利用pytorch准备数据集、构建与训练、保存与加载CNN模型
本文的主要内容是利用pytorch框架与torchvision工具箱,进行准备数据集、构建CNN网络模型、训练模型、保存和加载自定义模型等工作。本文若有疏漏、需更正、改进的地方,望读者予以指正,如果本文对您有一定点帮助,请您给个赞、推荐和关注哦,在此,谢谢大家啦!!!
笔者的运行环境:CPU (AMD Ryzen™ 5 4600U) + pytorch (1.13,CPU版) + jupyter;
本文所用到的资源:链接:https://pan.baidu.com/s/1WgW3IK40Xf_Zci7D_BVLRg 提取码:1212
1. torchvision工具箱
1.1. torchvision简介
torchvision是基于pytorch的工具箱(它需要独立安装),主要用来处理图像数据,其内包含一些常用的数据集、模型、图像转换等。torchvision工具箱主要包含以下四大模块:
- torchvision.models:提供深度学习中各种经典的网络结构、预训练好的模型,如:Alex-Net、VGG、ResNet、Inception等。
- torchvision.datasets:提供常用的数据集,设计上继承torch.utils.data.Dataset,主要包括:MNIST、CIFAR10/100、ImageNet、COCO等。
- torchvision.transforms:提供常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
- torchvision.utils:工具类,如保存张量作为图像到磁盘,给一个小批量创建一个图像网格。
1.2. torchvision.models简述
torchvision.models模块包含以下模型结构,AlexNet、VGG、GoogLeNet、ResNet、SqueezeNet、DenseNet等常用模型结构。其中,每个模型结构又可以根据卷积核大小、网络层深度等细分成不同的模型。例如,ResNet就提供了5种不同深度的模型,分别为resnet18、resnet34、resnet50、resnet101、resnet152。
1.2.1. 加载预训练模型及其参数权重
torchvision提供了各种模型的预训练模型,我们可以在此基础上针对性地调整,这大大减少了工作量。加载预训练模型的过程如下,这里以resnet18模型为例。
import torchvision
resnet18 = torchvision.models.resnet18(pretrained=True)
以上代码运行结果:
预训练模型加载完成后我们可以使用model.atate_dict()方法查看训练好的权重。
resnet18.state_dict()
部分运行结果:
现在,让我们进一步了解torchvision.models.resnet18()。
语法:torchvision.models.resnet18(*, weights: Union[torchvision.models.resnet.ResNet18_Weights, NoneType] = None, progress: bool = True, **kwargs: Any) ---> torchvision.models.resnet.ResNet
参数:Union---是否使用预训练权重,默认不使用;当pretrained=True,使用预训练权重。
备注:resnet18 = torchvision.models.resnet18(),表示随机初始化权重创建模型。
1.2.2. 加载预训练模型并自定义参数权重
我们也可以只加载模型的网络结构,然后置入自定义的参数权重(该参数权重一定要符合该网络结构)。
import torchvision
# 导入模型的网络结构,并随机初始化参数权重
resnet18 = torchvision.models.resnet18()
# 查看随机参数权重
resnet18.state_dict()
# 加载本地的参数权重
resnet18.load_state_dict(torch.load("D:\\Users\\CV learning\\pytorch\\data\\resnet18-f37072fd.pth"))
# 查看加载后的参数权重
resnet18.state_dict()
1.2.3. 调整预训练模型
预训练的模型有些层并不是直接能用,需要我们微微改一下,比如,resnet最后的全连接层是分1000类,而我们只有21类;或resnet第一层卷积接收的通道是3, 我们可能输入图片的通道是4,那么可以通过以下方法修改:
from torchvision import models
from torch import nn
resnet34 = models.resnet34(pretrained=True, num_classes=1000)
# 默认是ImageNet上的1000分类,这里修改最后的全连接层为10分类问题
resnet34.fc = nn.Linear(512, 10)
1.3. torchvision.datasets简述
提供常用的数据集,设计上继承torch.utils.data.Dataset,主要包括:MNIST、Fashion-MNIST、CIFAR10/100、ImageNet、COCO等。
1.3.1. 加载网络数据集
torchvision提供的数据集允许从网络上下载,具体使用方法如下,我们以加载Fashion-MNIST为例。
from torchvision import datasets
data_train = datasets.FashionMNIST("D:\\Users\\CV learning\\pytorch\\data\\",
download=True, train=False, transform=None)
现在,让我们详细了解一下torchvision.datasets.FashionMNIST()。
语法:torchvision.datasets.FashionMNIST(root, train=True, transform=None, target_transform=None, download=False)
参数:
root---存放MNIST/processed/training.pt和MNIST/processed/test.pt的数据集的根目录。即,存放下载的或是要加载的数据集的根目录。
train---可选,如果为True,则从training.pt创建数据集,否则从test.pt创建数据集。
transform---可选,即图像变换操作。
target_transform---可选,接受目标并对其进行转换的函数/转换。
download---可选,如果为true,则从internet下载数据集并将其放在根目录中。如果数据集已下载,则不会再次下载。
备注:不同数据集的对应的函数不同,详见Datasets — Torchvision 0.15 documentation。
1.3.2. 加载本地数据集
torchvision.datasets.ImageFolder可以用来加载本地数据集,它要求我们以下面这种格式来组织数据集的训练、验证或者测试图片。
语法:dataset=torchvision.datasets.ImageFolder(root, transform=None,target_transform=None, loader=
参数:
root---图片存储的根目录,即各类别文件夹所在目录的上一级目录。
transform---对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片。
target_transform---对图片类别进行预处理的操作,输入为 target,输出对其的转换。 如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…。root下的每个文件夹为一个类别。
loader---表示数据集加载方式,通常默认加载方式即可。
is_valid_file---获取图像文件的路径并检查该文件是否为有效文件的函数(用于检查损坏文件)
返回:返回的是一个dataset(也可以理解为Dataset的一个子类),它的结构就是[(img_data,class_id),(img_data,class_id),…]。
返回值的属性:
self.classes:用一个 list 保存类别名称。
self.class_to_idx:类别对应的索引,与不做任何转换返回的 target 对应。
self.imgs:保存(img-path, class) tuple的 list。
备注:torchvision.datasets.ImageFolder()的源码链接:torchvision.datasets.folder — Torchvision 0.15 documentation
from torchvision.datasets import ImageFolder
from torchvision import transforms
transform = transforms.ToTensor()
root = "D:\\Users\\CV learning\\pytorch\\data\\an1"
dataset = ImageFolder(root, transform=transform)
print(dataset[0])
print(dataset.classes) #根据分的文件夹的名字来确定的类别
print(dataset.class_to_idx) #按顺序为这些类别定义索引为0,1...
print(dataset.imgs) #返回从所有文件夹中得到的图片的路径以及其类别
'''
(tensor([[[0.7961, 0.7961, 0.8000, ..., 0.9412, 0.9373, 0.9333],
[0.7961, 0.7961, 0.8000, ..., 0.9451, 0.9412, 0.9333],
[0.7961, 0.7961, 0.8000, ..., 0.9451, 0.9412, 0.9373],
...,
[0.6000, 0.6000, 0.6000, ..., 0.0078, 0.0078, 0.0078],
[0.5961, 0.5961, 0.5961, ..., 0.0078, 0.0078, 0.0078],
[0.5922, 0.5922, 0.5922, ..., 0.0039, 0.0039, 0.0039]],
[[0.6431, 0.6431, 0.6471, ..., 0.7882, 0.7843, 0.7804],
[0.6431, 0.6431, 0.6471, ..., 0.7922, 0.7882, 0.7804],
[0.6431, 0.6431, 0.6471, ..., 0.7922, 0.7882, 0.7843],
...,
[0.4784, 0.4784, 0.4784, ..., 0.0078, 0.0078, 0.0078],
[0.4745, 0.4745, 0.4745, ..., 0.0078, 0.0078, 0.0078],
[0.4706, 0.4706, 0.4706, ..., 0.0039, 0.0039, 0.0039]],
[[0.3412, 0.3412, 0.3451, ..., 0.4784, 0.4745, 0.4706],
[0.3412, 0.3412, 0.3451, ..., 0.4824, 0.4784, 0.4706],
[0.3412, 0.3412, 0.3451, ..., 0.4824, 0.4784, 0.4745],
...,
[0.2157, 0.2157, 0.2157, ..., 0.0000, 0.0000, 0.0000],
[0.2118, 0.2118, 0.2118, ..., 0.0000, 0.0000, 0.0000],
[0.2078, 0.2078, 0.2078, ..., 0.0000, 0.0000, 0.0000]]]), 0)
['cat', 'dog']
{'cat': 0, 'dog': 1}
[('D:\\Users\\CV learning\\pytorch\\data\\an\\cat\\cat.0.jpg', 0),
('D:\\Users\\CV learning\\pytorch\\data\\an\\cat\\cat.1.jpg', 0),
('D:\\Users\\CV learning\\pytorch\\data\\an\\cat\\cat.2.jpg', 0),
('D:\\Users\\CV learning\\pytorch\\data\\an\\dog\\dog.0.jpg', 1),
('D:\\Users\\CV learning\\pytorch\\data\\an\\dog\\dog.1.jpg', 1),
('D:\\Users\\CV learning\\pytorch\\data\\an\\dog\\dog.2.jpg', 1)]
'''
1.4 torchvision.transforms简述
transforms包含了一些图像预处理操作,这些操作可以使用torchvison.transforms.Compose连在一起进行串联操作。这些操作有:
__all__ = ["Compose", "ToTensor", "ToPILImage", "Normalize", "Resize",
"CenterCrop", "Pad", "Lambda", "RandomApply", "RandomChoice", "RandomOrder",
"RandomCrop", "RandomHorizontalFlip", "RandomVerticalFlip", "RandomResizedCrop",
"RandomSizedCrop", "FiveCrop", "TenCrop", "LinearTransformation", "ColorJitter",
"RandomRotation", "RandomAffine", "Grayscale", "RandomGrayscale"]
- Compose():用来管理所有的transforms操作。
- ToTensor():把图片数据转换成张量并转化范围在[0,1]区间内。
- ToPILImage():将Tensor或numpy.ndarray转换为PIL Image。
- Normalize(mean, std):归一化(标准化)。具体见,pytorch中归一化transforms.Normalize的真正计算过程
- Resize(size):输入的PIL图像调整为指定的大小,参数可以为int或int元组。
- CenterCrop(size):将给定的PIL Image进行中心切割,得到指定size的tuple。
- Pad(padding, fill=0, padding_mode=‘constant’):对PIL边缘进行填充。
- RandomApply(transforms, p=0.5):随机选取变换。
- RandomCrop(size, padding=0):随机中心点切割。size可以是tuple也可以是Integer
- RandomHorizontalFlip():随机水平翻转给定的PIL Image。
- RandomVerticalFlip():随机垂直翻转给定的PIL Image。
- FiveCrop(size):将给定的PIL图像裁剪成4个角落区域和中心区域。
- RandomAffine(degrees, translate=None, scale=None):保持中心不变的图片进行随机仿射变化。
- Grayscale(num_output_channels=1):对图像进行灰度变换。
备注:torchvision.transforms.Compose()的源码链接:torchvision.transforms.transforms — Torchvision 0.15 documentation
我们可以将transfors.Compose类的实例化可以理解成生成一个图像变换器,实例化过程中传入的参数就是图像的变换操作,操作之间是串联关系。
import torch
import torchvision
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
transform = transforms.Compose([transforms.ToTensor(),
transforms.Resize((300, 300)),
transforms.RandomAffine(degrees=30),
transforms.RandomHorizontalFlip(),
transforms.ToPILImage()])
img = Image.open("D:\\Users\\CV learning\\opencv learning\\image\\lena.jpg")
imgs1 = transform(img)
imgs2 = transform(img)
imgs3 = transform(img)
plt.subplot(1, 3, 1), plt.imshow(imgs1), plt.title("img1")
plt.subplot(1, 3, 2), plt.imshow(imgs2), plt.title("img2")
plt.subplot(1, 3, 3), plt.imshow(imgs3), plt.title("img3")
plt.show()
运行结果:
注:需要注意的是transforms模块中类或函数的操作对象是torch.Tensor类或PIL.Image.Image类。
1.5. torchvision.utils简述
torchvision.utils模块主要介绍两个函数,即torchvision.utils.make_grid()和torchvision.utils.save_image()函数。
1.5.1. torchvision.utils.make_grid()
torchvision.utils.make_grid()将多张图像组合成一张网格图像,和九宫格图像挺像的。
语法:torchvision.utils.make_grid(tensor: Union[Tensor, List[Tensor]], nrow: int = 8, padding: int = 2, normalize: bool = False, value_range: Optional[Tuple[int, int]] = None, scale_each: bool = False, pad_value: float = 0.0, kwargs) ---> torch.Tensor
参数:**
tensor(Tensor or list)---4维张量(Tensor.shape=(B x C x H x W))或相同尺寸的图像。
nrow(int, 可选 )---网格中每行显示的图像数量。
padding(int, 可选)---图像之间的填充像素数。
normalize(bool, 可选)---如果为True,将网格图像使用value_range的最小值和最大值进行归一化。
value_range (tuple, 可选)---归一化图像的最小值和最大值。默认情况下,最小值和最大值从张量计算。
scale_each (bool, 可选)---缩放批中的每个图像 图像单独显示,而不是所有图像上的(最小值、最大值)。
pad_value (float, 可选)---填充像素的大小。
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
import torchvision
import matplotlib.pyplot as plt
transform = transforms.Compose([transforms.ToTensor(),
transforms.Resize((300, 300))])
root = "D:\\Users\\CV learning\\pytorch\\data\\an2"
dataset = ImageFolder(root, transform=transform)
data_loder = DataLoader(dataset=dataset, batch_size=32, shuffle=True)
for imgs, label in data_loder:
img_tensor = torchvision.utils.make_grid(imgs, nrow=8, padding=10)
imgs = transforms.ToPILImage()(img_tensor)
plt.imshow(imgs)
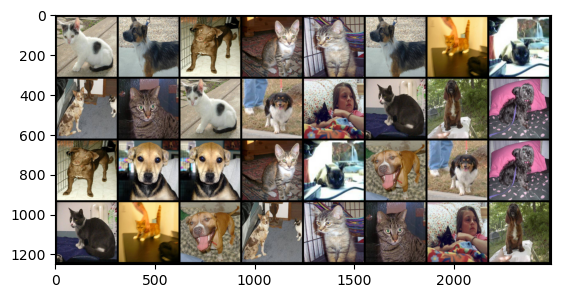
1.5.2. torchvision.utils.save_image()
torchvision.utils.save_image()函数只能保存RGB彩色图像,如果网络的输出是单通道灰度图像,则该函数依然会输出三个通道,每个通道的数值都是相同的,即“伪灰度图像”。
语法:torchvision.utils.save_image(tensor: Union[torch.Tensor, List[torch.Tensor]], fp: Union[str, pathlib.Path, BinaryIO], format: Union[str, NoneType] = None, kwargs) ---> None
参数:**
tensor(Tensor or list)---要保存的图像的张量。如果是B x C x H x W形式的四维张量,需要将其转换为网格图像进行保存。
fp (string or file object)---保存路径。
format (可选)--- 如果省略,则使用要使用的格式从文件名扩展名确定。如果使用文件对象而不是文件名,则应始终使用此参数。
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
import torchvision
transform = transforms.Compose([transforms.ToTensor(),
transforms.Resize((300, 300))])
root = "D:\\Users\\CV learning\\pytorch\\data\\an2"
dataset = ImageFolder(root, transform=transform)
data_loder = DataLoader(dataset=dataset, batch_size=8, shuffle=True)
i=0
for imgs, label in data_loder:
img_tensor = torchvision.utils.make_grid(imgs, nrow=8, padding=10)
torchvision.utils.save_image(img_tensor, fp=f"D:\\Users\\CV learning\\pytorch\\data\\an2\\{i}.jpg")
i+=1

1.6. 参考内容
- Pytorch torchvision库使用详情
- FashionMNIST — Torchvision 0.15 documentation
- torchvision.datasets.ImageFolder使用详解_HealthScience的博客-CSDN博客
- 【pytorch】transforms.Compose()使用
- make_grid — Torchvision 0.15 documentation
2. 数据集的准备
在训练网络模型时,我们可以使用torchvision库自带的数据集(torchvision.datasets),也可以使用自己的数据集。实际运用中一般都是使用自己的数据集,本文就讲一下该如何准备自己的数据。这里呢,笔者偷了个懒,我使用的是下载好的FashionMNIST数据集,刚好这里也讲一下如何将.ubyte文件转换为.jpg文件。
2.1. 一个例子
首先来看一个例子:
import os
import cv2
import torchvision.datasets.mnist as mnist
root="D:\\Users\\CV learning\\pytorch\\FashionMNIST\\raw\\"
# 读取训练图像和对应标签,并将其转换为Tensor类型
train_set=(mnist.read_image_file(root+"train-images-idx3-ubyte"),
mnist.read_label_file(root+"train-labels-idx1-ubyte"))
# 读取测试图像和对应标签,并将其转换为Tensor类型
test_set=(mnist.read_image_file(root+"t10k-images-idx3-ubyte"),
mnist.read_label_file(root+"t10k-labels-idx1-ubyte"))
# 输出训练数据和测试数据的相关信息
print("训练图像数据集的有关信息---",train_set[0].size())
print("测试图像数据集的有关信息---",test_set[0].size())
#定义一个函数将数据集转换为图像
def convert_to_img(train=True):
if train:
f = open(root+"train.txt", "w")
data_path = root+"train\\"
#判断是否存在data_path文件夹,若不存在则创建一个
if not os.path.exists(data_path):
os.makedirs(data_path)
#将image、label组合成带有序列的迭代器,并遍历;保存图像,并保存图像地址和标签在.txt中
for i, (img, label) in enumerate(zip(train_set[0], train_set[1])):
img_path = data_path+str(i)+".jpg"
cv2.imwrite(img_path, img.numpy())
f.write(img_path+'---'+str(int(label))+'\n')
f.close()
else:
f = open(root+"test.txt", "w")
data_path = root+"test\\"
#判断是否存在data_path文件夹,若不存在则创建一个
if not os.path.exists(data_path):
os.makedirs(data_path)
#将image、label组合成带有序列的迭代器,并遍历;保存图像,并保存图像地址和标签在.txt中
for i, (img, label) in enumerate(zip(test_set[0], test_set[1])):
img_path = data_path+str(i)+'.jpg'
cv2.imwrite(img_path, img.numpy())
f.write(img_path+'---'+str(int(label))+'\n')
f.close()
convert_to_img(True)
convert_to_img(False)
import torch
import cv2
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
root = "D:\\Users\\CV learning\\pytorch\\FashionMNIST\\raw\\"
class MyDataset(Dataset):
def __init__(self, txt, transform = None):
with open(txt, 'r') as ft:
imgs = []
for line in ft:
line = line.strip('\n')
words = line.split('---')
imgs.append((words[0], int(words[1])))
self.imgs = imgs
self.transform = transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = cv2.imread(fn, cv2.IMREAD_COLOR)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_data = MyDataset(root+'train.txt', transform=transforms.ToTensor())
test_data= MyDataset(root+'test.txt', transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=64)
从上面的例子可以看出,数据集的准备就是将不适用于pytorch的数据转换为适用的数据类型,即Tensor;当训练样本数量太过庞大时,需要分成多个Batch来训练,因此就需要设置batch_size的大小。上个例子中的数据并没有在GPU中建立副本,通常为了充分调用GPU,还需要设置一些如num_workers、pin_memory等参数。
具体而言,数据集的准备与torch.utils.data模块下DataSet、DataLoader和Sampler类有关,下面让我们来看看这三个类之间的关系。
2.2. DataSet、DataLoader和Sampler
一文弄懂Pytorch的DataLoader, DataSet, Sampler之间的关系,这篇文章讲简单易懂,因此就直接拿来用了。
2.2.1 自上而下理解三者关系
首先我们看一下DataLoader.next的源代码长什么样,为方便理解我只选取了num_works为0的情况(num_works简单理解就是能够并行化地读取数据)。
class DataLoader(object):
...
def __next__(self):
if self.num_workers == 0:
indices = next(self.sample_iter) # Sampler
batch = self.collate_fn([self.dataset[i] for i in indices]) # Dataset
if self.pin_memory:
batch = _utils.pin_memory.pin_memory_batch(batch)
return batch
在阅读上面代码前,我们可以假设我们的数据是一组图像,每一张图像对应一个index,那么如果我们要读取数据就只需要对应的index即可,即上面代码中的indices,而选取index的方式有多种,有按顺序的,也有乱序的,所以这个工作需要Sampler完成,现在你不需要具体的细节,后面会介绍,你只需要知道DataLoader和Sampler在这里产生关系。
那么Dataset和DataLoader在什么时候产生关系呢?没错就是下面一行。我们已经拿到了indices,那么下一步我们只需要根据index对数据进行读取即可了。
再下面的if语句的作用简单理解就是,如果pin_memory=True,那么Pytorch会采取一系列操作把数据拷贝到GPU,总之就是为了加速。
综上可以知道DataLoader,Sampler和Dataset三者关系如下: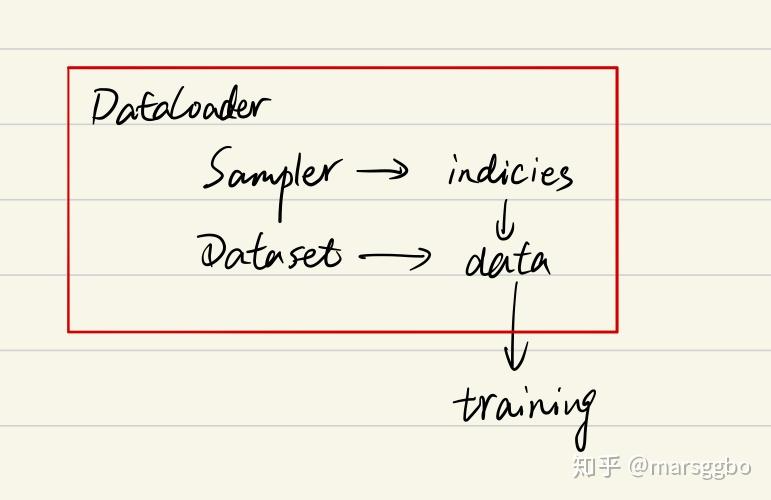
在阅读后文的过程中,你始终需要将上面的关系记在心里,这样能帮助你更好地理解。
2.2.2. Sampler
参数传递
要更加细致地理解Sampler原理,我们需要先阅读一下DataLoader 的源代码,如下:
class DataLoader(object):
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=default_collate,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
可以看到初始化参数里有两种sampler:sampler和batch_sampler,都默认为None。前者的作用是生成一系列的index,而batch_sampler则是将sampler生成的indices打包分组,得到一个又一个batch的index。例如下面示例中,BatchSampler将SequentialSampler生成的index按照指定的batch size分组。
>>>in : list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
>>>out: [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
Pytorch中已经实现的Sampler有如下几种:
SequentialSamplerRandomSamplerWeightedSamplerSubsetRandomSampler
需要注意的是DataLoader的部分初始化参数之间存在互斥关系,这个你可以通过阅读源码更深地理解,这里只做总结:
- 如果你自定义了
batch_sampler那么这些参数都必须使用默认值:batch_size,shuffle,sampler,drop_last. - 如果你自定义了
sampler,那么shuffle需要设置为False - 如果
sampler和batch_sampler都为None,那么batch_sampler使用Pytorch已经实现好的BatchSampler,而sampler分两种情况:
2.2.3. 如何自定义Sampler和BatchSampler?
仔细查看源代码其实可以发现,所有采样器其实都继承自同一个父类,即Sampler,其代码定义如下:
class Sampler(object):
r"""Base class for all Samplers.
Every Sampler subclass has to provide an :meth:`__iter__` method, providing a
way to iterate over indices of dataset elements, and a :meth:`__len__` method
that returns the length of the returned iterators.
.. note:: The :meth:`__len__` method isn't strictly required by
:class:`~torch.utils.data.DataLoader`, but is expected in any
calculation involving the length of a :class:`~torch.utils.data.DataLoader`.
"""
def __init__(self, data_source):
pass
def __iter__(self):
raise NotImplementedError
def __len__(self):
return len(self.data_source)
所以你要做的就是定义好__iter__(self)函数,不过要注意的是该函数的返回值需要是可迭代的。例如SequentialSampler返回的是iter(range(len(self.data_source)))。
另外BatchSampler与其他Sampler的主要区别是它需要将Sampler作为参数进行打包,进而每次迭代返回以batch size为大小的index列表。也就是说在后面的读取数据过程中使用的都是batch sampler。
2.2.4. Dataset
Dataset定义方式如下:
class Dataset(object):
def __init__(self):
...
def __getitem__(self, index):
return ...
def __len__(self):
return ...
上面三个方法是最基本的,其中__getitem__是最主要的方法,它规定了如何读取数据。但是它又不同于一般的方法,因为它是python built-in方法,其主要作用是能让该类可以像list一样通过索引值对数据进行访问。假如你定义好了一个dataset,那么你可以直接通过dataset[0]来访问第一个数据。在此之前我一直没弄清楚__getitem__是什么作用,所以一直不知道该怎么进入到这个函数进行调试。现在如果你想对__getitem__方法进行调试,你可以写一个for循环遍历dataset来进行调试了,而不用构建dataloader等一大堆东西了,建议学会使用ipdb这个库,非常实用!!!以后有时间再写一篇ipdb的使用教程。另外,其实我们通过最前面的Dataloader的__next__函数可以看到DataLoader对数据的读取其实就是用了for循环来遍历数据,不用往上翻了,我直接复制了一遍,如下:
class DataLoader(object):
...
def __next__(self):
if self.num_workers == 0:
indices = next(self.sample_iter)
batch = self.collate_fn([self.dataset[i] for i in indices]) # this line
if self.pin_memory:
batch = _utils.pin_memory.pin_memory_batch(batch)
return batch
我们仔细看可以发现,前面还有一个self.collate_fn方法,这个是干嘛用的呢?在介绍前我们需要知道每个参数的意义:
indices: 表示每一个iteration,sampler返回的indices,即一个batch size大小的索引列表self.dataset[i]: 前面已经介绍了,这里就是对第i个数据进行读取操作,一般来说self.dataset[i]=(img, label)
看到这不难猜出collate_fn的作用就是将一个batch的数据进行合并操作。默认的collate_fn是将img和label分别合并成imgs和labels,所以如果你的__getitem__方法只是返回 img, label,那么你可以使用默认的collate_fn方法,但是如果你每次读取的数据有img, box, label等等,那么你就需要自定义collate_fn来将对应的数据合并成一个batch数据,这样方便后续的训练步骤。
如果大家对这三个类的源码感兴趣可以阅读这篇文章:PyTorch源码解析与实践(1):数据加载Dataset,Sampler与DataLoader
2.3. 内容参考
- pytorch: 准备、训练和测试自己的图片数据 - denny402 - 博客园
- CNN训练前的准备:PyTorch处理自己的图像数据(Dataset和Dataloader)_pytorch训练自己的图片_Cyril_KI的博客-CSDN博客
- 一文弄懂Pytorch的DataLoader, DataSet, Sampler之间的关系
- PyTorch源码解析与实践(1):数据加载Dataset,Sampler与DataLoader
3. 构建CNN模型
3.1. 如何让构建一个CNN模型
构建模型的过程就是对CNN原理的代码实现,我们已经了解到CNN内部包含有卷积层、池化层、全连接层等网络层,模型的构建就是对这些层的实现以及链接。
CNN的模型的实现依赖pytorch中的torch.nn模块,而torch.nn.Module是所有模型的基类。需要注意的是,pytorch中没有“层”的概念,网络层也是基于基类torch.nn.Module实现的。直白而言,自定义CNN模型就是自定义一个类。我们知道LeNet模型内部的网络层可以根据功能,分为特征提取层(块)与全连接层(块),这种划分有利于直观理解。pytorch提供了多种容器实现“划分”,即torch.nn.Sequential类、torch.nn.Modulelist类、torch.nn.ModuleDict类等。综上,可以用下图简单示意CNN模型的构建。
3.2. nn.Sequential类
| 类别 | 区别 |
|---|---|
| Sequential类 | 1)顺序性,各网络层之间严格按照顺序构建,我们在构建网络时,一定要注意前后网络层之间输入和输出数据之间的形状是否匹配;2)自带forward()函数:在nn.Sequetial的forward()函数里通过 for 循环依次读取每个网络层,执行前向传播运算。这使得我们我们构建的模型更加简洁。 |
| Modulelist类 | 1)迭代性,常用于大量重复网络构建,通过 for 循环实现重复构建;2)内部无forward()函数。 |
| ModuleDict类 | 1)索引性,常用于可选择的网络层;2)内部无forward()函数。 |
Sequential类、Modulelist类、ModuleDict类的基类也都是torch.nn.Module,构建简单的CNN模型Sequential类是比较适合的,这里只具体介绍Sequential类。Sequential类有三种“包装形式”,具体如下。
第一种
import torch.nn as nn
model = nn.Sequential(nn.Conv2d(3, 32, 5),
nn.ReLU(),
nn.Conv2d(32, 64, 5),
nn.ReLU())
print(model)
print(model[1])
'''
Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(3): ReLU()
)
ReLU()
'''
注:这样做有一个问题,每一个层是没有名称,默认的是以0、1、2、3来命名,从上面的运行结果也可以看出。
第二种
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict({'conv1':nn.Conv2d(3, 32, 5),
'relu1':nn.ReLU(),
'conv2':nn.Conv2d(32, 64, 5),
'relu2':nn.ReLU()}))
print(model)
print(model[1])
'''
Sequential(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1))
(relu1): ReLU()
(conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(relu2): ReLU()
)
ReLU()
'''
注:从上面的结果中可以看出,这个时候每一个层都有了自己的名称,但是此时需要注意,我并不能够通过名称直接获取层,依然只能通过索引index,即model[2] 是正确的,model["conv2"] 是错误的。这其实是由它的定义实现的,看上面的Sequenrial定义可知,只支持index访问。
第三种
import torch.nn as nn
model = nn.Sequential()
model.add_module('conv1',nn.Conv2d(3, 32, 5))
model.add_module('relu1',nn.ReLU())
model.add_module('conv2',nn.Conv2d(32, 64, 5))
model.add_module('relu2',nn.ReLU())
print(model)
print(model[1])
'''
Sequential(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1))
(relu1): ReLU()
(conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(relu2): ReLU()
)
ReLU()
'''
注:model.add_module()函数输入的是集合,第一个是网络层名称,第二个是网络层。
补充torch.nn.Conv2d类的知识
上文中出现的nn.Conv2d类是二维卷积类,是最常用的卷积方式。和普通的类一样,它需要先实例化再使用。让我们构建一个只有一层二维卷积的神经网络,进而理解nn.Conv2d的使用。
import torch.nn as nn
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.conv2d = nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=2,padding=1)
def forward(self, x):
print(x.requires_grad)
x = self.conv2d(x)
return x
net = MyNet()
print(net.conv2d.weight) #查看初始权重
print(net.conv2d.bias) #查看初始偏置
pytorch手册中的torch.nn.Conv2d类如下所示,前三个参数是必须要提供的:
需要注意的是,torch.nn.Conv2d并不需要提供初始权重和偏置,这是因为在nn模块中,pytorch对于卷积层的权重和偏置(如果需要偏置)初始化都是采用He初始化的,当然也可以手动进行初始化(这里不展开讲)。虽然pytorch自动初始化的参数,但我们可以通过torch.nn.Conv2d.weight和torch.nn.Conv2d.bias来查看卷积层的初始值。让我们来看一下各参数的意义:
in_channels---输入的四维张量[N, C, H, W]中的C,即输入图像的通道数(N为batch_size)。
out_channels---输出图像的通道数。在数值上它也是卷积核的种类数。
kernel_size---卷积核的尺寸,一般是3x3, 5x5这种奇数核,当核为nxn方阵时,记作kernel_size=n。当核为nxm矩阵时,记作kernel_size=(n, m)。
stride---卷积核移动时的步长。
padding---边缘填充。
dilation---这个参数决定了是否采用空洞卷积,默认为1(不采用)。
groups---决定了是否采用分组卷积。
bias---即是否要添加偏置参数作为可学习参数的一个,默认为True。
padding_mode---padding的模式,默认采用零填充。
3.3. nn.Module类
以下内容来自:pytorch教程之nn.Module类详解——使用Module类来自定义模型_LoveMIss-Y的博客-CSDN博客
3.3.1. torch.nn.Module类简介
先来简单看一它的定义:
class Module(object):
def __init__(self):
def forward(self, *input):
def add_module(self, name, module):
def cuda(self, device=None):
def cpu(self):
def __call__(self, *input, **kwargs):
def parameters(self, recurse=True):
def named_parameters(self, prefix='', recurse=True):
def children(self):
def named_children(self):
def modules(self):
def named_modules(self, memo=None, prefix=''):
def train(self, mode=True):
def eval(self):
def zero_grad(self):
def __repr__(self):
def __dir__(self):
'''
有一部分没有完全列出来
'''
我们在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__init__构造函数和forward这两个方法。但有一些注意技巧:
(1)一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数__init__()中,当然也可以把不具有参数的层也放在里面;
(2)不具有可学习参数的层(如ReLU、dropout、BatchNormanation层)既可放在构造函数中,也可不放在构造函数中,如果不放在构造函数__init__里面,则在forward方法里面可以使用nn.functional来代替。
(3)forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。
下面先看一个简单的例子。
import torch
class MyNet(torch.nn.Module):
def __init__(self):
super(MyNet, self).__init__() # 第一句话,调用父类的构造函数
self.conv1 = torch.nn.Conv2d(3, 32, 3, 1, 1)
self.relu1=torch.nn.ReLU()
self.max_pooling1=torch.nn.MaxPool2d(2,1)
self.conv2 = torch.nn.Conv2d(3, 32, 3, 1, 1)
self.relu2=torch.nn.ReLU()
self.max_pooling2=torch.nn.MaxPool2d(2,1)
self.dense1 = torch.nn.Linear(32 * 3 * 3, 128)
self.dense2 = torch.nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.max_pooling1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.max_pooling2(x)
x = self.dense1(x)
x = self.dense2(x)
return x
model = MyNet()
print(model)
'''运行结果为:
MyNet(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU()
(max_pooling1): MaxPool2d(kernel_size=2, stride=1, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu2): ReLU()
(max_pooling2): MaxPool2d(kernel_size=2, stride=1, padding=0, dilation=1, ceil_mode=False)
(dense1): Linear(in_features=288, out_features=128, bias=True)
(dense2): Linear(in_features=128, out_features=10, bias=True)
)
'''
注意:上面的是将所有的层都放在了构造函数__init__里面,但是只是定义了一系列的层,各个层之间到底是什么连接关系并没有,而是在forward里面实现所有层的连接关系,当然这里依然是顺序连接的。下面再来看一下一个例子:
import torch
import torch.nn.functional as F
class MyNet(torch.nn.Module):
def __init__(self):
super(MyNet, self).__init__() # 第一句话,调用父类的构造函数
self.conv1 = torch.nn.Conv2d(3, 32, 3, 1, 1)
self.conv2 = torch.nn.Conv2d(3, 32, 3, 1, 1)
self.dense1 = torch.nn.Linear(32 * 3 * 3, 128)
self.dense2 = torch.nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x)
x = self.dense1(x)
x = self.dense2(x)
return x
model = MyNet()
print(model)
'''运行结果为:
MyNet(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv2): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(dense1): Linear(in_features=288, out_features=128, bias=True)
(dense2): Linear(in_features=128, out_features=10, bias=True)
)
'''
注意:此时,将没有训练参数的层没有放在构造函数里面了,所以这些层就不会出现在model里面,但是运行关系是在forward里面通过nn.functional的方法实现的(nn.Xxx和nn.functional.xxx的区别详见PyTorch 中,nn 与 nn.functional 有什么区别? - 知乎)。
总结:所有放在构造函数__init__里面的层的都是这个模型的“固有属性”。
3.3.2 torch.nn.Module类的多种实现
上面是为了一个简单的演示,但是Module类是非常灵活的,可以有很多灵活的实现方式,下面将一一介绍。
通过Sequential类来包装层
所谓的包装,就是将几个层包装在一起作为一个大的层(块),前面已经介绍了Sequential类的三种实现方式,这里取一种方式演示。
import torch.nn as nn
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(3, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2))
self.dense_block = nn.Sequential(
nn.Linear(32 * 3 * 3, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
# 在这里实现层之间的连接关系,其实就是所谓的前向传播
def forward(self, x):
conv_out = self.conv_block(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense_block(res)
return out
model = MyNet()
print(model)
'''运行结果为:
MyNet(
(conv_block): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(dense_block): Sequential(
(0): Linear(in_features=288, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=10, bias=True)
)
)
'''
几个常用Module类方法
Sequenrial类实现了整数索引,故而可以使用model[index] 这样的方式获取一个曾,但是Module类并没有实现整数索引,不能够通过整数索引来获得层,那该怎么办呢?它提供了几个主要的方法,如下:
def children(self):
def named_children(self):
def modules(self):
def named_modules(self, memo=None, prefix=''):
'''
注意:这几个方法返回的都是一个Iterator迭代器,故而通过for循环访问,当然也可以通过next
'''
- model.children()方法
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.conv_block=torch.nn.Sequential()
self.conv_block.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))
self.conv_block.add_module("relu1",torch.nn.ReLU())
self.conv_block.add_module("pool1",torch.nn.MaxPool2d(2))
self.dense_block = torch.nn.Sequential()
self.dense_block.add_module("dense1",torch.nn.Linear(32 * 3 * 3, 128))
self.dense_block.add_module("relu2",torch.nn.ReLU())
self.dense_block.add_module("dense2",torch.nn.Linear(128, 10))
def forward(self, x):
conv_out = self.conv_block(x)
res = conv_out.view(conv_out.size(0), -1)
out = self.dense_block(res)
return out
model = MyNet()
for i in model.children():
print(i)
print(type(i)) # 查看每一次迭代的元素到底是什么类型,实际上是 Sequential 类型,所以有可以使用下标index索引来获取每一个Sequenrial 里面的具体层
'''运行结果为:
Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
<class 'torch.nn.modules.container.Sequential'>
Sequential(
(dense1): Linear(in_features=288, out_features=128, bias=True)
(relu2): ReLU()
(dense2): Linear(in_features=128, out_features=10, bias=True)
)
<class 'torch.nn.modules.container.Sequential'>
'''
- model.named_children()方法
for i in model.named_children():
print(i)
print(type(i)) # 查看每一次迭代的元素到底是什么类型,实际上是 返回一个tuple,tuple 的第一个元素是
'''运行结果为:
('conv_block', Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
))
<class 'tuple'>
('dense_block', Sequential(
(dense1): Linear(in_features=288, out_features=128, bias=True)
(relu2): ReLU()
(dense2): Linear(in_features=128, out_features=10, bias=True)
))
<class 'tuple'>
'''
总结:
- model.children()和model.named_children()方法返回的是迭代器;
- model.children()每一次迭代返回的元素是Sequential类;
- model.named_children()每一次迭代返回的元素是元组类型,元组的第一个元素是名称,第二个元素就是对应的层或者是Sequential。
- model.modules()方法
for i in model.modules():
print(i)
print("==================================================")
'''运行结果为:
MyNet(
(conv_block): Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(dense_block): Sequential(
(dense1): Linear(in_features=288, out_features=128, bias=True)
(relu2): ReLU()
(dense2): Linear(in_features=128, out_features=10, bias=True)
)
)
==================================================
Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
==================================================
Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
==================================================
ReLU()
==================================================
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
==================================================
Sequential(
(dense1): Linear(in_features=288, out_features=128, bias=True)
(relu2): ReLU()
(dense2): Linear(in_features=128, out_features=10, bias=True)
)
==================================================
Linear(in_features=288, out_features=128, bias=True)
==================================================
ReLU()
==================================================
Linear(in_features=128, out_features=10, bias=True)
==================================================
'''
- model.named_modules()方法
for i in model.named_modules():
print(i)
print("==================================================")
'''运行结果是:
('', MyNet(
(conv_block): Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(dense_block): Sequential(
(dense1): Linear(in_features=288, out_features=128, bias=True)
(relu2): ReLU()
(dense2): Linear(in_features=128, out_features=10, bias=True)
)
))
==================================================
('conv_block', Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
))
==================================================
('conv_block.conv1', Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
==================================================
('conv_block.relu1', ReLU())
==================================================
('conv_block.pool1', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))
==================================================
('dense_block', Sequential(
(dense1): Linear(in_features=288, out_features=128, bias=True)
(relu2): ReLU()
(dense2): Linear(in_features=128, out_features=10, bias=True)
))
==================================================
('dense_block.dense1', Linear(in_features=288, out_features=128, bias=True))
==================================================
('dense_block.relu2', ReLU())
==================================================
('dense_block.dense2', Linear(in_features=128, out_features=10, bias=True))
==================================================
'''
总结:
model.modules()和model.named_modules()方法返回的是迭代器iterator;- model的modules()方法和named_modules()方法都会将整个模型的所有构成(包括包装层、单独的层、自定义层等)由浅入深依次遍历出来,只不过modules()返回的每一个元素是直接返回的层对象本身,而named_modules()返回的每一个元素是一个元组,第一个元素是名称,第二个元素才是层对象本身。
- 如何理解children和modules之间的这种差异性。注意pytorch里面不管是模型、层、激活函数、损失函数都可以当成是Module的拓展,所以modules和named_modules会层层迭代,由浅入深,将每一个自定义块block、然后block里面的每一个层都当成是module来迭代。而children就比较直观,就表示的是所谓的“孩子”,所以没有层层迭代深入。
3.4 创建一个CNN模型
import torch.nn as nn
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.conv1=nn.Sequential(nn.Conv2d(3, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv2=nn.Sequential(nn.Conv2d(32, 64, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv3=nn.Sequential(nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2))
self.dense=nn.Sequential(nn.Linear(64*3*3, 128),
nn.ReLU(),
nn.Linear(128, 10))
def forward(self, x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
res = conv3_out.view(conv3_out.size(0), -1)
return self.dense(res)
model=MyNet()
print(model)
'''
MyNet(
(conv1): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv3): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(dense): Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=10, bias=True)
)
)
'''
3.5. 参考内容
- pytorch教程之nn.Module类详解——使用Module类来自定义模型_LoveMIss-Y的博客-CSDN博客
- [PyTorch 学习笔记] 3.1 模型创建步骤与 nn.Module
- pytorch教程之nn.Sequential类详解——使用Sequential类来自定义顺序连接模型_LoveMIss-Y的博客-CSDN博客
- Pytorch的nn.Conv2d()详解_风雪夜归人o的博客-CSDN博客
4. 训练CNN模型
训练模型是为了得到合适的参数权重,设计模型的训练时,最重要的就是损失函数和优化器的选择。损失函数(Loss function)是用于衡量模型所作出的预测离真实值(Ground Truth)之间的偏离程度,损失函数值越小,模型的鲁棒性越好。当损失函数值过大时,我们就需要借助优化器(Optimizer)对模型参数进行更新,使预测值和真实值的偏离程度减小。
4.1. 损失函数
在机器学习中,损失函数(Loss function)是代价函数(Cost function)的一部分,而代价函数则是目标函数(Objective function)的一种类型。它们的定义如下,
损失函数(Loss function):用于定义单个训练样本与真实值之间的误差;
代价函数(Cost function):用于定义单个批次/整个训练集样本与真实值之间的误差;
目标函数(Objective function):泛指任意可以被优化的函数。
损失函数是用于衡量模型所作出的预测离真实值(Ground Truth)之间的偏离程度。 通常,我们都会最小化目标函数,最常用的算法便是“梯度下降法”(Gradient Descent)。俗话说,任何事情必然有它的两面性,因此,并没有一种万能的损失函数能够适用于所有的机器学习任务,所以在这里我们需要知道每一种损失函数的优点和局限性,才能更好的利用它们去解决实际的问题。损失函数大致可分为两种:回归损失(针对连续型变量)和分类损失(针对离散型变量)。
有关回归损失函数与分类损失函数的详细内容,见一文看尽深度学习中的各种损失函数。图像分类用的最多的是分类损失函数中的交叉熵损失函数。图像分类可分为二分类和多分类,在pytorch中也有相对应的损失函数类,分别是torch.nn.BCELoss()和torch.nn.CrossEntropyLoss() 。
4.1.1. torch.nn.BCELoss()
公式
BCELoss()是计算目标值和预测值之间的二进制交叉熵损失函数。其公式如下:
ln=−wn⋅[yn⋅logxn+(1−yn)⋅log(1−xn)]
其中,wn表示权重矩阵,xn表示预测值矩阵(输入矩阵被激活函数处理后的结果),yn表示目标值矩阵。
pytorch实现
语法:Class torch.nn.BCELoss(weight: Union[torch.Tensor, NoneType] = None, size_average=None, reduce=None, reduction: str = 'mean')
参数:
最常用的参数为 reduction(str, optional) ,可设置其值为 mean, sum, none ,默认为 mean。该参数主要影响多个样本输入时,损失的综合方法。mean表示损失为多个样本的平均值,sum表示损失的和,none表示不综合。其他参数读者可查阅官方文档。
注意:类别是one-hot二维向量形式,不能是index形式,这是因为loss_func=nn.BCELoss()\nloss_func(pre, tgt),pre、tgt必须具有相同的形状。
loss_func_mean = nn.BCELoss(reduction="mean")
loss_func_sum = nn.BCELoss(reduction="sum")
loss_func_none = nn.BCELoss(reduction="none")
pre = torch.tensor([[0.8, 0.2],
[0.9, 0.1],
[0.1, 0.9],
[0.3, 0.7]], dtype=torch.float)
tgt_onehot_data = torch.tensor([[1, 0], [1, 0], [0, 1], [0, 1]], dtype=torch.float)
print(loss_func_mean(pre, tgt_onehot_data))
print(loss_func_sum(pre, tgt_onehot_data))
print(loss_func_none(pre, tgt_onehot_data))
'''
tensor(0.1976)
tensor(1.5811)
tensor([[0.2231, 0.2231],
[0.1054, 0.1054],
[0.1054, 0.1054],
[0.3567, 0.3567]])
'''
4.1.2. torch.nn.CrossEntropyLoss()
torch.nn.CrossEntropyLoss() 参数、计算过程以及及输入Tensor形状,这篇文章介绍的足够详实,以下内容摘自此文章。
交叉熵损失函数一般用于多分类问题。现有C分类问题,(x, y)是训练集中的一个样本,其中x是样本的属性,y∈[0, 1]C为样本类别标签。将x输入模型,得到样本的类别预测值y~∈[0, 1]C,采用交叉熵损失计算类别预测值y~和真实值 y 之间的距离:
Quick Start
简单定义两个Tensor,其中pre为模型的预测值,tgt为类别真实标签,采用one-hot形式表示。
import torch.nn as nn
loss_func = nn.CrossEntropyLoss()
pre = torch.tensor([0.8, 0.5, 0.2, 0.5], dtype=torch.float)
tgt = torch.tensor([1, 0, 0, 0], dtype=torch.float)
print(loss_func(pre, tgt))
'''
tensor(1.1087)
'''
语法和参数
语法:torch.nn.CrossEntropyLoss(weight: Union[torch.Tensor, NoneType] = None, size_average=None, ignore_index: int = -100, reduce=None, reduction: str = 'mean', label_smoothing: float = 0.0)
参数:
最常用的参数为 reduction(str, optional) ,可设置其值为 mean, sum, none ,默认为 mean。该参数主要影响多个样本输入时,损失的综合方法。mean表示损失为多个样本的平均值,sum表示损失的和,none表示不综合。其他参数读者可查阅官方文档。
loss_func_none = nn.CrossEntropyLoss(reduction="none")
loss_func_mean = nn.CrossEntropyLoss(reduction="mean")
loss_func_sum = nn.CrossEntropyLoss(reduction="sum")
pre = torch.tensor([[0.8, 0.5, 0.2, 0.5],
[0.2, 0.9, 0.3, 0.2],
[0.4, 0.3, 0.7, 0.1],
[0.1, 0.2, 0.4, 0.8]], dtype=torch.float)
tgt = torch.tensor([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]], dtype=torch.float)
print(loss_func_none(pre, tgt))
print(loss_func_mean(pre, tgt))
print(loss_func_sum(pre, tgt))
'''
tensor([1.1087, 0.9329, 1.0852, 0.9991])
tensor(1.0315)
tensor(4.1259)
'''
loss_func = nn.CrossEntropyLoss()
pre = torch.tensor([0.8, 0.5, 0.2, 0.5], dtype=torch.float)
tgt = torch.tensor([1, 0, 0, 0], dtype=torch.float)
print("手动计算:")
print("1.softmax")
print(torch.softmax(pre, dim=-1))
print("2.取对数")
print(torch.log(torch.softmax(pre, dim=-1)))
print("3.与真实值相乘")
print(-torch.sum(torch.mul(torch.log(torch.softmax(pre, dim=-1)), tgt), dim=-1))
print()
print("调用损失函数:")
print(loss_func(pre, tgt))
'''
手动计算:
1.softmax
tensor([0.3300, 0.2445, 0.1811, 0.2445])
2.取对数
tensor([-1.1087, -1.4087, -1.7087, -1.4087])
3.与真实值相乘
tensor(1.1087)
调用损失函数:
tensor(1.1087)
'''
由此可见:
①交叉熵损失函数会自动对输入模型的预测值进行softmax。因此在多分类问题中,如果使用nn.CrossEntropyLoss(),则预测模型的输出层无需添加softmax层。
②nn.CrossEntropyLoss()=nn.LogSoftmax()+nn.NLLLoss()。
损失函数输入及输出的Tensor形状
为了直观显示函数输出结果,我们将参数reduction设置为none。此外pre表示模型的预测值,为4*4的Tensor,其中的每行表示某个样本的类别预测(4个类别);tgt表示样本类别的真实值,有两种表示形式,一种是类别的index,另一种是one-hot形式。
loss_func = nn.CrossEntropyLoss(reduction="none")
pre_data = torch.tensor([[0.8, 0.5, 0.2, 0.5],
[0.2, 0.9, 0.3, 0.2],
[0.4, 0.3, 0.7, 0.1],
[0.1, 0.2, 0.4, 0.8]], dtype=torch.float)
tgt_index_data = torch.tensor([0,
1,
2,
3], dtype=torch.long)
tgt_onehot_data = torch.tensor([[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]], dtype=torch.float)
print("pre_data: {}".format(pre_data.size()))
print("tgt_index_data: {}".format(tgt_index_data.size()))
print("tgt_onehot_data: {}".format(tgt_onehot_data.size()))
'''
pre_data: torch.Size([4, 4])
tgt_index_data: torch.Size([4])
tgt_onehot_data: torch.Size([4, 4])
'''
- 简单情况(一个样本)
pre = pre_data[0]
tgt_index = tgt_index_data[0]
tgt_onehot = tgt_onehot_data[0]
print(pre)
print(tgt_index)
print(tgt_onehot)
'''
tensor([0.8000, 0.5000, 0.2000, 0.5000])
tensor(0)
tensor([1., 0., 0., 0.])
'''
pre形状为Tensor(C);两种tgt的形状分别为Tensor(), Tensor(C) 。此时①手动计算损失②损失函数+tgt_index形式③损失函数+tgt_onehot形式:
print(-torch.sum(torch.mul(torch.log(torch.softmax(pre, dim=-1)), tgt_onehot), dim=-1))
print(loss_func(pre, tgt_index))
print(loss_func(pre, tgt_onehot))
'''
tensor(1.1087)
tensor(1.1087)
tensor(1.1087)
'''
可见torch.nn.CrossEntropyLoss()接受两种形式的标签输入,一种是类别index,一种是one-hot形式。
- 一个batch(多个样本)
pre = pre_data[0:2]
tgt_index = tgt_index_data[0:2]
tgt_onehot = tgt_onehot_data[0:2]
print(pre)
print(tgt_index)
print(tgt_onehot)
'''
tensor([[0.8000, 0.5000, 0.2000, 0.5000],
[0.2000, 0.9000, 0.3000, 0.2000]])
tensor([0, 1])
tensor([[1., 0., 0., 0.],
[0., 1., 0., 0.]])
'''
pre形状为Tensor(N, C);两种tgt的形状分别为Tensor(N), Tensor(N, C) 。此时①手动计算损失②损失函数+tgt_index形式③损失函数+tgt_onehot形式:
print(-torch.sum(torch.mul(torch.log(torch.softmax(pre, dim=-1)), tgt_onehot), dim=-1))
print(loss_func(pre, tgt_index))
print(loss_func(pre, tgt_onehot))
'''
tensor([1.1087, 0.9329])
tensor([1.1087, 0.9329])
tensor([1.1087, 0.9329])
'''
4.2. 优化器
优化器主要是在模型训练阶段对模型可学习参数进行更新, 所有的优化器都是继承Optimizer类,常用优化器有 SGD,RMSprop,Adam等。基本用法如下:
- 优化器初始化时传入传入模型的可学习参数,以及其他超参数如
lr,momentum等; - 在训练过程中先调用
optimizer.zero_grad()清空梯度,再调用loss.backward()反向传播,最后调用optimizer.step()更新模型参数。
4.2.1. Optimizer的基本属性和基本方法
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
...
param_groups = [{'params': param_groups}]
- defaults:优化器超参数;
- state:参数的缓存,如momentum的缓存;
- params_groups:管理的参数组;
- _step_count:记录更新次数,学习率调整中使用。
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
...
param_groups = [{'params': param_groups}]
def zero_grad(self):
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
p.grad.detach_()
# 清零
p.grad.zero_()
def add_param_group(self, param_group):
for group in self.param_groups:
param_set.update(set(group['params’]))
...
def state_dict(self):
...
return {
'state': packed_state,
'param_groups': param_groups, }
def load_state_dict(self, state_dict):
...
- zero_grad():在反向传播计算梯度之前对上一次迭代时记录的梯度清零(pytorch特性:张量梯度不自动清零,会将张量梯度累加;因此,需要在使用完梯度之后,或者在反向传播前,将梯度自动清零);
- step():此方法主要完成一次模型参数的更新;
- add_param_group():添加参数组,例如:可以为特征提取层与全连接层设置不同的学习率或者别的超参数;
- state_dict():获取优化器当前状态信息字典;长时间的训练,会隔一段时间保存当前的状态信息,用来在断点的时候恢复训练,避免由于意外的原因导致模型的终止;
- load_state_dict() :加载状态信息字典。
有关Optimizer更详细的内容,见PyTorch 源码解读之 torch.optim:优化算法接口详解。
4.2.2. 常用优化器:SGD,RMSprop,Adam
以下内容摘自Pytorch优化器全总结(一)SGD、ASGD、Rprop、Adagrad_pytorch sgd优化器_小殊小殊的博客-CSDN博客系列。
1. SGD优化器
'''
params(iterable)- 参数组,优化器要优化的那部分参数。
lr(float)- 初始学习率,可按需随着训练过程不断调整学习率。
momentum(float)- 动量,通常设置为 0.9,0.8
dampening(float)- dampening for momentum ,暂时不了解其功能,在源码中是这样用的:buf.mul_(momentum).add_(1 - dampening, d_p),值得注意的是,若采用nesterov,dampening 必须为 0.
weight_decay(float)- 权值衰减系数,也就是 L2 正则项的系数
nesterov(bool)- bool 选项,是否使用 NAG(Nesterov accelerated gradient)
'''
class torch.optim.SGD(params, lr=<object object>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
SGD算法解析
- MBGD(Mini-batch Gradient Descent)小批量梯度下降法
明明类名是SGD,为什么介绍MBGD呢,因为在Pytorch中,torch.optim.SGD其实是实现的MBGD,要想使用SGD,只要将batch_size设成1就行了。
MBGD就是结合BGD和SGD的折中,对于含有 n个训练样本的数据集,每次参数更新,选择一个大小为 m(m<n) 的mini-batch数据样本计算其梯度,其参数更新公式如下,其中j是一个batch的开始: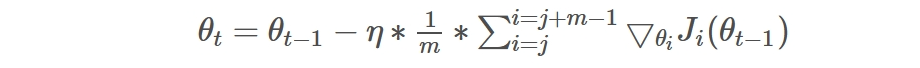
优点:使用mini-batch的时候,可以收敛得很快,有一定摆脱局部最优的能力。
缺点:a.在随机选择梯度的同时会引入噪声,使得权值更新的方向不一定正确
b.不能解决局部最优解的问题
- Momentum动量
动量是一种有助于在相关方向上加速SGD并抑制振荡的方法,通过将当前梯度与过去梯度加权平均,来获取即将更新的梯度。如下图b图所示。它通过将过去时间步长的更新向量的一小部分添加到当前更新向量来实现这一点: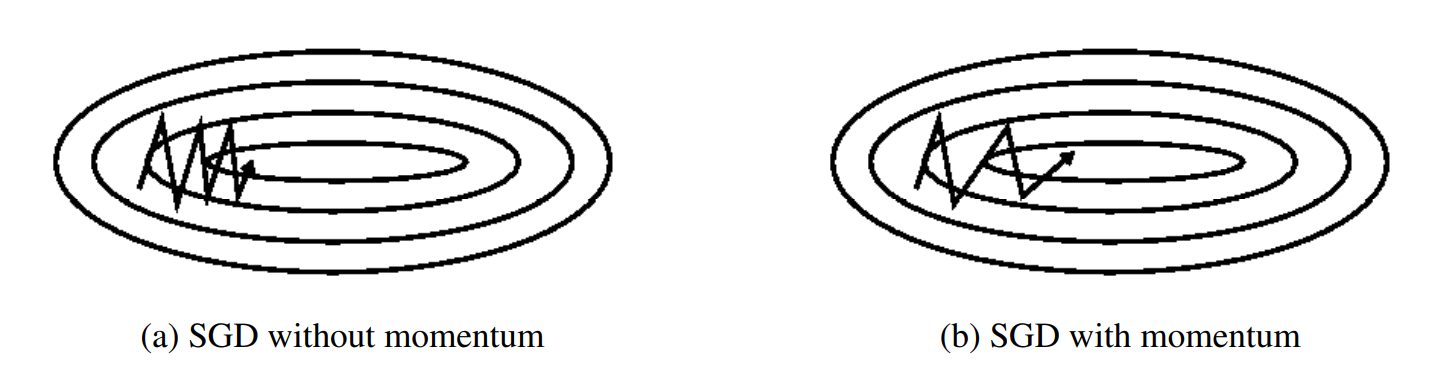
动量项通常设置为0.9或类似值。
- NAG(Nesterov accelerated gradient)
NAG的思想是在动量法的基础上展开的。动量法是思想是,将当前梯度与过去梯度加权平均,来获取即将更新的梯度。在知道梯度之后,更新自变量到新的位置。也就是说我们其实在每一步,是知道下一时刻位置的。这时Nesterov就说了:那既然这样的话,我们何不直接采用下一时刻的梯度来和上一时刻梯度进行加权平均呢?下面两张图看明白,就理解NAG了:

SGD总结
使用了Momentum或NAG的MBGD有如下特点:
优点:加快收敛速度,有一定摆脱局部最优的能力,一定程度上缓解了没有动量的时候的问题
缺点:a.仍然继承了一部分SGD的缺点
b.在随机梯度情况下,NAG对收敛率的作用不是很大
c.Momentum和NAG都是为了使梯度更新更灵活。但是人工设计的学习率总是有些生硬,下面介绍几种自适应学习率的方法。
推荐程度:带Momentum的torch.optim.SGD 可以一试。
2. RMSprop优化器
'''
params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
lr (float, 可选) – 学习率(默认:1e-2)
momentum (float, 可选) – 动量因子(默认:0),该参数的作用下面会说明。
alpha (float, 可选) – 平滑常数(默认:0.99)
eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
centered (bool, 可选) – 如果为True,计算中心化的RMSProp,并且用它的方差预测值对梯度进行归一化
'''
class torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
RMSprop总结
RMSprop算是Adagrad的一种发展,用梯度平方的指数加权平均代替了全部梯度的平方和,相当于只实现了Adadelta的第一个修改,效果趋于RMSprop和Adadelta二者之间。
优点:适合处理非平稳目标(包括季节性和周期性)——对于RNN效果很好
缺点:RMSprop依然依赖于全局学习率
推荐程度:推荐!
3. Adam优化器
'''
params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
lr (float, 可选) – 学习率(默认:1e-3)
betas (Tuple[float,float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)
eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0)
'''
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
Adam总结
在adam中,一阶矩来控制模型更新的方向,二阶矩控制步长(学习率)。利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
优点:
1、结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点
2、更新步长和梯度大小无关,只和alpha、beta_1、beta_2有关系。并且由它们决定步长的理论上限
3、更新的步长能够被限制在大致的范围内(初始学习率)
4、能较好的处理噪音样本,能天然地实现步长退火过程(自动调整学习率)
推荐程度:非常推荐
4.3. Accuracy和Loss的计算
4.3.1 Accuracy的计算
Accuracy指的是正确率,计算方式:acc = 正确样本个数 /样本总数,以上内容想必大家都知道,下面让我们看一下在pytorch中是如何计算的吧。
模型(多分类)的输出结果是经过归一化指数函数——softmax函数(二分类是sigmoid函数)变换,将多分类结果以概率形式展现出来。因此我们需要将概率形式的分类结果转换为index,再根据分类形式(例如one-hot形式)做相应操作。torch.max()与torch.argmax()可以求最大概率的index。
out = torch.tensor([[0.03,0.12,0.85], [0.01,0.9,0.09], [0.95,0.01,0.04], [0.09, 0.9, 0.01]])
print(torch.max(out.data, 1))
print()
print(torch.max(out.data, 1)[1])
'''
torch.return_types.max(
values=tensor([0.8500, 0.9000, 0.9500, 0.9000]),
indices=tensor([2, 1, 0, 1]))
tensor([2, 1, 0, 1])
'''
print(torch.argmax(out, 1))
'''
tensor([2, 1, 0, 1])
'''
这里,我们假设tgt=torch.tensor([2, 1, 1, 1]),则:
pre = torch.max(out.data, 1)[1]
tgt=torch.tensor([2, 1, 1, 1])
acc_num = (pre==tgt).sum().item()
Acc = acc_num/len(out)
print(Acc)
# 0.75
4.3.2. Loss的计算
Loss的计算与选用的损失函数息息相关,这里我们以loss_func=torch.nn.CrossEntropyLoss()损失函数为例。参数reduction有三个可选值,因此有三种不同计算方式。
loss_func_mean = torch.nn.CrossEntropyLoss(reduction="mean")
loss_func_sum = torch.nn.CrossEntropyLoss(reduction="sum")
loss_func_none = torch.nn.CrossEntropyLoss(reduction="none")
out = torch.tensor([[0.03,0.12,0.85], [0.01,0.9,0.09], [0.95,0.01,0.04], [0.09, 0.9, 0.01]])
tgt = torch.tensor([2, 1, 1, 1])
loss1 = loss_func_mean(out, tgt)
loss2 = loss_func_sum(out, tgt)
loss3 = loss_func_none(out, tgt)
Loss1 = loss1
Loss2 = loss2.item()/len(out)
Loss3 = sum(loss3.tolist())/len(out)
print(f"{Loss1:.6f}")
print(f"{Loss2:.6f}")
print(f"{Loss3:.6f}")
'''
0.853460
0.853460
0.853460
'''
4.4. 训练一个模型
from torch.autograd import Variable
optimizer = torch.optim.Adam(model.parameters(), lr=0.0005)
loss_func = nn.CrossEntropyLoss()
for epoch in range(10):
print("-"*60)
print(f"第{epoch+1}次训练与验证:")
start=time.perf_counter()
# 训练
model.train()
train_loss, train_acc = 0, 0
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
out = model(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.item()*batch_x.size(0)
pred = torch.max(out.data, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.item()
loss.backward()
optimizer.step()
print(f"train loss: {train_loss/len(train_data) : .6f}, train acc: {train_acc/len(train_data) : .6f}")
# 验证
with torch.no_grad():
model.eval()
val_loss, val_acc = 0, 0
for batch_x, batch_y in eval_loader:
out = model(batch_x)
loss = loss_func(out, batch_y)
val_loss += loss.item()*batch_x.size(0)
pred = torch.max(out.data, 1)[1]
val_correct = (pred == batch_y).sum()
val_acc += val_correct.item()
print(f"val_loss: {val_loss/len(eval_data) : .6f}, val_acc: {val_acc/len(eval_data) : .6f}")
print(f"第{epoch+1}次训练与验证用时{time.perf_counter()-start:.6f}")
4.5. 参考内容
- 一文看尽深度学习中的各种损失函数
- 【pytorch函数笔记(三)】torch.nn.BCELoss()_榴莲味的电池的博客-CSDN博客
- torch.nn.CrossEntropyLoss() 参数、计算过程以及及输入Tensor形状
- PyTorch学习—13.优化器optimizer的概念及常用优化器_optimizer作用_哎呦-_-不错的博客-CSDN博客
- Pytorch优化器全总结(二)Adadelta、RMSprop、Adam、Adamax、AdamW、NAdam、SparseAdam(重置版)_adam pytorch_小殊小殊的博客-CSDN博客
- pytorch accuracy和Loss 的计算_也问吾心的博客-CSDN博客
5. 保存加载自定义模型
本章节转载自:PyTorch | 保存和加载模型
5.1. 简介
本文主要介绍如何加载和保存 PyTorch 的模型。这里主要有三个核心函数:
- torch.save :把序列化的对象保存到硬盘。它利用了 Python 的 pickle 来实现序列化。模型、张量以及字典都可以用该函数进行保存;
- torch.load:采用 pickle 将反序列化的对象从存储中加载进来。
- torch.nn.Module.load_state_dict:采用一个反序列化的 state_dict加载一个模型的参数字典。
本文主要内容如下:
- 什么是状态字典(state_dict)?
- 预测时加载和保存模型
- 加载和保存一个通用的检查点(Checkpoint)
- 在同一个文件保存多个模型
- 采用另一个模型的参数来预热模型(Warmstaring Model)
- 不同设备下保存和加载模型
5.2. 什么是状态字典(state_dict)
PyTorch 中,一个模型(torch.nn.Module)的可学习参数(也就是权重和偏置值)是包含在模型参数(model.parameters())中的,一个状态字典就是一个简单的 Python 的字典,其键值对是每个网络层和其对应的参数张量。模型的状态字典只包含带有可学习参数的网络层(比如卷积层、全连接层等)和注册的缓存(batchnorm的 running_mean)。优化器对象(torch.optim)同样也是有一个状态字典,包含的优化器状态的信息以及使用的超参数。
由于状态字典也是 Python 的字典,因此对 PyTorch 模型和优化器的保存、更新、替换、恢复等操作都很容易实现。
下面是一个简单的使用例子,例子来自:Training a Classifier — PyTorch Tutorials 2.0.1+cu117 documentation
# Define model
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Initialize model
model = TheModelClass()
# Initialize optimizer
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Print model's state_dict
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# Print optimizer's state_dict
print("Optimizer's state_dict:")
for var_name in optimizer.state_dict():
print(var_name, "\t", optimizer.state_dict()[var_name])
上述代码先是简单定义一个 5 层的 CNN,然后分别打印模型的参数和优化器参数。
输出结果:
Model's state_dict:
conv1.weight torch.Size([6, 3, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([16, 6, 5, 5])
conv2.bias torch.Size([16])
fc1.weight torch.Size([120, 400])
fc1.bias torch.Size([120])
fc2.weight torch.Size([84, 120])
fc2.bias torch.Size([84])
fc3.weight torch.Size([10, 84])
fc3.bias torch.Size([10])
Optimizer's state_dict:
state {}
param_groups [{'lr': 0.001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'params': [4675713712, 4675713784, 4675714000, 4675714072, 4675714216, 4675714288, 4675714432, 4675714504, 4675714648, 4675714720]}]
5.3. 预测时加载和保存模型
5.3.1. 加载/保存状态字典(推荐做法)
保存的代码:
torch.save(model.state_dict(), PATH)
加载的代码:
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
当需要为预测保存一个模型的时候,只需要保存训练模型的可学习参数即可。采用 torch.save() 来保存模型的状态字典的做法可以更方便加载模型,这也是推荐这种做法的原因。
通常会用 .pt 或者 .pth 后缀来保存模型。
记住
- 在进行预测之前,必须调用 model.eval() 方法来将 dropout 和 batch normalization 层设置为验证模型。否则,只会生成前后不一致的预测结果。
- load_state_dict() 方法必须传入一个字典对象,而不是对象的保存路径,也就是说必须先反序列化字典对象,然后再调用该方法,也是例子中先采用 torch.load() ,而不是直接 model.load_state_dict(PATH)
5.3.2. 加载/保存整个模型
保存:
torch.save(model, PATH)
加载:
# Model class must be defined somewhere
model = torch.load(PATH)
model.eval()
保存和加载模型都是采用非常直观的语法并且都只需要几行代码即可实现。这种实现保存模型的做法将是采用 Python 的 pickle 模块来保存整个模型,这种做法的缺点就是序列化后的数据是属于特定的类和指定的字典结构,原因就是 pickle 并没有保存模型类别,而是保存一个包含该类的文件路径,因此,当在其他项目或者在 refactors 后采用都可能出现错误。
5.4. 加载和保存一个通用的检查点(Checkpoint)
保存的示例代码:
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
...
}, PATH)
加载的示例代码:
model = TheModelClass(*args, **kwargs)
optimizer = TheOptimizerClass(*args, **kwargs)
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
model.eval()
# - or -
model.train()
当保存一个通用的检查点(checkpoint)时,无论是用于继续训练还是预测,都需要保存更多的信息,不仅仅是 state_dict ,比如说优化器的 state_dict 也是非常重要的,它包含了用于模型训练时需要更新的参数和缓存信息,还可以保存的信息包括 epoch,即中断训练的批次,最后一次的训练 loss,额外的 torch.nn.Embedding 层等等。
上述保存代码就是介绍了如何保存这么多种信息,通过用一个字典来进行组织,然后继续调用 torch.save 方法,一般保存的文件后缀名是 .tar 。
加载代码也如上述代码所示,首先需要初始化模型和优化器,然后加载模型时分别调用 torch.load 加载对应的 state_dict 。然后通过不同的键来获取对应的数值。
加载完后,根据后续步骤,调用 model.eval() 用于预测,model.train() 用于恢复训练。
5.5. 在同一个文件保存多个模型
保存模型的示例代码:
torch.save({
'modelA_state_dict': modelA.state_dict(),
'modelB_state_dict': modelB.state_dict(),
'optimizerA_state_dict': optimizerA.state_dict(),
'optimizerB_state_dict': optimizerB.state_dict(),
...
}, PATH)
加载模型的示例代码:
modelA = TheModelAClass(*args, **kwargs)
modelB = TheModelBClass(*args, **kwargs)
optimizerA = TheOptimizerAClass(*args, **kwargs)
optimizerB = TheOptimizerBClass(*args, **kwargs)
checkpoint = torch.load(PATH)
modelA.load_state_dict(checkpoint['modelA_state_dict'])
modelB.load_state_dict(checkpoint['modelB_state_dict'])
optimizerA.load_state_dict(checkpoint['optimizerA_state_dict'])
optimizerB.load_state_dict(checkpoint['optimizerB_state_dict'])
modelA.eval()
modelB.eval()
# - or -
modelA.train()
modelB.train()
当我们希望保存的是一个包含多个网络模型 torch.nn.Modules 的时候,比如 GAN、一个序列化模型,或者多个模型融合,实现的方法其实和保存一个通用的检查点的做法是一样的,同样采用一个字典来保持模型的 state_dict 和对应优化器的 state_dict 。除此之外,还可以继续保存其他相同的信息。
加载模型的示例代码如上述所示,和加载一个通用的检查点也是一样的,同样需要先初始化对应的模型和优化器。同样,保存的模型文件通常是以 .tar 作为后缀名。
5.6 采用另一个模型的参数来预热模型(Warmstaring Model)
保存模型的示例代码:
torch.save(modelA.state_dict(), PATH)
加载模型的示例代码:
modelB = TheModelBClass(*args, **kwargs)
modelB.load_state_dict(torch.load(PATH), strict=False)
在之前迁移学习教程中也介绍了可以通过预训练模型来微调,加快模型训练速度和提高模型的精度。
这种做法通常是加载预训练模型的部分网络参数作为模型的初始化参数,然后可以加快模型的收敛速度。
加载预训练模型的代码如上述所示,其中设置参数 strict=False 表示忽略不匹配的网络层参数,因为通常我们都不会完全采用和预训练模型完全一样的网络,通常输出层的参数就会不一样。
当然,如果希望加载参数名不一样的参数,可以通过修改加载的模型对应的参数名字,这样参数名字匹配了就可以成功加载。
5.7. 不同设备下保存和加载模型
5.7.1. 在GPU上保存模型,在 CPU 上加载模型
保存模型的示例代码:
torch.save(model.state_dict(), PATH)
加载模型的示例代码:
device = torch.device('cpu')
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location=device))
在 CPU 上加载在 GPU 上训练的模型,必须在调用 torch.load() 的时候,设置参数 map_location ,指定采用的设备是 torch.device('cpu'),这个做法会将张量都重新映射到 CPU 上。
5.7.2. 在GPU上保存模型,在 GPU 上加载模型
保存模型的示例代码:
torch.save(model.state_dict(), PATH)
加载模型的示例代码:
device = torch.device('cuda')
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH)
model.to(device)
# Make sure to call input = input.to(device) on any input tensors that you feed to the model
在 GPU 上训练和加载模型,调用 torch.load() 加载模型后,还需要采用 model.to(torch.device('cuda')),将模型调用到 GPU 上,并且后续输入的张量都需要确保是在 GPU 上使用的,即也需要采用 my_tensor.to(device)。
5.7.3. 在CPU上保存,在GPU上加载模型
保存模型的示例代码:
torch.save(model.state_dict(), PATH)
加载模型的示例代码:
device = torch.device("cuda")
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH, map_location="cuda:0")) # Choose whatever GPU device number you want
model.to(device)
# Make sure to call input = input.to(device) on any input tensors that you feed to the model
这次是 CPU 上训练模型,但在 GPU 上加载模型使用,那么就需要通过参数 map_location 指定设备。然后继续记得调用 model.to(torch.device('cuda'))。
5.7.4. 保存 torch.nn.DataParallel 模型
保存模型的示例代码:
torch.save(model.module.state_dict(), PATH)
torch.nn.DataParallel 是用于实现多 GPU 并行的操作,保存模型的时候,是采用 model.module.state_dict()。
加载模型的代码也是一样的,采用 torch.load() ,并可以放到指定的 GPU 显卡上。
6. 完整代码
import torch
import torch.nn as nn
import cv2
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from torch.autograd import Variable
import time
class MyDataset(Dataset):
def __init__(self, txt, transform = None):
with open(txt, 'r') as ft:
imgs = []
for line in ft:
line = line.strip('\n')
words = line.split('---')
imgs.append((words[0], int(words[1])))
self.imgs = imgs
self.transform = transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = cv2.imread(fn, cv2.IMREAD_COLOR)
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
torch.manual_seed(0)
root = "D:\\Users\\CV learning\\pytorch\\FashionMNIST\\raw\\"
transformer = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.286, 0.286, 0.286], [0.319, 0.319, 0.319])])
train_data = MyDataset(root+'train.txt', transform=transformer)
transformer = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.287, 0.287, 0.287], [0.319, 0.319, 0.319])])
eval_data= MyDataset(root+'test.txt', transform=transformer)
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0)
eval_loader = DataLoader(dataset=eval_data, batch_size=64, num_workers=0)
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.conv1=nn.Sequential(nn.Conv2d(3, 32, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv2=nn.Sequential(nn.Conv2d(32, 64, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv3=nn.Sequential(nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2))
self.dense=nn.Sequential(nn.Linear(64*3*3, 128),
nn.ReLU(),
nn.Linear(128, 10))
def forward(self, x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
res = conv3_out.view(conv3_out.size(0), -1)
return self.dense(res)
model=MyNet()
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=0.0005)
loss_func = nn.CrossEntropyLoss()
for epoch in range(10):
print("-"*60)
print(f"第{epoch+1}次训练与验证:")
start=time.perf_counter()
# 训练
model.train()
train_loss, train_acc = 0, 0
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
out = model(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.item()*batch_x.size(0)
pred = torch.max(out.data, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.item()
loss.backward()
optimizer.step()
print(f"train loss: {train_loss/len(train_data) : .6f}, train acc: {train_acc/len(train_data) : .6f}")
# 验证
with torch.no_grad():
model.eval()
val_loss, val_acc = 0, 0
for batch_x, batch_y in eval_loader:
out = model(batch_x)
loss = loss_func(out, batch_y)
val_loss += loss.item()*batch_x.size(0)
pred = torch.max(out.data, 1)[1]
val_correct = (pred == batch_y).sum()
val_acc += val_correct.item()
print(f"val_loss: {val_loss/len(eval_data) : .6f}, val_acc: {val_acc/len(eval_data) : .6f}")
print(f"第{epoch+1}次训练与验证用时{time.perf_counter()-start:.6f}")
'''
MyNet(
(conv1): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv3): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(dense): Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=10, bias=True)
)
)
------------------------------------------------------------
第1次训练与验证:
train loss: 0.511146, train acc: 0.816233
val_loss: 0.365574, val_acc: 0.866200
第1次训练与验证用时61.706758
------------------------------------------------------------
第2次训练与验证:
train loss: 0.313273, train acc: 0.886467
val_loss: 0.314742, val_acc: 0.887500
第2次训练与验证用时59.915729
------------------------------------------------------------
第3次训练与验证:
train loss: 0.266815, train acc: 0.902950
val_loss: 0.272385, val_acc: 0.897700
第3次训练与验证用时60.355403
------------------------------------------------------------
第4次训练与验证:
train loss: 0.237419, train acc: 0.913283
val_loss: 0.251820, val_acc: 0.908100
第4次训练与验证用时60.558280
------------------------------------------------------------
第5次训练与验证:
train loss: 0.212313, train acc: 0.922783
val_loss: 0.251697, val_acc: 0.908200
第5次训练与验证用时61.204346
------------------------------------------------------------
第6次训练与验证:
train loss: 0.194762, train acc: 0.928167
val_loss: 0.233501, val_acc: 0.916000
第6次训练与验证用时60.957354
------------------------------------------------------------
第7次训练与验证:
train loss: 0.177436, train acc: 0.935350
val_loss: 0.235065, val_acc: 0.915900
第7次训练与验证用时61.345187
------------------------------------------------------------
第8次训练与验证:
train loss: 0.162173, train acc: 0.940500
val_loss: 0.241811, val_acc: 0.915100
第8次训练与验证用时58.322480
------------------------------------------------------------
第9次训练与验证:
train loss: 0.149520, train acc: 0.945283
val_loss: 0.257016, val_acc: 0.909900
第9次训练与验证用时57.995899
------------------------------------------------------------
第10次训练与验证:
train loss: 0.136408, train acc: 0.949550
val_loss: 0.248721, val_acc: 0.911800
第10次训练与验证用时57.863073
'''
# 加载/保存状态字典
# 保存
torch.save(model.state_dict(), "D:\\Users\\CV learning\\pytorch\\FashionMNIST\\model_save_1\\model_state_dict.pt")
# 加载状态字典
model_test=MyNet()
model_test.load_state_dict(torch.load("D:\\Users\\CV learning\\pytorch\\FashionMNIST\\model_save_1\\model_state_dict.pt"))
model_test.eval()
# 测试图像
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
transformer = transforms.ToTensor()
root = "D:\\Users\\CV learning\\pytorch\\FashionMNIST\\test"
dataset = ImageFolder(root, transformer)
data_loader = DataLoader(dataset=dataset, batch_size=5)
counter = 0
for batch in data_loader:
counter += 1
imgs = batch[0]
pre = model_test(imgs)
labels = torch.max(pre.data, 1)[1].tolist()
print(imgs.shape)
print(labels)
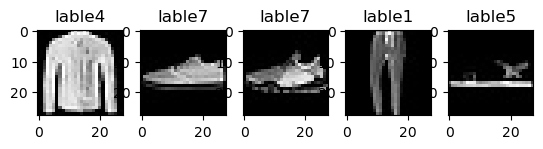
for i in range(imgs.size(0)):
img = transforms.ToPILImage()(imgs[i])
lable = labels[i]
plt.subplot(counter, 5, i+1), plt.imshow(img), plt.title(f"lable{lable}")
plt.show()
'''
torch.Size([5, 3, 28, 28])
[9, 4, 2, 8, 6]
torch.Size([5, 3, 28, 28])
[4, 7, 7, 1, 5]
'''
输出图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号