+30 from dual;
• select '12.5'||30 from dual;
• 尽管数据类型之间可以进行自动转换,仍建议使用显示转换函数,以保持良好的设计风格。
常用类型转换函数有to_char(), to_date(), to_number()。
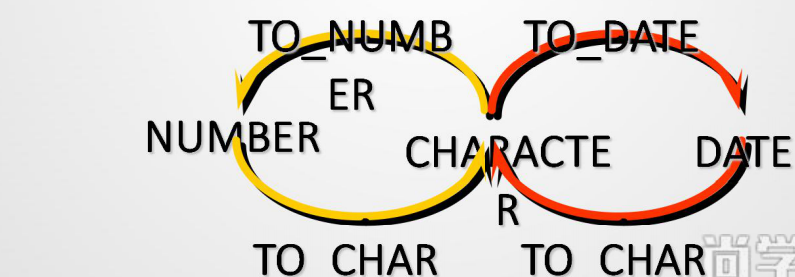
• to_char(num,format)
• to_char(date,format)


--ceil向上取整 select ceil(1263.00235)from dual; --floor 向下取整 select floor(123.999)from dual; --round 四舍五入,第二个参数可以控制四舍五入的位数,正数表示小数点后,负数表示小数点前。 select round(123995.235,1)from dual; select round(12351.213,-1)from dual; --2.2trunc 截断 select trunc(123.456)from dual; select trunc(123.456,1)from dual; select trunc(123.456,-2)from dual; --2.3日期函数 --2.3.1 months_between -- 计算两个日期间的月数 select sysdate from dual; --a)查询所有员工的入职的月数 select ename,months_between(sysdate,hiredate)from emp; select ename,months_between(hiredate,sysdate)from emp; --表示天数 select sysdate-hiredate from emp; select sysdate,sysdate+1 from dual; --2.3.2 --add_months --给日期加减月数 select sysdate,add_months(sysdate,5)from dual; select sysdate,add_months(sysdate,-5)from dual; --2.3.3 --last_dsy --计算出给定日期所在月份的最后一天是哪个日期 select sysdate,last_day(sysdate)from dual; select last_day('1-2月-2018')from dual; --2.3.4next_day --基于给定日期计算下个给定的星期几是什么日期 select sysdate,next_day(sysdate,'星期一')from dual; --2.4转换函数 --用于在不同数据类型间进行转换,数值类型number,字符串类型varchar2,日期类型date --select * from emp where hiredate='123';error --to_number将字符串转换成数字 --to_date 将字符串转换成日期 --to_char 将日期或者数字转换成字符串 select 1+'1' from dual; --2.4.1 to_number --将字符串转换成数字,涉及到钱的时候,$123,123,123.00 select to_number('¥123,123,123.00','L999,999,999.00')from dual; select to_char(1234.34,'9,9,9,9.$99')from dual; select to_char(1234,'9999') from dual; select to_char(123.23,'999.$99')from dual; --2.4.2 to_date select to_date('2022-12-12 23:21:20','YYYY-MM-DD HH24:MI:SS') from dual; --2.4.3 to_char select to_char(1313131,'L999,999,999.00') from dual; select sysdate, to_char(sysdate,'yyyy"年"mm"月"dd"日" hh24:mi:ss')from dual;
日期字符串转换函数:to_char()
• to_char()函数可以将日期型数值转换为字符串形式
• to_char(date) //缺省转换为'dd-mon-yy'格式
• to_char(date,‘format_model’) //转换为模式串指定的格式
使用举例
• select empno, ename, sal, to_char(hiredate,'yyyy-mm-dd') from emp;
• SELECT TO_CHAR(sysdate,'YYYY-MM-DD HH24:MI:SS AM DY') FROM dual;
• SELECT TO_CHAR(sysdate,'YYYY"年"MM"月"DD"日"') FROM dual;
说明
• 缺省的日期格式是DD-MON-YY
• 可使用sysdate函数获取当前系统日期和时间
• 日期字符串转换函数:to_date()
• to_date()函数可以将字符串转换为日期类型
• 格式:
• to_date(char) //按缺省格式进行解析
• to_date(char,‘format_model’) //按模式串指定的格式进行解析
• 使用举例
• insert into test2 values('Tom', to_date('2008-02-28 ', 'yyyy-mm-dd '));
• 问题:查询入职时间某个时间点之后的员工信息
• 使用to_char()
• 使用to_date()
• 使用默认的时间格式
其他函数
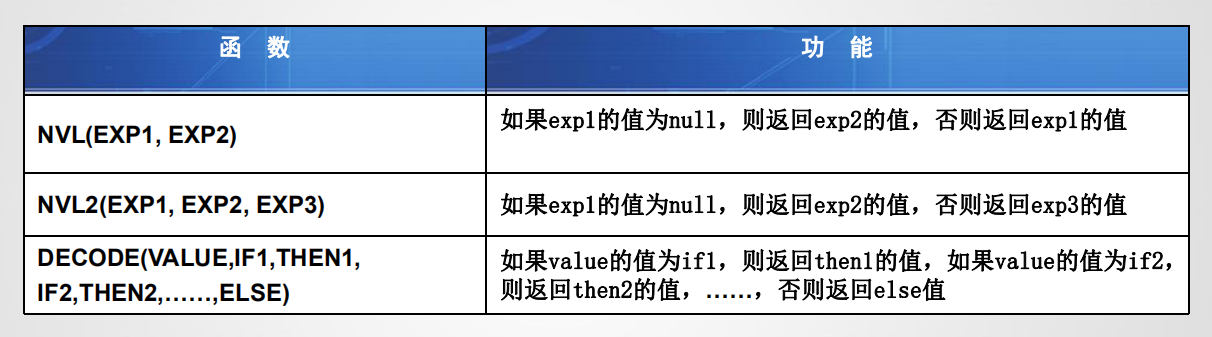
通用函数:NVL()函数
• NVL()函数用于将空值null替换为指定的缺省值,适用于字符、数字、日期等类型数据。
• 语法格式:NVL(exp1, exp2)
• 说明:如果表达式exp1的值为null,则返回exp2的值,否则返回exp1的值。
用法举例:
• select empno, ename, sal, comm, sal + nvl(comm, 0) from emp;
• select empno, ename, hiredate, nvl(hiredate, sysdate) from emp;
• select empno, ename, job, nvl(job, 'No job yet') from emp;
通用函数:NVL2()函数
• NVL2()函数用于实现条件表达式功能。
• 语法格式:NVL2(exp1, exp2, exp3)
• 说明:如果表达式exp1的值不为null,则返回exp2的值,否则返回exp3的值。
用法举例:
• select empno, ename, sal, comm, nvl2(comm, sal+comm, sal) total from emp;
通用函数:NULLIF
通用函数:NULLIF(expr1,expr2)函数:比较两个表达式,如果相等,函数返回空,如果不相等,函数返回第一个表达式。第一个表达式不能为null.
expr1是对于expr2的被比较原值。
expr2是对expr1的被比较原值。(如果它不等于expr1,expr1被返回)。
示例四:
查询雇员,显示他们的first_name与长度,长度列命名为expr1.last_name与长度,长度命名为expr2.判断他们的first_name与last_name的长度,如果长度相同返回空,否则返回first_name的长度。判断结果命名为result。
select
first_name,length(first_name) "expr1" ,last_name, length(last_name) "expr2" ,nullif(length(first_name),length(last_name)) "result"
from employees;
通用函数:coalesce
通用函数:coalesce(expr1,expr2,..exprn)函数:返回列表中的第一个非空表达式。
expr1 如果它非空,返回该表达式。
expr2如果第一个表达式为空并且该表达式非空,返回该表达式。
exprn如果前面的表达式都为空,返回该表达式。
示例五:
查询雇员表,如果commission_pct值是非空,显示它。如果commission_pct值是空,显示salary。如果commission_pct和salary值都是空,那么显示10。
select first_name,coalesce(commission_pct,salary,10) from employees order by first_name;
条件表达式
在sql语句中提供if-then-else逻辑的使用
两种用法:
case 表达式
decode函数
case表达式
使得if-then-else条件判断容易实现
case expr when comparison_expr1 then return_expr1
[when comparison_expr2 then return_expr2
when comparison_eprn then return_exprn
else else_expr]
case表达式:case表达式可以让你在sql语句中使用if-then-else逻辑。如果没有when...then满足条件,并且else子句存在,oracle返回else_expr。否则,oralce返回null。所有的表达式(expr、comparison_expr和return_expr)必须是相同的数据类型。
示例:
查询雇员,显示last_name ,job_Id,salary如果job_id是it_prog,薪水增加10%;如果job_id是st_clerk,薪水增加15%;如果job_id是sa_rep,薪水增加20%。对于所有其他的工作角色,不增加薪水。
select last_name ,job_id ,salary , case job_id
when 'IT_PROG' then salary *1.1
when 'st_cleark' then salary*1.15
when 'sa_rep' then salary*1.2
from employees;
decode函数
使得case或者if-then-else条件判断容易实现:
decode(col|expression, search1,result1
[,search2,result2,...,]
[,default ])
decode函数:decode函数以一种类似在多种语言中使用的if-then-else逻辑的方法判断一个表达式。decode函数比较表达式(expression)和每个查找(search)值后,如果表达式与查找相同,返回结果。如果省略默认值,当没有查找值与表达式相匹配时返回一个空值。
示例:
使用decode函数完成(查询雇员,显示last_name ,job_Id,salary如果job_id是it_prog,薪水增加10%;如果job_id是st_clerk,薪水增加15%;如果job_id是sa_rep,薪水增加20%。对于所有其他的工作角色,不增加薪水。)
select last_name ,job_Id ,salary ,decode(job_id,'it_prog','salary*1.1', 'st_clerk',salary*1.15, 'sa_rep',salary*1.2)from employees;
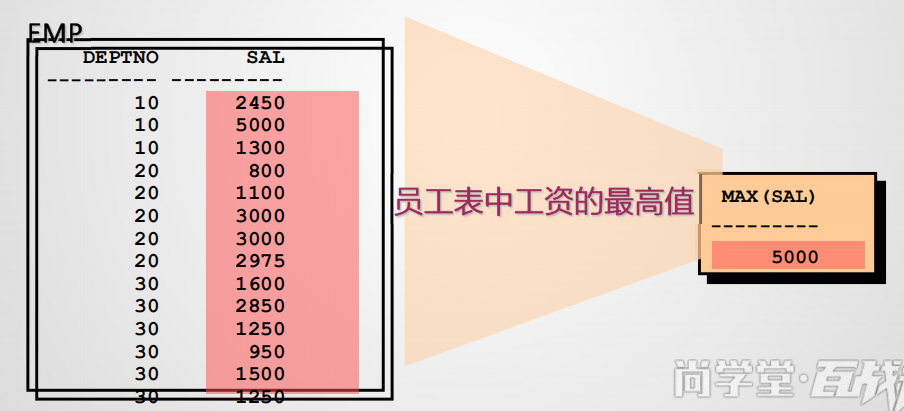
多行函数
• 对一组数据进行运算,针对一组数据(多行记录)只返回一个结果,也称分组函数。
常用多行函数
• sum() avg() 仅适用数值型
• count() max() min() 适用任何类型数据
• select avg(sal), max(sal), min(sal), sum(sal) from emp;
• select max(hiredate), min(hiredate) from emp;
• 多行函数与空值
• 多行函数除了count(*)外,都跳过空值而处理非空值
• select count(comm),sum(comm),avg(comm) from emp;
• 可使用NVL()函数强制多行函数处理空值
• select count(nvl(comm,0)),sum(nvl(comm,0)),avg(nvl(comm,0)) from emp;
count()函数
• count(*)返回组中总记录数目;
• count(exp)返回表达式exp值非空的记录数目;
• count(distinct(exp))返回表达式exp值不重复的、非空的记录数目。
• select count(*) from emp;
• select count(comm) from emp;
• select count(distinct(deptno)) from emp;
• select count(nvl(comm,0)) from emp;
--2.6分组函数(聚组函数) --2.6.1 sum --求和 --查询所有员工的工资总和 select sum(sal) from emp; --2.6.2 ave --求平均值 --查询平均工资 select avg(sal)from emp; --2.6.3 max --统计公司最高工资 select max(sal) from emp; --2.6.4min --求最小值 --统计公司的最低工资 select min(sal)from emp; --2.6.5 count --计数 --统计公司人数 select count(empno)from emp; select count(*) from emp; //这张表有多少行 select count(comm) from emp;//对空值不做处理
GROUP BY 子句将表中数据分成若干小组
• 语法格式
• select column, group_function(column)
• from table
• [where condition]
• [group by group_by_expression]
• [order by column];
使用举例
• select deptno, avg(sal) from emp group by deptno;
• select deptno, job, count(*),avg(sal) from emp group by deptno, job;
注意事项
• 出现在SELECT列表中的字段,如果不是包含在多行函数中,那么该字段必须同时在GROUP BY
子句中出现。
• 错误:select ename,job,sum(sal) from emp group by job; • 包含在GROUP BY子句中的字段则不必须出现在SELECT列表中。
• 如果没有GROUP BY子句,SELECT列表中不允许出现字段(单行函数)与多行函数混用的情况
• select empno, sal from emp; //合法
• select avg(sal) from emp; //合法
• select empno, avg(sal) from emp; //非法
• 不允许在WHERE 子句中使用多行函数
• select deptno, avg(sal) from emp
• where avg(sal) > 2000; //执行where时尚未执行groupby 及其他
• group by deptno;
• 对分组查询的结果进行过滤,要使用having从句。
• having从句过滤分组后的结果,它只能出现在group by从句之后,而where从句要出现
在group by从句之前。
• where过滤行,having过滤分组。having支持所有where操作符。
• 语法格式
• select column, group_function(column)
• from table
• [where condition]
• [group by group_by_expression]
• [having group_condition]
• [order by column];
• 执行过程:from--where -- group by– select-having- order by
• 用法举例
• 在emp表中,列出工资最小值小于2000的职位。
• 思考:select job,min(sal) from emp where min(sal)<=2000
• Select job,min(sal) from emp group by job having min(sal)<2000
• 列出平均工资大于1200元的部门和工作搭配组合
• select deptno, job, avg(sal) from emp
• group by deptno,job having avg(sal) > 1200 order by deptno,job;
• 思考:
• 统计人数小于4的部门的平均工资。
• 统计各部门的最高工资,排除最高工资小于3000的部门
--1. group by --进行分组查询,group by子句可以将查询分为若干个组 --1.1分组查询 --a) 统计每个部门的编号,最高工资和最低工资 select deptno,max(sal),min(sal) from emp group by deptno order by deptno; select * from emp; --1.2带where的分组查询 --a)查询每个部门的人数和平均工资,排除10部门 --注意:group by子句要写到where子句的后面 select deptno,count(*),avg(sal)from emp group by deptno select deptno,count(*),avg(sal) from emp where deptno<>10 group by deptno order by deptno; --having --用于过滤分组后的条件 --where子句中不允许使用使用分组函数 --a)查询每个部门的总工资和平均工资,排除平均工资不低于1600 --select deptno,sum(sal),avg(sal) from emp where avg(sal)>=1600 group by deptno; select deptno,sum(sal),avg(sal) from emp group by deptno having avg(sal)>=1600 order by deptno ; --1.4select 语句的执行顺序 from-> where->group by ->select >having->order by ---在emp表中列出工资最小值小于2000的职位 select job, min(sal) from emp group by job having min(sal)<2000; --列出平均工资大于1200元的部门和工作搭配组合 select deptno,job from emp group by deptno,job having avg(sal)>1200 order bydeptno;
• 往表中插入数据的语句是insert语句,方式有两种,一种是记录值的插入,一种是查
询结果的插入
• 记录值的插入语法如下:
• INSERT INTO table [(column [, column...])]
• VALUES (value [, value...]);
• 一次插入操作只插入一行
DML
• 可以添加所有列
• insert into emp (empno,ename,job,mgr,hiredate,sal, comm, deptno)
values(1111,'gao','clerk',7902,sysdate, 10000,3000,40)
• 此处插入的元组中列的个数、顺序与emp的结构完全一致,因此表名之后的列名可以省略不
写
• insert into emp values(2222,'gaohs','clerk',7902,sysdate,10000,3000,40)
• 也可以只添加部分列
• insert into emp(empno,ename) values (3333,'xiaozhang')
• 但要求省略的列必须满足下面的条件:
• 该列定义为允许Null值。
• 在表定义中给出默认值,这表示如果不给出值,将使用默认值。
• 如果不符合上面两个条件,将会报错。不能成功插入
• 可以用insert语句把一个select语句的查询结果插入到一个基本表中,语法如下:
• Insert into tablename(column,..) • select * from tablename2
• 创建一个临时表
• create table temp
• as
• select * from emp
• where 1 = 2
• 执行插入
• insert into ss select * from emp;
• Update语句用于修改基本表中元组的某些列,其语法如下:
• UPDATE table
• SET column = value [, column = value] …
• [WHERE condition];
• 其语义是:修改基本表中满足条件表达式的那些元组的列值,需修改的列值在set子
句中指出。
SSXXTT DML—update语句 A
• SQL的删除操作是指从基本表中删除元组,语法如下:
• DELETE [FROM] table
• [WHERE condition];
• 其语义是从基本表中删除满足条件表达式的元组
• delete from table 表示从表中删除一切元组
• 如果想从表中删除所有的行,不要使用delete,可使用truncate table 语句,完成相同
的工作,但是速度更快。
SSXXTT 作业
• 精通select语句各个子句的使用
• 熟练常用函数的使用
--2.DML --2.1复制一个测试表格 --a)复制emp表格,命名为tmp create table temp as( select * from emp); select * from temp; --b)赋值emp表格的表结构,不复制数据 -- create table temp2 as(select * from emp where 1=2); select * from temp2; --2.2新增(inset into) --a) 语法 --insert into 表名[(列1,列2....)]values(值1,值2...); --b)向temp2表格插入一条数据 --新增数据 insert into temp2(empno,ename,job,mgr,hiredate,sal,comm,deptno) values(1234,'小明','学生',1111,to_date('2008-8-8','yyyy-mm-dd'),3000,200,10); --c)注意,当表格的每一列都要插入数据时,可以省略列名不写 insert into temp2 values(1234,'小明','学生',1111,to_date('2008-8-8','yyyy-mm-dd'),3000,200,10); --d)向表格插入一条数据,只有编号和姓名 insert into temp2(empno,ename) values(1235,'小刚'); --2.3修改(update) --a)语法 --update 表名 set 列1=值1【,列2=值2..】[where 条件] --b)将10部门员工的工资调高10% update temp2 set sal=sal*1.1 where deptno=10; --2.4删除(delete from) --a)语法 --delete [from] 表名[where 条件]; ---b)删除编号为1234员工信息 delete from temp2 where empno=1234; delete temp2 where empno=1234;
SQL99的多表连接查询
• SQL1999规范中规定的连接查询语法
• select 字段列表
• from table1
• [cross join table2] | //1:交叉连接
• [natural join table2] | //2:自然连接
• [join table2 using (字段名)] | //3:using子句
• [join table2 on (table1.column_name
• = table2.column_name)] | //4:on子句
• [(left | right | full outer) join table2
• on (table1.column_name = table2.column_name)]; //5:左/右/满外连接
2.1:交叉连接
• Cross join产生了一个笛卡尔集,其效果等同于在两个表进行连接时未使用WHERE子句限定连
接条件; • 可以使用where条件从笛卡尔集中选出满足条件的记录。
• 用法举例
• select dept.deptno,dname,ename,job
• from dept cross join emp;
2.2:自然连接
• Natural join基于两个表中的全部同名列建立连接
• 从两个表中选出同名列的值均对应相等的所有行
• 如果两个表中同名列的数据类型不同,则出错
• 不允许在参照列上使用表名或者别名作为前缀
• 自然连接的结果不保留重复的属性
• 举例:
• select empno, ename, sal, deptno, dname
• from emp natural join dept • where deptno = 10;
2.3:Using子句
• 如果不希望参照被连接表的所有同名列进行等值连接,自然连接将无法满足要求,可以在连接时使用USING子句来设置用于等值连接的列(参照列)名。
• using子句引用的列在sql任何地方不能使用表名或者别名做前缀
• 举例:
• select e.ename,e.ename,e.sal,deptno,d. dname
• from emp e join dept d
• using(deptno)
• where deptno=20
2.4:On子句
• 自然连接的条件是基于表中所有同名列的等值连接
• 为了设置任意的连接条件或者指定连接的列,需要使用ON子句
• 连接条件与其它的查询条件分开书写
• 使用ON 子句使查询语句更容易理解
• select ename,dname
from emp join dept on emp.deptno=dept.deptno
where emp.deptno=30;
• select empno, ename, sal, emp.deptno, dname
from emp join dept
on (emp.deptno = dept.deptno and job='SALESMAN);
--sql连接查询 --交叉连接 cross join --交叉连接会产生一个笛卡尔积,在笛卡尔积中很多数据是无意义的,所以需要消除,可以通过where子句来消除 --笛卡尔积 select * from emp cross join dept; select * from emp; select * from dept; select * from emp cross join dept where emp.deptno=dept.deptno; select emp.* ,dept.dname,dept.loc from emp cross join dept where emp.deptno=dept.deptno; select emp.* ,dname,loc from emp cross join dept where emp.deptno=dept.deptno; --可以在查询时给表格取别名 select e.*,dname,loc from emp e cross join dept where e.deptno=dept.deptno; --natural join 用于针对多张表的同名字段进行等值连接 select * from emp e natural join dept d; --特点: --a在自然连接时,自动进行所有同名列的等值连接,不需要写连接的条件 --b 同名列只显示一列,不能加前缀 --查询所有员工的姓名,部门编号和部门名称 select ename,deptno,d.dname from emp e natural join dept d; --3.3 using子句 --用于指定等值连接的同名字段,针对自然连接提供。 --a查询20部门员工的姓名,工资,部门编号和部门名称。 select e.ename deptno,d.dname ,e.sal from emp e natural join dept d where deptno=20; select e.ename,e.sal,deptno,d.dname from emp e join dept d using(deptno)where deptno=20; --on子句 --on子句是使用非常广泛的子句,它可以被用来指定连接的条件 --a查询所有员工的姓名,工资,和工资等级 select * from salgrade; select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal>=s.losal and e.sal <=s.hisal; select e.ename,e.sal,s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal; --b查询30部门员工的编号,姓名,部门名称和所在地 select e.empno,e.ename,d.dname,d.loc from emp e join dept d on e.deptno=d.deptno where d.deptno=30; --c查询所有员工的姓名,工资,部门名称及工资等级。 --n张表连接,至少需要n-个连接条件 select e.ename ,e.sal,s.grade from emp e join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal; select e.ename ,e.sal,s.grade from emp e natural join dept d join salgrade s on e.sal between s.losal and s.hisal;
等值连接
什么是等值连接
等值连接被称为简单连接或者内连接。是通过等号来判断连接条件中的数据值是否相匹配。
select last_name,department_name from employees,departments where employees.department_id=departments.department_id;
内连接,外连接实际上都是在笛卡尔积(join)的基础上对记录进行筛选。
等值连接和非等值连接:这两者同时包含在内连接和外连接中,因为内连接和外连接都是需要连接条件的,条件为=则为等值连接,反之为非等值连接。
自然连接:等值连接的一种,使用natural join后面可以不使用on接查询条件,默认会将关联表中的相同字段进行比较,查询出的结果相同的字段会去重(值必须相等)。
内连接:使用inner join和join连接都行,重点是要有查询条件,条件使用on或者where引导查询都行,查询出的结果为两表都匹配的记录。
外连接:分为左外连接,右外连接,要有查询条件,条件只能使用on引导查询。左外连接查询出的结果除了两表都匹配的记录外,还会查询出左表的其余记录,同时右表对应记录置为null,左外连接则相反。
inner join(内连接)(自然连接)
格式:select * from 部门 inner join 组织 on 部门.组织编号 = 组织.编号
目的:将两表中符合on条件的所有记录都找出来。
规律:
1. 拼出的大表记录不会增加。
2. 如果左边与右表的关系是一对多的关系,在选出的任一记录中,假若右表有多个记录与其对应,那么,连接后的左表,主键将不再唯一。
典型应用:将存在多关系的引用表放在左表,将存在一关系的被引用表放在右表,通过=号将主外键进行连接,通过对右表设定过滤条件,选出相应的且主键唯一的左表记录。
备注:inner join 是默认的连接方式,可缩写为join。
• 2.5:外连接
• 左外联接
• 两个表在连接过程中除返回满足连接条件的行以外,还返回左表中不满足条件的行,这种连接称为左
外联接。
• 右外联接
• 两个表在连接过程中除返回满足连接条件的行以外,还返回右表中不满足条件的行,这种连接称为右
外联接。
• 满外联接
• 两个表在连接过程中除返回满足连接条件的行以外,还返回两个表中不满足条件的所有行,这种连接
称为满外联接。
• 内连接:在SQL99规范中,内连接只返回满足连接条件的数据
• 外连接举例
外连接除了能显示满足连接条件的数据以外,还用于显示不满足连接条件的数据。
• 左外连接
• select deptno, dname,empno,ename,job
• from dept left join emp
• using(deptno);
• 右外连接
• select deptno, dname,empno,ename,job
• from dept right join emp
• using(deptno); • 满外连接
• select deptno, dname,empno,ename,job
• from dept full join emp
• using(deptno);
2.6:三表连接使用on创建连接
• 创建城市表City,部门表Dept1,员工表EMP1
• 部门表城市id参考城市表,员工表部门编号参考部门表
• 显示所有员工的编号,姓名和部门名称,城市编号
• select e.empno,e.ename,d.dname,c.name
• from emp1 e
• join dept1 d on e.deptno = d.deptno --连接条件
• join city c on d.loc = c.id --连接条件
• where empno > 7800
• 查询每个员工的部门名称和工资等级
• select e.empno,e.ename,e.sal,e.deptno,d.dname,sg.*
• from emp e
• join dept d
• on d.deptno = e.deptno
• join salgrade sg
• on e.sal between sg.losal and sg.hisal
2.7:自连接
自连接是发生在同一个表格中的连接。
• 使用举例:查询每个员工的工号、姓名、经理姓名
• select * from emp e join emp m on(e.mgr = m.empno)
• select e.empno,e.ename,e.mgr,m.empno,m.ename from emp e join emp m on(e.mgr = m.empno)
• --没有上级的员工也显示
• select e.empno,e.ename,e.mgr,m.empno,m.ename from emp e left join emp m on(e.mgr = m.empno)
• --没有员工的上级(不就是底层员工吗)也显示,还是别显示了
• select e.empno,e.ename,e.mgr,m.empno,m.ename from emp e right join emp m on(e.mgr = m.empno)
• 语法规则:
• SELECT table1.column, table2.column
• FROM table1, table2
• WHERE table1.column1 = table2.column2;
• 特点
• 在 WHERE 子句中写入连接条件
• 当多个表中有重名列时,必须在列的名字前加上表名作为前缀
• 连接的类型:
• 等值连接 -- Equijoin
• 非等值连接 -- Non-equijoin
• 外连接 -- Outer join
• 左外连接 右外连接
• 自连接 -- Self join
1.1笛卡尔集
• select * from dept;//4条记录
• select * from emp; ;//14条记录
• select * from dept,emp; ;//4*14=56条记录
• 总结
• 检索出的行的数目将是第一个表中的行数乘以第二个表中的行数
• 检索出的列的数目将是第一个表中的列数加上第二个表中的列数
• 应该保证所有联结都有where子句,不然数据库返回比想要的数据多得多的数据
--3.5外连接 除了能显示满足连接条件的数据以外,还用于显示不满足连接条件的数据。 select * from emp; select * from dept; --查询所有员工的姓名,职位和部门信息,显示没有员工的部门的信息 select e.ename,e.job,d.deptno,d.dname,d.loc from emp e join dept d on e.deptno=d.deptno; --3.5.1左外连接 left [outer] join , 表示左外连接,可以显示左表中不满足连接条件的数据 --3.5.2右外连接 right [outer]join ,表示右外连接,可以显示有表中不满足连接条件的数据。 select e.ename,e.job,d.deptno,d.dname,d.loc from emp e right join dept d on e.deptno=d.deptno; ---3.5.3全外连接 full[outer]join ,表示全外连接,可以显示左右表中不满足连接的数据。 select e1.empno,e1.ename,e2.empno,e2.ename from emp e1 full join emp e2 on e1.mgr=e2.empno order by e1.empno; --普通连接就是内连接 [inner]join =join --自连接 --自连接是发生在同一个表格中的连接。 --a查询所有员工的编号,姓名和领导的编号及姓名。 select e1.empno,e1.ename,e2.empno,e2.ename from emp e1 join emp e2 on e1.mgr=e2.empno order by e1.empno; --查询所有员工的编号,姓名和领导的编号及姓名,并显示没有领导的员工信息 select e1.empno,e1.ename,e2.empno,e2.ename from emp e1 left join emp e2 on e1.mgr=e2.empno order by e1.empno; select e1.empno,e1.ename,e2.empno,e2.ename from emp e1 right join emp e2 on e1.mgr=e2.empno order by e1.empno;
1.2:等值查询
• select * from dept,emp where dept.deptno=emp.deptno;
• select * from dept d,emp e where d.deptno=e.deptno;
• select d.deptno,dname,loc,empno,ename,job from dept d,emp e where d.deptno=e.deptno;
• select d.deptno,dname,loc,empno,ename,job from dept d,emp e where d.deptno=e.deptno and
d.deptno=10
• select d.deptno,dname,loc,empno,ename,job from dept d,emp e where d.deptno=e.deptno and
loc='DALLAS';
• 当被连接的多个表中存在同名字段时,须在该字段前加上"表名."前缀
• 可使用AND 操作符增加查询条件;
• 使用表别名可以简化查询
• 使用表名(表别名)前缀可提高查询效率;
SQL92的语法规则的缺点:
• 语句过滤条件和表连接的条件都放到了where子句中 。
• 当条件过多时,联结条件多,过滤条件多时,就容易造成混淆
• SQL99修正了整个缺点,把联结条件,过滤条件分开来,包括以下新的TABLE JOIN的
句法结构:
• 交叉连接(Cross join)
• 自然连接(Natural join)
• 使用Using子句建立连接
• 使用On子句建立连接
• 外连接( Outer join )
• 左外连接
• 右外连接
• 全外连接
3.1:子查询
• 问题引入
• 如何查得所有比“CLARK”工资高的员工的信息
• select * from emp
• where sal>(select sal from emp where ename='CLARK'); • 思考:查询工资高于平均工资的雇员名字和工资。
• 思考:查询和SCOTT同一部门且比他工资低的雇员名字和工资。
• 语法格式:
• select 字段列表 from table
• where 表达式 operator (select 字段列表 from table); • 特点
• 子查询在主查询前执行一次
• 主查询使用子查询的结果
3.2:使用子查询注意事项
• 在查询是基于未知值时应考虑使用子查询
• 子查询必须包含在括号内
• 建议将子查询放在比较运算符的右侧,以增强可读性。
• 除非进行Top-N 分析,否则不要在子查询中使用ORDER BY 子句。
• 如果子查询返回单行结果,则为单行子查询,可以在主查询中对其使用相应的单行记录
比较运算符
• 如果子查询返回多行结果,则为多行子查询,此时不允许对其使用单行记录比较运算符

 浙公网安备 33010602011771号
浙公网安备 33010602011771号