
python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那样不容易关闭服务
先来看下我编写的爬虫文件
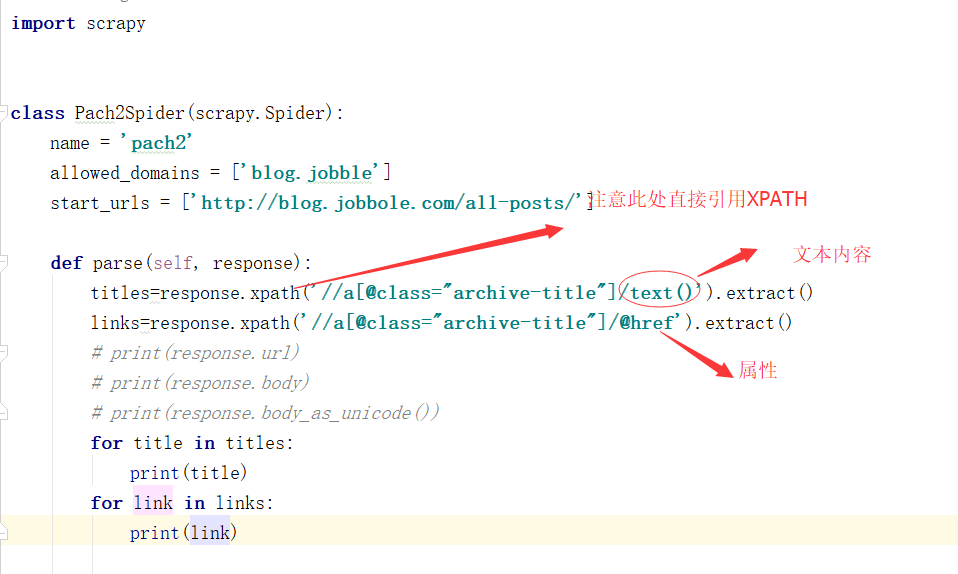
先来看下结果:
看到了吧不停的切换路径,也同时感到了xpath的强大了吧
总是切换到终端很麻烦,很多人为了炫耀自己的技术的强大都喜欢在终端各种操作,我个人觉得没有意义,明明走直线到家非得拐个弯
现在我们在文件中创建main.py文件 看一下路径 这个文件执行时是调动整个scrapy文件,那么文件创建的路径应该在外,看一下我编辑的位置
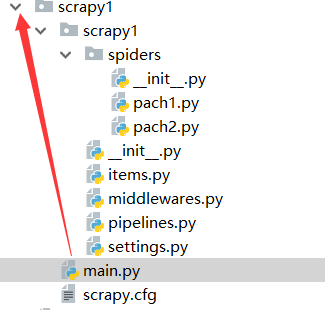
清晰明了 之前我写过pyMySQL的一篇随笔里面函数的用法和这里很相似

现在看下结果 看看哪个方便


 浙公网安备 33010602011771号
浙公网安备 33010602011771号