
剖析一个用C++写的行情交易系统
最近hen ci hen ci用C++写完了一整套证券行情系统,但是不是服务沪深交易所的,是给文交所用的。整个系统涵盖了从DBF文件解析开始到客户端展现这一整条逻辑。想来一年多没有更新博客了,所以趁这个机会,把整个系统的架构和开发中遇到的问题写下来,权当总结和分享。
首先要说明的是,整个系统的架构都是以当前业务为出发点的,所以和目前网上看到的,比方说广发自研的系统是肯定有差别的,我们就没有合规一说。另外,从用户规模和市场活跃程度来看,我们也无法和国内证券市场比较,所以和目前公开出来的系统结构相比也还是有差异的。我们根据自身人力资源限制和当前业务角度考虑,首要目标是希望整体架构要简单,易于横向扩展。因为一,人太少,平均下来,我就俩人;二,不懂业务,其中接手我服务端开发的还是应届毕业生。
这里先把系统结构图罗列一下:
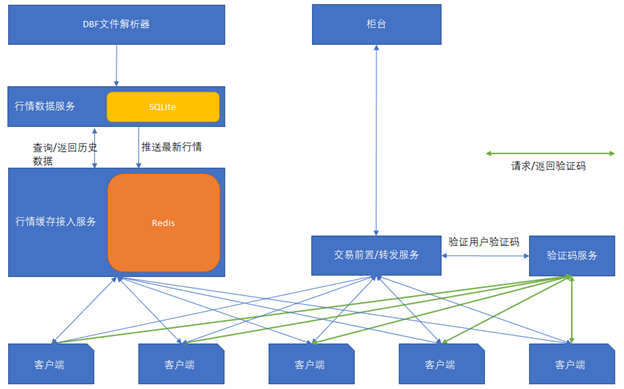
你会看到里面有很多让人意想不到的东西,比方说SQLite!
容我后续慢慢来说!
DBF文件解析
目前沪深L1数据更新的频率是3秒。文交所这边是1秒。总得来说解析DBF文件没有太大的难度,就是要理解文件结构。DBF文件结构其实也是开放的,随便查。这个程序没有任何难度,不需要多线程,只有一个要求,就是解析文件越快越好。
关于DBF么,我就画一个结构图在这里好了。方便大家查阅。

行情数据库程序
首先来张图展示下行情数据库程序的结构。
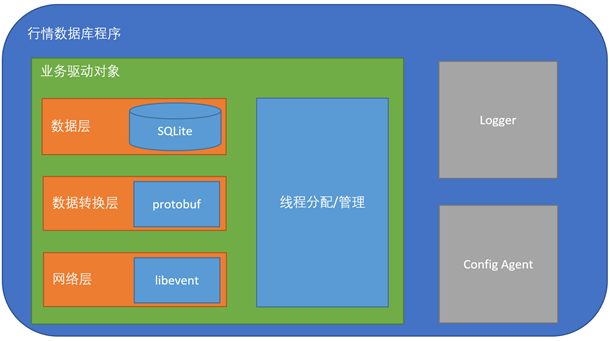
从图上看,我们的行情程序分三大模块:
- 业务驱动对象
- Logger
- Config Agent
Logger
也就是日志。我们这里是直接用了Linux自带的Syslog。当然了回归到代码的话,是一个logger接口,然后在Linux上基于Syslog实现了这个logger接口。
为什么选用Syslog?一是我们没有那么多资源搞一个异步logger;二是以我们目前的压力来看,Syslog从各方面都满足我们的要求。而且是独立的进程,万一发生不测,不影响我们行情正常运行,无非就是没有日志了。
Config Agent
配置文件读取对象。好像没有神马好说的。
业务驱动对象
我们重点来说下这个业务驱动对象。
首先来说一说这个业务驱动对象到底是用来干啥的。
服务端程序在设计的时候,你肯定会将业务进行层次划分,这样做的好处就是结构清晰,易于维护。每一层就是一个模块,模块之间规定好访问接口,形象地说就是高内聚低耦合。
在我们这里,模块之间的接口都是以boost:: signals2::signal来做的。
网络层
网络层只开放了5个接口:

其中shield是指DBF文件解析器。当连上了DBF解析器的时候,网络层会向上层发送一个shield_connected_signal_t类型的信号,一般这个信号上一层都没有订阅。当DBF解析器推送数据过来的时候,网络层解析成功后,就会发送一个shield_data_ready_signal_t信号。这个信号上次肯定会订阅的,不然程序就不用跑了。
另外,cache打头的信号指的是从缓存程序发送过来的请求。和DBF的shield类似,基本上一目了然,顾名思义。
数据转换层
这层其实可有可无。这层的作用就是将网络过来的二进制数据解码成protobuf message对象,然后将protobuf message对象解码成无第三方库依赖的本地数据包,并根据数据包的类型,发送相应的信号给数据层。之所以有一个protobuf到本地包的转换,主要是感谢Google,毕竟Google是出了名的喜欢弃坑。或者说,等哪天有了更好的数据包二进制序列号反序列化库,只需要考虑将这一场替换掉,就万事大吉了。当然,目前来看,这一层肯定是我想多了!
数据层
数据层也就是我们真正处理业务的模块。这个模块的特点是,宏观上看简单,微观上看复杂。
宏观上看无非就三件事情:
- 从DBF数据计算出各种周期行情数据
- 将最新的行情数据存盘
- 将最新的行情数据推送到前端缓存
微观上复杂怎么说呢?复杂就复杂在计算周期行情数据。
行情数据计算
我们给每一个行情数据都指定了一个数据项ID。比方说开盘价我们可以用0xFFFFFFFF这个ID来表示,收盘价可以用0xFFFFFFFE来表示。
除此以外,我们还具体定义了周期ID。实时周期,一分钟周期,五分钟周期,十五分钟周期,三十分钟周期,六十分钟周期,日周期,周月季年周期等。
DBF里的数据就相当与实时周期数据。
所以我们有多少数据要计算?显而易见,数据项ID个数x周期个数!
数据项ID说实话,并不少!所以计算周期数据真的是相当的重体力!
那么计算行情数据到底应该是:
- 遍历每一个数据项,计算出这个数据项所有周期的数据
- 还是先根据周期来,计算出每一个周期下所有数据项的值
这个话题说到这里,感觉说不下去了。因为我最后付诸的行动不是这么搞的。我不确定我的算法是不是最优算法,但是我想应该八九不离十?
要把这个想法说清楚,估计还是要真正写一把,你才知道到前面提到的说法到底对不对。
我前前后后写了大概至少两遍。我最终的想法容我下来吗慢慢说来。
先说一说我们数据的特点。行情数据其实都是以时间为顺序的离散数据点!这个能理解吧?所以,我们的行情数据在根据DBF文件计算的时候对于任意一个周期来说,无非遇到两种情况:
- 更新最新的这个时间点数据
- 生成一个最新时间点的数据
另外,在这两个大类的情下还要考虑一个因素:
- 更新当前最新数据点的时候是否和该周期前一个数据点有依赖关系?
- 生成一个最新数据点的时候是否和该周期前一个数据点有依赖关系?
所以我在计算行情数据时,先区分是否生成一个新的数据点。然后根据周期来计算的。
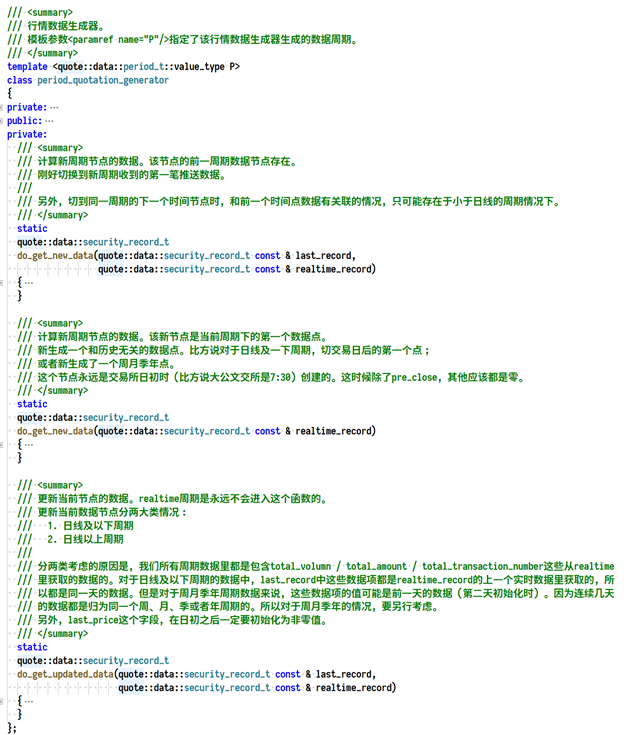
这个代码注释可能不对,心领神会就好。
关于行情计算这里再说最后一点,前段时间发现一个八哥。如果DBF文件里的某只代码/某个证券的昨收为0时,这个时候,这只代码当天的昨收是0还是其他值?正确答案是,不是零,是上一个交易日的昨收。
数据存盘
终于说到数据存盘,说到SQLite了。
先不从业务角度考虑这个问题。当有大量数据要存储的时候,一般的解决方案是什么?没有特殊要求的情况下,多数会使用数据库来解决这个问题。毕竟自研一套数据存储工具,而且要做得好,并不是一件简单的事情。接着我说一说同花顺和恒生,据我了解同花顺和恒生都是自己设计的二进制文件格式来保存行情数据的(不要问我怎么知道的,毕竟当初我是同花顺的)。恒生的不知道,同花顺我是有切身体会的。这个二进制文件经常会莫名其妙写挂了。所以现在经典的统一版客户端出现数据错误的时候,多半是文件已经写坏了。你需要“重新初始化”!
基于上面的考虑,我果断选择了SQLite。好处就是事务性,不容易写坏,并且易于通过第三方工具快速查阅。当然相比较自定义的二进制结构文件,劣势是查询数据的方式会慢一点,你得构造出一个SQL语句,然后解析返回的数据才可以。不过这其实并不是问题,大量频繁的查询操作我们都定义在缓存里,全部交由Redis来解决了。除了查询历史数据,我们一般都不需要访问数据库。
数据库另外一个优势就是历史库。我们可以把很久远的数据导到历史库里,这比自己搞一个二进制文件,然后要支持分割历史到历史库里要方便,这种复杂的操作,我不是不相信自己写代码的能力,而是我觉得何必呢?
既然经验证明存文件都没有问题,那么数据库我选用SQLite应该不会出大问题,如果出问题了,我改用非嵌入式数据库就行了。等性能问题即将出现的时候,profile一下,问题若出在SQLite,再改不迟。
线程分配/管理
接下来说一说线程分配管理模块。这个模块的设想是怎么出来的呢?显然,并不是瞎想出来的。
我们先来回顾一下我们经常用到的几个网络库,比方说Libevent,ASIO。这些类库没有在业务逻辑里面自己搞线程池,说神马自己创建一个线程然后跑。最多就是支持一下线程安全。该有锁的地方配好一把锁。所以,这个基本特性也告诉我,我的网络层我的数据层这些,他们都不应该自己去分配线程。这些层级要做的就是要确保线程安全,这样才能方便做横向拓展。
要实现这个目的,就需要网络层对象、数据层对象有一个dependence injection的构造函数,传入一个libevent event base wrapper对象。一个对象只能跑在一个线程上。那么一个客户端session到时候就只在指定的一个(我希望是这样,避免不必要的线程切换)或两个(看网络层和数据层这些是在同一条线程上跑还是分开跑)线程上跑。在这样的设计下,加之不同客户端之间其实业务行为都是独立的,包括数据都可以是独立的。那么不同线程间的客户session都是相互不影响的。有了这个分析结果,再配合thread_local,你在业务层面就不需要锁了。所以接下来通过增加线程的方式可以很轻松做到横向的多线程扩展。是不是?
未完,待续,to be continued。。。
posted on 2018-08-20 23:14 wpcockroach 阅读(4280) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号