
Python day 6(3) Python 函数式编程1
一:函数式编程概念
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
而函数式编程(请注意多了一个“式”字)——Functional Programming,虽然也可以归结到面向过程的程序设计,但其思想更接近数学计算。
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。
而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
二:高阶函数概念
1 变量可以指向函数,内置函数abs是函数本身,abs(-10)才是函数的调用。f=abs f(-10)与abs(10)的含义相同
2 函数名也是变量
3 变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
三:高阶函数
1 filter函数
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
1 def is_odd(n): 2 3 return n % 2 == 1 4 5 list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
把一个序列中的空字符串删掉:
1 def not_empty(s): 2 return s and s.strip() 3 4 list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
filter()这个高阶函数,关键在于正确实现一个“筛选”函数。filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
求素数
1 # -*- coding: utf-8 -*- 2 3 def main(): 4 for n in primes(): 5 if n < 1000: 6 print(n) 7 else: 8 break 9 10 def _odd_iter(): 11 n = 1 12 while True: 13 n = n + 2 14 yield n 15 16 def _not_divisible(n): 17 return lambda x: x % n > 0 18 19 def primes(): 20 yield 2 21 it = _odd_iter() 22 while True: 23 n = next(it) 24 yield n 25 it = filter(_not_divisible(n), it) 26 27 if __name__ == '__main__': 28 main()
2 map/reduce函数
a map()函数接收两个参数,一个是函数,一个是iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。注意:Iterator是一个惰性序列,可以通过list,next,for in来返回
1 def f(x): 2 3 ... return x * x 4 ... 5 >>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) 6 >>> list(r)
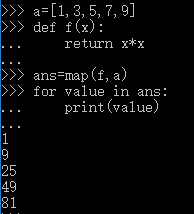
map()传入的第一个参数是f(函数名),即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
b reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)。但是用前必须先用 from functools import reduce导入
把字符串转化为整数的函数
1 from functools import reduce 2 3 DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9} 4 5 def char2num(s): 6 return DIGITS[s] 7 8 def str2int(s): 9 return reduce(lambda x, y: x * 10 + y, map(char2num, s))
利用map和reduce编写一个str2float函数,把字符串'123.456'转换成浮点数123.456:
1 # -*- coding: utf-8 -*- 2 from functools import reduce 3 4 def str2float(s): 5 d={"0":0,"1":1,"2":2,"3":3,"4":4,"5":5,"6":6,"7":7,"8":8,"9":9} 6 def str2num(s): 7 return d[s] 8 def str2int(x,y): 9 return x*10+y 10 def str2dec(x,y): 11 return x/10.0+y 12 int,dec=s.split('.',1) 13 return reduce(str2int,map(str2num,int))+reduce(str2dec,map(str2num,dec[::-1]))*0.1 14 print('str2float(\'123.456\') =', str2float('123.456')) 15 if abs(str2float('123.456') - 123.456) < 0.00001: 16 print('测试成功!') 17 else: 18 print('测试失败!')
3 sorted函数
(1)sorted()函数就可以对list进行排序:>>> sorted([36, 5, -12, 9, -21]) [-21, -12, 5, 9, 36]
(2) sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序: >>> sorted([36, 5, -12, 9, -21], key=abs) [5, 9, -12, -21, 36]key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。然后sorted()函数按照keys进行排序,并按照对应关系返回list相应的元素。
(3) 默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。
这样,我们给sorted传入key函数,即可实现忽略大小写的排序:
1 >>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower) 2 ['about', 'bob', 'Credit', 'Zoo']
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
1 >>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) 2 ['Zoo', 'Credit', 'bob', 'about']
(4)
# -*- coding: utf-8 -*- L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)] def by_name(t): return t[0]#t[1]按照分数进行排序 L2 = sorted(L, key=by_name)#按照名字排序 print(L2)
4 split方法
语法:str.split(str="",num=string.count(str))[n]
参数说明:
str:表示为分隔符,默认为空格,但是不能为空('')。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量
[n]:表示选取第n个分片
注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略
string = "www.gziscas.com.cn"
1.以'.'为分隔符
print(string.split('.'))
['www', 'gziscas', 'com', 'cn']
2.分割两次
print(string.split('.',2))
['www', 'gziscas', 'com.cn']
3.分割两次,并取序列为1的项
print(string.split('.',2)[1])
gziscas
4.分割两次,并把分割后的三个部分保存到三个文件
u1, u2, u3 =string.split('.',2)
print(u1)—— www
print(u2)—— gziscas
print(u3) ——com.cn

