Linux三剑客日志处理系列
三剑客日志处理系列
一、特殊符号
1.引号系列 必会
| 引号 | 含义 | |
|---|---|---|
| 单引号 | 所见即所得,单引号里的内容会原封不动输出 | |
| 双引号 | 和单引号类似,对双引号里面的特殊符号进行解析,对于{}花括号(通配符)没有解析 | |
| 不加引号 | 和双引号类似,支持通配符 | |
| 反引号 | 优先执行,先执行反引号里面的命令 |
[root@lnh ~]# echo '`hostname` 1234 $UID $(whoami) {1..5}' `hostname` 1234 $UID $(whoami) {1..5} [root@lnh ~]# echo "`hostname` 1234 $UID $(whoami) {1..5}" lnh 1234 0 root {1..5} [root@lnh ~]# echo `hostname` 1234 $UID $(whoami) {1..5} lnh 1234 0 root 1 2 3 4 5
2.重定向符号
2.1概述
重定向:改变输出方向

2.2 重定向符号
| 重定向符号 | 含义 | 应用场景 |
|---|---|---|
| > 或 1> | 标准输出重定向:先清空文件,然后写入 | 大部分情况下下清空的时候可以使用,创建文件 |
| >>或 1>> | 标准输出追加重定向:直接写入到文件末尾 | 修改配置文件,表示追加的时候 |
| 2> | 标准错误输出重定向:先清空文件,然后写入错误信息 | 较少使用 |
| 2>> | 标准错误追加输出重定向:直接把错误写入到文件末尾 | 较少使用 |
| >>oldboy.log 2>&1 | 无论对错都把结果写入到文件中 | 定时任务,脚本常用 |
| &>> oldboy.log | 无论对错都把结果写入到文件中 | 定时任务,脚本常用 |
| < 或0< | 标准输入重定向 | 搭配某几个命令使用xargs |
| << 或0<< | 标准输入追加重定向 | 与cat搭配使用,表示向文件写入多行内容 |
[root@lnh ~]# eccho 1>>oldboy.txt -bash: eccho: command not found [root@lnh ~]# cat oldboy.txt [root@lnh ~]# [root@lnh ~]# echo 1111 1>>oldboy.txt [root@lnh ~]# cat oldboy.txt 1111 [root@lnh ~]# eccho 2>>oldboy.txt [root@lnh ~]# cat oldboy.txt 1111 -bash: eccho: command not found [root@lnh ~]# echo haha >> oldboy.txt 2>> oldboy.txt [root@lnh ~]# cat oldboy.txt 1111 -bash: eccho: command not found haha [root@lnh ~]# eaacho haha >> oldboy.txt 2>> oldboy.txt [root@lnh ~]# cat oldboy.txt 1111 -bash: eccho: command not found haha -bash: eaacho: command not found [root@lnh ~]# eaacho xixi >> oldboy.txt 2>&1 [root@lnh ~]# cat oldboy.txt 1111 -bash: eccho: command not found haha -bash: eaacho: command not found -bash: eaacho: command not found [root@lnh ~]# echo xixi >> oldboy.txt 2>&1 [root@lnh ~]# cat oldboy.txt 1111 -bash: eccho: command not found haha -bash: eaacho: command not found -bash: eaacho: command not found xixi [root@lnh ~]# echo lll &> echo.txt [root@lnh ~]# cat echo.txt lll [root@lnh ~]# eqqcho lll &> echo.txt [root@lnh ~]# cat echo.txt -bash: eqqcho: command not found
定时任务中常用,同时记录错误信息和正确信息
用于与cat命令实现写入多行内容. 格式: cat >文件结束标记 结束标记 结束标记两边不要有多余符号 一般都是事先写好,然后粘贴到命令行执行. EOF End of File文件结束的缩写. [root@lnh ~]# cat >oldboy.txt <<EOF > I > LIKE > Money > EOF [root@lnh ~]# cat oldboy.txt I LIKE Money [root@lnh ~]# cat <<EOF >oldboy.txt > YOU > LIKE > Money > EOF [root@lnh ~]# cat oldboy.txt YOU LIKE Money
3.通配符
用于Linux中大部分命令使用,用于批量找文件名
| 符号 | 含义 | |
|---|---|---|
| * 星号 | 所有 | |
| {}花括号 | 输出序列,与echo,touch,mkdir使用 | |
| [] | 参考正则 | |
| [!] | 取反 | |
| ? | 任意一个字符 |
3.1 {} 必会
[root@lnh ~]# echo {a..z} a b c d e f g h i j k l m n o p q r s t u v w x y z [root@lnh ~]# echo {01..10} 01 02 03 04 05 06 07 08 09 10 [root@lnh ~]# seq 1 3 10 1 4 7 10 [root@lnh ~]# echo {1..10..2} 1 3 5 7 9 [root@lnh ~]# touch oldboy.txt [root@lnh ~]# cp oldboy.txt{,.bak} [root@lnh ~]# ll total 0 -rw-r--r-- 1 root root 0 Dec 23 11:29 oldboy.txt -rw-r--r-- 1 root root 0 Dec 23 11:29 oldboy.txt.bak
3.2 ?
找出/bin目录下面命令,命令仅有2个字符组成. [root@lnh ~]# ls -l /bin/?? -rwxr-xr-x. 1 root root 52640 Mar 24 2022 /bin/ab -rwxr-xr-x. 1 root root 62680 Oct 2 2020 /bin/ar -rwxr-xr-x. 1 root root 386424 Oct 2 2020 /bin/as -rwxr-xr-x. 1 root root 83424 Jun 10 2014 /bin/bc
二、正则表达式与grep
1.正则概述
正则表达式: regular expression regexp
用于给linux三剑客,程序语言使用
使用正则表达式对字符进行过滤,使用三剑客实现日志的过滤
正则表达式本质式一些符号:^ $ ^$. * .* [] [^] | () + {} ? .
正则符号都是英文符号,避免使用中文符号
推荐使用grep/egrep命令,默认设置了别名,自动加上颜色
http://nbre.oldboylinux.cn/playground
2.正则与通配符区别
| 区别 | 用途 | 支持的命令不同 |
|---|---|---|
| 正则 | 匹配文件内容(匹配字符) | 三剑客支持,开发语言 |
| 通配符 | 匹配文件名(命令参数) | Linux大部分命令都支持 |
3.正则分类
| 分类 | 符号 | |
|---|---|---|
| 基础正则BRE(basic RE) | ^ $ ^$. * .* [] [^] | |
| 扩展正则ERE(Extended RE) | | () + {} ? |
4.基础正则
三剑客默认支持的正则
环境准备:
cat >/oldboy/re.txt <<EOF I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http:oldboy.blog.51cto.com our size is http:blog.oldboyedu.com my qq is 49000448 not 4900000448. my god ,i am not oldbey,but OLDBOY! EOF
4.1 ^ 以什么开头的行
#以m开头的行 [root@lnh oldboy]# grep '^m' re.txt my blog is http://oldboy.blog.51cto.com my qq is 49000448 my god ,i am not oldbey,but OLDBOY!
4.2 $ 以什么结尾的行
#以数字8结尾的行 [root@lnh oldboy]# grep '8$' re.txt my qq is 49000448
cat -A 显示出文件中的特殊的隐藏符号
[root@lnh oldboy]# cat -A re.txt I am oldboy teacher!$ I teach linux.$ $ I like badminton ball ,billiard ball and chinese chess!$ my blog is http://oldboy.blog.51cto.com $ our size is http://blog.oldboyedu.com $ $ my qq is 49000448$ not 4900000448.$ $ my god ,i am not oldbey,but OLDBOY!$
4.3 ^$ 空行,这行中没有任何字符
#过滤出文件中的空行并显示行号 [root@lnh oldboy]# grep -n '^$' re.txt 3: 7: 10: #排除空行 [root@lnh oldboy]# grep -nv '^$' re.txt 1:I am oldboy teacher! 2:I teach linux. 4:I like badminton ball ,billiard ball and chinese chess! 5:my blog is http://oldboy.blog.51cto.com 6:our size is http://blog.oldboyedu.com 8:my qq is 49000448 9:not 4900000448. 11:my god ,i am not oldbey,but OLDBOY! #正则案例:排除/etc/ssh/sshd_config文件中的空行,然后排除以#号开头的行(可以使用管道) [root@lnh oldboy]# grep -v '^$' /etc/ssh/sshd_config |grep -v '^#' HostKey /etc/ssh/ssh_host_rsa_key HostKey /etc/ssh/ssh_host_ecdsa_key HostKey /etc/ssh/ssh_host_ed25519_key SyslogFacility AUTHPRIV AuthorizedKeysFile .ssh/authorized_keys PasswordAuthentication yes ChallengeResponseAuthentication no GSSAPIAuthentication yes GSSAPICleanupCredentials no UsePAM yes X11Forwarding yes AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE AcceptEnv XMODIFIERS Subsystem sftp /usr/libexec/openssh/sftp-server
4.4 . 任意一个字符,不匹配空行
[root@lnh oldboy]# grep '.$' re.txt I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com my qq is 49000448 not 4900000448. my god ,i am not oldbey,but OLDBOY!
4.5 \撬棍 转义字符,脱掉马甲打回原形,去掉特殊符号的含义
#找出文件中以.(点)结尾的行 [root@lnh oldboy]# grep '\.$' re.txt I teach linux. not 4900000448.
4.6 * 前一个字符连续出现0次或0次以上
[root@lnh oldboy]# grep '0*' re.txt I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com my qq is 49000448 not 4900000448. my god ,i am not oldbey,but OLDBOY!
4.7 .* 所有,任何字符
- . 任意一个字符
- * 前一个字符连续出现0次或0次以上
- .* 表示所有
#以任意内容开头直到匹配到am字符的行 [root@lnh oldboy]# grep '^.*am' re.txt I am oldboy teacher! my god ,i am not oldbey,but OLDBOY!
补充:贪婪性
正则表示连续出现的时候或者表示所有的是后续,正则体现出贪婪性,尽可能多的匹配
#匹配开头一直到o的内容 [root@lnh oldboy]# grep '.*o' re.txt I am oldboy teacher! I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com not 4900000448. my god ,i am not oldbey,but OLDBOY!
4.8 [] [abc] 表示匹配任意1个字符,a或b或c,中括号相当于一个字符
[root@lnh oldboy]# grep '[abc]' re.txt I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com my god ,i am not oldbey,but OLDBOY! #匹配数字 [root@lnh oldboy]# grep '[0-9]' re.txt #匹配大小写字母 [root@lnh oldboy]# grep '[a-Z]' re.txt #匹配大小写字母和数字 [root@lnh oldboy]# grep '[0-Z]' re.txt #匹配出以字母m或n开头的行 [root@lnh oldboy]# grep '^[mn]' re.txt my blog is http://oldboy.blog.51cto.com my qq is 49000448 not 4900000448. my god ,i am not oldbey,but OLDBOY! #匹配出以.或空格或!结尾的行 [root@lnh oldboy]# grep '[. !]$' re.txt I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com not 4900000448. my god ,i am not oldbey,but OLDBOY!
提示:
[] 中会自动去掉符号的特殊含义
4.9 [^] [^abc] 表示匹配任意1个字符,排除abc,中括号相当于一个字符
[root@lnh oldboy]# grep '[^abc]' re.txt I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com my qq is 49000448 not 4900000448. my god ,i am not oldbey,but OLDBOY!
grep -w 精确匹配
[root@lnh ~]# cat num.txt 22 333344422 2222 222222 [root@lnh ~]# grep '22' num.txt 22 333344422 2222 222222 [root@lnh ~]# grep -w '22' num.txt 22
小结:
| 基础正则 | 含义 | |
|---|---|---|
| ^ | 以什么开头 | |
| $ | 以什么结尾 | |
| ^$ | 空行 | |
| . | 任意一个字符 | |
| \ | 转义字符,撬棍 | |
| * | 前一个字符出现0次或0次以上 | |
| .* | 所有 | |
| [] | [abc]a或b或c | |
| [^] | [^abc]匹配除了abc之外的内容 |
5.扩展正则
Linux三剑客如何支持扩展正则
#grep egrep '0+' re.txt grep -E '0+' re.txt grep '0\+' re.txt #sed 需要使用-r选项 #awk 直接支持扩展正则
5.1 + 前一个字符连续出现1次或1次以上
#取出连续出现的0 [root@lnh oldboy]# egrep '0+' re.txt my qq is 49000448 not 4900000448. #取出连续出现的数字 [root@lnh oldboy]# egrep '[0-9]+' re.txt my blog is http://oldboy.blog.51cto.com my qq is 49000448 not 4900000448. #取出连续出现的字母(单词) [root@lnh oldboy]# egrep '[a-Z]+' re.txt I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com my qq is 49000448 not 4900000448. my god ,i am not oldbey,but OLDBOY! #案例: 统计re.txt文件中每个单词的出现次数. [root@lnh oldboy]# egrep -o '[a-Z]+' re.txt |sort|uniq -c |sort -rn|head 3 my 3 is 3 I 3 blog 2 oldboy 2 not 2 http 2 com 2 ball 2 am
5.2 | 或者
#文件中包含oldboy或linux的行 [root@lnh oldboy]# egrep 'oldboy|linux' re.txt I am oldboy teacher! I teach linux. my blog is http://oldboy.blog.51cto.com our size is http://blog.oldboyedu.com #在/etc/services过滤出包含ssh或http或smtp的行 [root@lnh oldboy]# egrep 'ssh|http|smtp' /etc/services # http://www.iana.org/assignments/port-numbers ssh 22/tcp # The Secure Shell (SSH) Protocol ssh 22/udp # The Secure Shell (SSH) Protocol smtp 25/tcp mail smtp 25/udp mail #排除/etc/ssh/sshd_config中的空行或注释,输出的时候显示行号 [root@lnh oldboy]# grep -v '^$' /etc/ssh/sshd_config |grep -v '^#' [root@lnh oldboy]# egrep -nv '^$|^#' /etc/ssh/sshd_config #一些配置文件中有空行,以#开头的行,不带注释的正常的行以字母开头的行 [root@lnh oldboy]# grep '^[a-Z]' /etc/ssh/sshd_config
5.3 () 表示一个整体 ,用于表示后向引用
#检查系统中tree,vim,sl软件是否安装. [root@lnh oldboy]# rpm -qa |egrep '^(tree|vim|sl)' tree-1.6.0-10.el7.x86_64 slang-2.2.4-11.el7.x86_64 vim-minimal-7.4.629-7.el7.x86_64 vim-common-7.4.629-8.el7_9.x86_64 vim-filesystem-7.4.629-8.el7_9.x86_64 vim-enhanced-7.4.629-8.el7_9.x86_64 sl-5.02-1.el7.x86_64
5.4 {} a{n,m} 前一个字符连续出现至少n次,最多m次
| 格式 | 应用 | |
|---|---|---|
| a{n,m} 前一个字符连续出现至少n次,最多m次 | 表示连续出现的范围 | |
| a{n} 前一个字符连续出现n次 | 匹配固定的次数 | |
| a{n,} 前一个字符连续出现至少n次 | ||
| a{,m} 前一个字符出现最多m次 |
[root@lnh oldboy]# egrep '0{1,5}' re.txt my qq is 49000448 not 4900000448. [root@lnh oldboy]# egrep -o '0{2,3}' re.txt 000 000 00
#匹配身份证的正则 18位 数字或X X在最后一位 [root@lnh oldboy]# cat id.txt 谈媚轩 230189199012251659 庾菲刚 23018199012015108 桑春 23018215507074953 范惠融 230182197510240695 霍莎 23018219590413055X 单燕可 230182197007233320 雷聪 23018215709180586 郑芬澜 23018199402088233 阙宁茜 230182198305100379 赵璧桂 23018195312204747 史勤 23018218107207651 项珠 230182195305221943 季艳盛 230182195604045725 吕进 230182196412284021 翟竹静 230182196102271858 翟竹静 23018219610227 翟竹静 2301821922 翟竹静 230181922 [root@lnh oldboy]# egrep '[0-9]{17}[0-9X]$' id.txt 谈媚轩 230189199012251659 范惠融 230182197510240695 霍莎 23018219590413055X 单燕可 230182197007233320 阙宁茜 230182198305100379 项珠 230182195305221943 季艳盛 230182195604045725 吕进 230182196412284021 翟竹静 230182196102271858
#匹配ip的正则 #创建环境 [root@lnh oldboy]# echo 10.0.0.{1..254} |xargs -n1 > ip.txt [root@lnh oldboy]# egrep '[0-9]{1,3}$' ip.txt
5.5 ? 前一个字符 出现0次或1次
一般用于匹配的内容可能有(出现1次)或者没有出现(出现0次)
[root@lnh oldboy]# cat good.txt gd goood god good [root@lnh oldboy]# egrep 'go?d' good.txt gd god
小结
| 扩展正则 | 含义 | |
|---|---|---|
| + | 前一个字符连续出现1次或多次 | |
| | | 或者 | |
| () | 表示整体, 后向引用或反向引用 | |
| {} | a{n,m} 前一个字符连续出现至少n次,最多m次 | |
| ? | 前一个字符出现0次或1次 |
6.perl语言正则表达式
| 符号 | 含义 | |
|---|---|---|
| \d | digit 数字 [0-9] | |
| \s | 匹配的空字符 空格 tab 等等 | |
| \w | word 数字,字母[0-9a-zA-Z_] | |
| \D | [^0-9] 排除数字 | |
| \S | 非空字符 | |
| \W | 排除数字,大小写字母和_ |
[root@lnh ~]# grep -P '\d' /oldboy/re.txt my blog is http:oldboy.blog.51cto.com my qq is 49000448 not 4900000448.
7. 零碎的正则 括号表达式 了解
[root@lnh ~]# grep '[[:alnum:]]' /oldboy/re.txt I am oldboy teacher! I teach linux. I like badminton ball ,billiard ball and chinese chess! my blog is http:oldboy.blog.51cto.com our size is http:blog.oldboyedu.com my qq is 49000448 not 4900000448. my god ,i am not oldbey,but OLDBOY!
三、 sed命令
1.概述
核心功能:取行、过滤、替换修改文件内容
后向引用(截取)
sed stream editor 流编辑器
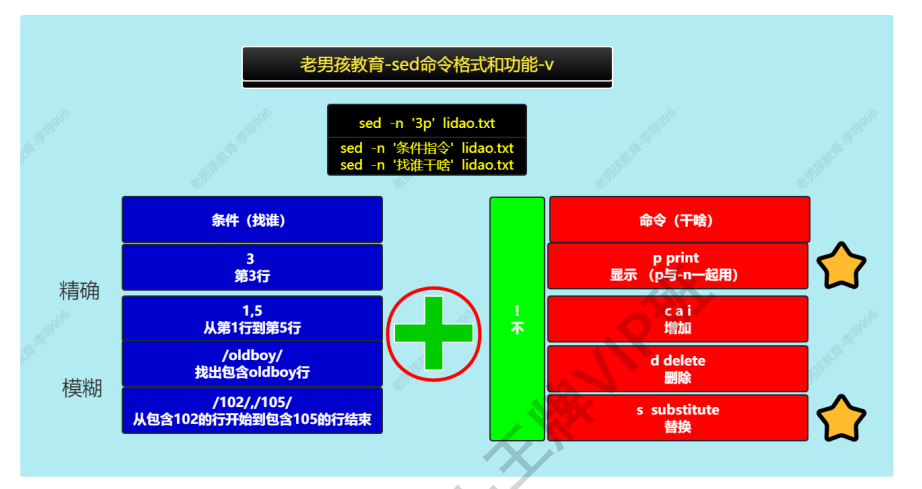
2.格式
| 命令 | 选项 | 详细格式 | 参数 |
|---|---|---|---|
| sed | 选项 | '条件动作' <br / 条件,匹配哪一行,哪些行 |
文件 |
| '找谁干啥' 动作,增删改查 |
| 选项 | 说明 | |
|---|---|---|
| -n | 取消默认输出 | |
| -r | sed支持扩展正则 | |
| -i | 修改文件内容,这个选项放在最后 | |
| -i.bak | 先进行备份,然后修改文件内容 |
3.sed 如何运行
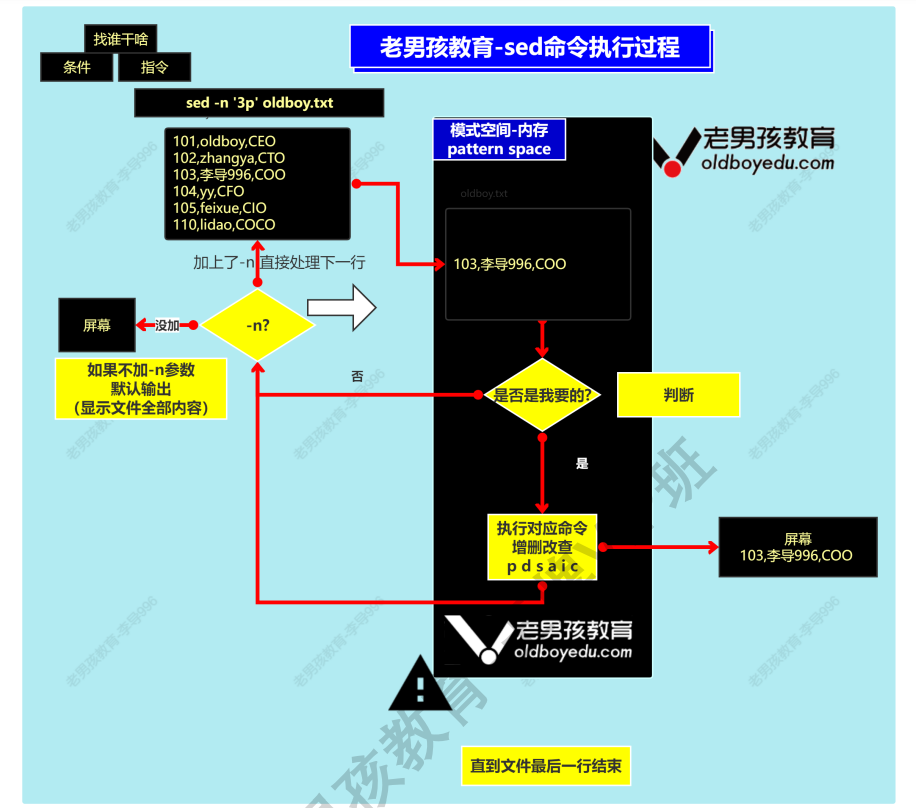
4.sed增删改查---查找
一种是类似于grep的模糊查找
一种是精确查找,行号
#取出文件的第3行 [root@lnh ~]# sed -n '3p' passwd daemon:x:2:2:daemon:/sbin:/sbin/nologin -n表示取消默认输出,sed处理文件的时候会默认的输出每一行内容 #取出/etc/passwd的第2行到第5行 [root@lnh ~]# sed -n '2,5p' passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin #过滤出/etc/passwd中包含root的行 [root@lnh ~]# sed -n '/root/p' passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin
sed进行过滤的时候需要使用 // 并且支持基础正则
如果需要使用扩展正则则需要sed -r 选项
#获取范围内的日志 cat >/oldboy/sed.txt<<EOF 101,oldboy,CEO 102,bigbao,CTO 103,李导996,COO 104,yy,CFO 105,feixue,CIO 110,lidao,COCO EOF [root@lnh ~]# sed -n '/102/,/105/p' /oldboy/sed.txt 102,bigbao,CTO 103,李导996,COO 104,yy,CFO 105,feixue,CIO sed -n '/从哪里来/,/到哪里去/p' sed.txt
#只显示第3行和第5行 [root@lnh ~]# sed -n '1p;5p' /etc/passwd root:x:0:0:root:/root:/bin/bash lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin #有规律的查找 [root@lnh ~]# seq 10 |sed -n '1~2p' #从1开始,每次增加2行 1 3 5 7 9
5.sed增删改查---修改(替换)
#把sed.txt文件中lidao替换为oldboy [root@lnh ~]# cd /oldboy/ [root@lnh oldboy]# cat sed.txt 101,oldboy,CEO 102,bigbao,CTO 103,李导996,COO 104,yy,CFO 105,feixue,CIO 110,lidao,COCO [root@lnh oldboy]# sed 's#lidao#oldboy#g' sed.txt 101,oldboy,CEO 102,bigbao,CTO 103,李导996,COO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO [root@lnh oldboy]# sed 's#[0-9]##g' sed.txt #全局替换 ,oldboy,CEO ,bigbao,CTO ,李导,COO ,yy,CFO ,feixue,CIO ,lidao,COCO [root@lnh oldboy]# sed 's#[0-9]##' sed.txt #非全局替换 01,oldboy,CEO 02,bigbao,CTO 03,李导996,COO 04,yy,CFO 05,feixue,CIO 10,lidao,COCO
sed命令替换格式说明:
sed 's#找谁#替换成什么#g' sed.txt
推荐使用:### @@@ ///
s substitute 替换
g global 全局替换,这一行中把所有匹配到的内容都进行替换,否则只替换每一行第1个
#修改文件内容 [root@lnh oldboy]# sed -i 's#lidao#oldboy#g' sed.txt [root@lnh oldboy]# cat sed.txt 101,oldboy,CEO 102,bigbao,CTO 103,李导996,COO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO -i 修改文件内容
#修改文件内容之前进行备份,然后修改文件内容 [root@lnh ~]# ll total 28 -rw------- 1 root root 2791 Dec 17 18:35 nohup.out -rw-r--r-- 1 root root 1262 Dec 26 19:20 passwd -rw-r--r-- 1 root root 90 Dec 27 14:42 sed.txt -rwxr-xr-x 1 root root 8648 Dec 15 10:04 zombine -rw-r--r-- 1 root root 591 Dec 15 09:56 zombine.c [root@lnh ~]# sed -i.bak 's#103#999#g' sed.txt [root@lnh ~]# ll total 32 -rw------- 1 root root 2791 Dec 17 18:35 nohup.out -rw-r--r-- 1 root root 1262 Dec 26 19:20 passwd -rw-r--r-- 1 root root 90 Dec 27 14:42 sed.txt -rw-r--r-- 1 root root 90 Dec 27 14:42 sed.txt.bak -rwxr-xr-x 1 root root 8648 Dec 15 10:04 zombine -rw-r--r-- 1 root root 591 Dec 15 09:56 zombine.c [root@lnh ~]# cat sed.txt 101,oldboy,CEO 102,bigbao,CTO 999,李导996,COO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO [root@lnh ~]# cat sed.txt.bak 101,oldboy,CEO 102,bigbao,CTO 103,李导996,COO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO 一般用于替换某一个文件,如果是多个文件就打包压缩进行备份即可
-i 一般放在sed命令最后
6.sed增删改查---替换进阶
6.1 后向引用格式
应用说明:
后向引用或反向引用:适用于sed命令处理/提取一行中的某一部分。sed命令配合正则实现取列
使用格式:
使用替换的形式 s###g
前2个#之间通过正则与(),对数据进行分组
后2个#之间通过\数字,去调用前面分组的内容
整体是后面调用前面分组的内容,称之为反向引用/后向引用
应用场景:
某一行中对部分数据进行加工与处理,提取某一部分的数据
6.2 基本使用
#输出12345678,通过sed加工变成1<234567>8 [root@lnh ~]# echo 12345678 |sed -r 's#(1)(.*)(8)#\1 <\2> \3#g' 1 <234567> 8 #调换/etc/passwd第1列和最后一列内容 [root@lnh ~]# sed -r 's#^(.*)(:.*:)(.*)$#\3\2\1#g' passwd /bin/bash:/root:root:x:0:0:root /sbin/nologin:/bin:bin:x:1:1:bin /sbin/nologin:/sbin:daemon:x:2:2:daemon /sbin/nologin:/var/adm:adm:x:3:4:adm #取出网卡ip地址 [root@lnh ~]# ip a s eth0 #ip address show eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 00:0c:29:72:55:cf brd ff:ff:ff:ff:ff:ff inet 10.0.0.200/24 brd 10.0.0.255 scope global noprefixroute eth0 valid_lft forever preferred_lft forever inet6 fe80::c78c:d46d:5579:381f/64 scope link noprefixroute valid_lft forever preferred_lft forever [root@lnh ~]# ip a s eth0 |sed -n '3p'|sed -r 's#^.*net (.*)/.*$#\1#g' 10.0.0.200 [root@lnh ~]# hostname -I |awk '{print $1}' 10.0.0.200 # 取出stat /etc/hosts中的0644或644 [root@lnh ~]# stat /etc/hosts |sed -n '4p'|sed -r 's#^.*\(([0-9]+)(/.*)$#\1#g' 0644 [root@lnh ~]# stat /etc/hosts |sed -n '4p'|sed -r 's#^.*\(0([0-9]+)(/.*)$#\1#g' 644 [root@lnh ~]# echo {1..9} |sed 's# [0-9] #<&>#g' <1> <2> <3> <4> <5> <6> <7> <8> <9>
7.增删改查---删除
d delete sed命令删除功能按照行为单位进行
如果仅仅删除某一行的一些字符,推荐使用's#[a-z]##g'
[root@lnh ~]# cat sed.txt 101,oldboy,CEO 102,bigbao,CTO 999,李导996,COO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO [root@lnh ~]# sed '3d' sed.txt 101,oldboy,CEO 102,bigbao,CTO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO #排除/删除文件中的空行和带注释的行 [root@lnh ~]# sed -r '/^$|^#/d' /etc/ssh/sshd_config HostKey /etc/ssh/ssh_host_rsa_key HostKey /etc/ssh/ssh_host_ecdsa_key HostKey /etc/ssh/ssh_host_ed25519_key SyslogFacility AUTHPRIV AuthorizedKeysFile .ssh/authorized_keys PasswordAuthentication yes ChallengeResponseAuthentication no GSSAPIAuthentication yes GSSAPICleanupCredentials no UsePAM yes X11Forwarding yes AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE AcceptEnv XMODIFIERS Subsystem sftp /usr/libexec/openssh/sftp-server [root@lnh ~]# sed -nr '/^$|^#/!p' /etc/ssh/sshd_config
8.增删改查---增加
cai:
a append 在指定的行后面追加内容
i insert 在指定的行上面插入一行
c replace 替换指定行的内容
[root@lnh ~]# cat sed.txt 101,oldboy,CEO 102,bigbao,CTO 999,李导996,COO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO [root@lnh ~]# sed '3a hahahaha' sed.txt 101,oldboy,CEO 102,bigbao,CTO 999,李导996,COO hahahaha 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO [root@lnh ~]# sed '3i hahahaha' sed.txt 101,oldboy,CEO 102,bigbao,CTO hahahaha 999,李导996,COO 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO [root@lnh ~]# sed '3c hahahaha' sed.txt 101,oldboy,CEO 102,bigbao,CTO hahahaha 104,yy,CFO 105,feixue,CIO 110,oldboy,COCO
四、awk命令
1.概述
| 四剑客 | 特点 | 擅长 |
|---|---|---|
| find | 查找文件 | 查找文件 |
| grep/egrep | 过滤 | 过滤速度最快 |
| sed | 过滤,取行,替换,删除 | 替换,修改文件内容,取行 |
| awk | 过滤,取行,取列,统计计算,判断,循环 | 取列,取行,统计计算 |
2.格式
awk 选项 '条件{动作}' 文件名
条件 找谁
动作 干啥
3.执行流程
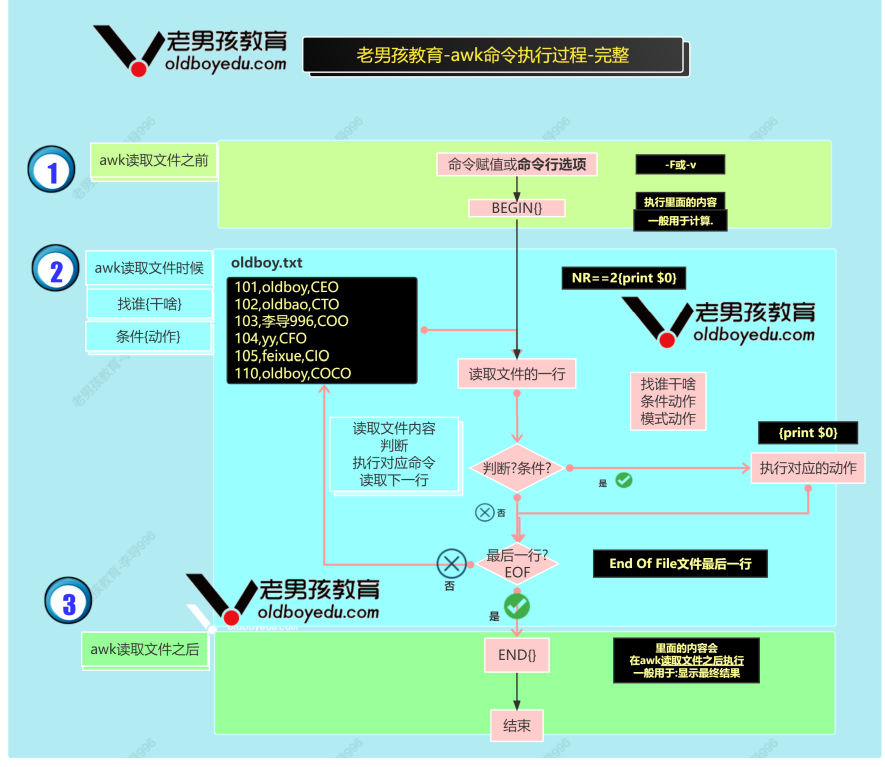
4.取行
#取出/etc/passwd的第1行 [root@lnh ~]# awk 'NR==1{print $0}' passwd root:x:0:0:root:/root:/bin/bash [root@lnh ~]# awk 'NR==1' passwd root:x:0:0:root:/root:/bin/bash #输出行号 [root@lnh ~]# awk 'NR==1{print NR,$0}' passwd
NR Number of Record 记录号,行号
== 表示等于
{print $0} 输出整行内容 $0 表示当前行的内容。 awk满足条件后默认的动作,输出这一行的内容
#取出第2行到第5行的内容 [root@lnh ~]# awk 'NR>=2 && NR<=5' passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
| awk常用的运算符 | 说明 | |
|---|---|---|
| == | 等于 | |
| != | 不等于 | |
| > | 大于 | |
| >= | 大于等于 | |
| < | 小于 | |
| <= | 小于等于 | |
| && | 并且 | |
| || | 或者 |
#过滤出/etc/passwd文件中包含root或nobody的行 [root@lnh ~]# awk '/root|nobody/' passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin #从包含root的行到包含nobody的行 [root@lnh ~]# awk '/root/ , /nobody/' passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin
5.取列
#使用awk取出ls -lh 的 大小列 和 最后一列 [root@lnh ~]# ll -h |awk '{print $5,$9}' 60 blank.txt 2.1K datafile 551 df.txt 477 fstab 2.8K nohup.out 1.3K passwd 93 sed.txt 90 sed.txt.bak 145 shouji.txt 8.5K zombine 591 zombine.c [root@lnh ~]# ll -h |awk '{print $5"\t"$9}' 60 blank.txt 2.1K datafile 551 df.txt 477 fstab 2.8K nohup.out 1.3K passwd 93 sed.txt 90 sed.txt.bak 145 shouji.txt 8.5K zombine 591 zombine.c [root@lnh ~]# ll -h |awk '{print $5,$9}'|column -t 60 blank.txt 2.1K datafile 551 df.txt 477 fstab 2.8K nohup.out 1.3K passwd 93 sed.txt 90 sed.txt.bak 145 shouji.txt 8.5K zombine 591 zombine.c
awk取列说明:
$数字,表示取列
$NF 最后一列
NF Number of Field 每行有多少列
$(NF-1) 取出倒数第2列
awk 输出与对齐
使用column 命令或者使用\t
#取出/etc/passwd中的第1列,第3列和最后一列 [root@lnh ~]# awk -F ':' '{print $1,$3,$NF}' passwd |column -t root 0 /bin/bash bin 1 /sbin/nologin daemon 2 /sbin/nologin adm 3 /sbin/nologin lp 4 /sbin/nologin sync 5 /bin/sync shutdown 6 /sbin/shutdown #指定复杂分隔符取出ip [root@lnh ~]# ip a s eth0|awk 'NR==3'|awk -F '[ /]+' '{print $3}' 10.0.0.200 inet前面有4个空格,所以正则要有加号
6.取行取列
#取行+取列 取ip地址 [root@lnh ~]# ip a s eth0|awk -F '[ /]+' 'NR==3{print $3}' 10.0.0.200 #取出权限部分 stat /etc/hosts的0644部分 [root@lnh ~]# stat /etc/hosts|awk -F '[(/]' 'NR==4{print $2}' 0644 #取出/etc/passwd文件中第3列大于大于1000的行,取出这行的第1列,第3列和最后一列 [root@lnh ~]# awk -F ':' '$3>1000{print $1,$3,$NF}' passwd #如果系统swap使用超过0则输出"异常系统开始占用swap" [root@lnh ~]# free |awk 'NR==3 && $3==0 {print "swap占用,系统异常,请尽快排查"}' swap占用,系统异常,请尽快排查 #过滤出/etc/passwd第4列的数字是以0或1开头的行,输出第1列,第4列,最后一列 [root@lnh ~]# awk -F ':' '$4 ~ /^[01]/ {print $1,$4,$NF}' passwd |column -t root 0 /bin/bash bin 1 /sbin/nologin sync 0 /bin/sync shutdown 0 /sbin/shutdown halt 0 /sbin/halt mail 12 /sbin/nologin operator 0 /sbin/nologin games 100 /sbin/nologin systemd-network 192 /sbin/nologin abrt 173 /sbin/nologin mysql 1314 /sbin/nologin oldboy 1315 /bin/bash
提示: awk 中,通过~可以实现对某一列进行过滤
某一列中含有XXXX内容
- ~ 表示包含的意思 $1 ~ /root/ 表示第1列中包含root
- !~ 表示不包含
7.awk 统计与计算
awk进行统计有2类案例
- 类似于 wc -l统计次数
- 进行求和,累加
7.1 统计次数
i=i+1 先计算i+1然后把结果存放到i中 i=i+1 i值 i=i+1值 i计算后的内容 第1行 空/0 i=0+1 i=1 第2行 1 i=1+1 i=2 第3行 2 i=2+1 i=3 [root@lnh ~]# awk '{i=i+1}END{print i}' passwd 27 [root@lnh ~]# awk '{i++}END{print i}' passwd 27
END{} 内容会在awk读取完成文件的时候执行
END{} 一般用于输出执行结果
i=i+1 ==== i++
7.2 计算总和
i=i+$1 $1 i i=i+$1 i结果 第1行 1 空 i=0+1 i=1 第2行 2 1 i=1+2 i=3 第3行 3 3 i=3+3 i=6 第4行 4 6 i=6+4 i=10 [root@lnh ~]# seq 10 |awk '{sum=sum+$1}END{print sum}' 55 i=i+$1 === i+=$1
本文作者:wh459086748
本文链接:https://www.cnblogs.com/world-of-yuan/p/17013588.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步