c记录
#include <stdio.h>
#include <stdlib.h>
int main(int argc,char **argv)
{
FILE *fp = fopen("./a.txt","a"); //add pattern
if(fp == NULL){
printf("open file failed\n");
return -1;
}
printf("open file successful\n");
//write characters to file
fputc('A',fp);
fputc('b',fp);
fputc('c',fp);
fputc('d',fp);
fputc('e',fp);
fputc('f',fp);
fputc('g',fp);
fputc('i',fp);
fputc('h',fp);
printf("write to file successful\n");
fclose(fp);
printf("start to read file\n");
FILE *rp = fopen("./a.txt","r");
if(rp == NULL){
printf("open file failed");
return -1;
}
char c;
while((c=fgetc(rp)) != EOF){
printf("%c\n",c);
}
fclose(rp);
return 0;
}
vi命令
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc,char **argv)
{
char fileName[256];
printf("请输入要创建的文件名\n");
scanf("%s",fileName);
getchar(); //保持输入状态
FILE *fp = fopen(fileName,"w"); //找不到文件自己创建
if(fp == NULL){
printf("创建文件失败");
return -1;
}
//定义一个缓冲区
char buff[1024];
while(1){
memset(buff,0,1024); //1k内存全部置为空 重置缓冲区
//读取用户输入的内容
fgets(buff,1024,stdin);
if(strncmp("exit",buff,4) == 0){
break;
}
int i=0;
while(buff[i] != '\0'){
fputc(buff[i++],fp);
}
}
//关闭文件操作符
fclose(fp);
return 0;
}
cat 命令
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc,char **argv)
{
char fileName[256];
printf("请输入要打开的文件名\n");
scanf("%s",fileName);
getchar(); //保持输入状态
FILE *fp = fopen(fileName,"r"); //找不到文件自己创建
if(fp == NULL){
printf("打开文件失败");
return -1;
}
char str;
while( (str = fgetc(fp)) != EOF){
printf("%c",str);
}
//关闭文件操作符
fclose(fp);
return 0;
}
文件行读取
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc,char **argv)
{
char fileName[256];
printf("请输入要打开的文件名\n");
scanf("%s",fileName);
FILE *fp = fopen(fileName,"r"); //找不到文件自己创建
if(fp == NULL){
printf("打开文件失败");
return -1;
}
char *str = malloc(sizeof(char)*1024);
while( feof(fp) == 0){
memset(str,0,1024);
fgets(str,1024,fp);
printf("%s",str);
}
//关闭文件操作符
fclose(fp);
return 0;
}
对10w条随机整型数据进行排序
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(int argc, char **argv)
{
/*******生成随机数10w个一千以内的随机数*********/
unsigned int wst = time(NULL);
unsigned int wet;
unsigned int tc;
unsigned int tcall;
//随机数种子
srand((unsigned int )time(NULL));
//新建文件
FILE *fp = fopen("./5.txt","w"); //可以用输入方式打开新建文件
if(!fp){
printf("Can not open file 5.txt");
}
//打开文件成功 写入10w个随机数
for(int i=0;i<100000;i++){
fprintf(fp,"%d\n",rand()%1000+1); //写入文件中
}
fclose(fp); //关闭文件
wet = time(NULL);
tc = wet - wst;
printf("生成随机数消耗时间%d(s)\n",tc);
/*****************使用快速排序对10W个数据排序 耗时52秒 win7 8G内存 **************************/
FILE *rp = fopen("./5.txt","r");
if(!rp){
printf("can not open file 5.txt");
return -1;
}
//读取数据到内存中
int *buff = (int *)malloc(sizeof(int)*100000); //开辟一个可以存放10W个数据的内存空间
//读取10次数据存放到堆中
for(int i=0;i<100000;i++){
fscanf(rp,"%d\n",&buff[i]); //注意第三个参数是用指针传递地址 方便快捷 节省空间
}
//数据已经放到内存中 从内存中拿出来 用快速排序实现数据的排序 然后重新写入到5.txt
for(int i=0;i<100000-1;i++){ //对堆内存中的数据排好序
for(int j=0;j<100000-i-1;j++){
if(buff[j] > buff[j+1]){
int temp = buff[j+1];
buff[j+1] = buff[j];
buff[j] = temp;
}
}
}
FILE *wp = fopen("./5.txt","w");
if(!wp){
printf("can not open file");
return -1;
}
//重新写入到原文件中
for(int i=0;i<100000;i++){
fprintf(wp,"%d\n",buff[i]);
}
tcall = time(NULL);
printf("总共消耗了%d(s)\n",tcall - wst);
fclose(wp);
free(buff); //释放空间
/************使用优化的方法来排序 耗时1秒*********/
/*
* 对10w条数据统计
*统计1-1000之内数字出现的次数
*arr[1] = xxx
*arr[1000] = xxxx
*记录 然后打印
*/
FILE *rp1 = fopen("./5.txt","r");
if(!rp1){
printf("can not open file 5.txt");
return -1;
}
int arr[1000]={0};
int value;
//用一个双层循环统计次数
for(int i=0;i<100000;i++){
fscanf(rp1,"%d\n",&value);
arr[value - 1]++;
}
fclose(rp1);
rp1 = fopen("./5.txt","w");
if(!rp1){
printf("can not open file 5.txt");
return -1;
}
//用循环打印所有的数据
for(int i=0;i<1000;i++){
for(int j=0;j<arr[i];j++){
fprintf(rp1, "%d\n",i+1);
}
}
fclose(rp1);
return 0;
}
fwrite 和fread 读取文件
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc , char **argv)
{
//二进制文件读写
char arr[30] = "woaiwodezuoguozhongguo";
FILE *fp = fopen("./6.txt","wb");
if(!fp){
printf("failed to open file");
return -1;
}
fwrite(arr,sizeof(char),30,fp);
//再用fread 去读取 打印
fclose(fp);
return 0;
}
大文件拷贝 类似Linux 下面的copy命令(简单版)
#include <stdio.h> #include <stdlib.h> #include <string.h> #include<time.h> #define MAXSIZE 1024*10 int main(int argc ,char *argv[]) { //文件拷贝 //fgets fputs //fread fwrite unsigned int start_time = time(NULL); if(argc < 3){ printf("Error:less paramters"); return -1; } FILE *fp1 = fopen("./1.mp4","rb"); FILE *fp2 = fopen("./2.mp4","wb"); if(!fp1 || !fp2){ printf("Error:open file failed"); return -1; } //fgets and fputs 拷贝文件 但是会丢失内容消耗时间特别长 例如会导致视频播放不了 char buff[MAXSIZE]; while(!feof(fp1)){ fgets(buff,MAXSIZE,fp1); fputs(buff,fp2); } /***fread and fwrite 这个比较可靠实现**/ char *buff = (char*)malloc(MAXSIZE); int readCount; while( (readCount = fread(buff,1,MAXSIZE,fp1)) > 0){ fwrite(buff,readCount,1,fp2); } free(buff); fclose(fp1); fclose(fp2); unsigned int end_time = time(NULL); printf("All consume time is %d(s)\n",end_time - start_time); return 0; }
fseek SEEK_SET SEEK_END SEEK_CUR 设置文件的光标位置
ftell 获取当前文件的光标位置
rewind 重置文件指针为初始位置
进阶
typedef
char *p1,p2; 不能同时定义两个char*
typedef char * PCHAR;
PCHAR P1,P2; 可以定义两个char*
void 是对函数返回的限定和函数参数的限定
void function(){}
int function(void){}
void * 可以表示任何类型的指针 不管是一级还是二级 还是多级 int*还是char*都可以表示 也就是可以转换成void* 类型 一般用于数据结构的封装(指针的祖宗)
这是给编译器用的参数设置,有关结构体字节对齐方式设置, #pragma pack是指定数据在内存中的对齐方式。
#pragma pack (n) 作用:C编译器将按照n个字节对齐。
#pragma pack () 作用:取消自定义字节对齐方式。
#pragma pack (push,1) 作用:是指把原来对齐方式设置压栈,并设新的对齐方式设置为一个字节对齐
#pragma pack(pop) 作用:恢复对齐状态
因此可见,加入push和pop可以使对齐恢复到原来状态,而不是编译器默认,可以说后者更优,但是很多时候两者差别不大
如:
#pragma pack(push) //保存对齐状态
#pragma pack(4)//设定为4字节对齐
相当于 #pragma pack (push,4)
间接赋值
int a = 100;
int *p = &a; //一定要确保地址没有被释放
*p = 200; //赋值
#pragma pack (1) 作用:调整结构体的边界对齐,让其以一个字节对齐;<使结构体按1字节方式对齐>
#pragma pack ()
堆区

解决办法 :
void allocateSpace(char **p) //参数是一个地址
{
temp = NULL;
temp = malloc(100);
strcpy(temp,"hello world");
*p = temp;
}
void test02()
{
char *p = NULL;
allocateSpace(&p); //参数是一个地址
printf("p=%s\n",p);
}
宏和函数的区别,C语言宏和函数区别详解
在 C 语言中,对于一些常用或通用的功能或代码段的封装可以有两种方式:函数和宏定义。那么,对于这两种方式,我们该如何抉择呢?在解决这个问题之前,有必要先来了解一下它们之间的区别。
1) 从程序的执行来看
函数调用会带来额外的开销,它需要开辟一片栈空间,记录返回地址,将形参压栈,从函数返回还要释放栈。这种开销不仅会降低代码效率,而且代码量也会大大增加。而宏定义只在编译前进行,不分配内存,不占运行时间,只占编译时间,因此在代码规模和速度方面都比函数更胜一筹。
2) 从参数的类型来看
函数的参数必须声明为一种特定的数据类型,如果参数的类型不同,就需要使用不同的函数来解决,即使这些函数执行的任务是相同的。而宏定义则不存在着类型问题,因此它的参数也是无类型的。也就是说,在宏定义中,只要参数的操作是合法的,它可以用于任何参数类型。
3) 从参数的副作用来看
毋庸置疑,在宏定义中,在对宏参数传入自增(或者自减)之类的表达式时很容易引起副作用,尽管前面也给出了一些解决方案,但还是不能够完全杜绝这种情况的发生。与此同时,在进行宏替换时,如果不使用括号完备地保护各个宏参数,那么很可能还会产生意想不到的结果。除此之外,宏还缺少必要的类型检查。而函数却从根本上避免了这些情况的产生。
4) 从代码的长度来看
在每次使用宏时,一份宏定义代码的副本都会插入程序中。除非宏非常短,否则使用宏会大幅度地增加程序的长度。而函数代码则只会出现在一个地方,以后每次调用这个函数时,调用的都是那个地方的同一份代码。
调用惯例(Calling Convention):函数的调用方和被调用方对于函数如何调用需要有一个明确的约定,只有双方都遵守同样的约定,函数才能被正确的调用。
调用惯例一般会涉及到一下三个方面:
1 函数参数传递的顺序与方式
函数传递参数的方式有很多中,可以通过寄存器、栈和内存区域传递,不过最常见的是通过栈传递。函数的调用方先将参数压入栈中,函数自己再从栈中取出参数。对于有多个参数的函数,调用惯例要规定调用方将函数压入栈的顺序:是从左到右,还是从右到左。有些惯例还允许通过寄存器传递参数,以提高性能。
2 栈的维护方式
在函数压入栈之后,函数体会被调用,此后需要将被压入栈中的参数全部弹出,以使得栈在函数调用前后保持一致。这个工作既可以由调用方来做,也可以由函数来做。
3 名字修饰
为了链接的时候对调用管理进行区分,调用管理要对函数本身的名字进行修饰。不同的调用管理有不同的名字修饰策略。
这里我们主要介绍的cdecl、stdcall、fastcall三种c中主要的调用惯例,还有pascal、naked call、thiscall调用管理。这三种调用的区别如下:
| 调用惯例 | 出栈方 | 参数传递 | 名字修饰 |
| cdecl | 函数调用方 | 从右至左压入栈 | 下划线+函数名 |
| stdcall | 函数本身 | 从右至左压入栈 | 下划线+函数名+@+参数的字节数 |
| fastcall | 函数本身 |
头两个DWORD(4字节)类型或者占更少 字节的参数被放入寄存器,其它剩下的参数 按从右至左的顺序压入栈 |
@+函数名+@+参数的字节数 |
下面用一个实际的例子来看看这些调用方式具体是怎么实现的:

1 #include <stdio.h>
2
3 void __attribute__ (( cdecl))
4 a(int a, int b, int c)
5 {
6 char buffer1[5];
7 char buffer2[10];
8 }
9
10 int main ( int argc, char *argv[] )
11 {
12 a(1, 2, 3);
13 return 0;
14 } /* ---------- end of function main ---------- */
编译上面的代码,然后反汇编看下main函数和a函数的汇编代码:
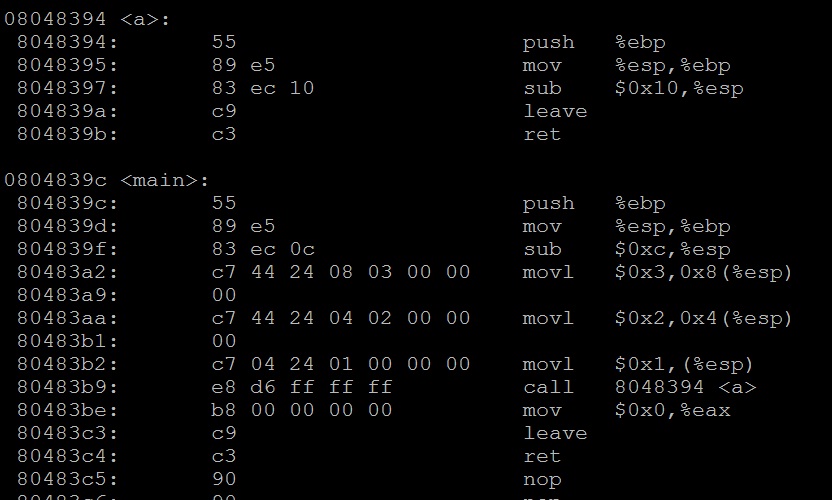
从反汇编的代码中可以看出main函数调用a时,参数是通过栈传输的,并且是从右至左向栈中压。a函数并没有维护栈,但是main函数貌似也没有维护栈,其实不然,main函数是用mov指令代替了push指令,所以esp的值并没有改变,也就不必维护了。不过如果用push,那就要维护esp的值,在编译时加上“-mno-accumulate-outgoing-args”选项就可以看到这种情况。这种调用惯例是gcc默认的,也就是cdecl惯例。
如果把上面代码中的第3行的cdecl换成stdcall,情况又会是怎样的呢?我们反汇编看下:
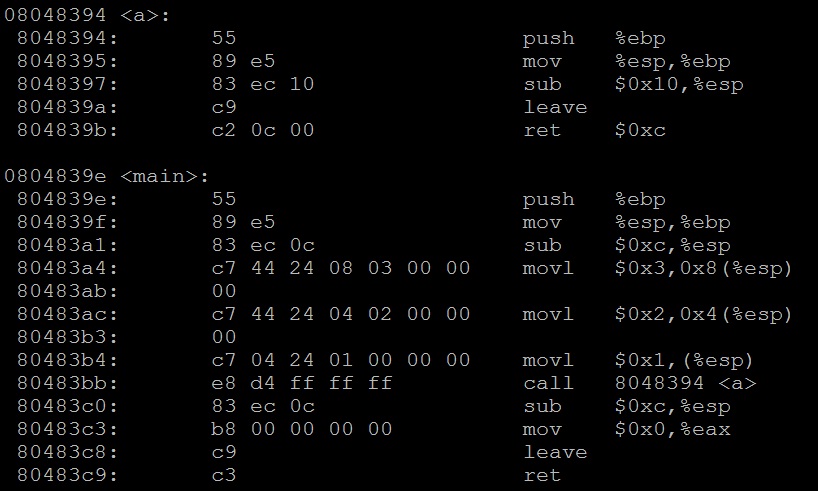
确实可以在a函数中看到它用ret指令维护了堆栈。不过对于用mov实现栈参数压入的main来说却反而要维护esp了,由于a中让esp减了0xc,所以回到main中后就必须回复esp的值,这也是为什么call a后main中将esp加了0xc。
如果把上面代码中的第3行的cdecl换成fastcall,情况又会是怎样的呢?我们反汇编看下:
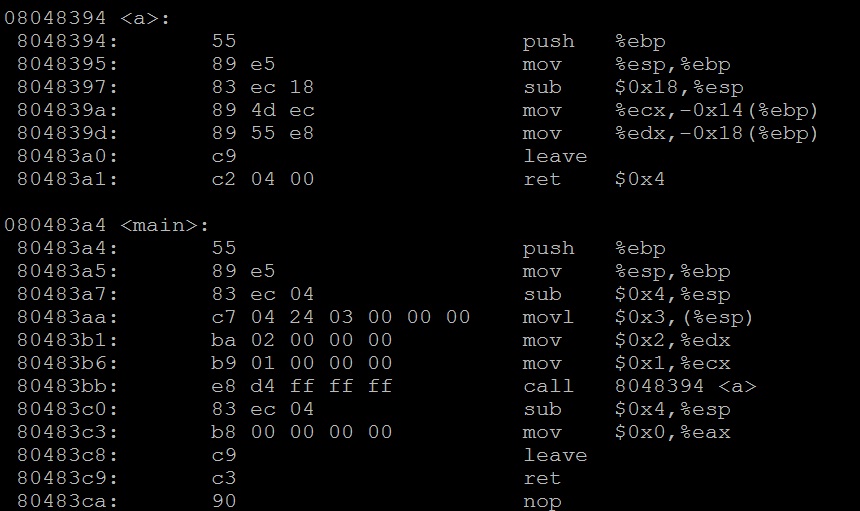
从main中可以看出,调用a函数的前两个参数分别通过ecx和edx传送,最后一个参数通过栈传送。a函数也维护了栈。
pascal调用惯例是将参数从左至右传送,函数自己维护栈,函数命名比较的复杂,貌似gcc通过前面的方式设置这种惯例不行。
C++内存区域分为5个区域。分别是堆,栈,自由存储区,全局/静态存储区和常量存储区。(同理解C)
栈:由编译器在需要的时候分配,在不需要的时候自动清除的变量存储区。里面通常是局部变量,函数参数等。
堆:由new分配的内存块,他们的释放编译器不去管,由我们的应用程序去控制,一般一个new对应一个delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。
自由存储区:由malloc等分配的内存块,和堆十分相似,不过它使用free来结束自己的生命。
全局/静态存储区:全局变量和静态变量被分配到同一块内存中,在以前的c语言中。全局变量又分为初始化的和未初始化的,在c++里面没有这个区分了,他们共同占用同一块内存。
常量存储区:这是一块比较特殊的存储区,里面存放的是常量,不允许修改。
C++内存区域中堆和栈的区别:
管理方式不同:栈是由编译器自动管理,无需我们手工控制;对于堆来说,释放由程序员完成,容易产生内存泄漏。
空间大小不同:一般来讲,在32为系统下面,堆内存可达到4G的空间,从这个角度来看堆内存几乎是没有什么限制的。但是对于栈来讲,一般都是有一定空间大小的,例如,在vc6下面,默认的栈大小好像是1M。当然,也可以自己修改:打开工程。 project-->setting-->link,在category中选中output,然后再reserve中设定堆栈的最大值和 commit。
能否产生碎片:对于堆来讲,频繁的new/delete势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题。
生长方向不同:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方式是向下的,是向着内存地址减小的方向增长。
分配方式不同:堆都是动态分配的;栈有静态和动态两种分配方式。静态分配由编译器完成,比如局部变量的分配。动态分配由alloca函数进行、但栈的动态分配和堆是不同的,它的动态分配由编译器进行释放,无需我们手工实现。
分配效率不同:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是c/c++库函数提供的,机制很复杂。库函数会按照一定的算法进行分配。显然,堆的效率比栈要低得多。
进程内存中的映像,主要有代码区,堆(动态存储区,new/delete的动态数据),栈,静态存储区
内存区域地址从低到高的方向:代码区,静态存储区,堆,栈
堆”和“栈”是独立的概念平常说的“堆栈”实际上是两个概念:“堆”和“栈”。在英文中,堆是heap,栈是stack,不知道什么时候,什么原因,在中文里,这两个不同的概念硬是被搞在一起了,所以,围绕这个混合词所发生的误解和争执这几年就没有断过。
“栈”一般是由硬件(CPU)实现的,CPU用栈来保存调用子程序(函数)时的返回地址,高级语言有时也用它作为局部变量的存储空间。
“堆”是个实实在在的软件概念,使用与否完全由编程者“显示地(explicitly)”决定,如malloc。
程序经过编译连接生成执行程序后,堆和栈的起始地址就已经确定了(具体说,是通过“连接程序”),在一个具有反向增长的栈的CPU上,数据空间可表示如下:
低 ->|-----------------|
| 全局量(所有已初始化量 .data, |
| 未初始化量 .bss ) |
堆起始->|-----------------|
| 堆向高地址增长 |
| |
| |
| 自由空间 |
| |
| |
| 栈向低地址增长 |
高 栈起始->|-----------------|
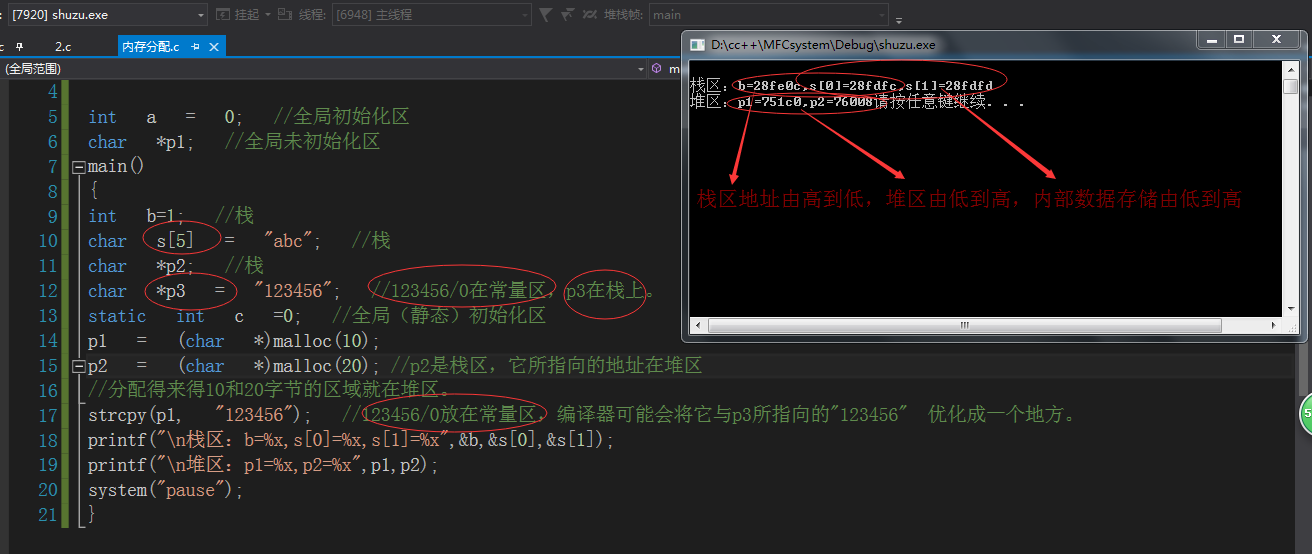
在内存中,“堆”和“栈”共用全部的自由空间,只不过各自的起始地址和增长方向不同,它们之间并没有一个固定的界限,如果在运行时,“堆”和 “栈”增长到发生了相互覆盖时,称为“栈堆冲突”,系统肯定垮台。由于开销方面的原因,各种编译在实现中都没有考虑解决这个问题,只有靠设计者自己解决,比如增加内存等。
=================================================================
说明(128为例)硬堆栈:
即SP,通常汇编中讲的所谓堆栈(用于PC指针等压栈),一般设置从片内RAM的顶部0X10FF开始向下生长,基本上64个足够足够了
软件堆栈:
C编译器自动分配的堆栈,在硬堆栈和全局变量之间的空间,也是向下生长,一般用于局部变量。比如一个子程序定义一个局部变量A[256],那么此空间即在软堆栈中,假设当前软堆栈用到0X800,分派A[256]后,软堆栈用到0X700,A[0]地址为0X700,A[1]地址为 0X701 ……,当然如果局部变量较少,用寄存器就可以了,用不着软堆栈了。此子程序退出后软堆栈恢复到0X800。
另:你的C程序编译后,生成的汇编文件中,R28:R29就是软堆栈指针
一般硬堆栈只要在编译选项中设置,软堆栈编译器会自动设置。你只要看看*.mp文件是否合理就可以了。
指针的步长
#include <stdio.h> #include <stddef.h> struct Person { int a; char b; char buf[64]; int d; }; int main(int argc, char **argv) { struct Person p = {10,'A',"I love China",200}; char b; int a; //获取结构体Person char b的偏移量 printf("A offset is:%d\n",offsetof(struct Person,b)); //offset is : 4 //获取int d 的值 //获取结构体p的首地址 (char *)&p+offsetof(struct Person,d) //int d 是整型 要转换成int * (int *)((char *)&p+offsetof(struct Person,d)) //取值 解引用 *(int *)((char *)&p+offsetof(struct Person,d)) printf("d's value is :%d\n",*(int *)((char *)&p+offsetof(struct Person,d))); return 0; }
指针做函数参数的输出特性
#include <stdio.h> #include <stdlib.h> #include <string.h> void changeValue(char **temp){ char *p = malloc(sizeof(char)*100); memset(p,0,100); strcpy(p,"hello world I love china"); *temp = p; } int main(int argc ,char **argv) { char *p = NULL; changeValue(&p); printf("p's value is %s\n",p); if(p != NULL) { free(p); p = NULL; } return 0; }
字符串拷贝实现
#include <stdio.h> #include <stdlib.h> #include <string.h> void test1(char *dest,char *sour){ int len = strlen(sour); for(int i=0;i<len;++i){ dest[i] = sour[i]; } dest[len] = '\0'; } void test2(char *dest, const char *sour){ while(*sour != '\0'){ *dest = *sour; sour++; dest++; } *dest = '\0'; } void test3(char *dest,char *sour){ while(*dest++ = *sour++); } int main(int argc ,char **argv) { char *s = "hello world"; char buf[1024] = {0}; test1(buf,s); printf("buf1's value is %s\n",buf);
memset(buf,0,1024); test2(buf,s); printf("buf2's value is %s\n",buf);
memset(buf,0,1024); test3(buf,s); printf("buf3's value is %s\n",buf); return 0; }
malloc,alloc,realloc之间的相似与区别
三个函数的申明分别是:
void* realloc(void* ptr, unsigned newsize);
void* malloc(unsigned size);
void* calloc(size_t numElements, size_t sizeOfElement);
都在stdlib.h函数库内。它们的返回值都是请求系统分配的地址,如果请求失败就返回NULL。
malloc与calloc的区别为1块与n块的区别:
malloc调用形式为(类型*)malloc(size):在内存的动态存储区中分配一块长度为“size”字节的连续区域,返回该区域的首地址。
calloc调用形式为(类型*)calloc(n,size):在内存的动态存储区中分配n块长度为“size”字节的连续区域,返回首地址。
realloc调用形式为(类型*)realloc(*ptr,size):将ptr内存大小增大到size。(也可以缩小,缩小的内容消失)。
另外有一点不能直接看出的区别是,malloc 只管分配内存,并不能对所得的内存进行初始化,所以得到的一片新内存中,其值将是随机的。calloc在动态分配完内存后,自动初始化该内存空间为零。
realloc有个细节需要注意:
无非就是将已经存在的一块内存扩大。
char* p = malloc(1024);
char* q = realloc(p,2048);
现在的问题是我们应该如何处理指针 p。 刚开始按照我最直观的理解,如果就是直接将 p = NULL;。 到最后只需要释放 q的空间就可以了。
因为最近在做个封装。结果在做单元测试的时候发现。有时候我在 free(q); 的时候会出错。这样我就郁闷了。
后来仔细一跟踪,发现 realloc 完以后 q 和 p 的指针地址是一样。不过有时候又不一样。
仔细查了下资料。得到如下信息:
1.如果 当前连续内存块足够 realloc 的话,只是将p所指向的空间扩大,并返回p的指针地址。 这个时候 q 和 p 指向的地址是一样的。
2.如果 当前连续内存块不够长度,再找一个足够长的地方,分配一块新的内存,q,并将 p指向的内容 copy到 q,返回 q。并将p所指向的内存空间删除。
这样也就是说 realloc 有时候会产生一个新的内存地址 有的时候不会。所以在分配完成后。我们需要判断下 p 是否等于 q。并做相应的处理。
这里有点要注意的是要避免 p = realloc(p,2048); 这种写法。有可能会造成 realloc 分配失败后,p原先所指向的内存地址丢失。
sscanf()的用法
sscanf() - 从一个字符串中读进与指定格式相符的数据.
函数原型:
int sscanf( string str, string fmt, mixed var1, mixed var2 ... );
int scanf( const char *format [,argument]... );
说明:
sscanf与scanf类似,都是用于输入的,只是后者以屏幕(stdin)为输入源,前者以固定字符串为输入源。
其中的format可以是一个或多个 {%[*] [width] [{h | l | I64 | L}]type | ' ' | '\t' | '\n' | 非%符号}
注:
1、 * 亦可用于格式中, (即 %*d 和 %*s) 加了星号 (*) 表示跳过此数据不读入. (也就是不把此数据读入参数中)
2、{a|b|c}表示a,b,c中选一,[d],表示可以有d也可以没有d。
3、width表示读取宽度。
4、{h | l | I64 | L}:参数的size,通常h表示单字节size,I表示2字节 size,L表示4字节size(double例外),l64表示8字节size。
5、type :这就很多了,就是%s,%d之类。
6、特别的:%*[width] [{h | l | I64 | L}]type 表示满足该条件的被过滤掉,不会向目标参数中写入值
支持集合操作:
%[a-z] 表示匹配a到z中任意字符,贪婪性(尽可能多的匹配)
%[aB'] 匹配a、B、'中一员,贪婪性
%[^a] 匹配非a的任意字符,贪婪性
注意:在读入的字符串是空字符串时,sscanf函数并不改变待读入到的字符串的值。
例子:
1. 常见用法。
char buf[512] = ;
sscanf("123456 ", "%s", buf);
printf("%s\n", buf);
结果为:123456
2. 取指定长度的字符串。如在下例中,取最大长度为4字节的字符串。
sscanf("123456 ", "%4s", buf);
printf("%s\n", buf);
结果为:1234
3. 取到指定字符为止的字符串。如在下例中,取遇到空格为止字符串。
sscanf("123456 abcdedf", "%[^ ]", buf);
printf("%s\n", buf);
结果为:123456
4. 取仅包含指定字符集的字符串。如在下例中,取仅包含1到9和小写字母的字符串。
sscanf("123456abcdedfBCDEF", "%[1-9a-z]", buf);
printf("%s\n", buf);
结果为:123456abcdedf
5. 取到指定字符集为止的字符串。如在下例中,取遇到大写字母为止的字符串。
sscanf("123456abcdedfBCDEF", "%[^A-Z]", buf);
printf("%s\n", buf);
结果为:123456abcdedf
6、给定一个字符串iios/12DDWDFF@122,获取 / 和 @ 之间的字符串,先将 "iios/"过滤掉,再将非'@'的一串内容送到buf中
sscanf("iios/12DDWDFF@122", "%*[^/]/%[^@]", buf);
printf("%s\n", buf);
结果为:12DDWDFF
7、给定一个字符串““hello, world”,仅保留world。(注意:“,”之后有一空格)
sscanf(“hello, world”, "%*s%s", buf);
printf("%s\n", buf);
结果为:world
%*s表示第一个匹配到的%s被过滤掉,即hello被过滤了
如果没有空格则结果为NULL。
sscanf的功能很类似于正则表达式, 但却没有正则表达式强大,所以如果对于比较复杂的字符串处理,建议使用正则表达式.
//-------------------------------------------------------
sscanf,表示从字符串中格式化输入
上面表示从str中,输入数字给x,就是32700
久以前,我以为c没有自己的split string函数,后来我发现了sscanf;一直以来,我以为sscanf只能以空格来界定字符串,现在我发现我错了。
sscanf是一个运行时函数,原形很简单:
int sscanf(
const char *buffer,
const char *format [,
argument ] ...
);
它强大的功能体现在对format的支持上。
我以前用它来分隔类似这样的字符串2006:03:18:
int a, b, c;
sscanf("2006:03:18", "%d:%d:%d", a, b, c);
以及2006:03:18 - 2006:04:18:
char sztime1[16] = "", sztime2[16] = "";
sscanf("2006:03:18 - 2006:04:18", "%s - %s", sztime1, sztime2);
但是后来,我需要处理2006:03:18-2006:04:18
仅仅是取消了‘-’两边的空格,却打破了%s对字符串的界定。
我需要重新设计一个函数来处理这样的情况?这并不复杂,但是,为了使所有的代码都有统一的风格,我需要改动很多地方,把已有的sscanf替换成我自己的分割函数。我以为我肯定需要这样做,并伴随着对sscanf的强烈不满而入睡;一觉醒来,发现其实不必。
format-type中有%[]这样的type field。如果读取的字符串,不是以空格来分隔的话,就可以使用%[]。
%[]类似于一个正则表达式。[a-z]表示读取a-z的所有字符,[^a-z]表示读取除a-z以外的所有字符。
所以那个问题也就迎刃而解了:
sscanf("2006:03:18 - 2006:04:18", "%[0-9,:] - %[0-9,:]", sztime1, sztime2);
如何定义数组指针
#include <stdio.h> #include <stdlib.h> #include <string.h> //sizeof 和 对数组名取地址 不是首地址 而是数组指针 int main(int argc ,char **argv) { int arr[5] = {1,2,3,4,5,6}; typedef int (ARRAY_TYPE)[5]; //define a new data type array_type ARRAY_TYPE narr; int i; for(i=0;i<5;i++) { narr[i] = arr[i]; } for(i= 0;i<5;i++) { printf("%d\n",narr[i]); } typedef int (*ARRAY_POINT)[5]; //保存数组的首地址 ARRAY_POINT ap; int j =0; *ap = arr; for(j=0;j<5;j++) { printf("new value %d\n",*(*ap+j)); } return 0; }
结构体深拷贝和浅拷贝
一、结构体的浅拷贝
1.结构体的浅拷贝是把一个结构体的内容拷贝到另外一个结构体,仔细看代码就可以
#include <stdlib.h> #include <string.h> #include <windows.h> typedef struct teacher { char *name; int age; }teacher; int main() { teacher t1; t1.name = (char*)malloc(30);//给name动态分配空间 strcpy(t1.name, "liming");//把文字常量区的内容拷贝给t1.name t1.age = 22; teacher t2 = t1;//结构体的浅拷贝 printf("%s %d", t2.name, t2.age); if (t1.name != NULL) //释放分配给t1.name 的堆区空间 { free(t1.name); t1.name = NULL; } //C语言中不能存在二次释放,会导致程序崩溃,画出内存图,可以看到t1.name和t2.name指向同一内存 //if (t2.name != NULL) //{ // free(t2.name); // t2.name = NULL; //} return 0; }
2.结构体的深拷贝
给t2单独分配一块空间进行拷贝,代码如下:
#include <stdio.h> #include <stdlib.h> typedef struct teacher { char *name; int age; }teacher; int main() { teacher t1; t1.name = (char*)malloc(30); strcpy(t1.name, "lily"); t1.age = 22; teacher t2; t2 = t1; t2.name = (char*)malloc(30);//给t2.name重新分配空间 strcpy(t2.name, t1.name); printf("%s %d", t2.name, t2.age); if (t1.name != NULL)//释放t1.name和t2.name的堆区空间 { free(t1.name); t1.name = NULL; } if (t2.name != NULL) { free(t2.name); t2.name = NULL; } return 0; }
使用动态内存


函数指针定义
1.函数名
typedef int(FUNC_TYPE)(int,char)
2.函数指针
typedef int(*FUNC_TYPE)(int,char)
3. 直接直接定义
int(*FUNC_TYPE)(int,char) = NULL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号