
Hadoop hdfs完全分布式搭建教程
本文转载自:https://www.cnblogs.com/ysocean/p/6965197.html
1、安装环境
①、四台Linux CentOS6.7 系统
hostname ipaddress subnet mask geteway
1、 master 192.168.146.200 255.255.255.0 192.168.146.2
2、 slave1 192.168.146.201 255.255.255.0 192.168.146.2
3、 slave2 192.168.146.202 255.255.255.0 192.168.146.2
4、 slave3 192.168.146.203 255.255.255.0 192.168.146.2
其中 master 机器是 NameNode;
slave1 机器是 SecondaryNameNode
slave1,slave2,slave3 是三台 DataNode
②、hadoop 2.7 安装包
百度云下载链接:http://pan.baidu.com/s/1gfaKpA7 密码:3cl7
③、三台机器上建立一个相同的用户 hadoop
2、安装 JDK
教程:http://www.cnblogs.com/ysocean/p/6952166.html
3、配置SSH 无密码登录
教程:http://www.cnblogs.com/ysocean/p/6959776.html
我们以 master 机器来进行如下配置:
4、解压 hadoop-2.7.3.tar.gz
①、将下载的 hadoop-2.7.3.tar.gz 复制到 /home/hadoop 目录下(可以利用工具 WinSCP)
②、解压,进入/home/hadoop 目录下,输入下面命令
tar -zxvf hadoop-2.7.3.tar.gz
③、给 hadoop-2.7.3文件夹重命名,以便后面引用
mv hadoop-2.7.3 hadoop2.7
④、删掉压缩文件 hadoop-2.7.3.tar.gz,并在/home/hadoop 目录下新建文件夹tmp
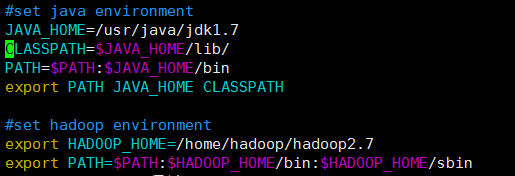
⑤、配置 hadoop 环境变量(这里我Java 和 hadoop 环境变量一起配置了)
使用 root 用户登录。输入
vi /etc/profile
5、配置 hadoop 文件中相应的文件
需要配置的文件如下,hadoop-env.sh,core-site.xml,hdfs-site.xml,slaves,所有的文件配置均位于hadoop2.7.1/etc/hadoop下面,具体需要的配置如下:
5.1 配置/home/hadoop/hadoop2.7/etc/hadoop目录下的core-site.xml
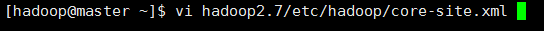
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.146.200:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp</value> </property> </configuration>
注意:hadoop.tmp.dir是hadoop 文件系统依赖的配置文件。 默认是在 /tmp 目录下的,而这个目录下的文件,在Linux系统中,重启之后,很多都会被清空。所以我们要手动指定这写文件的保存目录。
这个目录路径要么不存在,hadoop启动的时候会自动帮我们创建;要么是一个空目录,不然在启动的时候会报错。
5.2配置/home/hadoop/hadoop-2.7/etc/hadoop目录下的hdfs-site.xml

<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.146.201:50090</value> </property> </configuration>
注意:dfs.replication 是配置文件保存的副本数;dfs.namenode.secondary.http-address 是指定 secondary 的节点。
5.3配置/home/hadoop/hadoop-2.7/etc/hadoop目录下hadoop-env.sh 的JAVA_HOME

设置 JAVA_HOME 为自己在系统中安装的 JDK 目录

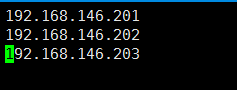
5.4配置/home/hadoop/hadoop-2.7/etc/hadoop目录下的slaves,删除默认的localhost,增加3个从节点

5.5、指定 SecondaryNameNode 节点
在 /home/hadoop hadoop-2.7/etc/hadoop 目录下手动创建一个 masters 文件
vi masters
打开文件后,输入 SecondaryNameNode 节点的主机名或者 IP 地址

6、将配置好的 hadoop 文件上传给其它三个节点
scp -r /home/hadoop 192.168.146.201:/home/
scp -r /home/hadoop 192.168.146.202:/home/
scp -r /home/hadoop 192.168.146.203:/home/
7、启动 hadoop
在master服务器启动hadoop,从节点会自动启动,进入/home/hadoop/hadoop-2.7目录
(1)初始化,输入命令,bin/hdfs namenode -format

(2)启动hdfs 命令:sbin/start-dfs.sh

(3)停止命令,sbin/stop-hdfs.sh
(4)输入命令,jps,可以看到相关信息
8、访问界面
①、关闭防火墙
service iptables stop
chkconfig iptables off
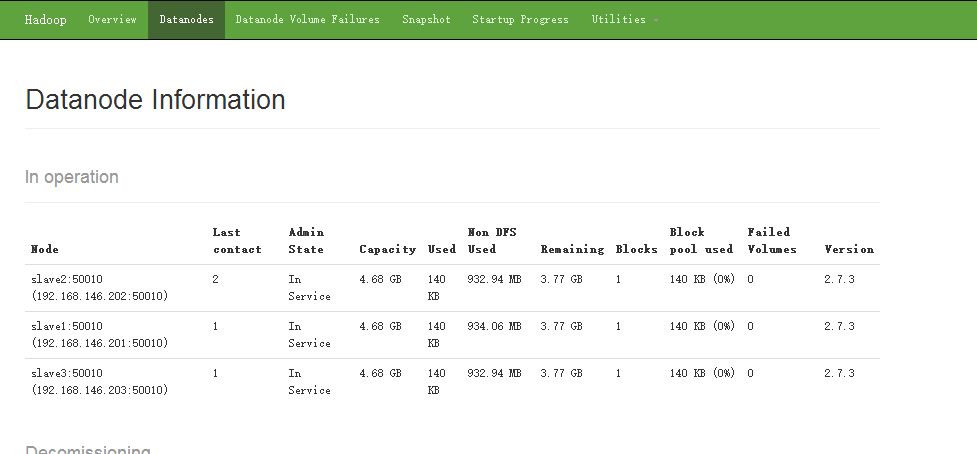
②、访问 NameNode 节点信息:http://192.168.146.200:50070
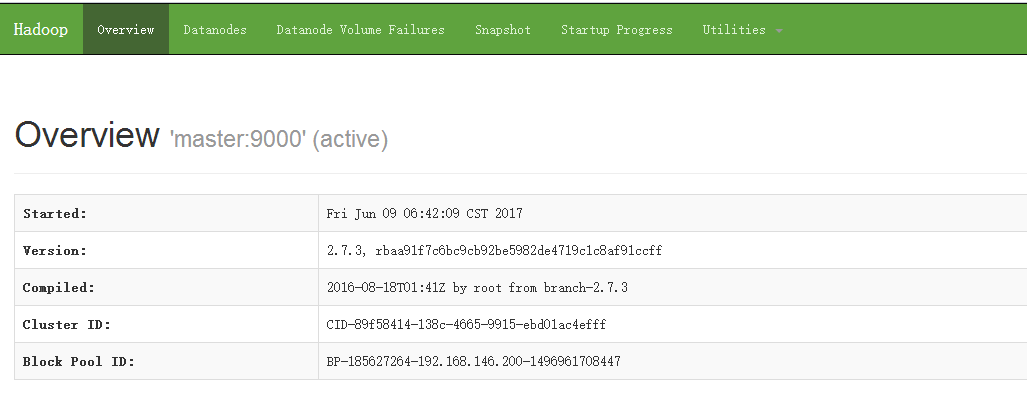
点击DataNodes 查看 DataNode 节点
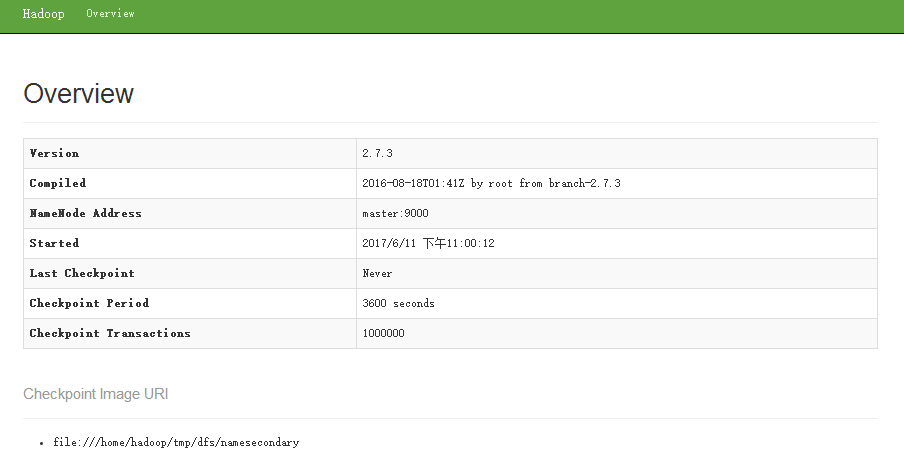
③、访问 SecondaryNameNode 节点信息,就是我们在hdfs-site.xml 中配置的路径 http://192.168.146.201:50090

 浙公网安备 33010602011771号
浙公网安备 33010602011771号