SpringBoot 整合Druid
前言
数据库连接池
数据库连接池是程序启动时建立足够的数据库连接,并将这些连接组成一个连接池,由程序动态的对池中连接进行申请、使用、释放
为什么需要使用数据库连接池
数据库连接是一件费事的操作,连接池可以使得多个操作共享一个连接,数据库连接池就是为数据库建立一个缓冲区。
当需要建立数据库连接时,只需要从缓冲区中取出一个,使用完毕后再放回去;使用数据库连接池可以提高对数据库连接资源的管理,数据库连接池负责分配、管理和释放数据库连接,允许程序重复使用一个现有的数据库连接,而不是重新建立一个;可以通过设定连接池最大连接数来防止系统无尽的与数据库连接
常见的连接池分类
- DBCP连接池:采用标准的java EE JDBC API来实现,同时支持JNDI,非常灵活;但是版本比较老了,而且在高并发场景下性能可能存在问题
- C3P0连接池:C3P0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展
- HikariCP连接池:专为高并发场景设计,性能优越,具有最快的初始化速度和最小的延迟,支持JDBC4 API;但是由于需要更多的JVM资源,可能会造成资源消耗问题
- druid连接池:支持JDBC和Oracle驱动程序徐,全面的性能检测,对等分布式,具有强大的扩展功能和高度定制和配置
什么是Druid
Druid是阿里巴巴开源平台上一个数据库连接池实现,结合了c3p0、DBCP等DB池的优点,同时加入了日志监控
spring boot 2.0以上默认使用Hikari数据库连接池,可以说Hikari和Druid都是当前Java web上最优秀的数据库连接池
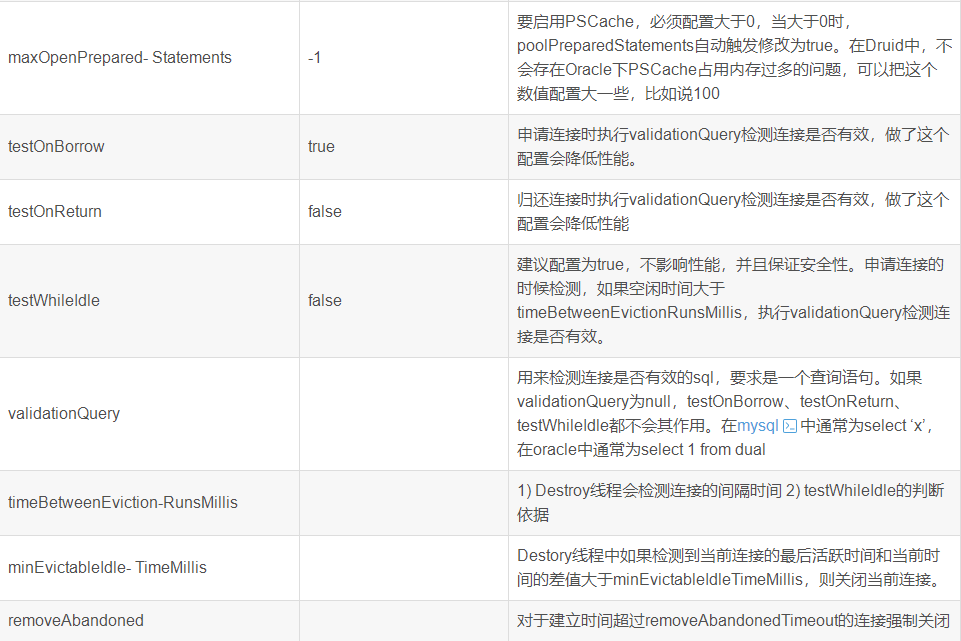
我们可以通过以下代码来查看我们所用的是什么连接池
@Autowired private DataSource dataSource; @Test void test(){ System.out.println(dataSource.getClass()); }
Druid的功能
监控数据库访问性能
Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,可以很好的监控sql的执行情况
替换传统的DBCP和c3p0连接池中间件
Druid提供了强大高效,可扩展性的数据库连接池
扩展JDBC
如对JDBC层由要求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件
SQL执行日志
Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j、jdkLog,可以按需求选择响应的LogFilter
数据库密码加密
数据库密码写在配置文件中,安全性不高
基本配置参数如下:


整合Druid
导入Druid数据源依赖
注意,我这里用的是springboot3.x版本,这里的druid数据源必须是1.2.19以上
错误导入:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.17</version>
</dependency>
正确导入:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-3-starter</artifactId>
<version>1.2.21</version>
</dependency>
配置数据源
springboot2.0以上默认使用的是hikari数据源,所以我们需要将数据源指定为Druid
spring: datasource: #druid数据源配置 druid: username: root # mysql账号 password: root # mysql 密码 driver-class-name: com.mysql.cj.jdbc.Driver # 驱动包名 url: jdbc:mysql://localhost:3306/recordnetwork?useUnicode=true&characterEncoding=utf-8 # 连接地址
获取当前数据源
随后我们在通过以下方式重新获取一下,得到数据源就是druid的了,证明我们指定的数据源生效了
根据需求配置数据源的配置
spring: datasource: #druid数据源配置 druid: username: root # mysql账号 password: root # mysql 密码 driver-class-name: com.mysql.cj.jdbc.Driver # 驱动包名 url: jdbc:mysql://localhost:3306/recordnetwork?useUnicode=true&characterEncoding=utf-8 # 连接地址 # 初始化建立物理连接个数 initial-size: 5 # 最小连接数 min-idle: 5 # 最大连接数 max-active: 10 # 最大等待时间,单位毫秒 max-wait: 6000 # 检测连接是否有效 time-between-eviction-runs-millis: 60000 # 连接在池中的最小生存时间 min-evictable-idle-time-millis: 300000 # 检测连接是否有效的SQL 要求是一个查询语句 validation-query: SELECT 1 FROM DUAL # 这些参数控制何时检测连接的有效性。 test-while-idle: true test-on-borrow: false test-on-return: false # 是否缓存预编译的sql语句 pool-prepared-statements: true # 配置监控统计拦截的filters,stat:监控统计,log4j:日志记录,wall:防御sql注入 filters: stat,wall,log4j # 每个连接可缓存的预编译语句的最大数量。 max-pool-prepared-statement-per-connection-size: 20 # # 是否启用全局的数据统计功能。 use-global-data-source-stat: true # 连接属性,这里设置了合并SQL和慢查询的阈值(毫秒)。 connection-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
注意:这些配置还没生效,因为还没有把自定义属性配置上去
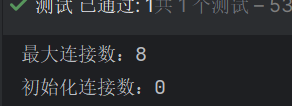
我们在配置文件中配置了最大连接数10,初始化连接数为5
测试一下看看
@Autowired private DataSource dataSource; @Test void test(){ DruidDataSource druidDataSource = (DruidDataSource)dataSource; System.out.println("最大连接数:" + druidDataSource.getMaxActive()); System.out.println("初始化连接数:" + druidDataSource.getInitialSize()); }
发现是8和0是错的。
因为上面的配置用到了日志,我们需要导入一下log4j的依赖
<!-- log4j依赖-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
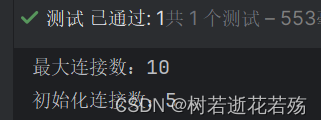
绑定全局配置文件的参数
package com.sxy.recordnetwork.config; import com.alibaba.druid.pool.DruidDataSource; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import javax.sql.DataSource; /** * druid配置类 */ @Configuration public class DruidConfig { @ConfigurationProperties(prefix = "spring.datasource.druid") @Bean public DataSource druidDataSource() { return new DruidDataSource(); } }
然后我们再测试已经成功了
配置Druid数据源监控
Druid提供了具有监控的功能,提供了一个web界面供用户查看,我们得设置Druid后台管理页面,如登录账号、密码等
spring:
datasource:
#druid数据源配置
druid:
// 其他配置
# 配置可视化控制台页面
stat-view-servlet:
enabled: true
# 访问druid监控页面的地址
url-pattern: /druid/*
# IP 白名单 没有配置或者为空则允许所有访问
allow:
# IP黑名单,若白名单也存在则优先使用
deny:
# 禁用重置按钮
reset-enable: true
# 登录所用的用户名与密码
login-username: admin
login-password: 123456
随后就可以访问监控页面了
配置DruidWeb监控Filter的过滤器
spring:
datasource:
#druid数据源配置
druid:
#配置过滤器,过滤掉静态文件
web-stat-filter:
enabled: true
url-pattern: /*
exclusions: /druid/*,*.js,*.css,*.gif,*.jpg,*.bmp,*.png,*.ico
配置以上即可
application-dev.yml


server: port: 18084 servlet: context-path: / session: timeout: 60000 spring: datasource: username: root password: HaiNei1205~! url: jdbc:mysql://10.25.110.102:3306/baseline_5.0_ls?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useTimezone=true&serverTimezone=GMT%2B8 driver-class-name: com.mysql.cj.jdbc.Driver druid: initial-size: 5 min-idle: 5 max-active: 20 max-wait: 60000 time-between-eviction-runs-millis: 60000 min-evictable-idle-time-millis: 300000 filters: stat,wall #日志的相关配置 redis: #Redis 服务器地址 host: localhost #Redis 服务器连接端口 port: 6379 lettuce: pool: max-active: 100 max-wait: PT10S max-idle: 30 min-idle: 1 timeout: PT10S database: 3 influx: #时序数据库url url: http://10.25.140.15:8086 #时序数据库用户名 userName: admin #时序数据库密码 password: hainei1205 #时序数据库链接数据库 database: rabbit5.0 #指定存储的"表" measurement: opc rabbitmq: host: 10.25.110.102 port: 5672 username: guest password: guest my: uploadFile: uploadPath: E:\tomcat\webapps\fileupload\ readPath: \fileupload\ diagramUploadPath: E:\tomcat\webapps\diagram\ diagramReadPath: \diagram\ projectCode: dafeng # 服务器通外网选true ipFrom: false gpsUserId: 园区项目 gpsUserPwd: Df123456 appKey: 8FB345B8693CCD0091580359B017EB28 appSecret: c5b1cb22e09f4b25944c99103a961bbb app: appKey: ding78ia5bjoxjhctssf appSecret: lo-dT410lzMGN9z9NTkXhLvuXjDrD5U0JpUZfBUqELUyTp1Nk5pRSWE7ev6gpBOU corpId: ding70a471e67f652ba635c2f4657eb6378f agentId: 1488828464 dbbak: # 数据库备份配置 dbUser: "root" dbPassword: "ZHEtang403~!" dbName: "baseline_5_park" jdbcUrl: "jdbc:mysql://192.168.1.104:3306/samp_zones_monitor?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true" file-path: C:\softInstall\Tomcat 8.5-0\webapps\fileupload\dbbak # 数据备份文件保存路径 # 数据备份脚本 script: "mysqldump --opt --single-transaction=TRUE --host={0} --protocol=tcp --port={1} --comments --default-character-set=utf8 --single-transaction=TRUE -R --hex-blob --flush-logs --routines --events --triggers {2} " logging: level: root: info #swagger 开关 swagger2: enable: true #日志的相关配置 spring.activiti.history-level: full spring.activiti.db-history-used: true # spring-activiti # 自动部署验证设置:true-开启(默认)、false-关闭 spring.activiti.check-process-definitions: false

 浙公网安备 33010602011771号
浙公网安备 33010602011771号