BUAA_OO 第一单元总结——表达式分析
BUAA_OO 第一单元总结——表达式分析
前言
第一单元OO终于落下了帷幕,期间无论是构建代码的辛苦,还是第二次作业寄了之后的接近崩溃,都给我留下了深刻的印象。不得不说,这门课真是在某种程度上折磨了我很久。但是,当我真正做完了第三次作业,再回首之前奋战的经历,只能是究极折磨(当然还是很好玩的)。
本门课为面向对象设计与构造,第一单元的内容为表达式分析,通过对表达式结构进行建模,完成单变量多项式的括号展开,到完成多项式的括号展开与函数调用、化简,最后到完成多层嵌套表达式和函数调用的括号展开与化简。层层深度,逐层递进,帮助学生掌握层次化设计的思想。
代码分析工具
本次使用的代码分析工具为MetricsReload和Statistic来分析代码的复杂度和各个模块之间的长度
第一次作业
简介
BNF如图所示
表达式 \rightarrow→ 空白项 [加减 空白项] 项 空白项 | 表达式 加减 空白项 项 空白项
项 \rightarrow→ [加减 空白项] 因子 | 项 空白项 * 空白项 因子
因子 \rightarrow→ 变量因子 | 常数因子 | 表达式因子
变量因子 \rightarrow→ 幂函数
常数因子 \rightarrow→ 带符号的整数
表达式因子 \rightarrow→ '(' 表达式 ')' [空白项 指数]
幂函数 \rightarrow→ 'x' [空白项 指数]
指数 \rightarrow→ '**' 空白项 带符号的整数
带符号的整数 \rightarrow→ [加减] 允许前导零的整数
允许前导零的整数 \rightarrow→ (0|1|2|…|9){0|1|2|…|9}
空白项 \rightarrow→ {空白字符}
空白字符 \rightarrow→ (空格) | \t
加减 \rightarrow→ '+' | '-'
1.整体架构
在第一次作业中,由于表达式的形式比较简单,且括号只有一层,在结构上并没有出现递归下降的情况,因此我将表达式分析分成了预处理、递归下降法处理表达式、输出处理三部分。
|- Main:主类
|- Parse :表达式
|- expr(表达式)
|- Term(项)
|- Num:常数
|- Variable:幂函数
|- expr(表达式)
|- Factor (abstract)
|- parser :表达式解析
|- PString:输出处理
1.1预处理
目的:便于处理后续表达式,使用replaceAll较为方便(虽然我最开始是一个一个字符分析)
-
去除冗余的
+-这个方法并不是一个十分符合处理表达式的方法,本质上还是一种字符串替换,而这个问题在经过我的不断学习之后,在第三次作业得以改善-
-
去除空白符(使用
replaceAll) -
在以
+或者-开头的表达式前补加0。这个是因为在我的第一次设计架构中,我对于因子的解析为表达式因子、幂函数因子和常数因子。其中,后两个在解析时是可以带符号的,而对于表达式因子来说,如果对这个因子进行分析时前面是负号令我十分困扰,因此我通过对于表达式形式化描述的分析,确认了表达式因子只会在第一项的第一个因子有符号。
注:由于我惯性的认为这样处理会使表达式适用于所有的表达式,因此在第二次作业中与不合理的字符串处理相结合导致了第二次作业的悲剧
1.2递归下降法
在对正则表达式和递归下降法分析时,我个人认为递归下降法更能层级性的表示出表达式分析的层次建构。下面是我的表达式建构
-
表达式
Expr -
项
Term、符号因子Sign -
常数因子
NUM、变量因子Variable、表达式因子Expr
处理过程与最为基础的递归下降法(train 2)有三处不同。
-
添加了符号因子,这个因子表示了不同项之间的符号,在后续的输出处理中再将符号挪到不同的项中。
这个问题在第三次作业解决
-
在得出表达式因子时,程序判断表达式因子后面的指数,通过for循环输出n个表达式依着你
-
由于预处理使表达式因子前面的符号一定是项的符号,因此对于另外两个因子处理时会先考虑正负号,再考虑因子的种类。保存常数因子和幂函数因子时,程序直接保存它们的值而没有进行化简(例如设置系数指数等等)。
1.3输出处理
- 建立
ArrayList<String>字符串列表,对于每一项保存到每个String中。由于嵌套括号只有一层,因此在这个阶段只是简单地通过多项式相乘法得到每一项。这是每个String是常数和幂函数的直接相连,且带正负号。 - 建立
HashMap哈希图,格式为HashMap<Integer, BigInteger>,前者为指数,后面为系数。
2.类图及分析
2.1类图
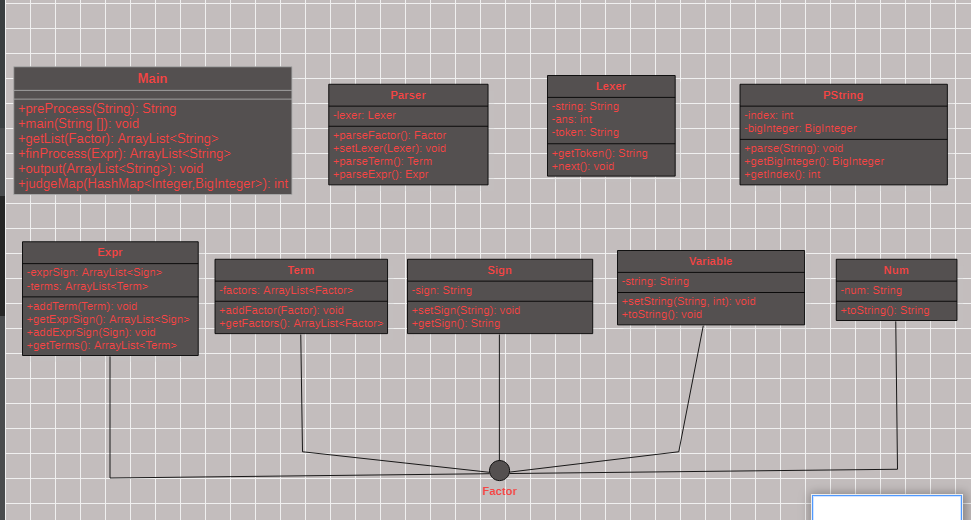
2.2分析
优点
合理建构了递归下降表达式分析的内容,对于第一次接触层次化设计的我来说,完成了递归下降法的使用无疑是一件很高兴的事
缺点
- 使用了大量的静态变量
(有点把他当函数写了),过程可以继续优化,这样做会使内存空间使用率不高 - 整体结构并没有达到最简,仍可以继续改进
- 输出处理的递归程度没有,导致第二三次作业的体系仍需重构
3.bug分析
第一次作业未出现bug,且程序通过HashMap进行合并,结果较为简短。
互测没hack出别人,也没hack到自己
4.程序结构度量
4.1代码量分析

感觉还是有点长,其实可以很简化的
4.2类复杂度分析
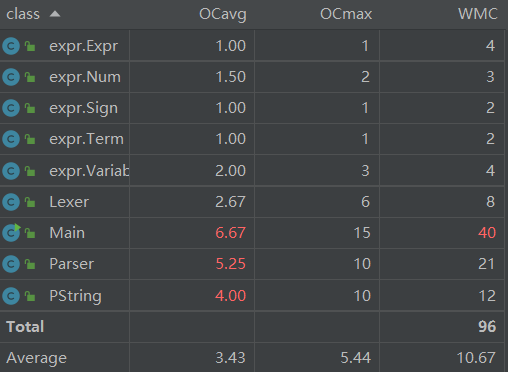
Main函数爆了在意料之中,毕竟写了太多的静态函数了
PString是用来合成HashMap的,CogC(认知复杂度)也比较高,可能是里面用了很多循环
4.3方法圈复杂度
| Complexity metrics | 周二 | 22 3月 2022 22:50:10 CST | ||
|---|---|---|---|---|
| Method | CogC | ev(G) | iv(G) | v(G) |
| Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| Lexer.getToken() | 0 | 1 | 1 | 1 |
| Lexer.next() | 10 | 2 | 7 | 7 |
| Main.finProcess(Expr) | 16 | 1 | 7 | 7 |
| Main.getList(Factor) | 15 | 1 | 6 | 6 |
| Main.judgeMap(HashMap<Integer, BigInteger>) | 6 | 4 | 3 | 4 |
| Main.main(String[]) | 2 | 1 | 2 | 2 |
| Main.output(ArrayList |
40 | 5 | 15 | 15 |
| Main.preProcess(String) | 10 | 2 | 5 | 6 |
| PString.getBigInteger() | 0 | 1 | 1 | 1 |
| PString.getIndex() | 0 | 1 | 1 | 1 |
| PString.parse(String) | 13 | 1 | 9 | 12 |
| Parser.parseExpr() | 1 | 1 | 2 | 2 |
| Parser.parseFactor() | 21 | 5 | 8 | 8 |
| Parser.parseTerm() | 21 | 1 | 10 | 10 |
| Parser.setLexer(Lexer) | 0 | 1 | 1 | 1 |
| expr.Expr.addExprSign(Sign) | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Term) | 0 | 1 | 1 | 1 |
| expr.Expr.getExprSign() | 0 | 1 | 1 | 1 |
| expr.Expr.getTerms() | 0 | 1 | 1 | 1 |
| expr.Num.Num(String, int) | 2 | 1 | 1 | 2 |
| expr.Num.toString() | 0 | 1 | 1 | 1 |
| expr.Sign.getSign() | 0 | 1 | 1 | 1 |
| expr.Sign.setSign(String) | 0 | 1 | 1 | 1 |
| expr.Term.addFactor(Factor) | 0 | 1 | 1 | 1 |
| expr.Term.getFactors() | 0 | 1 | 1 | 1 |
| expr.Variable.setString(String, int) | 4 | 1 | 1 | 3 |
| expr.Variable.toString() | 0 | 1 | 1 | 1 |
main函数里面的output静态方法四个都比较高,它其实是用了循环遍历HashMap来输出最后结果的,复杂度较高的原因在于为了化简提出了各种各样的条件。
Parser表达式解析器的提取因子和提取项的CogC(认知复杂度)也有点偏高,主要原因parseFactor()方法在于提取各种因子,而parseTerm()复杂度较高的原因在于处理表达式因子时判断了它的指数,并循环添加表达式因子造成。
其他的都还好。
第二次作业(悲)
第二次作业是个灾难,自认为代码没有问题,在互测时也没有人找到我的bug,踌躇满志时终于乐极生悲,互测确实没有问题,因为互测的数据没有调用其他函数,在处理其他函数处出了大问题。知道结果以后都差点想摆烂了

简介
相较于第一次增加了函数调用和三角函数,有嵌套括号。
1.整体架构
因子方面增加了Cos和Sin函数,预处理和输出处理方面多了很多其他静态方法。
|- Main:主类
|-预处理
|-FunLexer:函数处理-函数内容分析
|-FuncProcess:函数处理-字符串替换
|-SumProcess:求和函数处理
|- Parse :表达式
|- expr(表达式)
|- Term(项)
|- Num:常数
|- Variable:幂函数
|- expr(表达式)
|-sin正弦函数
|-cos余弦函数
|- Factor (abstract)
|- parser :表达式解析
|-输出处理
|-FactorList作为临时的中间类,保存每个项的因子
|-TermParse最终合成项
没错,第二次的我还是没有意识到架构的重要性,想着基于第一次的代码进行改动,这种行为是不对的,整体的代码架构相较于第一次没有优化,在某种程度上证明了我第二次作业是一种失败,最后的结果也证明了这一点。不过有些地方也确实为第三次作业的重新架构提供了一定的思路。
1.1预处理
预处理了求和函数和表达式函数,只是简单的字符串替换
替换过程出了大问题,主要是对于
BNF结构的理解,具体原因看bug分析
1.2递归下降法
增加了sin和cos函数的识别
1.3输出处理
在第一个处理中我使用了ArrayList<String>的字符串数列来保存每一项。
在第二次作业提取项的每一个因子时,使用了递归调用的方法获得了每一项的因子,而到了合成时,原本的字符串并不能支持后续的处理,因此在这其中我提出了一个FactorList类(这个类作为合成的中间类),它里面的属性只有ArrayList<Factor>,因此一个FactorList类就是一个项的所有因子,此时再调用ArrayList<FactorList>,就可以获得每一项。
此时构造一个新的类TermParse:
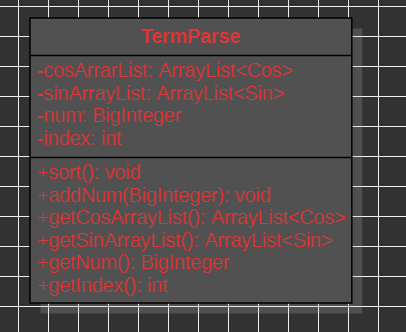
里面包括了系数(num)、指数(index)、三角函数属性、type(项的种类:根据指数和三角函数设置,这个在合成的时候简单地使用)
当然里面也包括了一些排序(使项的指数从大到小排序:为了使合成以及观看更方便)
毫无疑问,这就是我们最终合成的每一项内容了。当然合成所有项的全部因子后,就需要进入到不同项的合成了,这里通过判断他们指数和三角函数是否相等来进行判断。(这时合并三角函数的时候可以不合并指数,这个在后面三角函数合成时比较方便)
这种判断不同项合成的方法注定了要是用大量的代码来进行判断两个不同项之间的三角函数是否相等。我其实在后来的讨论区看到
HashMap<HashMap<String, BigInteger>,BigInteger>这样的项的组成,外层BigInteger存储前置系数,内层HashMap``String存储三角表达式或幂函数底数x的字符串形式,BigInteger存储三角表达式的x的幂次。我认为这是一种非常合理的构造。
三角函数合成
这里我仍然使用TermParse类,对于同一指数的每个项,两两进行判断
if 项个数为0:
返回
else if 项个数为1:
输出
else:
实例化三方法funCommon,nnCommon1,nnCommon2,分别代表同类型,不同类项,判断sin(x)**2+cos(x)**2=1及等号变形。
if 合成成功:
递归循环
else :
输出每一项
这里判断三角函数是否相等时,在最开始合成项的时候不合并就方便了一些
2.类图及分析
2.1类图

2.2分析
优点
最后结果理论上化简到了最短
缺点
- 用了大量的静态方法
- 相较于第一次代码架构上并没有其余的优化,只是优化了合并方法。
3.bug分析(重点)
预处理方面是个杯具
- 边界问题,对于sum函数的分析,替换i字符时为了防止把sin函数里面的i给替换掉,判断i的下一个字符是不是n。这样做没有问题,但是因为边界问题可能i是最后一个字符就导致下一个字符超过了边界范围
(悲) - 字符串替换之后其实不仅是第一项的第一个表达式因子前面可以有正负号了(当然这个是符合形式化描述的),导致我只考虑了第一项的第一个因子的情况,对于
(-(这个的嵌套表达式我并没有处理,导致程序直接崩掉。
解析三角函数也出现了问题
问题在于我对形式化表述的认识不够深刻,导致写sin(x**2)时直接写了sin(x*x)这样的形式,导致出了问题。
然后合成项的判断出现了问题
不得不说,我在合成同类项时合成判断由于两个类的名字过于相近,然后检查的时候也没看出了(例如我的termParse1和termParse)
不过构造测试数据的时候竟然没检查出来是大问题
综上,就是由于这样对于预处理的失误(我其实更归结于第一个和第四个bug是自己的考虑问题,第二个和第三个bug更偏向于形式化处理方面的理解失误)
代码行和圈复杂度上的差异
经过修改之后,代码行和代码复杂度都没有什么变化,我提交了好几个修改bug,每一个都控制在了5行以内,说明自己的架构思路是没有什么大的问题的(除了架构的太复杂了并且可读性和可移植性有点烂,但好歹能读懂)。
真正出问题的地方在于我对于题目形式化表述阅读理解的不够深刻,当我采用了取巧的方式处理字符串时,在莫种程度上的形式化表达就会遭到一定的破坏。
bug修复
改了这样那样的错误,唯一有点小偷懒的是(-(这个的嵌套表达式处理我用了replaceAll往里面直接加零。(主要是完全的改整体架构也需要改很多,这次偷懒了,第三次作业完全改了)
4.程序结构度量
4.1代码量分析

啊哈,比上次多了1000行!
主要原因在于在预处理方面和输出处理方便多了很多行,其他的解析方面也有少量的增加类,从个人设计来说,我肯定是不满意的,因为他多的地方并不是对于程序架构的优化,而大多数是对于处理过程的复杂化。
如果这次作业进行评价的话,我只能对自己合成项和实现三角函数的合成比较满意,其他部分一律不行。
4.2类复杂度分析
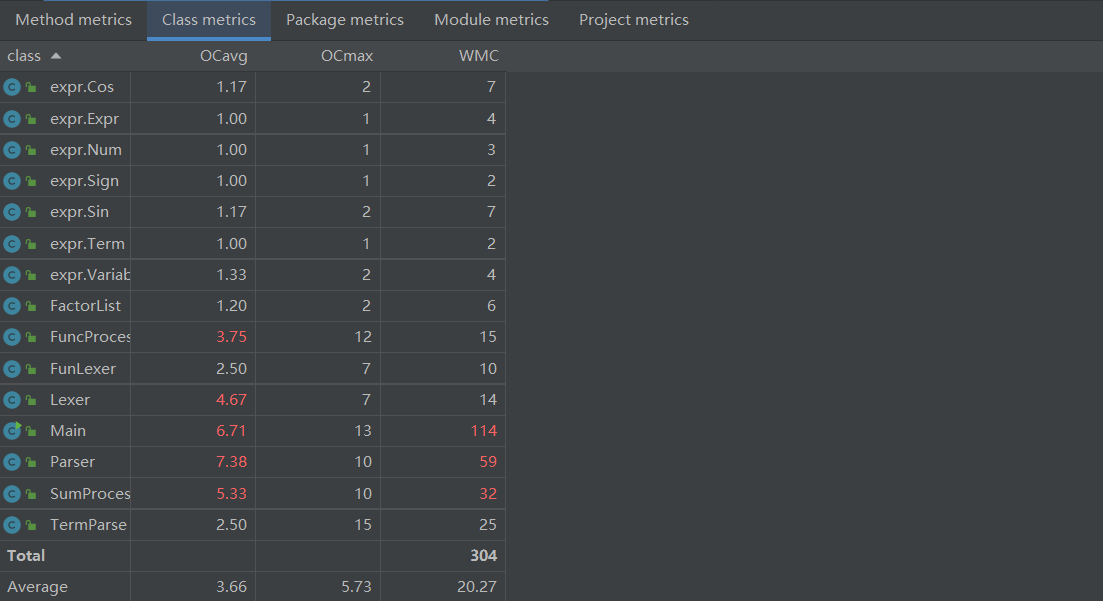
main函数继续爆掉,还是因为输出处理方面多了很多静态方法。
parser表达式递归下降部分处理CogC(认知复杂度)更高了,此外WMC也高了,这是由于增加了cos、sin函数的原因
此外多出的两个FuncProcess(表达式函数分析),SumProcess(求和函数分析)的预处理部分,这两个部分写的也不太好,主要原因在于处理时调用了多个循环函数,我个人觉得正则表达式匹配会比较好点。
4.3方法圈复杂度
| Complexity metrics | 周三 | 23 3月 2022 22:21:43 CST | ||
|---|---|---|---|---|
| Method | CogC | ev(G) | iv(G) | v(G) |
| FactorList.addFactor(Factor) | 0 | 1 | 1 | 1 |
| FactorList.deepClone() | 0 | 1 | 1 | 1 |
| FactorList.getFactorArrayList() | 0 | 1 | 1 | 1 |
| FactorList.getSign() | 0 | 1 | 1 | 1 |
| FactorList.setSign(int) | 1 | 1 | 1 | 2 |
| FunLexer.FunLexer(String) | 10 | 3 | 6 | 7 |
| FunLexer.getEqualFunc() | 0 | 1 | 1 | 1 |
| FunLexer.getName() | 0 | 1 | 1 | 1 |
| FunLexer.getVarList() | 0 | 1 | 1 | 1 |
| FuncProcess.getLocal() | 0 | 1 | 1 | 1 |
| FuncProcess.getStringBuilder() | 0 | 1 | 1 | 1 |
| FuncProcess.ini(StringBuilder, String, int) | 30 | 8 | 14 | 14 |
| FuncProcess.setFunLexers(ArrayList |
0 | 1 | 1 | 1 |
| Lexer.Lexer(String, ArrayList |
9 | 1 | 7 | 8 |
| Lexer.getToken() | 0 | 1 | 1 | 1 |
| Lexer.next() | 10 | 1 | 8 | 8 |
| Main.finProcess(Expr) | 26 | 1 | 9 | 9 |
| Main.judgeEqual(TermParse, TermParse) | 17 | 7 | 5 | 10 |
| Main.main(String[]) | 8 | 1 | 6 | 6 |
| Main.mergeProcess1(ArrayList |
10 | 1 | 6 | 6 |
| Main.mergeProcess2(ArrayList |
23 | 1 | 9 | 9 |
| Main.mergeProcess3(ArrayList |
23 | 1 | 9 | 9 |
| Main.mergeProcess4(ArrayList |
29 | 1 | 10 | 10 |
| Main.out(TermParse, StringBuilder) | 41 | 1 | 13 | 15 |
| Main.out2(StringBuilder, TermParse, int) | 5 | 1 | 3 | 3 |
| Main.outAddCos(ArrayList |
14 | 1 | 6 | 6 |
| Main.outAddSin(ArrayList |
14 | 1 | 6 | 6 |
| Main.outIndex1(StringBuilder, TermParse, int) | 5 | 1 | 4 | 4 |
| Main.outIndex2(StringBuilder, TermParse) | 3 | 1 | 3 | 3 |
| Main.outMerge(ArrayList |
5 | 2 | 4 | 4 |
| Main.outNum(StringBuilder, TermParse) | 4 | 1 | 4 | 4 |
| Main.output(ArrayList |
14 | 1 | 6 | 6 |
| Main.signProcess(ArrayList |
27 | 1 | 9 | 9 |
| Parser.parseExpr() | 1 | 1 | 2 | 2 |
| Parser.parseFactor() | 23 | 7 | 10 | 10 |
| Parser.parseTerm() | 21 | 1 | 10 | 10 |
| Parser.setCos(int) | 24 | 4 | 10 | 10 |
| Parser.setCos1(int) | 16 | 5 | 7 | 8 |
| Parser.setLexer(Lexer) | 0 | 1 | 1 | 1 |
| Parser.setSin(int) | 24 | 4 | 10 | 10 |
| Parser.setSin1(int) | 16 | 5 | 7 | 8 |
| SumProcess.SumProcess(StringBuilder, String, int) | 22 | 3 | 9 | 11 |
| SumProcess.getE(String, int) | 9 | 7 | 4 | 7 |
| SumProcess.getExpr(String, int) | 11 | 5 | 4 | 8 |
| SumProcess.getLocal() | 0 | 1 | 1 | 1 |
| SumProcess.getS(String, int) | 6 | 5 | 3 | 5 |
| SumProcess.getStringBuilder() | 0 | 1 | 1 | 1 |
| TermParse.TermParse(FactorList) | 32 | 1 | 11 | 19 |
| TermParse.addNum(BigInteger) | 0 | 1 | 1 | 1 |
| TermParse.compareTo(TermParse) | 2 | 2 | 1 | 2 |
| TermParse.deepClone() | 0 | 1 | 1 | 1 |
| TermParse.getCosArrayList() | 0 | 1 | 1 | 1 |
| TermParse.getIndex() | 0 | 1 | 1 | 1 |
| TermParse.getNum() | 0 | 1 | 1 | 1 |
| TermParse.getSinArrayList() | 0 | 1 | 1 | 1 |
| TermParse.getType() | 0 | 1 | 1 | 1 |
| TermParse.sort() | 0 | 1 | 1 | 1 |
| expr.Cos.Cos(String, int, int) | 0 | 1 | 1 | 1 |
| expr.Cos.addIndex(int) | 0 | 1 | 1 | 1 |
| expr.Cos.compareTo(Cos) | 2 | 2 | 1 | 2 |
| expr.Cos.getFunc() | 0 | 1 | 1 | 1 |
| expr.Cos.getIndex() | 0 | 1 | 1 | 1 |
| expr.Cos.getJudgeSign() | 0 | 1 | 1 | 1 |
| expr.Expr.addExprSign(Sign) | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Term) | 0 | 1 | 1 | 1 |
| expr.Expr.getExprSign() | 0 | 1 | 1 | 1 |
| expr.Expr.getTerms() | 0 | 1 | 1 | 1 |
| expr.Num.Num(String, int) | 0 | 1 | 1 | 1 |
| expr.Num.getJudgeSign() | 0 | 1 | 1 | 1 |
| expr.Num.toString() | 0 | 1 | 1 | 1 |
| expr.Sign.getSign() | 0 | 1 | 1 | 1 |
| expr.Sign.setSign(String) | 0 | 1 | 1 | 1 |
| expr.Sin.Sin(String, int, int) | 0 | 1 | 1 | 1 |
| expr.Sin.addIndex(int) | 0 | 1 | 1 | 1 |
| expr.Sin.compareTo(Sin) | 2 | 2 | 1 | 2 |
| expr.Sin.getFunc() | 0 | 1 | 1 | 1 |
| expr.Sin.getIndex() | 0 | 1 | 1 | 1 |
| expr.Sin.getJudgeSign() | 0 | 1 | 1 | 1 |
| expr.Term.addFactor(Factor) | 0 | 1 | 1 | 1 |
| expr.Term.getFactors() | 0 | 1 | 1 | 1 |
| expr.Variable.getIndex() | 0 | 1 | 1 | 1 |
| expr.Variable.getJudgeSign() | 0 | 1 | 1 | 1 |
| expr.Variable.setString(String, int) | 2 | 1 | 2 | 2 |
我们可以看到,FuncProcess(表达式函数分析),SumProcess(求和函数分析)的预处理部分的处理部分仍然较高,因为处理的时候有点把他弄到统一的方法里面去了。
此外处理sin和cos内容的方法setSin、setCos圈复杂度也比较高,这是由于在处理内部的三角函数内部的因子时,我是一个一个字符处理的(当成表达式处理应该会更方便,这个是在第三次作业)
还有输出项的时候圈复杂度也比较高,这个是因为我在合成项和合成三角函数的时候把所有的三角函数的指数都展开了,最后还需要合成。
这个时候就不免吐槽一下用hashMap方法的方便性了
第三次作业
简介
三角函数内部增加了嵌套表达式,自定义函数也同样
这次的构造我还是很满意的,全程没有什么巨大的bug,处理过程也很流畅。
|- Main:主类
|-预处理
|-FunLexer:函数处理-函数内容分析
|-FuncProcess:函数处理-字符串替换
|-SumProcess:求和函数处理
|- Parse :表达式
|- expr(表达式)
|- Term(项)
|- Var:常数和幂函数
|- Circular:三角函数
|- Factor (abstract)
|- parser :表达式解析
|-输出处理
|-FactorList作为临时的中间类,保存每个项的因子
|-TermParse最终合成项
1.整体架构
有了前两次的经验,第三次设计架构进行了全面的优化,某些步骤合并简化。
1.1预处理
主要是求和函数和自定义函数有了一个嵌套判断输出,这个东西比较好写
1.2递归下降法
因子类型完全简化
现在就有两个因子类,幂函数类和三角函数类,内容如下:

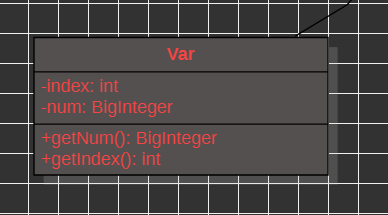
对于三角函数,name和index代表种类和指数,其他的之后在介绍
对于幂函数,num和index分别代表系数和指数
其实我本来想写一个大类把这些都包含进去的,然后我发现这次如果这样写在合成项的时候行不通,最后还是拆成了两类。不过上一次的到可以合成。
增加了非项之间正负号的处理
这个我把表达式和项解析传递的参数增加了一个布尔值(原来没有),对于每个项和每个因子之前进行了判断正负号的方法(我命名为judgeSign)。
同时,当一个项处理完所有的因子返回时,如果它是false(符号),就增加了一个-1的因子。
不得不说,这个方法真好用,让自己的架构更符合形式化表述了。
将三角函数的内容设为表达式
这也就说明了我的三角函数类为什么有一个Factor因子了
1.3输出处理
增加了迭代因子处理
这个东西很好理解,就是遇到了三角函数因子就对里面的表达式处理,然后再返回。这也就说明了我的三角函数类里面多了ArrayList<Factorlist>和ArrayList<TermParse>
化简方法
对于不同项的合成,我是先进行了同项三角函数的合成,一方面我对于每一项的三角函数进行了排序,另一方面我在对比不同项三角函数的内容时,我是直接判断了它里面的内容是否相等。
那这里面就涉及到了内容顺序的问题,因此,我又对我的TermParse类进行了一个排序,这样可以通过字符串输出内容来判断是否相等了。
提取负号
我只是对于三角函数内容只有一个项的时候进行了符号提取,其余的不变
内部为0判断
判断三角函数内容是否为0,这个是一个递归的过程,比较好写。
2类图及分析
类图

分析
优点
设计架构更加简单
缺点
缺点在于我合成不同项的时候先进行了排序判断里面的内容是否相同,这里面就涉及到了一个排序方法的问题,感觉应该有别的方法来处理。还有提取负号也有缺陷。
3.bug分析
问题在于把break改为continue(bushi
对于一个项的某个三角函数内部为0的时候直接跳出这个项的所有三角函数了。
求和函数边界出现问题
这个问题是第二次作业就出现了(不过第二次没测出来)。我判断s和e的值的时候设置为int行,所以数据范围小了
只能说不是不报,时候未到。
4.程序结构度量
4.1代码量分析

比上次足足少了500行!
这个是我能做到的最大限度了(在没看讨论区之前)
4.2类复杂度分析
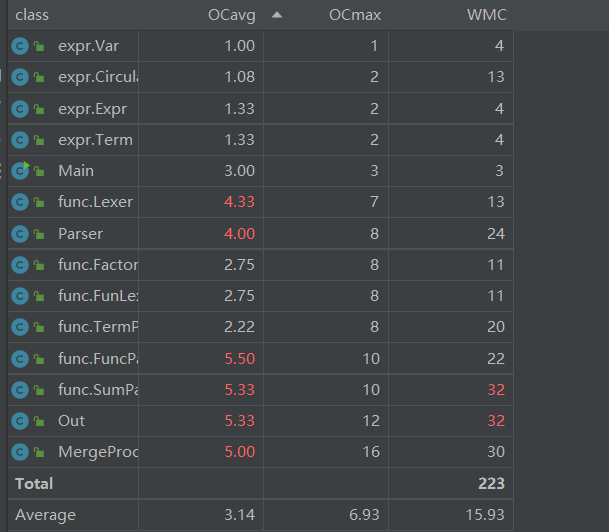
求和函数和自定义函数处理多了递归处理,复杂度当然高了
合成项(MergeProcess)、输出(Out)也是递归处理
4.3方法圈复杂度
| Complexity metrics | 周三 | 23 3月 2022 23:12:10 CST | ||
|---|---|---|---|---|
| Method | CogC | ev(G) | iv(G) | v(G) |
| Main.main(String[]) | 4 | 1 | 4 | 4 |
| MergeProcess.MergeProcess(ArrayList |
0 | 1 | 1 | 1 |
| MergeProcess.circularEquals(ArrayList |
0 | 1 | 1 | 1 |
| MergeProcess.getTermParseArrayList() | 0 | 1 | 1 | 1 |
| MergeProcess.mergeCircular(ArrayList |
63 | 6 | 18 | 18 |
| MergeProcess.mergeProcess(ArrayList |
1 | 1 | 2 | 2 |
| MergeProcess.mergeVar(ArrayList |
23 | 1 | 9 | 9 |
| Out.Out(ArrayList |
0 | 1 | 1 | 1 |
| Out.judge(ArrayList |
19 | 1 | 6 | 8 |
| Out.out1(TermParse, StringBuilder) | 9 | 1 | 5 | 5 |
| Out.out2(TermParse, StringBuilder) | 19 | 1 | 13 | 13 |
| Out.outPrintf() | 0 | 1 | 1 | 1 |
| Out.output(ArrayList |
7 | 1 | 5 | 5 |
| Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| Parser.getIndex() | 4 | 2 | 3 | 3 |
| Parser.judgeSign(boolean) | 2 | 1 | 3 | 3 |
| Parser.parseExpr(boolean) | 1 | 1 | 2 | 2 |
| Parser.parseFactor() | 7 | 7 | 5 | 7 |
| Parser.parseTerm(boolean) | 12 | 1 | 7 | 7 |
| expr.Circular.Circular(String, int, Factor) | 0 | 1 | 1 | 1 |
| expr.Circular.addIndex(int) | 0 | 1 | 1 | 1 |
| expr.Circular.compareTo(Circular) | 2 | 2 | 1 | 2 |
| expr.Circular.deepClone() | 0 | 1 | 1 | 1 |
| expr.Circular.getFactor() | 0 | 1 | 1 | 1 |
| expr.Circular.getFactorLists() | 0 | 1 | 1 | 1 |
| expr.Circular.getIndex() | 0 | 1 | 1 | 1 |
| expr.Circular.getName() | 0 | 1 | 1 | 1 |
| expr.Circular.getTermParses() | 0 | 1 | 1 | 1 |
| expr.Circular.setFactorLists(ArrayList |
0 | 1 | 1 | 1 |
| expr.Circular.setTermParses(ArrayList |
0 | 1 | 1 | 1 |
| expr.Circular.toString() | 0 | 1 | 1 | 1 |
| expr.Expr.addTerm(Term) | 0 | 1 | 1 | 1 |
| expr.Expr.getTermArrayList() | 0 | 1 | 1 | 1 |
| expr.Expr.toString() | 1 | 1 | 2 | 2 |
| expr.Term.addFactor(Factor) | 0 | 1 | 1 | 1 |
| expr.Term.getFactorArrayList() | 0 | 1 | 1 | 1 |
| expr.Term.toString() | 1 | 1 | 2 | 2 |
| expr.Var.Var(BigInteger, int) | 0 | 1 | 1 | 1 |
| expr.Var.getIndex() | 0 | 1 | 1 | 1 |
| expr.Var.getNum() | 0 | 1 | 1 | 1 |
| expr.Var.toString() | 0 | 1 | 1 | 1 |
| func.FactorList.addFactor(Factor) | 0 | 1 | 1 | 1 |
| func.FactorList.deepClone() | 0 | 1 | 1 | 1 |
| func.FactorList.finProcess(Expr) | 26 | 1 | 8 | 8 |
| func.FactorList.getFactorArrayList() | 0 | 1 | 1 | 1 |
| func.FunLexer.FunLexer(String) | 11 | 3 | 7 | 8 |
| func.FunLexer.getEqualFunc() | 0 | 1 | 1 | 1 |
| func.FunLexer.getName() | 0 | 1 | 1 | 1 |
| func.FunLexer.getVarList() | 0 | 1 | 1 | 1 |
| func.FuncParse.FuncParse(StringBuilder, String, int, ArrayList |
7 | 5 | 3 | 5 |
| func.FuncParse.funcOut(String, int, ArrayList |
37 | 3 | 13 | 13 |
| func.FuncParse.getLocal() | 0 | 1 | 1 | 1 |
| func.FuncParse.next(String, int) | 11 | 5 | 9 | 9 |
| func.Lexer.Lexer(String, ArrayList |
7 | 1 | 7 | 7 |
| func.Lexer.getToken() | 0 | 1 | 1 | 1 |
| func.Lexer.next() | 10 | 1 | 8 | 8 |
| func.SumParse.SumParse(StringBuilder, String, int) | 23 | 3 | 10 | 12 |
| func.SumParse.getE(String, int) | 9 | 7 | 4 | 7 |
| func.SumParse.getExpr(String, int) | 11 | 5 | 4 | 8 |
| func.SumParse.getLocal() | 0 | 1 | 1 | 1 |
| func.SumParse.getS(String, int) | 6 | 5 | 3 | 5 |
| func.SumParse.getStringBuilder() | 0 | 1 | 1 | 1 |
| func.TermParse.addNum(BigInteger) | 0 | 1 | 1 | 1 |
| func.TermParse.circularEquals(Circular, Circular) | 1 | 2 | 2 | 2 |
| func.TermParse.compareTo(TermParse) | 6 | 4 | 3 | 4 |
| func.TermParse.getCirculars() | 0 | 1 | 1 | 1 |
| func.TermParse.getIndex() | 0 | 1 | 1 | 1 |
| func.TermParse.getNum() | 0 | 1 | 1 | 1 |
| func.TermParse.setIndex(int) | 0 | 1 | 1 | 1 |
| func.TermParse.setNum(BigInteger) | 0 | 1 | 1 | 1 |
| func.TermParse.setTerm(FactorList) | 31 | 6 | 10 | 10 |
有一个MergeProcess.mergeCircular(ArrayList<TermParse>)方法Cogs特别高,他是合成同一项的三角函数,这个过程需要判断内容是否相等,且还需要递归处理,因此圈复杂度很高。
数据构造和测试
测试结构我采用了python的subprocess模块,大体结构如下:
import subprocess
def process(jar, input_):
location = './'
command = "java -jar " + jar + ".jar"
java = subprocess.Popen(command,
cwd=location,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout, stderr = java.communicate(input=str.encode(input_))
# 与子进程交互,向自己的程序发送字符串,接收stdout等返回
output = bytes.decode(stdout).replace('Mode: Normal\r\n', '').strip()
out_err = bytes.decode(stderr).strip()
print("输出:"+output)
print("错误:"+out_err)
n = input("输入:")
input_java = n
for i in n:
input_java = input_java + "\n" + input()
input_jar = "1"
process(input_jar, input_java)
测试结果的时候我采用的是sympy模块
测试数据我主要采用的是自己构造边界数据,例如零次幂,超过int范围,优化三角函数。递归嵌套等等数据。这种构造方法帮助我测出一些数据。但由于是个人考虑,仍有一些不足之处,例如求和函数的超过int范围我就忘记了处理。
总结体会
由于设计架构不加,导致我几乎每一次作业都重构了一个,其中由于重构过去剧烈导致我第二次作业直接崩掉。虽然代码重构较多,但是每次都有新思路,每次都能想到更好的思路去修改自己的架构,这种逐渐成长的过程让人很有成就感。在这其中,我深刻的感受到了对于层次化设计的重要性,领会到面向对象设计与构造才是最重要的。

