【pytorch】目标检测:一文搞懂如何利用kaggle训练yolov5模型
笔者的运行环境:python3.8+pytorch2.0.1+pycharm+kaggle。
yolov5对python和pytorch版本是有要求的,python>=3.8,pytorch>=1.6。yolov5共有5种类型n\s\l\m\x,参数量依次递增,对训练设备的要求也是递增。本文以yolov5_6s为切入点,探究yolov5如何在实战种运用。
1. 数据集的准备
roboflow是一个公开数据集网站,里面有很多已经标注好的数据可以直接拿来练手,很方便。我们就以里面的车辆数据集为本次实战数据集,点击这里直接下载数据集。该数据集共有五个类别,['Ambulance', 'Bus', 'Car', 'Motorcycle', 'Truck']。从下图可以看到同样的照片有两个,因此我们需要去掉一张,labels也是这样。代码如下所示,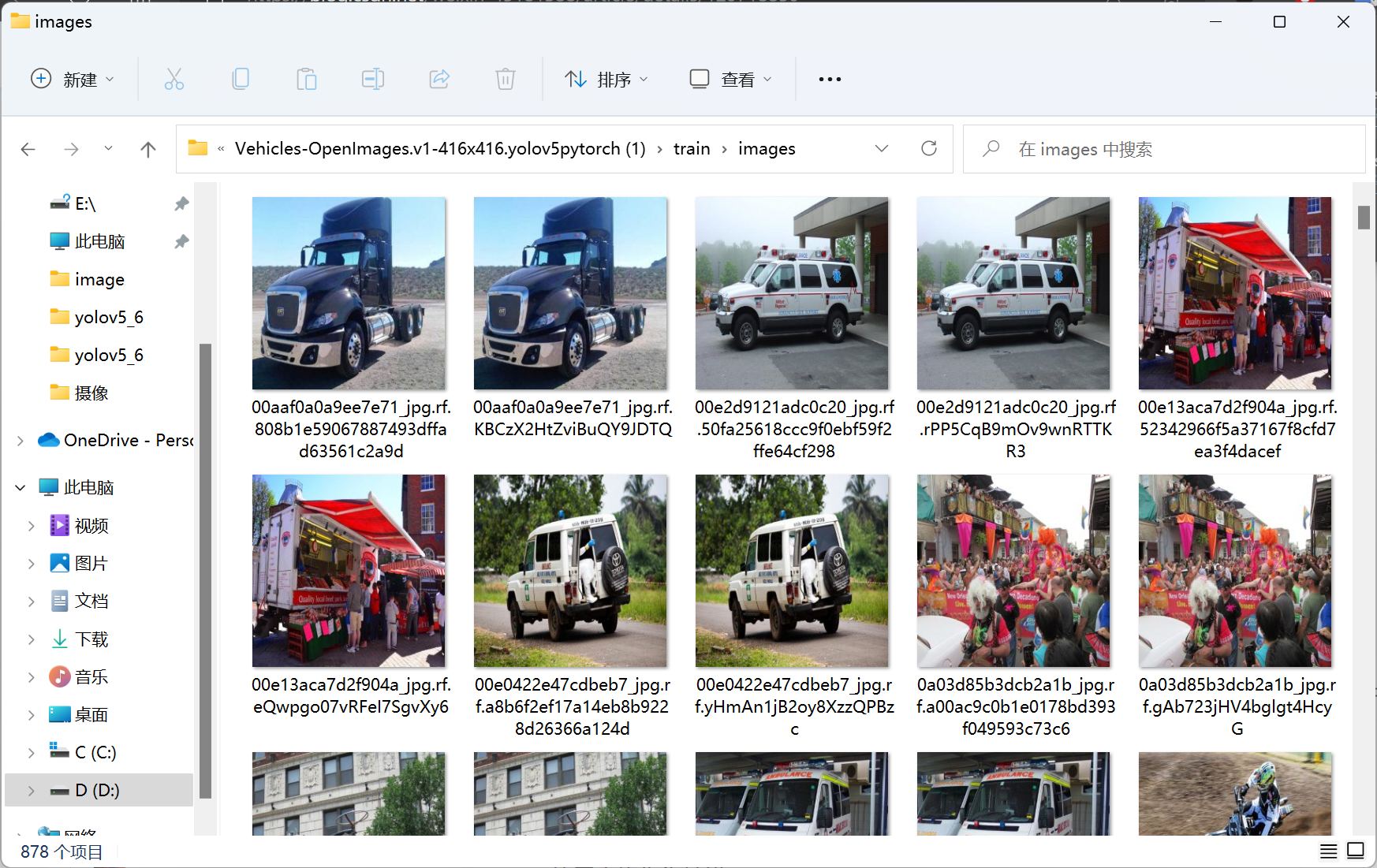
import os
root = "D:/Users/CV learning/pytorch/data/Vehicles-Open/"
dirs = ['train', 'valid', 'test']
for i, dir_name in enumerate(dirs):
all_image_names = sorted(os.listdir(f"{root}{dir_name}/images/"))
for j, image_name in enumerate(all_image_names):
if (j % 2) == 0:
file_name = image_name.split('.jpg')[0]
os.remove(f"{root}{dir_name}/images/{image_name}")
os.remove(f"{root}{dir_name}/labels/{file_name}.txt")
我们将整理好的数据集放入yolov5_6/data文件夹下,数据集的data.yaml需要剪切至yolov5_6/data文件夹下,即Vehicles-Open文件夹和data.yaml在同一文件夹下。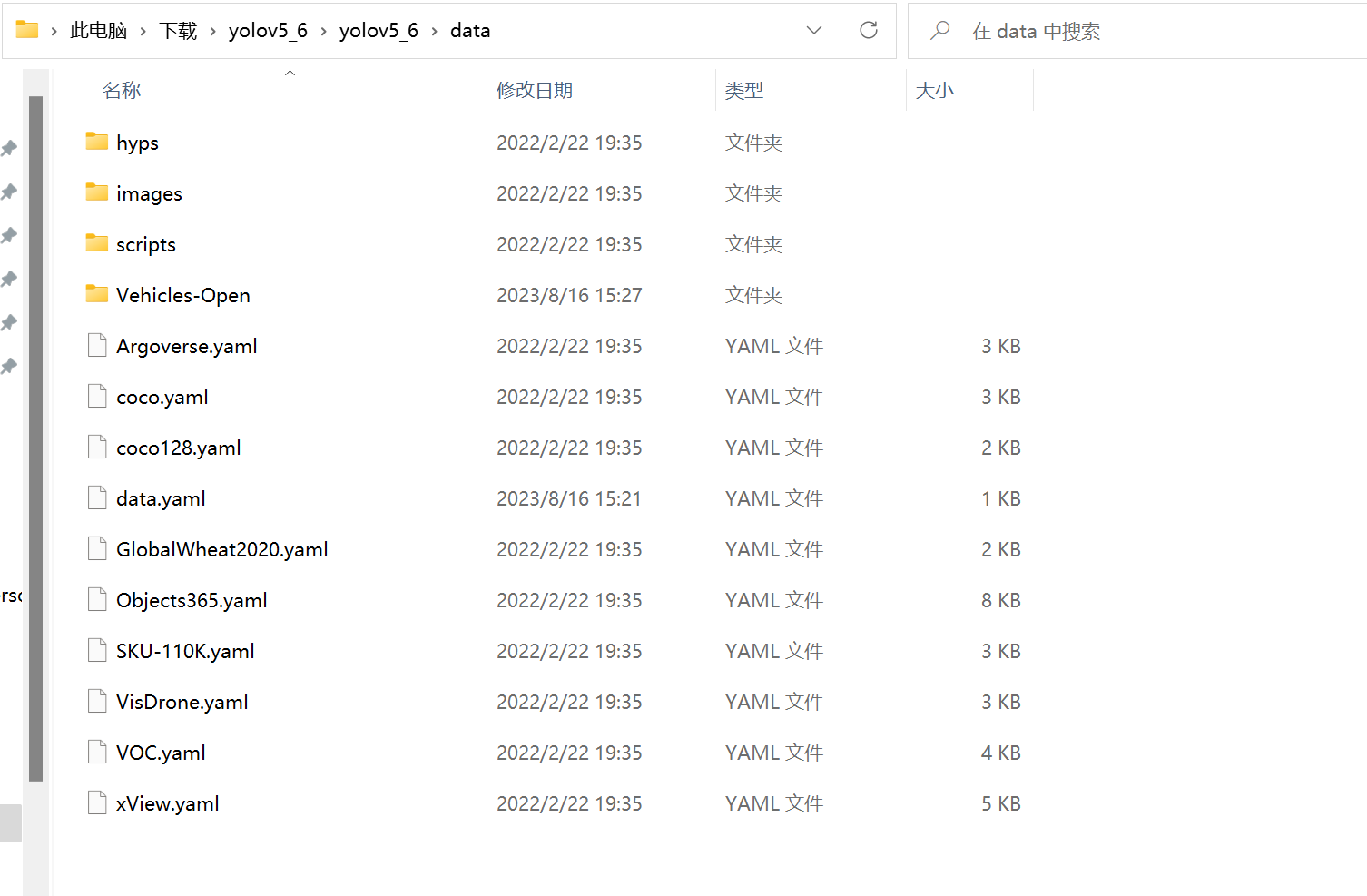
与此同时我们也需要将data.yaml做一些修改,修改如下:train: ../train/images -->train: data/Vehicles-Open/train/imagesval: ../valid/images -->val: data/Vehicles-Open/valid/images
2. 下载yolov5源码和预训练权重
yolov5源码下载地址:https://github.com/ultralytics/yolov5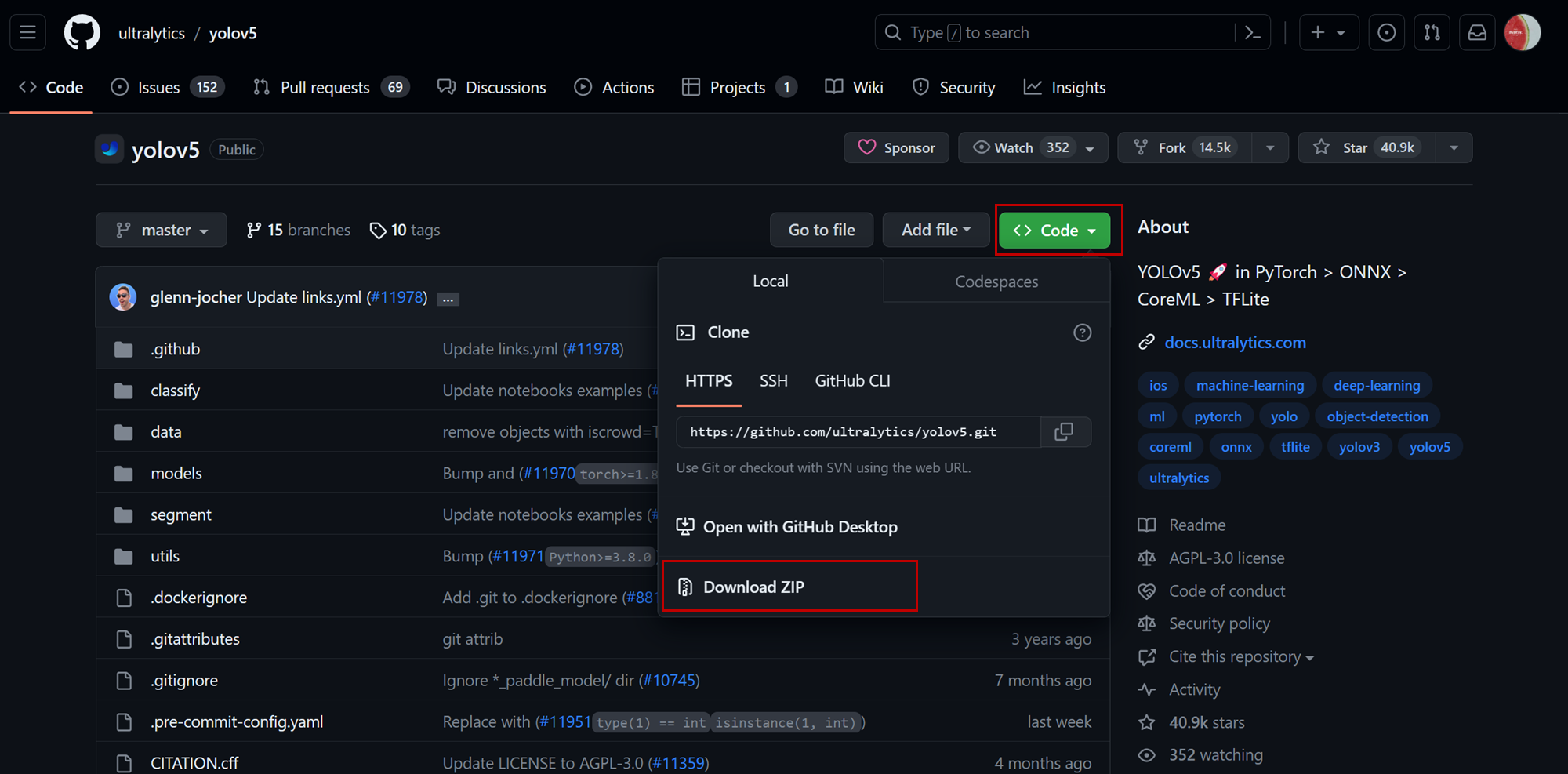
yolov5预训练权重下载地址:https://github.com/ultralytics/yolov5/releases,yolov5目前为止已有7个版本,每个版本下都有Asset,根据自己需要选择预训练权重(和源码版本对上)。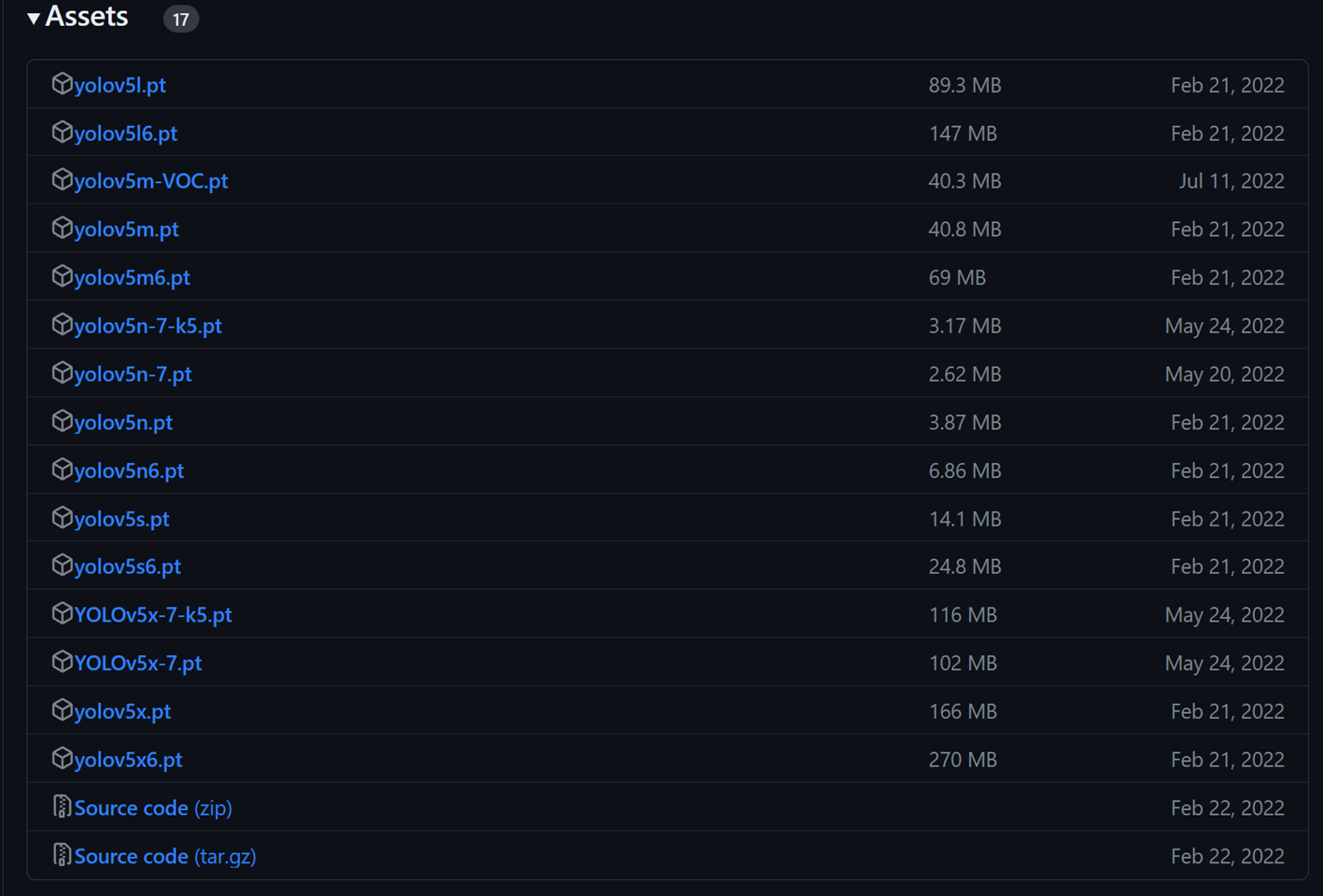
笔者下载的是yolov5_6.1的源码文件:
3. 部署yolov5的环境
3.1. 本地部署
本地部署建议先安装好pytorch,然后再通过源码文件中的requirements.txt文件配置yolov5所需环境。在终端中使用以下命令进行一次性安装。(强烈推荐anaconda,管理环境贼方便)
# requirements.txt是文件的路径,如D:/Users/requirements.txt
pip install -U -r requirements.txt
注意:
1)配置环境时务必关闭梯子,因为梯子的存在会引起以下两个错误(这里的matplotlib也可以是其他package)
2)如果是通过anaconda手动配置,则需要注意anaconda中并无opencv-python,需要输入pip install "opencv-python>=4.1.2"进行安装。
3.2. 云端部署
和本地部署没有多大区别,只需要修改requirements.txt的路径即可。
!pip install -U -r /kaggle/input/yolov5-data/yolov5_6/requirements.txt
注:!指开一个新的progress,执行结束后立即终止;%则是操作会继续。
3.3. 验证部署是否成功
训练验证
在pycharm的terminal中输入以下命令:
# train.py/yolov5s.yaml/yolov5s.pt,指的是该文件的路径,以下代码皆是指路径,不再复述
python train.py --cfg yolov5s.yaml --weights yolov5s.pt
在jupyter notebook、kaggle中输入以下命令:
!python train.py --cfg yolov5s.yaml --weights yolov5s.pt
注:!指开一个新的progress,执行结束后立即终止;%则是操作会继续。
检测验证
在pycharm的terminal中输入以下命令:
python detect.py --source data/images/ --weights ./yolov5s.pt
在jupyter notebook中输入以下命令:
!python detect.py --source data/images/ --weights ./yolov5s.pt
4. 使用kaggle训练模型
下面我们从整理数据、上传数据、部署云端环境、训练模型、下载训练结果等五方面出发,来完整的进行一次利用kaggle基于自定义数据训练yolo检测模型。
4.1. 修改源码
由于改变了训练数据集、且是在云端进行训练,我们必须要进行一部分源码的修改。
数据集的data.yaml修改已经介绍,这里不再赘述。yolov5s.yaml需要将nc: 80 -->nc:5,这是因为预训练使用的coco128共有80个类别,而我们的数据集共5个类别。train.py中必须要修改训练结果的保存路径,改为如下所示的路径(这里是kaggle的输出路径):
#采用kaggele训练模型一定要修改文件的保存路径
parser.add_argument('--project', default= '/kaggle/working/runs/train', help='save to project/name')
备注:我在使用kaggle训练模型时出现了如下问题(出现此问题时没有截图,因此在网上找了一张相同问题的图),看白色框内的描述。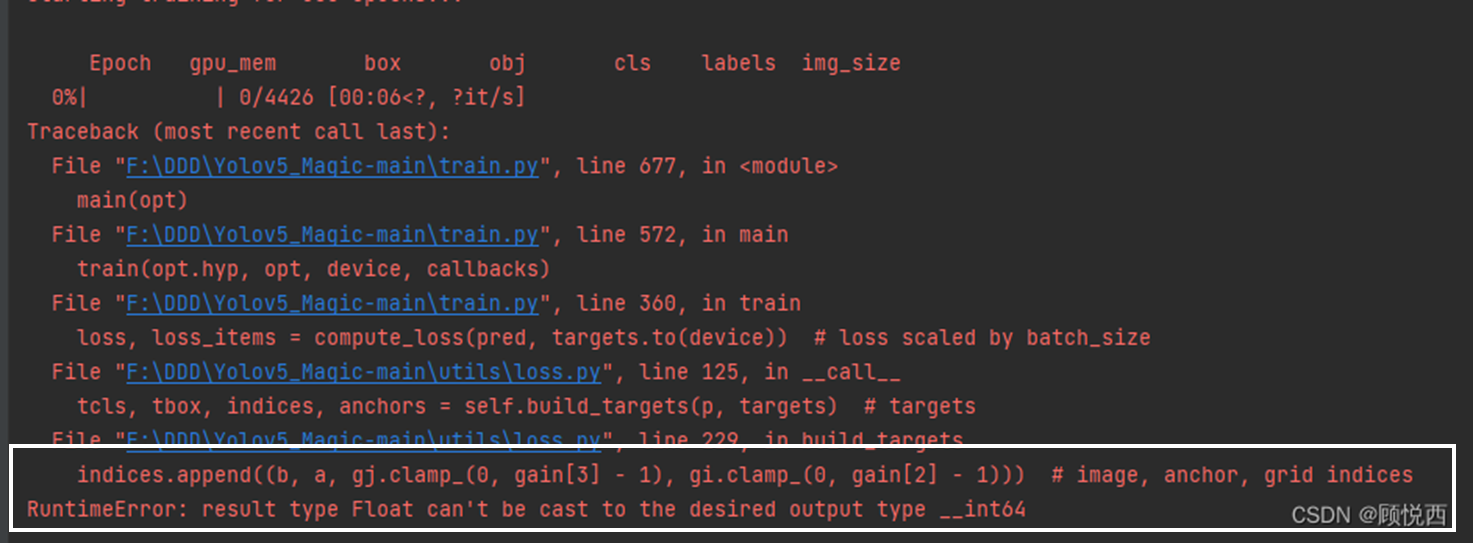
解决方法:将loss.py中gain = torch.ones(7, device=targets.device)改为gain = torch.ones(7, device=targets.device).long()即可。原因是新版本的torch无法自动执行此转换,旧版本torch可以。
4.2. 上传云端
将需要的源码和数据打包成.zip格式上传到kaggle的data中,如下图所示。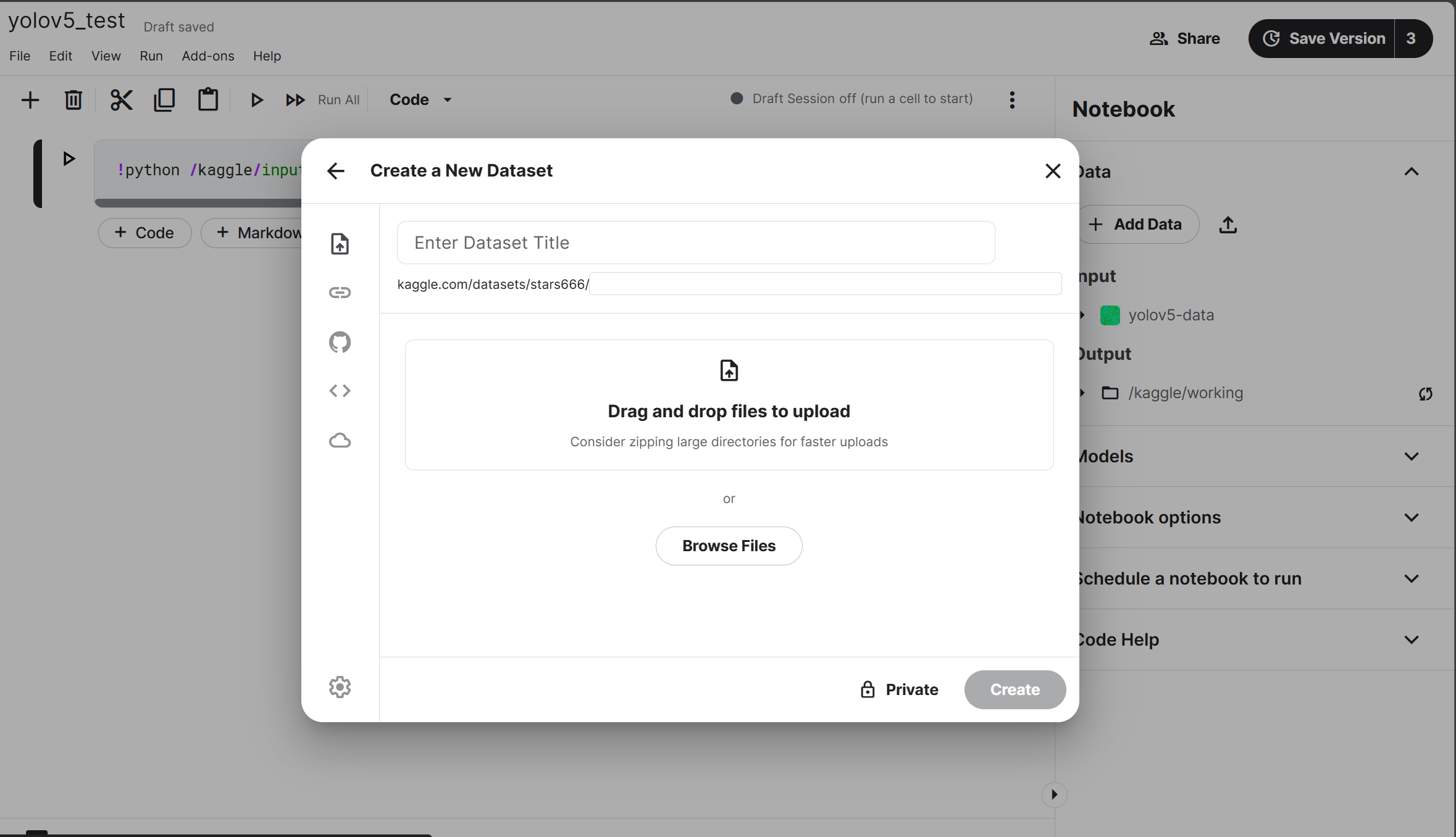
4.3. 部署环境
!pip install -U -r /kaggle/input/yolov5-data/yolov5_6/requirements.txt
运行过程中的截图: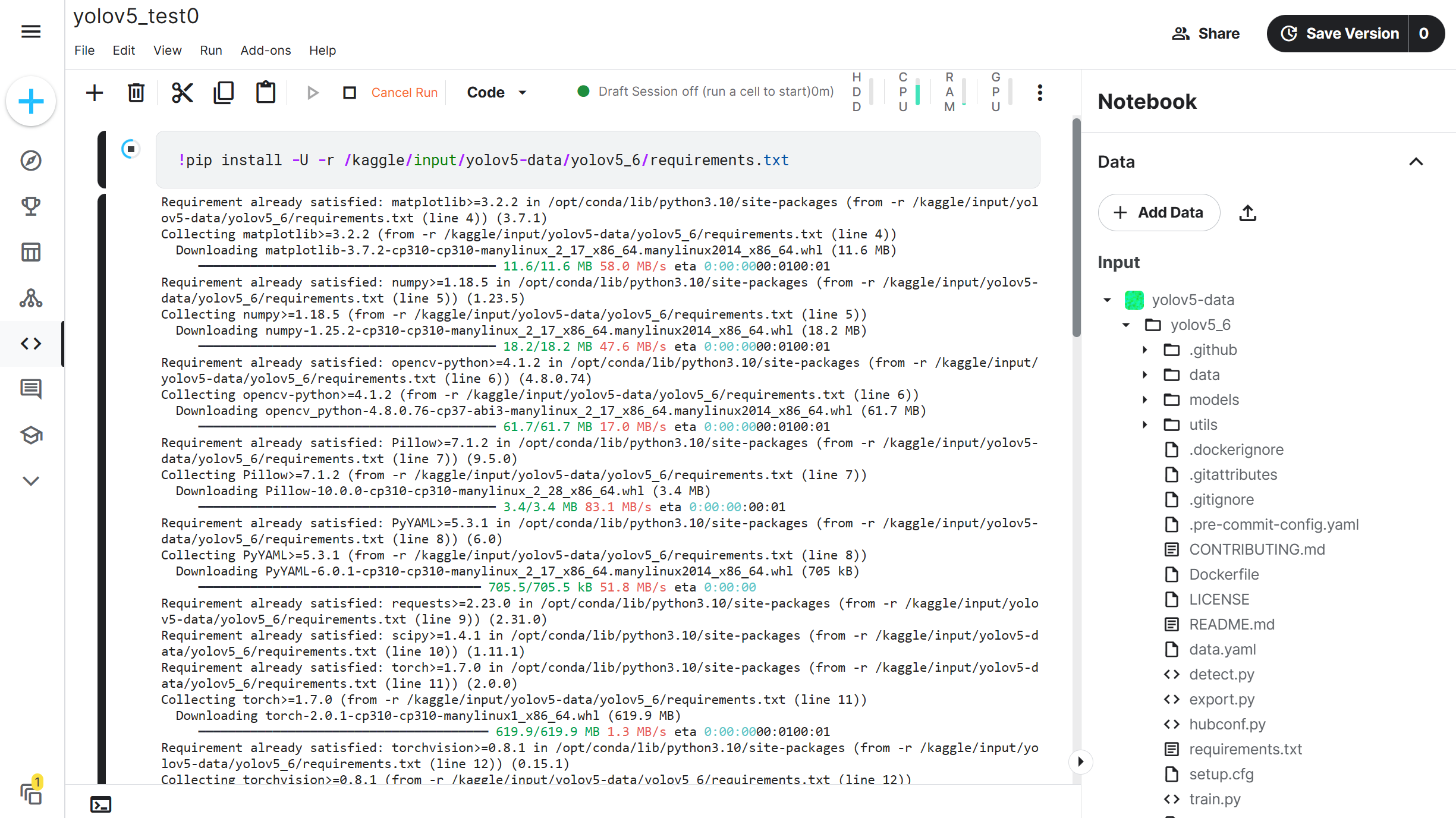
检测部署环境是否可正常运行
!python /kaggle/input/yolov5-data/yolov5_6/train.py --cfg /kaggle/input/yolov5-data/yolov5_6/models/yolov5s.yaml --epochs 10 --weights /kaggle/input/yolov5-data/yolov5_6/yolov5s6.pt
经验:第一次运行上述代码时,可能会失败,这是由于有的环境包的版本与其他包有冲突,那么kaggle会自动匹配不冲突的版本并进行下载。因此第一次运行失败后,应重启内核,该按钮位置如下图所示: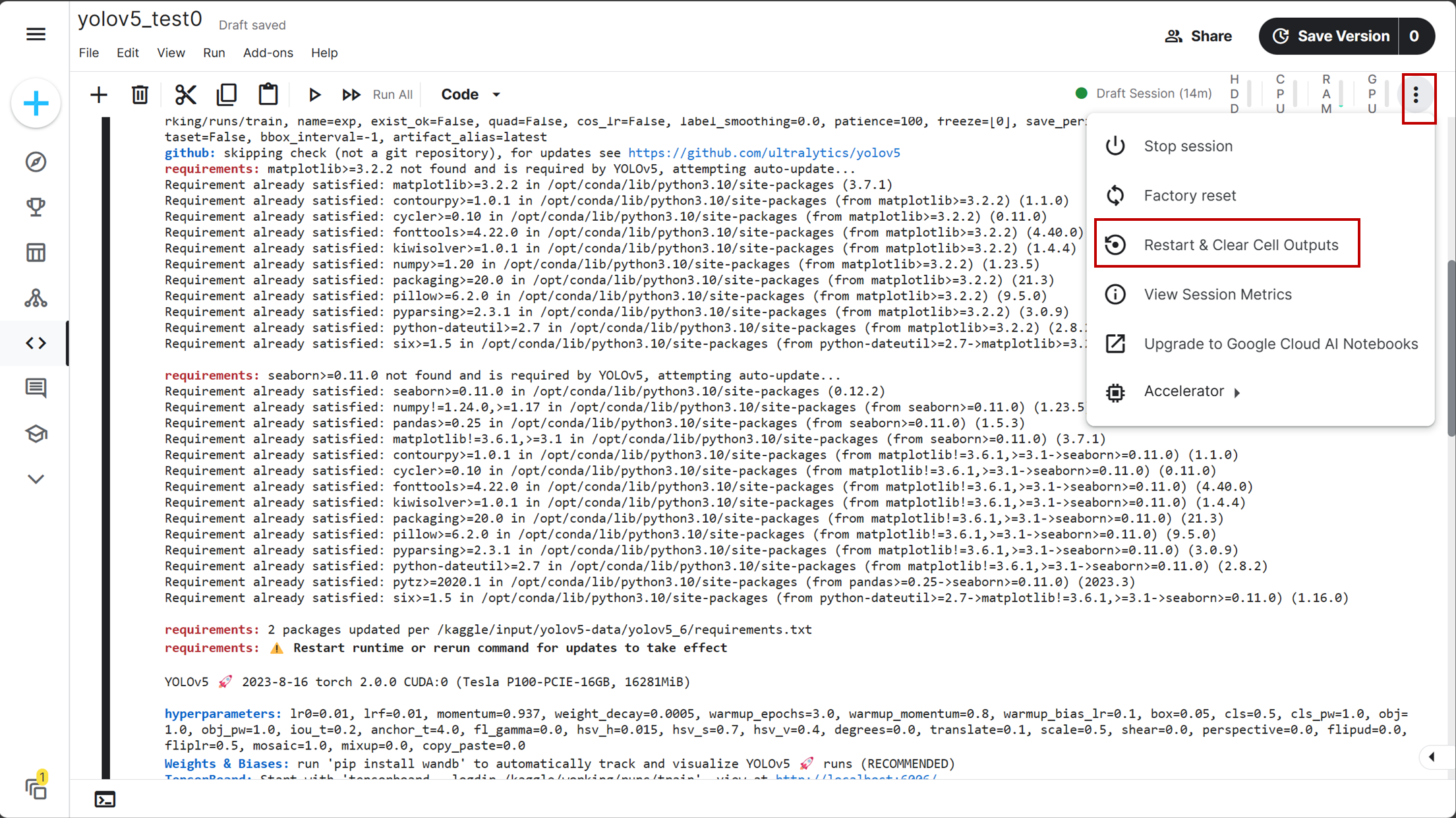
4.4. 自定义数据集训练模型
先让我们看一下train.py中的parse_opt函数,它是一个与用户交互的参数解析器函数,也就是说我们可以通过如下参数调节程序。
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
先定义epochs=5,看一下是否会出错。
!python /kaggle/input/yolov5-data/yolov5_6/train.py --data /kaggle/input/yolov5-data/yolov5_6/data/data.yaml --batch-size 32 --epochs 5 --cfg /kaggle/input/yolov5-data/yolov5_6/models/yolov5s.yaml --weights /kaggle/input/yolov5-data/yolov5_6/yolov5s6.pt
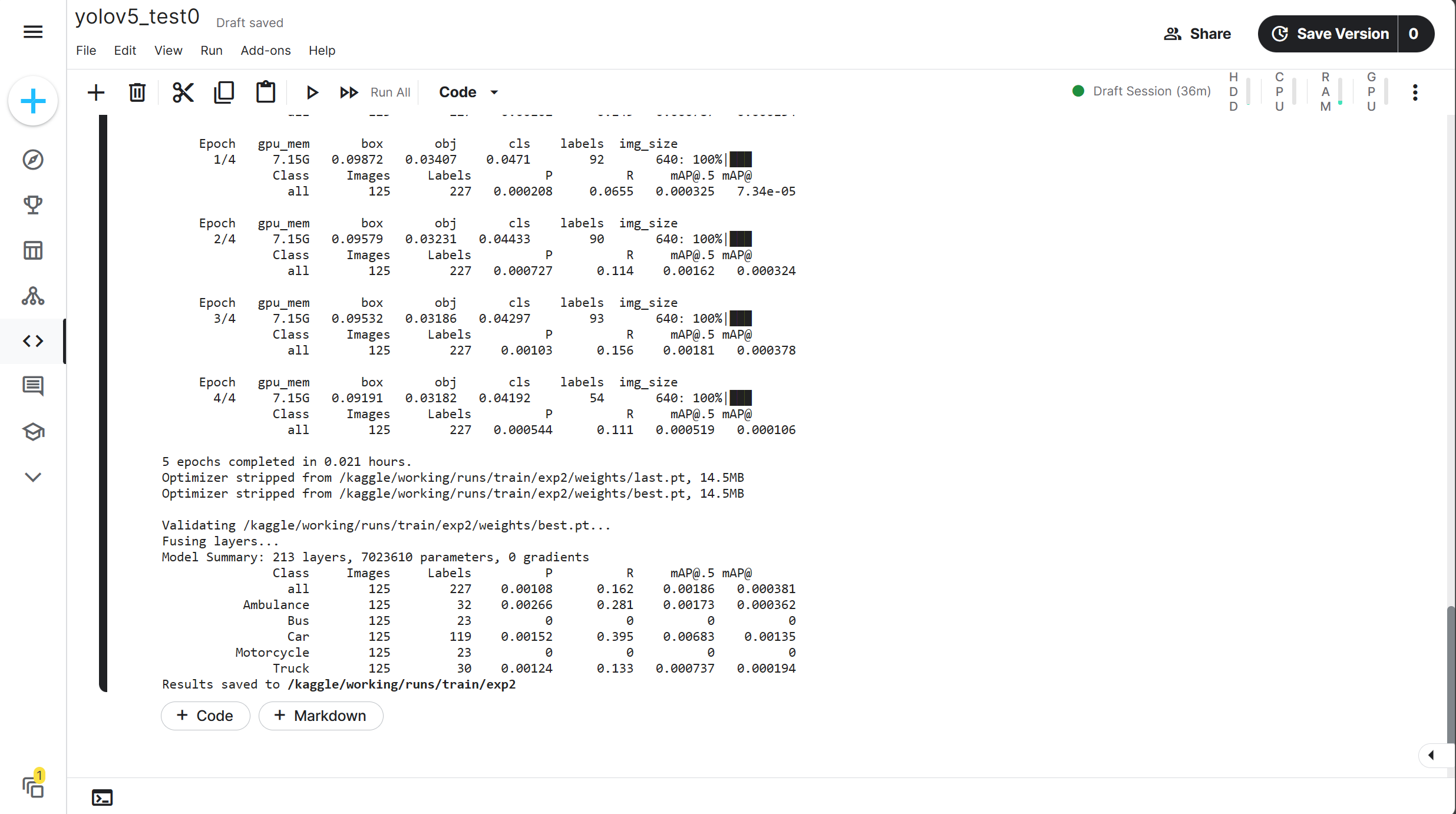
可以看到能够正常无误的运行,现在让我们把epochs调到100,进入后台运行。进入后台运行是指保存此版本程序并运行,即点击Save Version进行保存版本,并选择保存并运行方式保存。
注意:进入后台运行前一定要把!pip install -U -r /kaggle/input/yolov5-data/yolov5_6/requirements.txt删去,不然后台会重新部署环境并导致不必要的问题出现。
4.5. 下载训练结果
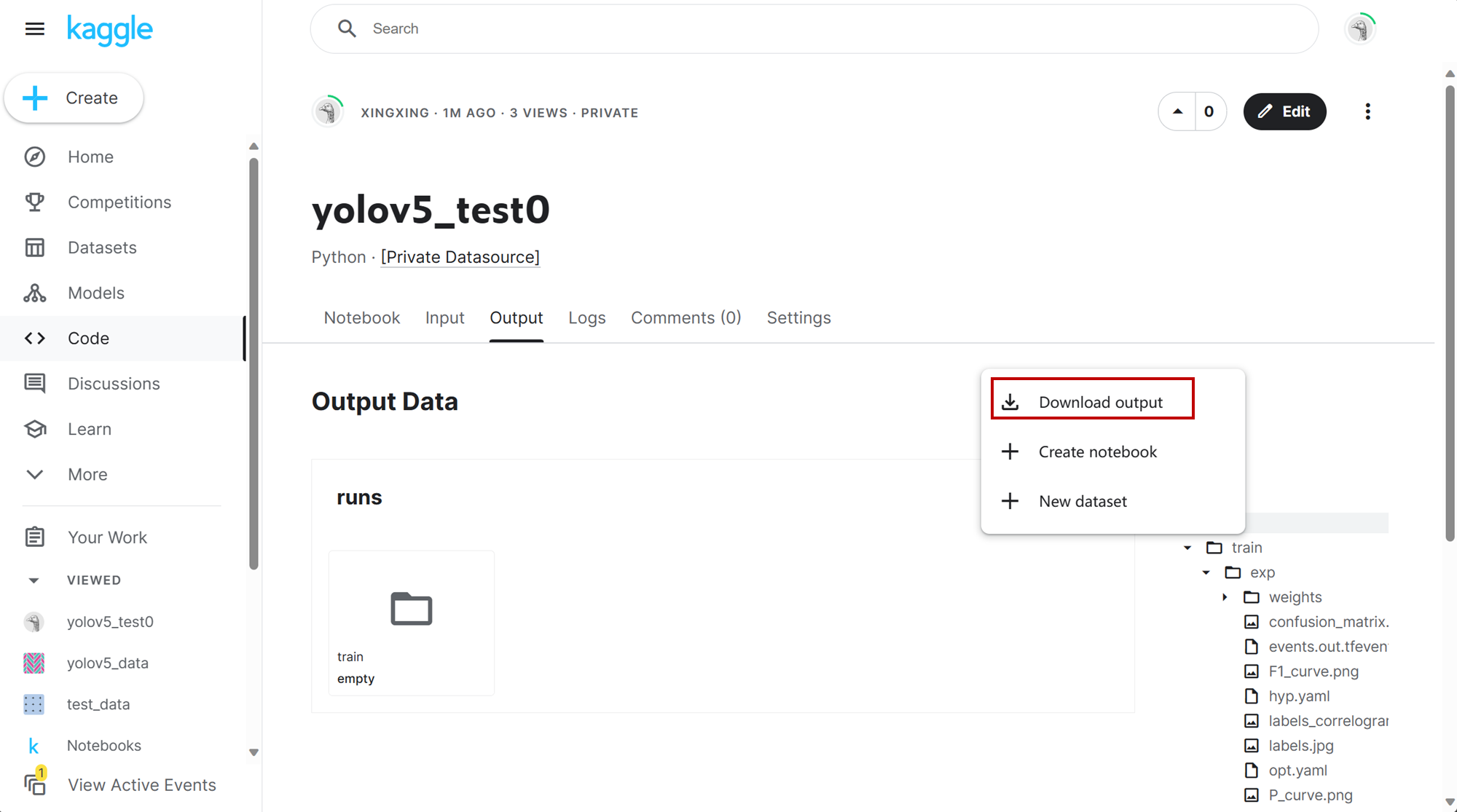

5. 本地加载训练后的权重进行推理
选择要进行推理的环境,笔者这里使用的是pycharm-->部署yolov5环境-->创建项目。
假如已经有了项目文件夹,但确忘记路径,可以调用在终端输入pwd,查看当前的工作路径。
将yolov5的源码、要推理的图片和下载的训练权重文件夹放入项目文件夹,如下图所示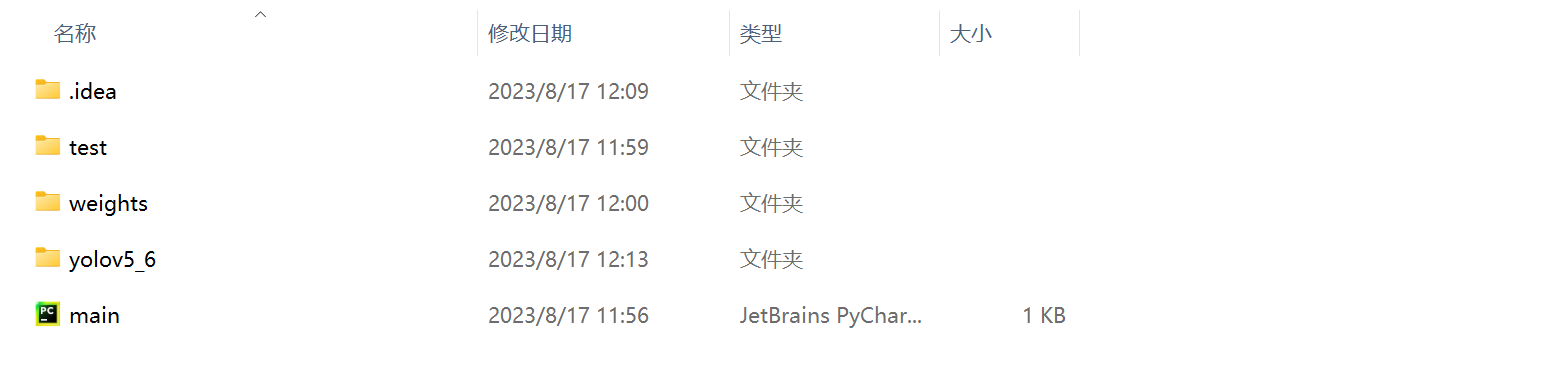
在此之前我们先来看一下detect.py中的parse_opt函数,它是一个与用户交互的参数解析器函数,也就是说我们可以通过如下参数调节程序。
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
做好以上准备后,我们进入pycharm调出终端窗口,如下图
在终端输入如下命令即可。
python yolov5_6/detect.py --weights weights/best.pt --source test/images/
我们可以在yolov5源码文件夹中的runs/detect/exp查看推理结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号