



本文转载自:https://www.cnblogs.com/LazyJoJo/p/6910504.html
1、配置好Hadoop和spark
2、配置好Pytho3.5
3、安装py4j
pip3 install py4j
4、idea 中添加Python插件
file->setting->editor->plugins
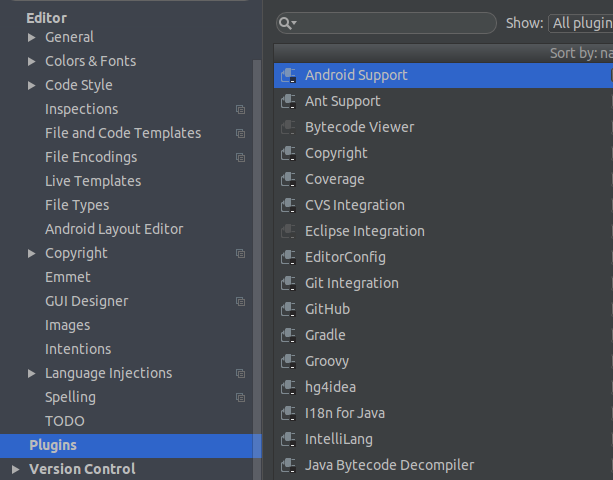
右边搜索框中 搜索Python,下载插件
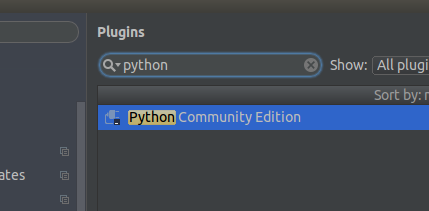
5、下载完后,重启软件,建立Python项目,导入pyspark的包文件
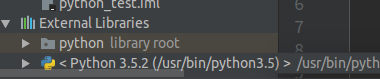
导入步骤:file->project Structure->modules->右边栏中点dependencies->点添加->将"spark/python" 添加进去
6、test:
from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession \ .builder \ .master("local") \ .appName("PythonWordCount") \ .getOrCreate() data = spark.read.csv("/lab/data/2/02singleentry.csv") data.show(10) spark.stop()
7、目前观察不能读取本地的数据,只能读取HDFS上的数据
