mysql深入理解
MYSQL索引
AVL树(平衡二叉树)、B树(多路平衡查找树)、B+树分别解决了什么问题
AVL树的一个重要的特点是:树的左右两边的层数之差不会大于一,从而解决了二叉树链表边可能会往一边倾斜的情况 ,变成一个单一的单向链表。
b树又叫做多路平衡二叉树, AVL树存在的问题是, 如果数据量很大,就会导致树的深度很深,当需要找的值的位置,在树的较低层的时候,就会导致多次的i/o操作,而每次的i/o操作相对是比较浪费时间的,导致找到数据时,时间很长。对于b树而言,当每个page的存储大小是16kb时,而-条记录时1kb时,假设建值需要8bytes ,向下的指针时6bytes ,当树的深度为2时,可以存储2000多w的数据,从而大大降低了树的深度,也就大大降低了i/o的次数,降低了时间,提高了数据查找的效率。
B+树,相对与b树而言,添加了叶子节点上 ,数据库数据的排序链式索引。当需要查找多个数据之间数值差距不大的值,亦或者
是,查找一个范围内的数值时,可以避免每- -次的查找都需 要从根节点走起,直接从当前的叶子节点走起,从而提高了扫库扫
表、排序以及磁盘的读写能力。
为什么推荐使用递增的ID作为主键索引?而不是使用类似于UUID 身份证
2.身份证号和UUID的值的特点是一样的,就是新插入的数据具有随机性。我们知道对于InnoDB而言 ,主键索引是聚簇索引。当
主键具有不确定性,需要插入的数据可能在B+树的叶子节点中间,就会导致叶子节点频繁的分裂,数据的存储和B+树的分裂不
一致, page页新增时,出现磁盘存储的碎片化等-系列的问题 ,同时在需要进行insert操作,将会读取整个B+树节点到内存,
在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显。而采用自增的字段作为主
键时,每一-次的插入都是在叶子节点的末尾,和b+树的分裂-致,提高了聚簇索引的存取效率,有效避兔了磁盘的碎片化等- -些
了的问题,提高了磁盘的使用率。
什么是索引

在InnoDB中 数据和索引都是放在磁盘上
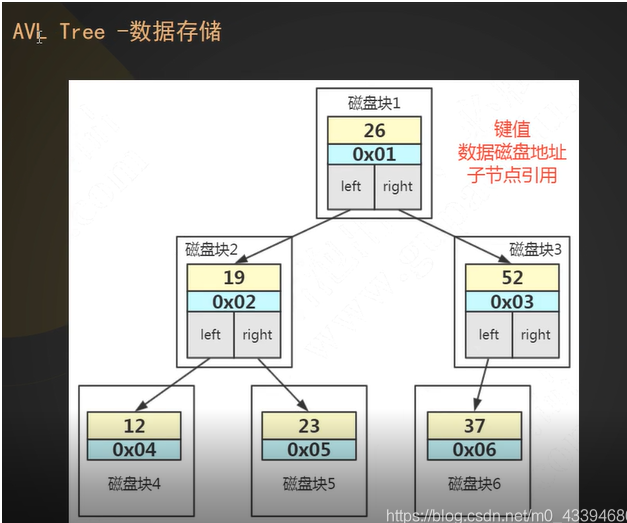
基于索引检索数据 :
需要将磁盘上的索引加载到存储引擎的内存中(磁盘到内存) 在InnoDB中从磁盘加载数据到内存中 默认的单位是page 大小为16kb 也就是发生一次磁盘I/O必须要读取16KB的内容,节点=page 16kb 可理解为一个节点一次I/O
索引数据结构的调整实际上就是page的分裂合并,不要在一个频繁更新的字段是建立索引,是因为会带来数据结构的大量调整,计算是会消耗CPU时间的
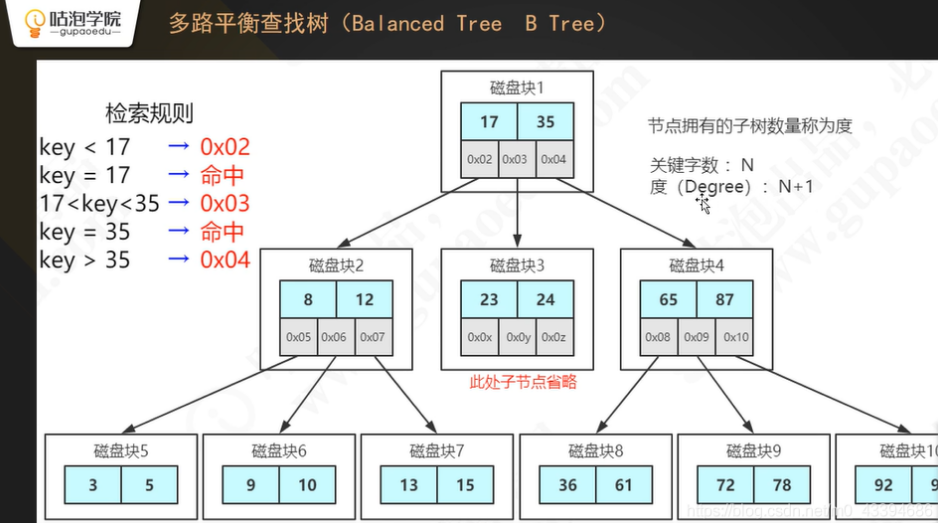
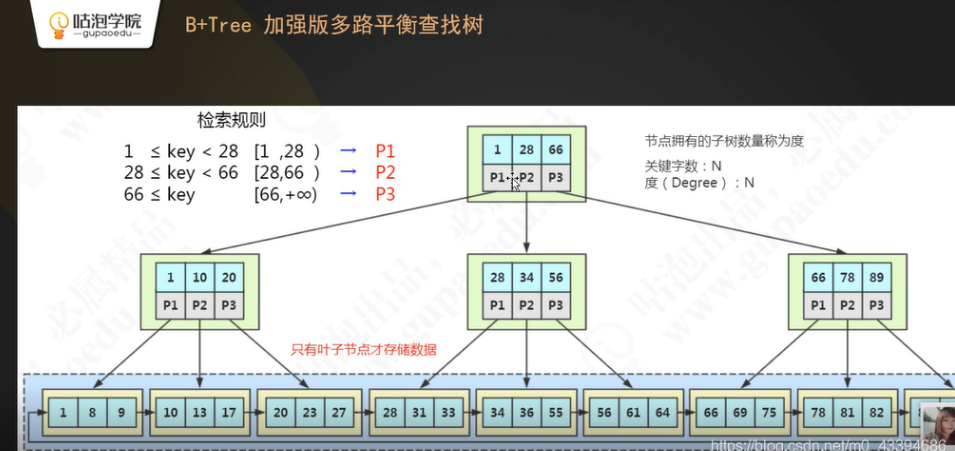

Hash索引

哈希索引只能支持等值查询,时间复杂度永远是O(1),会出现Hash冲突 影响效率 在Memory存储引擎中有Hash索引 InnoDB中无法显示的使用Hash索引
MyISAM主键索引
索引存放在 .myi文件下
数据存放在 .myd文件下
当找到索引去取对应的数据时,会多经过一次I/O
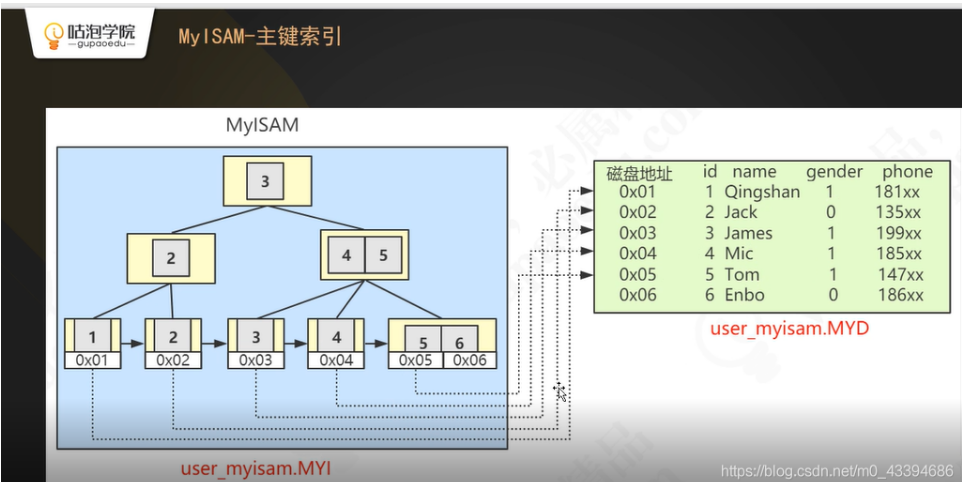
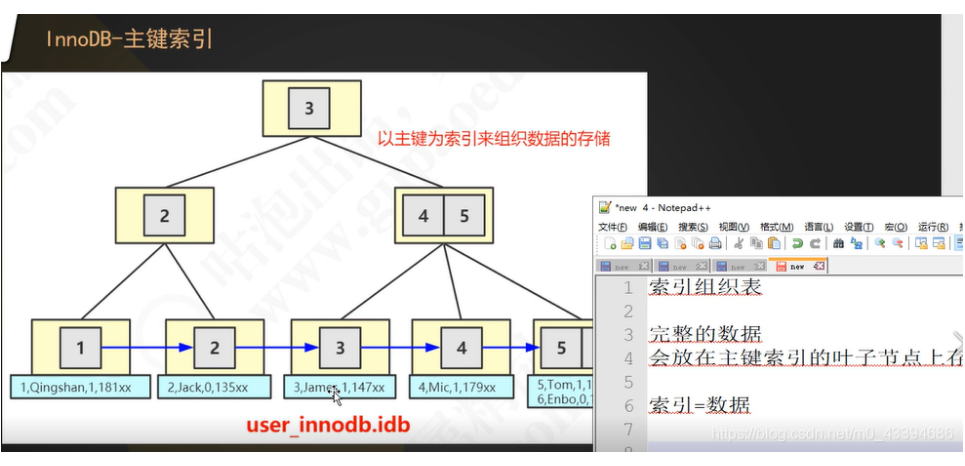
InnoDB 主键索引
数据的存放位置是由索引决定的
索引和数据是同一个文件 完整的数据会放在主键索引的叶子节点上存储 也就是说完整数据必然是存放在一颗B+树上 存放了完整数据的B+树且当索引的逻辑顺序和数据行的物理存放顺序相同的时候 这棵B+树 就叫做聚集索引
如果一张表没有主键,谁是聚集索引
如果有主键索引 那么这个主键索引就是聚集索引
如果没有主键索引,会使用第一个不包含空值的唯一索引作为聚集索引
既没有主键索引,也没有不包含空值的唯一索引 是使用row ID作为隐藏的聚集索引
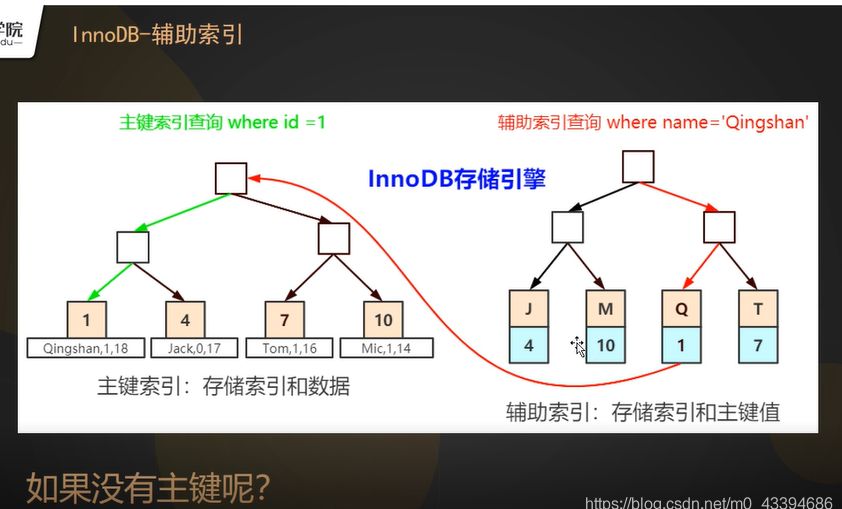
如果一张表有多个索引,聚集索引上存放完整数据,那么非聚集索引(也叫二级索引)的叶子节点上存放的主键索引的键值
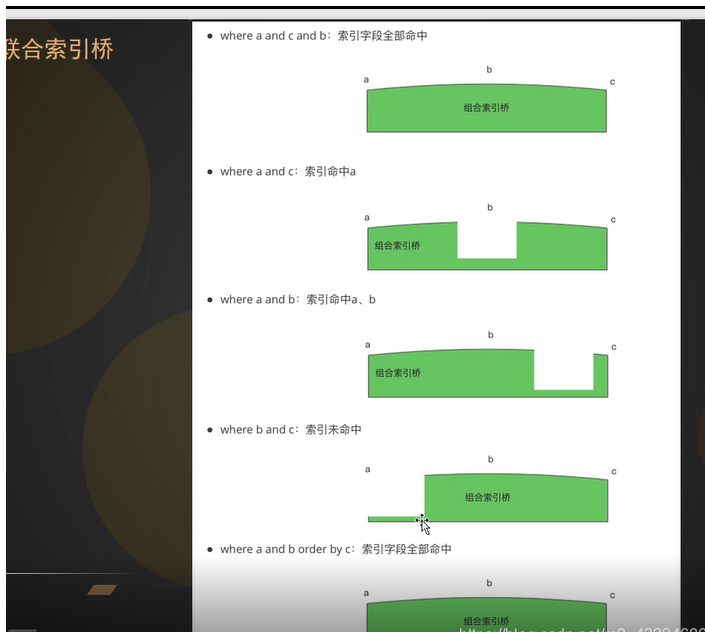
联合索引
联合索引使用规则: 查询条件使用联合索引,必须从头开始,不能跳过,不能中断

覆盖索引
什么叫回表?
在InnoDB的辅助索引中,叶子节点上存放的是主键索引的键值,要想拿到完整数据,需要扫描辅助索引的B+树之后 在扫描主键索引的B+树 此过程被称为回表
回表没有只扫描一颗B+树快
避免回表的方法-
select查询的数据列已经包含在使用的索引中的时候,不需要回表 这种情况被称为使用了覆盖索引
————————————————
版权声明:本文为CSDN博主「刘记清汤圆」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_43394686/article/details/117222721

