SQL Server中通过设置非聚集索引(Non-Clustered index)来达到性能优化的目的
首先我们一下,在SQL Server 2014 Management Studio中,如何为一张表设置Non-Clustered index
具体可以参考 https://docs.microsoft.com/en-us/sql/relational-databases/indexes/create-unique-indexes
在SQL Server Management Studio中,点击表,右键选择"Design". 然后在菜单栏中选择"Table Designer" => "Indexes/Keys"
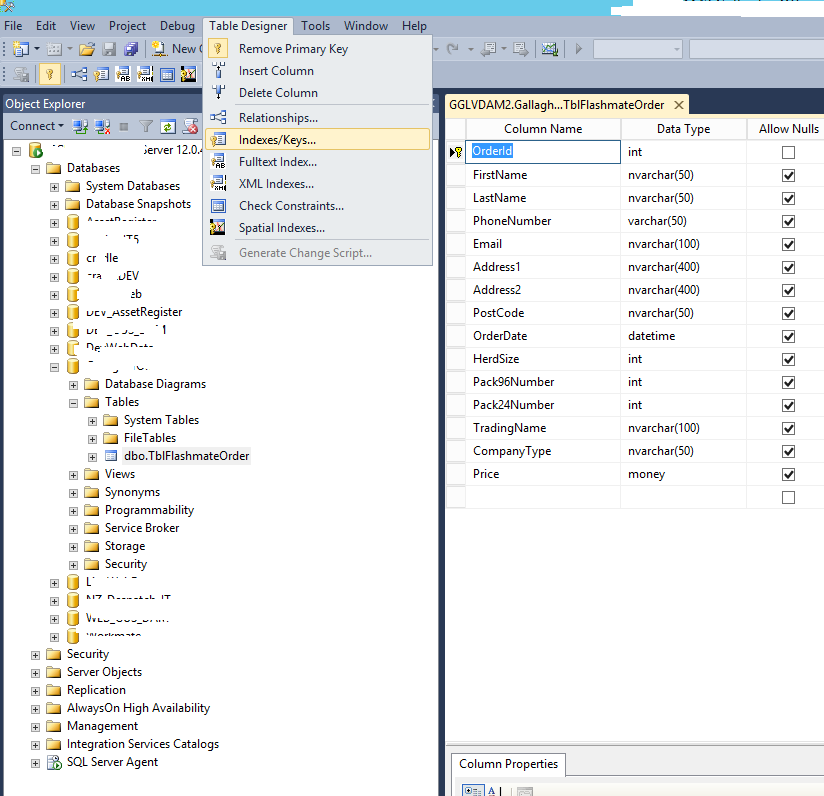
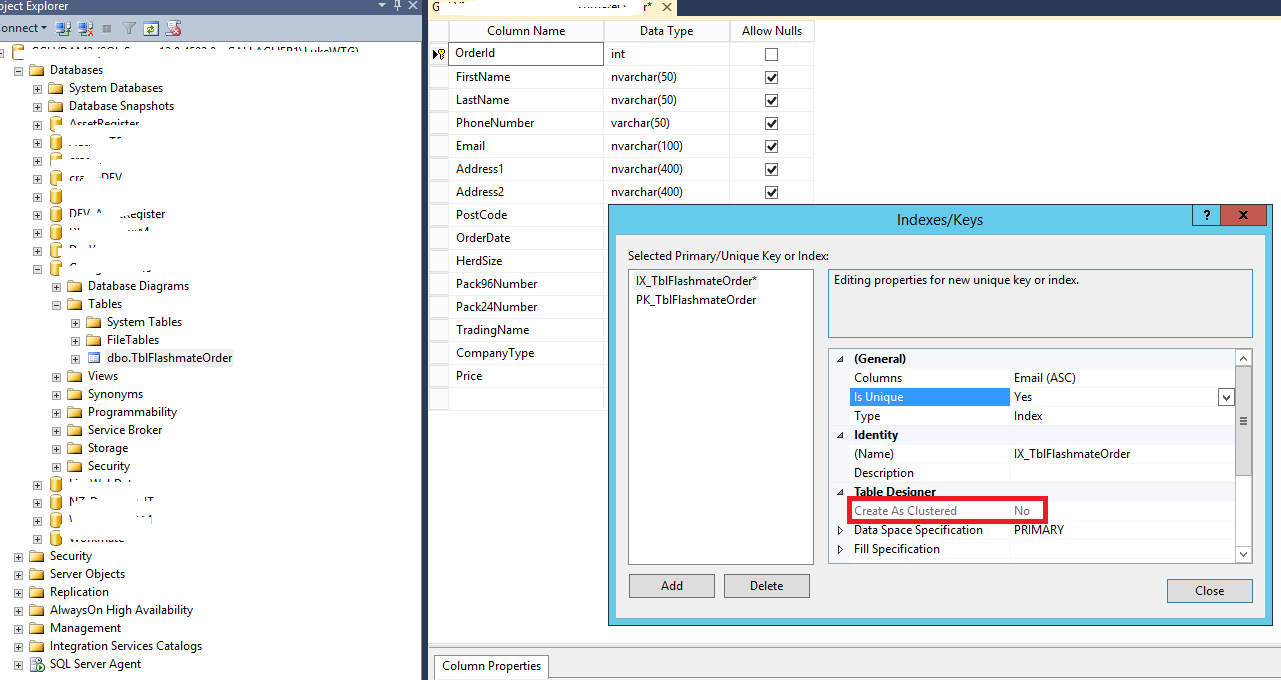
Click "Close" and "Save" button under the menu. Referesh the table and you can see the index folder under the table:
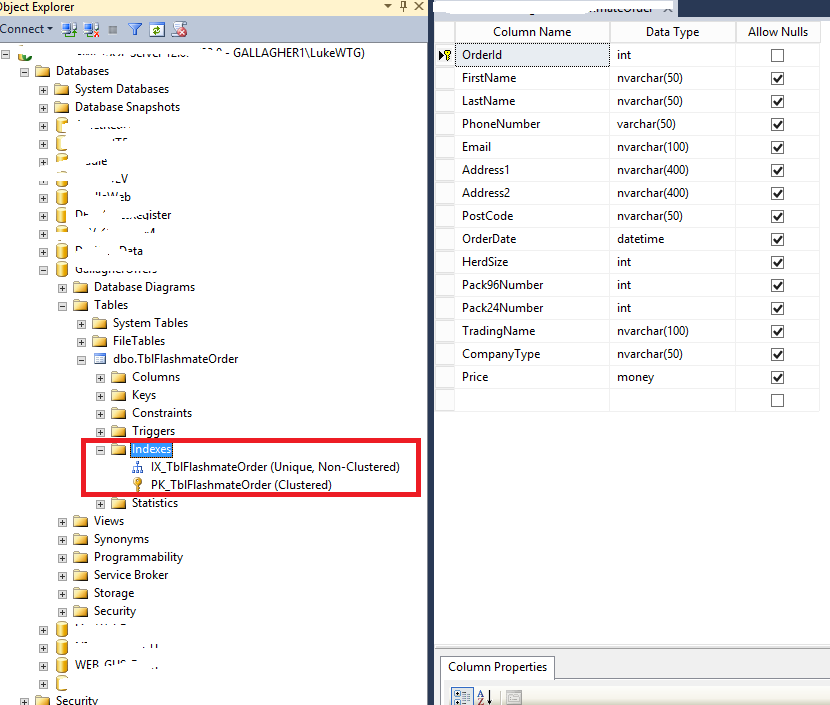
在上图中,右键点击“Indexes” ,可以新建 Non-Clustered Index.
在一个表需要Group by 一些字段 来计算一些数值字段的时候, 我们通常可以把Group by 的那些字段设置为Non-Clustered Index, 把那些需要计算的数值字段设置为Index中的包含列。 如下图:
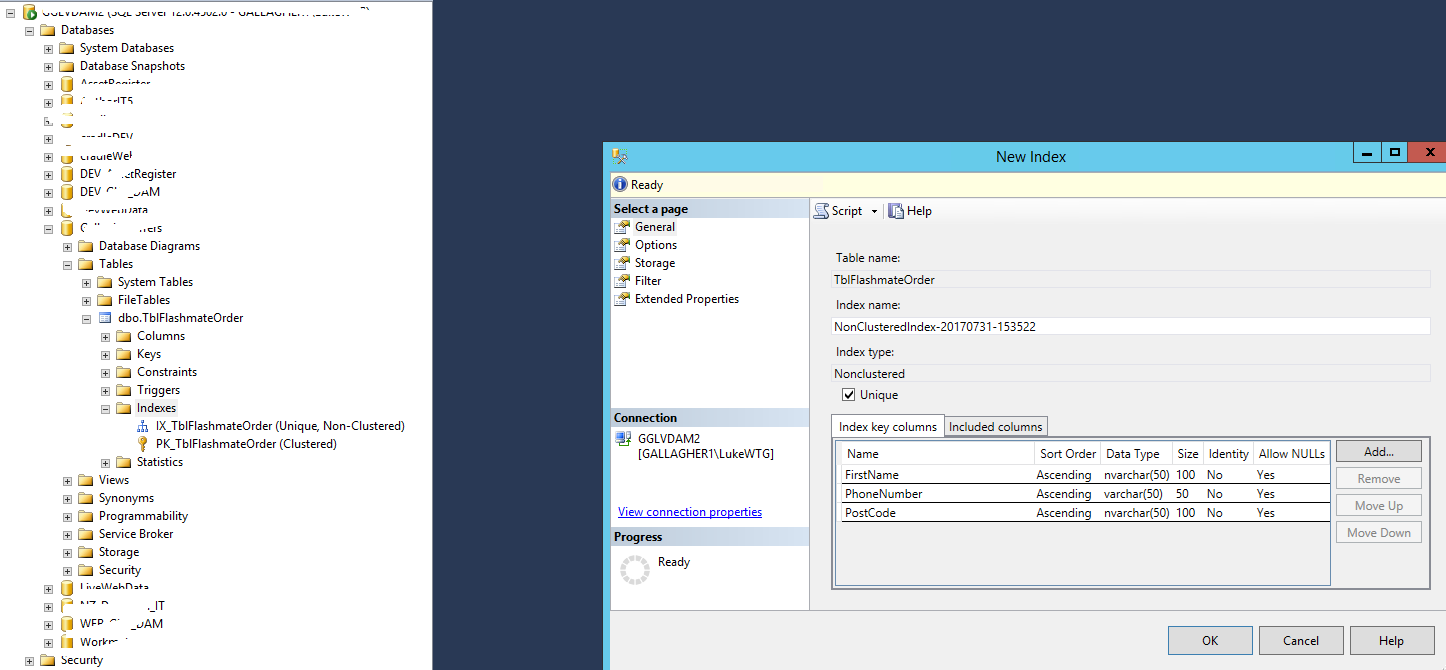
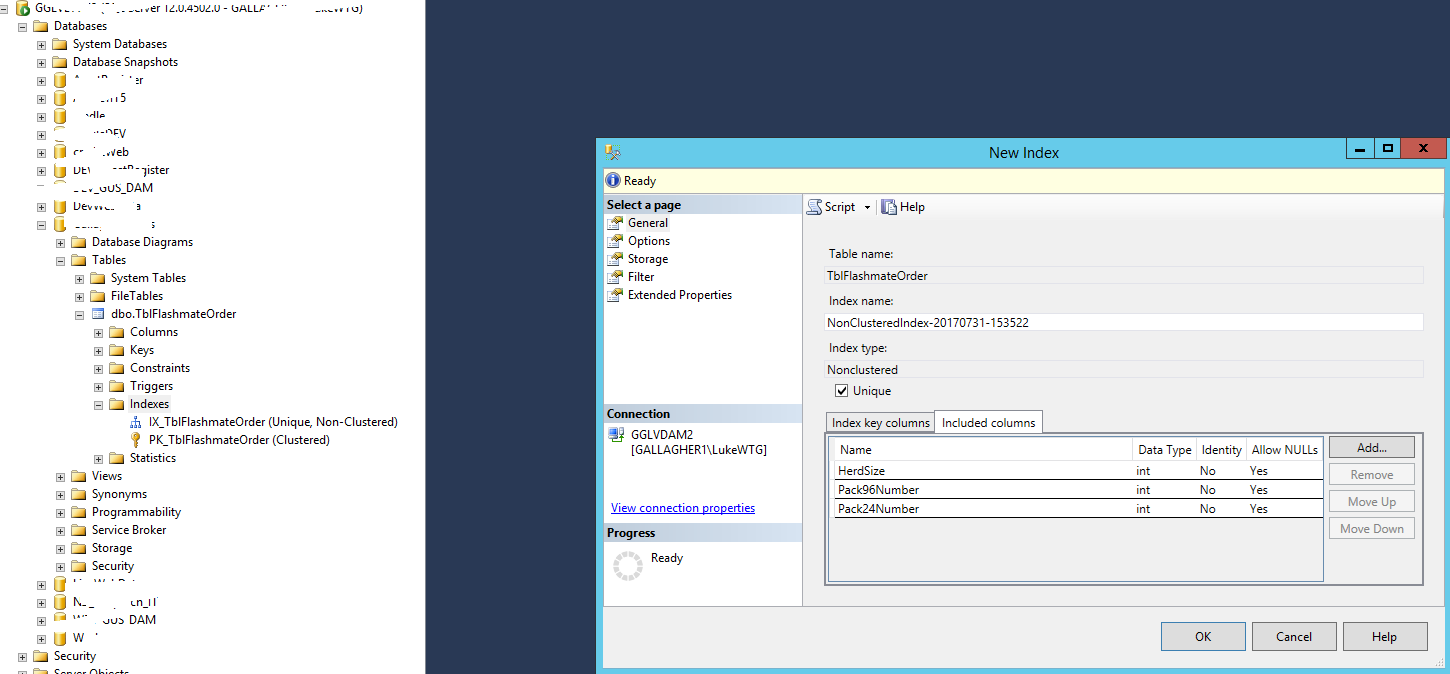
这样的话,可以大大提高这个SQL语句的性能(Performance)
请参考文章 http://www.cnblogs.com/emrys5/p/sqlserver_index.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号