读书笔记:CSAPP 11章 网络编程
深入理解计算机系统 第11章
本章代码:Index of /afs/cs/academic/class/15213-f15/www/code/22-netprog2
其中包含本章课本示例代码,测试 Tiny Web 服务器所需的所有内容,包括示例 HTML 文件、GIFS、CGI 脚本以及 csapp.c 和 csapp.h 文件需要 在 Linux 机器上编译和测试。
视频:【精校中英字幕】2015 CMU 15-213 CSAPP 深入理解计算机系统 课程视频
课件:11.1-11.4 11.5-11.6
1 客户端-服务器编程模型
网络应用都是基于客户端-服务器模型的,应用由一个服务器进程和一个或多个客户端进程组成,服务器会管理着某些资源,通过操作这些资源来为它的客户端提供某种服务。比如Web服务器管理着一组磁盘文件,会代替客户端进行检索和执行。该模型主要执行以下步骤:
- 当一个客户端需要服务时,就向服务器发送一个请求。比如Web浏览器需要一个文件时,就会发送一个请求到Web服务器。
- 服务器接收到请求后,会对其进行解释并以适当方式操作它的资源。比如当Web服务器接收到请求后,就读一个磁盘文件。
- 服务器给客户端发送一个响应,等待下一次请求。比如Web服务器将文件发送回客户端。
- 客户端接收到响应并进行处理。比如当Web浏览器收到来自服务器的数据后,就将其显示在屏幕上。

注意:所谓的客户端和服务器是进程,而不是机器或主机。
2 网络基础
2.1 网络
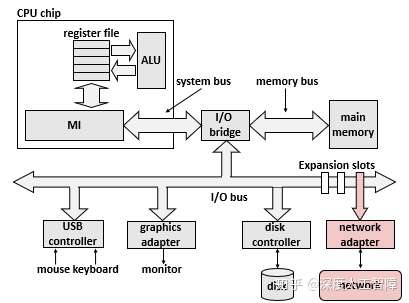
当客户端进程和服务器进程处于不同主机时,两个进程就需要通过计算机网络的硬件和软件资源进行通信。对主机而言,计算机网络其实只是一个I/O设备,通过插在I/O总线扩展槽的适配器提供到网络的物理接口,从网络接收到的数据从适配器经过I/O总线和内存总线复制到内存,而数据也可以从内存复制到网络。
网络是具有层次结构的,最底层的是局域网(Local Area Network,LAN),通常是在一个较小范围内构成的网络,比如一个建筑物,而最流行的局域网技术是以太网(Ethernet)。
层次一:一个以太网段(Ethernet Segment)由一些电缆和一个集线器组成,通常跨越一些更小的区域,比如一个房间。电缆的一段连接着主机的适配器,另一端连接到集线器的某个端口,这些电缆通常具有相同的最大位带宽。当主机通过适配器发送数据时,集线器会从一个端口中接收到并将其广播到其他端口,所以其他连接到相同适配器的主机也会收到这些数据。
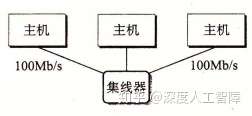
为了标识每个主机,为每个以太网适配器都提供一个唯一的48位地址,保存在适配器的非易失性存储器上,称为MAC地址。所以当主机发送数据时,可以在数据的头部(Header)包含标识该数据的源和目的地址以及数据长度的信息,随后才是放数据的有效载荷(Payload),由此构成一个数据帧(Data Frame)进行传输,这样连接到相同集线器的其他主机就能通过这个数据的头部来判断该数据是不是传输给自己的。
层次二:我们可以通过电缆将一些集线器连接到网桥(Bridge),并通过电缆将一些网桥连接起来,得到更大的局域网,称为桥接以太网(Bridge Ethernet),这两种电缆通常具有不同的带宽。
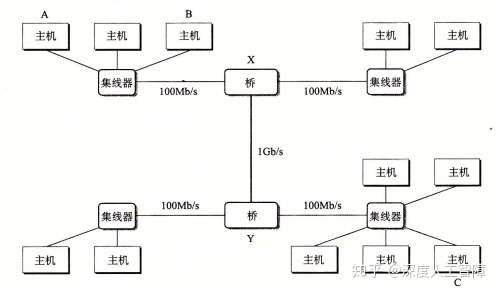
相比集线器不加区分地广播数据,网桥会使用更好的分配算法,它会自动学习哪些主机通过哪些端口是可达的,并将对应的数据传到对应的端口,节约了其余端口的带宽。比如主机A想传递数据到处于同一以太网段的主机B,则集线器会接收到该数据并广播到所有端口,此时网桥X也会接收到该数据,但是它判断该数据的目和源处于相同以太网段,所以就不进行转发。再比如主机想传递数据到不同以太网段的主机C,则网桥X和网桥Y会将其传递到合适的端口进行转发,使其最终到达主机C。
层次三:通过以上两个层次可以构建出若干个互不兼容的局域网,这些局域网可以通过路由器(Router)这一 特殊计算器相连组成internet,每台路由器对它连接到的每个网络都有一个适配器。而路由器之间可以通过广域网(Wide-Area Network,WAN)相连,来跨越更大的地理范围。

主机(适配器)-->以太网段(集线器)-->桥接以太网(网桥)-->internet(路由器)
可以发现,internet是由采用不同和不兼容技术的各种局域网和广域网构成的,为了消除不同网络之间的差异,需要在每台主机和路由器上运行协议软件,来控制主机和路由器如何协同工作来实现数据传输。该协议具有两个基本功能:
- 命名机制:在各个局域网中,由于主机数目较少,可以通过集线器直接广播主机的MAC地址或通过网桥记录一些主机MAC地址对应的端口,就能实现主机之间的数据传输。但是到了路由器层面时,主机数目变得特别多,直接广播MAC地址不现实,而记录各个主机MAC地址对应的端口时,由于MAC地址都是各个主机唯一且不具有地域性,就需要一张特别大的表来进行记录。但其实同一局域网的主机具有一定的地域性,都连接在路由器的一个端口,所以路由器其实只需要记录局域网对应的端口就行。所以如果我们能为主机分配唯一的具有地域性的地址时,能通过该主机地址得知对应的局域网就能在路由器中确定对应的端口,就能大量减轻了路由器记录的负担。该地址称为IP地址。
- 传送机制:在不同层面上传输数据需要不同的地址,比如在局域网中需要通过MAC地址来确定目标主机,而在internet中需要通过IP地址确定路由器的端口。所以互联网协议需要在数据最外侧添加路由器的MAC地址,来使得数据能先传输到路由器,然后内侧再添加IP地址,使得路由器能确定端口。IP地址和数据构成了数据报(Datagram)。
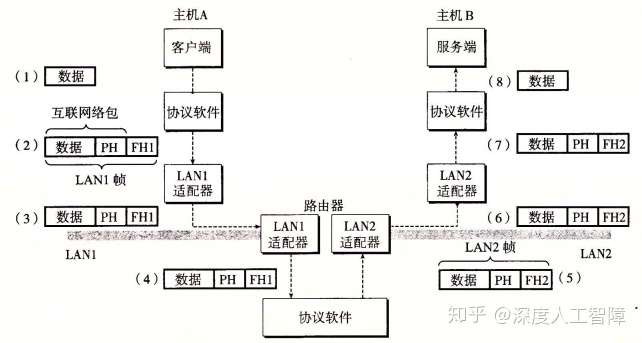 PH:包头,FH:帧头
PH:包头,FH:帧头
以上面为例,说明如何从主机A传输数据到主机B
- 运行在主机A中的客户端通过系统调用,从客户端的虚拟地址空间复制数据到内核缓冲区中。
- 主机A上的协议软件在数据前添加数据帧头
FH1和数据包头PH,其中FH1中记录了路由器1的MAC地址,PH记录了主机B的IP地址。主机A将该数据帧传输到自己的适配器上。 - LAN 1根据帧头中记录的MAC地址,对其进行广播和转发。
- 路由器1的适配器会接收到该数据帧,并将其传送到协议软件。
- 协议软件从中剥离掉帧头
FH1,获得PH中记录的主机B的IP地址,就能将其作为路由器表的索引获得要将其转发到路由器的哪个端口。这里是将其转发到传输到路由器2的端口。 - 当路由器2获得该数据包时,可以从一个表中得知该IP地址对应的MAC地址,即主机B的MAC地址,就将将其再次封装成数据帧的形式,通过适配器将其传输到LAN 2中。
- 在LAN 2根据帧头中记录的MAC地址,对其进行广播和转发。
- 当主机B接收到该数据帧时,将其传送到协议软件中。
- 在协议软件中,判断数据帧头中记录的目的MAC地址是否与自己的MAC地址相同,发现是相同的,则会剥离包头和帧头获得数据。当服务器进行一个读取这些数据的系统调用时,就将其复制到服务器的虚拟地址空间中。
2.2 全球IP因特网
每台主机都运行实现TCP/IP协议,它是一个协议族,其中每个都提供了不同的功能。比如IP协议提供了上文介绍的基本的命名方法和传送机制,由此保证了能从一台主机向别的主机发送数据报,但是这种传送机制是不可靠的,因为如果数据报发生丢失,IP协议并不会试图恢复。而基于IP协议提出了UDP协议和TCP协议,由此保证了包可以在进程之间而不是主机之间进行传送。而客户端-服务器应用程序就正需要TCP/IP协议这种在进程间传送数据的能力,它们通过套接字接口函数系统调用,在内核中调用各种内核模式的TCP/IP函数,由此在客户端进程和服务器进程之间传送数据。
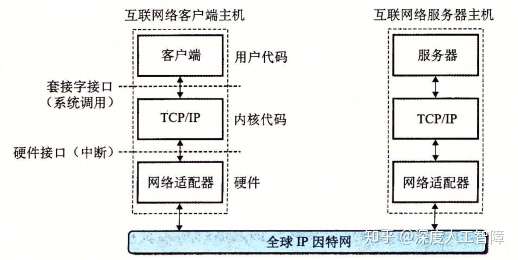
我们这里就间TCP/IP看成一个单独的整体协议,值讨论TCP和IP为应用程序提供的某些功能。我们可以将因特网看成是一个世界范围的主机集合,满足以下特点:
- 主机集合被映射为一组32位的IP地址。
- 这组IP地址被映射为一组称为因特网域名(Internet Domain Name)的标识符。
- 因特网主机上的进程能通过连接(Connection)和任何其他因特网主机上的进程通信。
2.2.1 IP地址
IP地址是一个32位的无符号整数,具有以下数据结构

我们知道不同主机可以有不同的主机字节顺序,常用的是小端法,而TCP/IP为任意整数定义了统一的网络字节顺序(Network Byte Order),来规定IP地址的字节顺序(总是大端法)。Unix提供了以下函数来进行转换

htonl函数是将32位整数由主机字节顺序转换为网络字节顺序;ntohl函数是将32位整数由网络字节顺序转换为主机字节顺序。
IP地址通常用点分十进制表示法来表示,每个字节由它对应的十进制数来表示,而不用数之间通过.间隔,由于IP地址为32位的,所以会有4个整数。这里提供以下函数来实现IP地址和点分十进制串之间的转换

inet_pton函数将一个点分十进制串src转换为二进制的网络字节顺序的IP地址,其中AF_INET表示32位的IPv4地址,而AF_INET6表示64位的IPv6地址。inet_ntop函数将二进制的网络字节顺序的IP地址src转换为对应的点分十进制表示。
在1996年IETF推出了具有128位地址的IPv6,打算作为IPv4的后继者,截至2015年,绝大多数互联网流量仍由IPv4承载,只有4%的用户使用IPv6访问Google服务。我们将主要介绍IPv4,但会展示如何编写独立于协议的网络代码。
2.2.2 域名
由于IP地址较难记忆,所以定义了一组域名(Domain Name)以及一种将域名映射到实际IP地址的机制。域名的集合形成一种层次结构,每个域名编码了它在这个层次中的位置。
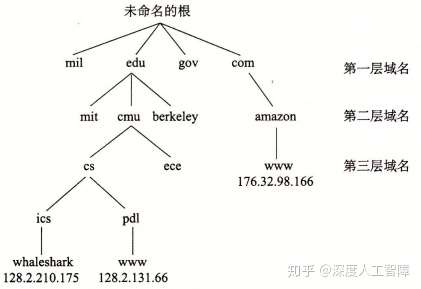
根节点为未命名的根,第一层为一级域名(First-level Domain Name),由ICANN组织定义,再下一层为二级域名(Second-level Domain Name),由ICANN的各个授权代理按照先到先得服务进行分配的,只要有组织得到二级域名,就能在这个子域中创建任何新的域名。从叶子结点返回到一级域名的路径就构成了一条完整的域名,通过非常大的分布式域名系统(Domain Name System,DNS)将其映射到对应的IP地址。
每台主机都有本地定义的域名localhost,总是映射为回送地址(Loopback Address)127.0.0.1。hostname可以确定本地主机的实际域名,然后可以通过nslookup程序来查看DNS映射的一些属性,可以发现通常多个域名可以映射到同一组的多个IP地址,而有些合法的域名没有映射到任何IP地址。
注意:存在多个域名对应一个IP地址,或一个域名对应多个IP地址,因为一些大型网络不止有一台服务器,可能会有多台服务器在处理你的数据,所以DNS会根据你的显示位置来返回多个IP地址。
2.2.3 因特网连接
客户端和服务器通过在连接上发送和接收数据来进行通信,连接具有以下特点:
- 点对点:连接了一对进程
- 全双工:数据可以同时在连接双向流动
- 可靠的:由源进程发出的字节流最终被目的进程按序接收
连接的两端分别是客户端套接字和服务器套接字,每个套接字都有相应的套接字地址,由IP地址和16位整数端口组成,表示为地址:端口。其中客户端套接字中的端口是由内核自动分配的临时端口(Ephemeral Port),而服务器套接字的端口与服务器提供的服务相关,比如Web服务器就使用端口80、FTP服务器就是用端口25,可通过/etc/services查看。

所以一个连接由它两端的套接字地址唯一确定,称为套接字对(Socket Pair),表示为(cliaddr:cliport, servaddr:servport)。

通常内核需要区分传入机器的不同连接,并且当别的机器的数据到达时,判断要为该连接启动什么软件和进程,实际上,每个端口都有特定的进程执行程序来处理这些请求。并且一个客户端可以同时和单一服务器上的不同端口通信,来获得该服务器的不同服务,但这需要建立不同的连接,避免相互干扰。
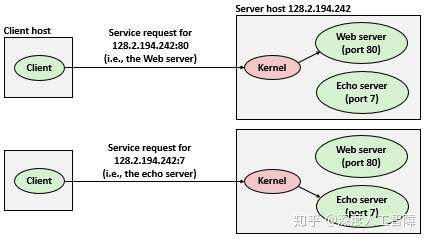
注意:对Linux内核而言,套接字就是通信的一个端点。对程序员而言,套接字就是一个有相应描述符的打开文件(与上一章关联起来,Linux中将所有资源都视为文件,套接字也不例外)。
3 套接字接口
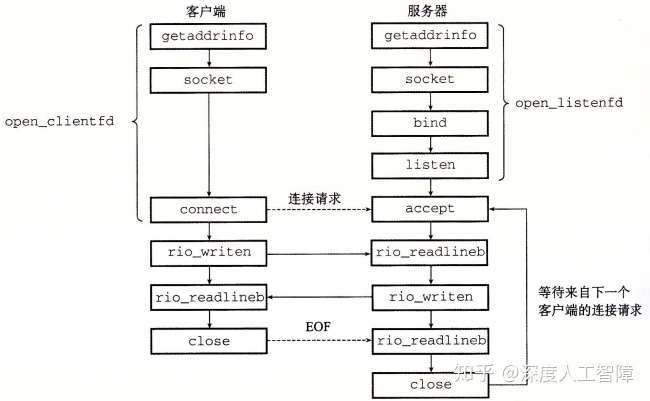
套接字接口(Socket Interface)是一组函数,他们和Unix I/O函数结合起来,用以创建网络应用。以下是一个基于套接字接口的网络应用概述
3.1 套接字地址结构
套接字地址具有以下两种数据结构

这是因为在一开始设计socket时,是打算兼容各种不同协议的套接字地址,而不同协议的套接字地址有自己不同的地址构造,比如IPv4就是sockaddr_in、IPv6就是sockaddr_in6等等,而sockaddr就是这些不同协议地址的抽象,仔细观察上面两个不同结构的声明顺序,两者定义的内存分布如下所示

这样通过将sockaddr_in强制类型转换为sockaddr时,sockaddr的sa_family值就是 sockaddr_in的sa_family值,而sockaddr的sa_data值就是sockaddr_in中sin_port、sin_addr和sin_zero拼接起来的结果。由此通过将不同协议的地址强制类型转换为sockaddr类型,就能得到统一的套接字地址,而后的函数都是基于sockaddr类型的,方便兼容不同协议的地址。
注意:这些地址字节顺序都是网络字节顺序,即大端法。
参考:ustcsse308:信息安全课程8:套接字(socket) 编程
3.2 常用函数
首先,套接字作为一种文件,我们需要在服务器和客户端将其打开来得到套接字描述符(Socket Descriptor)
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
为了使套接字作为连接的端点,可使用如下硬编码的参数来调用socket函数
socket(AF_INET, SOCK_STREAM, 0);
AF_INET表示是一个32位的IPv4地址,SOCK_STREAM表明连接是一个TCP连接。此时就会返回套接字描述符,客户端套接字描述符写成clientfd,服务器套接字描述符写成sockfd。
在服务器方面,接下来需要将服务器套接字地址和它的描述符sockfd联系起来
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
该内核函数会将服务器套接字描述符sockfd与服务器套接字地址addr关联起来,其中addrlen=sizeof(sockaddr_in),此时addr中包含了端口号,也就将sockfd与该服务器的某个端口绑定在一起,用于提供特定的服务。
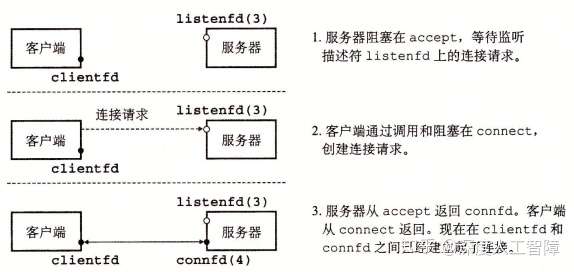
由于socket函数创建的是主动套接字描述符(Active Socket Descriptor),而服务器是接收请求方,所以需要将服务器套接字描述符转换为监听套接字描述符(Listening Socket Descriptor)
#include <sys/socket.h>
int listen(int sockfd, int backlog);
该函数会将服务器套接字的描述符sockfd转换为监听套接字描述符listenfd,也相当于高速内核当前为服务器。接下来服务器就能监听等待来自客户端的连接请求
#include <sys/socket.h>
int accept(int listenfd, struct sockaddr *addr, int *addrlen);
该函数会等待来自客户端的连接请求到达监听描述符listenfd,然后将客户端的套接字地址填写到addr中,并返回一个已连接描述符(Connected Descriptor)connfd,这样服务器就能通过connfd和Unix I/O来与客户端通信了。
注意:服务器通常只创建一次监听套接字描述符listenfd,并存在于服务器的整个生命周期,作为客户端连接请求的一个端点,服务器可从listenfd得知是否有客户端发送连接请求 ,而后服务器每次接受连接请求时就会创建一个已连接描述符connfd来作为与客户端建立起连接的一个端点,只存在于服务器为一个客户端服务的过程,当客户端不需要该服务器的服务时,就会删掉该connfd。这两种描述符的存在,使得我们可以构建并发的服务器来同时处理多个客户端连接,每当accept返回一个connfd时,就表示服务器接收了一个客户端的连接,此时就能通过fork函数创建一个子进程来通过该connfd与客户端通信,而父进程继续监听listenfd来查看是否有另一个客户端发送连接请求。
服务器方面:创建套接字描述符
sockfd(socket)-->将sockfd与服务器套接字地址进行关联(bind)-->将sockfd转换为监听套接字描述符listenfd(listen)-->等待客户端的连接请求,并得到已连接描述符connfd(accept)-->通过connfd和Unix I/O与客户端进行通信。
在客户端方面,在创建了客户端套接字描述符clientfd后,就能通过以下函数来建立与服务器的连接
#include <sys/socket.h>
int connect(int clientfd, const struct sockaddr *addr, socklen_t addrlen);
该函数会尝试与服务器套接字地址addr建立一个连接,其中addrlen=sizeof(sockaddr_in)。该函数会阻塞直到连接建立成功或发生错误,如果成功,客户端就能通过clientfd和Unix I/O与服务器进行通信了。
3.3 IP协议无关代码
Linux提供一些函数来实现二进制套接字地址结构和主机名、主机地址、服务名和端口号的字符串表示之间的相互转化,当与套接字接口一起使用时,能让我们编写独立于任何特定版本的IP协议的网络程序。
3.3.1 getaddrinfo函数
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
int getaddrinfo(const char *host, const char *service,
const struct addrinfo *hints,
const struct addrinfo **result);
void freeaddrinfo(struct addrinfo *result);
const char *gai_strerror(int errcode);
getaddrinfo函数能将主机名、主机地址、服务名和端口号的字符串转换成套接字地址结构。其中,host参数可以是域名、点分十进制数字地址或NULL,service参数可以是服务名(如http)、十进制端口号或NULL,两者必须制定一个。而hits和result参数分别是addinfo结构的指针和链表

result是通过host和service构建的一系列套接字地址结构,可以通过ai_next来一次遍历链表中的每个addrinfo结构,而每个addrinfo结构的ai_family、ai_socktype和ai_protocol可以直接传递给socket函数,而ai_addr和ai_addrlen可以直接传递给connect和bind函数,使得我们只要传递host和service参数给getaddrinfo函数,就能编写独立于某个特定版本的IP协议的客户端和服务器。
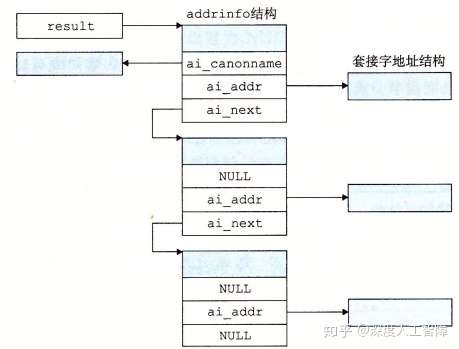
可以通过hits来控制result的结果。设置hits时,通常用memset将整个结构清空,再有选择地设置一些字段:
-
ai_family:result默认会包含IPv4和IPv6的套接字地址,可以通过设置ai_family为AF_INET或AF_INET6来限制只包含IPv4或IPv6的套接字地址。 -
ai_socktype:将其设置为SOCK_STREAM可以将result限制为每个地址最多只有一个addrinfo结构,可以用来作为连接的一个端点。 -
ai_flags:是一个位掩码,可以修改默认行为: -
AI_ADDRCONFIG:只有当本地主机被配置了IPv4时,result才会返回IPv4地址,IPv6同理。AI_CANONNAME:如果设置了该位,则result第一个addrinfo结构的ai_cannonname字段指向host的官方名字。AI_NUMERICSERV:强制service参数只能是端口号。AI_PASSIVE:使得返回的套接字地址可以被服务器用作监听套接字,此时host应该为NULL,就会使得返回的套接字地址结构中的地址字段为通配符地址。
从上面可知,一个域名可能会对应多个IP地址,通过这个
getaddrinfo函数就能寻找域名对应的所有可用的IP地址。
最终要调用freeaddrinfo函数来释放你得到的结果result,如果出错,可以调用gai_strerror函数来查看错误信息。
3.3.2 getnameinfo函数
#include <sys/socket.h>
#include <netdb.h>
int getnameinfo(const struct sockaddr *sa, socklen_t salen,
char *host, size_t hostlen,
char *service, size_t servlen, int flags);
该函数和getaddrinfo函数相反,通过传入套接字地址sa,能够返回对应的主机名字符串host和服务名字字符串service。其中flags可以修改该函数的默认行为:
NI_NUMERICHOST:该函数默认返回host中的域名,通过设置这个标志位来返回数字地址字符串。NI_NUMERICSERV:该函数默认检查/etc/service并返回服务名,通过设置这个标志位来返回端口号。
从上面可知,一个IP地址可能会对应多个域名,通过这个
getnameinfo函数就能寻找IP地址对应的所有可用的域名。
3.3.3 套接字接口的辅助函数
这里提供两个封装函数open_clientfd和open_listenfd来封装getnameinfo和getaddrinfo函数来进行客户端和服务端的通信。
int open_clientfd(char *hostname, char *port){
int clientfd;
struct addrinfo hints, *listp, *p;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo)); //初始化hints为0
hints.ai_socktype = SOCK_STREAM; /* Open a connection */
hints.ai_flags = AI_NUMERICSERV; /* ... using a numeric port arg. */
hints.ai_flags |= AI_ADDRCONFIG; /* Recommended for connections */
getaddrinfo(hostname, port, &hints, &listp); //获得一系列套接字地址
/* Walk the list for one that we can successfully connect to */
for (p = listp; p; p = p->ai_next) { //遍历所有套接字地址,找到一个可以连接的
/* Create a socket descriptor */
if ((clientfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Connect to the server */
if (connect(clientfd, p->ai_addr, p->ai_addrlen) != -1)
break; /* Success */
close(clientfd); /* Connect failed, try another */ //line:netp:openclientfd:closefd
}
/* Clean up */
freeaddrinfo(listp);
if (!p) /* All connects failed */
return -1;
else /* The last connect succeeded */
return clientfd;
}
客户端可以通过open_clientfd函数来简历与服务器的连接,该服务器运行在hostname主机上,并在port端口监听连接请求。首先会通过getaddrinfo函数找到一系列套接字地址,并依次遍历寻找可以创建套接字描述符且连接成功的一个套接字地址,然后返回准备好的套接字描述符,客户端可以直接通过clientfd和Unix I/O来与服务器进行通信。
int open_listenfd(char *port){
struct addrinfo hints, *listp, *p;
int listenfd, optval=1;
/* Get a list of potential server addresses */
memset(&hints, 0, sizeof(struct addrinfo));
hints.ai_socktype = SOCK_STREAM; /* Accept connections */
hints.ai_flags = AI_PASSIVE | AI_ADDRCONFIG; /* ... on any IP address */
//AI_PASSIVE保证套接字地址可被服务器用作监听套接字
hints.ai_flags |= AI_NUMERICSERV; /* ... using port number */
getaddrinfo(NULL, port, &hints, &listp); //这里的host为NULL
/* Walk the list for one that we can bind to */
for (p = listp; p; p = p->ai_next) {
/* Create a socket descriptor */
if ((listenfd = socket(p->ai_family, p->ai_socktype, p->ai_protocol)) < 0)
continue; /* Socket failed, try the next */
/* Eliminates "Address already in use" error from bind */
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, //line:netp:csapp:setsockopt
(const void *)&optval , sizeof(int));
/* Bind the descriptor to the address */
if (bind(listenfd, p->ai_addr, p->ai_addrlen) == 0)
break; /* Success */
close(listenfd); /* Bind failed, try the next */
}
/* Clean up */
freeaddrinfo(listp);
if (!p) /* No address worked */
return -1;
/* Make it a listening socket ready to accept connection requests */
if (listen(listenfd, LISTENQ) < 0) {
Close(listenfd);
return -1;
}
return listenfd;
}
服务器可通过open_listenfd来创建一个监听描述符,并准备好连接请求。首先hints.ai_flags包含AI_PASSIVE使得返回的套接字地址可被服务器作为监听套接字,并在socket函数中将host设置为NULL,使得后面的p->ai_addr为通配符地址,这样在bind函数中就能使得服务器监听所有发送请求的客户端IP地址,并且这里只指定了端口号,所以就是将listenfd用于该端口的监听。这里的setsockopt函数使得服务器能被终止、重启和立即开始接收连接请求。最终,服务器可以直接通过listenfd和Unix I/O来与客户端进行通信。
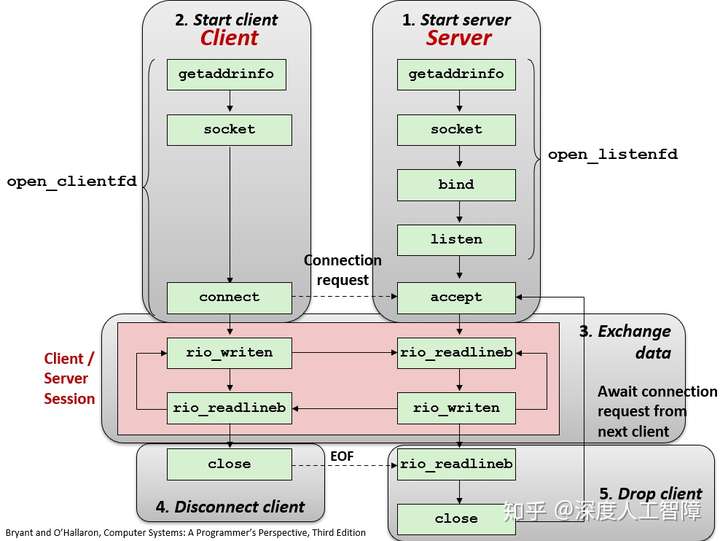
通过以上open_clientfd和open_listenfd函数,使得我们无需考虑之前socket和bind等函数在不同协议下的代码,使得客户端可以直接传输服务器的域名和端口到open_clientfd函数来完成与服务器的连接,而服务器也可以直接传输监听的端口到open_listenfd函数来完成监听,避免了底层的很多设置。
3.4 echo客户端和服务端实例
 echo客户端
echo客户端
该客户端中,直接将服务器主机host和端口号port传入open_clientfd来完成socket和connect函数,直接返回可以使用的套接字描述符clientfd,然后从标准输入读取数据保存在buf中,再将clientfd当做普通文件的描述符,直接使用Rio_writen和Rio_readlineb来与服务器进行传输数据。
 echo服务器
echo服务器
服务器中首先通过open_listenfd来调用socket、bind和listen函数来监听特定端口,然后不断循环调用accept来查看是否有客户端发送请求,并将发送请求的客户端套接字地址保存在clientaddr中,并返回已连接套接字描述符connfd,可以对clientaddr调用getnameinfo函数来获取客户端的地址,也可以将connfd当做普通文件的描述符,直接使用Rio_writen和Rio_readlineb来与客户端进行传输数据。这里调用了echo函数

该函数中就是通过connfd来执行Rio_readlineb函数,读取客户端发送过来的一行文本,然后将其输出,并返回到客户端中。
注意:要先开启服务器,再运行客户端。这里的服务器一次只能与一个客户端相连。
4 .Web基础
4.1 web基础
Web客户端和服务器之间的交互基于超文本传输协议(Hypertext Transfer Protocol,HTTP),该协议是建立在TCP协议之上的。传输的过程为
- 一个Web客户端(即浏览器)打开一个到Web服务器的连接,并请求某些内容
- Web服务器响应所请求的内容,然后关闭连接
- Web客户端读取这些内容,再将其显示在屏幕上
4.2 web内容
其中,这些内容是一串字节序列,Web服务器会发送一个MIME(Multipurpose Internet Mail Extensions)类型来帮助浏览器识别一个HTTP请求返回的是什么内容的数据,应该如何打开、如何显示,即MIME类型是用来标注网络数据的,常见类型包括

Web服务器提供的内容也有两种不同的方式:
- 服务静态内容(Serving Static Content):取一个磁盘文件,并将其内容返回给客户端。
- 服务动态内容(Serving Dynamic Content):运行一个可执行目标文件,将其输出返回给客户端。
所以Web服务器返回的每条内容都与它管理的某个文件相关联,这些文件都有一个唯一的名字,称为URL(Universal Resource Locator)。比如对于http://www.google.com:80/index.html,客户端使用前缀http://www.google.com:80来决定与哪个Web服务器联系以及Web服务器的监听端口,而Web服务器使用后缀/index.html来发现在它文件系统中的文件,确定请求内容是静态还是动态的。此外,URL还可以用?字符来分隔文件名和参数,用&分隔多个参数,来向动态内容传送参数,这个后缀称为URI(Universal Resource Indentifier)。
对于服务器如何解释一个URL后缀:
- 没有标准来确定后缀是动态内容还是静态内容,过去是将所有可执行目标文件都放在同一个目录中。
- 后缀中最开始的
/并不表示Web服务器中的根目录,而是被请求内容类型的主目录。 - 如果URL没有后缀,则浏览器会在URL后添加缺失的
/并将其传递给Web服务器,Web服务器又将/扩充到某个默认的文件名,比如/index.html,由此来展示网站的主页。
4.3 HTTP事务
可以使用Linux的TELNET程序来和Web服务器执行事务,如
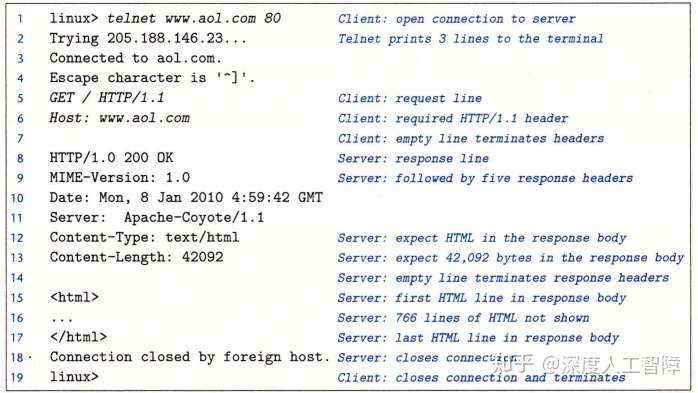
在第1行中运行telnet www.aol.com 80,表示要打开一个到AOL Web服务器的连接,此时TELNET会输出3段信息,然后等待我们的输入,我们可以输入一个文本行,此时TELNET就会读取并添加回车和换行符号,然后将其发送到服务器。
3.1 HTTP请求
在第5~7行,我们输入了一个HTTP请求(HTTP Requests),它主要包含:
- 请求行(Request Line):
在第5行中,主要形式为method URI version。
HTTP这里支持不同方法,这里主要介绍GET方法,它将指导服务器生成和返回URI标识的内容。而version字段表明该请求的HTTP版本,并表明接下来的请求报头是HTTP/1.1格式的。
总的来说,第5行要求服务器取出并返回HTML文件/index.html。 - 请求报头(Request Hearder):
主要是为服务器提供额外的信息,格式为header-name: header-data。
比如这里我们提供了HTTP/1.1需要的Host信息。在客户端和原始服务器(Irigin Server)之间存在很多缓存了原始服务器内容的代理,称为代理链(Proxy Chain),通过Host字段来指明原始服务器的域名,使得代理链中的代理能判断是否在他们本地缓存了被请求内容的副本,避免从很远的原始服务器调用数据。 - 一个空文本行来终止请求报头列表
3.2 HTTP请求响应
在TELNET将我们的HTTP请求发送给Web服务器后,Web服务器就会返回一个HTTP响应(HTTP Responses),它主要包含:
- 响应行(Response Line):
响应行和请求行类似,格式为version status-code status-message。
version字段表明响应使用的HTTP版本,而status-code和status-message主要指明请求的状态,表示你的请求是否被正确处理或出现什么问题

- 响应报头(Response Header):
是关于响应的附加信息,比如Content-type表示Web服务器发送给浏览器的响应主体的MIME类型,使得浏览器能正确解析这些字节序列。Content-Length用来表明响应主体的字节大小。 - 一个终止报头的空行
- 响应主体(Response Body):包含被请求的内容。
4.4 服务动态内容
比如Web服务器接收到浏览器的发送的URI时
GET /cgi-bin/adder?15000&213 HTTP/1.1
其中/cgi-bin/adder称为CGI(Common Gateway Interface)程序,该程序是使用CGI标准来让Web服务器服务动态内容。而其中的15000&213是浏览器发送给CGI程序的参数。
- Web服务器首先调用
fork创建一个子进程,并在子进程中设置对应的CGI环境变量

比如将程序的参数保存在QUERY_STRING中,则CGI程序可以通过getenv("QUERY_STRING")函数来获得浏览器发送的参数。然后调用dup2函数将子进程的标准输出重定向到和客户端相关联的已连接描述符
- 调用
execve来执行/cgi-bin/adder程序 - CGI程序负责生成
Content-type和Content-Length响应报头,并将它的动态内容发送到标准输出

我们可以自己写CGI程序,但是要注意当执行CGI程序时,是在Web服务器中的一个子进程中,需要通过getenv来获得程序参数,且标准输出已被重定向到与浏览器关联的已连接描述符,并且要根据执行的结果来生成Content-type和Content-Length响应报头。

注意:CGI实际上定义了一个简单的标准,用于在客户端(浏览器),服务器和子进程之间传输信息。它是用于生成动态内容的原始标准,由于创建子进程十分昂贵且慢,目前已被其他更快的技术取代:比如fastCGI,Apache模块,Java Servlet,Rails控制器。
5 TINY Web服务器
这一节将实现一个简单的Web服务器来提供静态和动态内容。
/*
* tiny.c - A simple, iterative HTTP/1.0 Web server that uses the
* GET method to serve static and dynamic content.
*/
#include "csapp.h"
void doit(int fd);
void read_requesthdrs(rio_t *rp);
int parse_uri(char *uri, char *filename, char *cgiargs);
void serve_static(int fd, char *filename, int filesize);
void get_filetype(char *filename, char *filetype);
void serve_dynamic(int fd, char *filename, char *cgiargs);
void clienterror(int fd, char *cause, char *errnum,
char *shortmsg, char *longmsg);
int main(int argc, char **argv)
{
int listenfd, connfd;
char hostname[MAXLINE], port[MAXLINE];
socklen_t clientlen;
struct sockaddr_storage clientaddr;
/* Check command line args */
if (argc != 2) {
fprintf(stderr, "usage: %s <port>\n", argv[0]);
exit(1);
}
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(clientaddr);
connfd = Accept(listenfd, (SA *)&clientaddr, &clientlen); //line:netp:tiny:accept
Getnameinfo((SA *) &clientaddr, clientlen, hostname, MAXLINE,
port, MAXLINE, 0);
printf("Accepted connection from (%s, %s)\n", hostname, port);
doit(connfd); //line:netp:tiny:doit
Close(connfd); //line:netp:tiny:close
}
}
首先,这个是Web服务器的代码,我们可以传入一个端口参数,使得Web服务器能调用open_listenfd来监听该端口,并返回一个监听套接字描述符,并进入死循环,不断调用accept函数来判断是否有浏览器发起连接请求,如果有则返回已连接描述符connfd,并且可以通过getnameinfo函数来获得浏览器的信息,然后调用doit函数来处理一个HTTP事务。
void doit(int fd)
{
int is_static;
struct stat sbuf;
char buf[MAXLINE], method[MAXLINE], uri[MAXLINE], version[MAXLINE];
char filename[MAXLINE], cgiargs[MAXLINE];
rio_t rio;
/* Read request line and headers */
Rio_readinitb(&rio, fd);
if (!Rio_readlineb(&rio, buf, MAXLINE)) //line:netp:doit:readrequest
return;
printf("%s", buf);
sscanf(buf, "%s %s %s", method, uri, version); //line:netp:doit:parserequest
if (strcasecmp(method, "GET")) { //line:netp:doit:beginrequesterr
clienterror(fd, method, "501", "Not Implemented",
"Tiny does not implement this method");
return;
} //line:netp:doit:endrequesterr
read_requesthdrs(&rio); //line:netp:doit:readrequesthdrs
/* Parse URI from GET request */
is_static = parse_uri(uri, filename, cgiargs); //line:netp:doit:staticcheck
if (stat(filename, &sbuf) < 0) { //line:netp:doit:beginnotfound
clienterror(fd, filename, "404", "Not found",
"Tiny couldn't find this file");
return;
} //line:netp:doit:endnotfound
if (is_static) { /* Serve static content */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IRUSR & sbuf.st_mode)) { //line:netp:doit:readable
clienterror(fd, filename, "403", "Forbidden",
"Tiny couldn't read the file");
return;
}
serve_static(fd, filename, sbuf.st_size); //line:netp:doit:servestatic
}
else { /* Serve dynamic content */
if (!(S_ISREG(sbuf.st_mode)) || !(S_IXUSR & sbuf.st_mode)) { //line:netp:doit:executable
clienterror(fd, filename, "403", "Forbidden",
"Tiny couldn't run the CGI program");
return;
}
serve_dynamic(fd, filename, cgiargs); //line:netp:doit:servedynamic
}
}
void read_requesthdrs(rio_t *rp)
{
char buf[MAXLINE];
Rio_readlineb(rp, buf, MAXLINE);
printf("%s", buf);
while(strcmp(buf, "\r\n")) { //line:netp:readhdrs:checkterm
Rio_readlineb(rp, buf, MAXLINE);
printf("%s", buf);
}
return;
}
该函数中,将已连接描述符当做普通文件的描述符,通过该描述符来与客户端进行通信。首先调用Rio_readinitb函数将描述符和输入缓存关联起来。此时浏览器会发送HTTP请求,这里可以通过一个Rio_readlineb函数来读取HTTP请求的第一行内容,即请求头,然后从中解析出HTTP方法method、URIuri和HTTP版本version。这里TINY Web服务器只支持GET方法,所以传入其他方法就直接返回主程序。然后通过read_requesthdrs函数来读取请求报头,但是TINY不使用任何请求报头的信息,所以只传入输入缓存rio,然后依次判断什么时候读取到\r\n就表示HTTP请求结束了。
接下来通过调用parse_uri函数来判断URI是否为静态服务。该TINY Web服务器将所有静态文件都放在当前目录,而可执行目标文件都放在./cgi-bin中,所以先通过strstr函数来判断URI中是否含有cgi-bin子串来判断当前HTTP请求是要静态内容还是动态内容。如果是静态内容,就将静态内容对应的文件保存在filename中,并清空CGI参数cgiargs;如果是动态内容,首先从中分解出CGI程序和CGI参数,分别将其保存在filename和cgiargs参数中。
int parse_uri(char *uri, char *filename, char *cgiargs)
{
char *ptr;
if (!strstr(uri, "cgi-bin")) { /* Static content */ //line:netp:parseuri:isstatic
strcpy(cgiargs, ""); //line:netp:parseuri:clearcgi
strcpy(filename, "."); //line:netp:parseuri:beginconvert1
strcat(filename, uri); //line:netp:parseuri:endconvert1
if (uri[strlen(uri)-1] == '/') //line:netp:parseuri:slashcheck
strcat(filename, "home.html"); //line:netp:parseuri:appenddefault
return 1;
}
else { /* Dynamic content */ //line:netp:parseuri:isdynamic
ptr = index(uri, '?'); //line:netp:parseuri:beginextract
if (ptr) {
strcpy(cgiargs, ptr+1);
*ptr = '\0';
}
else
strcpy(cgiargs, ""); //line:netp:parseuri:endextract
strcpy(filename, "."); //line:netp:parseuri:beginconvert2
strcat(filename, uri); //line:netp:parseuri:endconvert2
return 0;
}
}
则在doit函数中可以先通过stat函数来判断是否存在对应的文件,然后如果是静态文件就调用serve_static函数,如果是动态文件就调用serve_dynamic函数。
void serve_static(int fd, char *filename, int filesize)
{
int srcfd;
char *srcp, filetype[MAXLINE], buf[MAXBUF];
/* Send response headers to client */
get_filetype(filename, filetype); //line:netp:servestatic:getfiletype
sprintf(buf, "HTTP/1.0 200 OK\r\n"); //line:netp:servestatic:beginserve
sprintf(buf, "%sServer: Tiny Web Server\r\n", buf);
sprintf(buf, "%sConnection: close\r\n", buf);
sprintf(buf, "%sContent-length: %d\r\n", buf, filesize);
sprintf(buf, "%sContent-type: %s\r\n\r\n", buf, filetype); //最终的\r\n表示响应的空白行
Rio_writen(fd, buf, strlen(buf)); //line:netp:servestatic:endserve
printf("Response headers:\n");
printf("%s", buf);
/* Send response body to client */
srcfd = Open(filename, O_RDONLY, 0); //line:netp:servestatic:open
srcp = Mmap(0, filesize, PROT_READ, MAP_PRIVATE, srcfd, 0);//line:netp:servestatic:mmap
Close(srcfd); //line:netp:servestatic:close
Rio_writen(fd, srcp, filesize); //line:netp:servestatic:write
Munmap(srcp, filesize); //line:netp:servestatic:munmap
}
void get_filetype(char *filename, char *filetype)
{
if (strstr(filename, ".html"))
strcpy(filetype, "text/html");
else if (strstr(filename, ".gif"))
strcpy(filetype, "image/gif");
else if (strstr(filename, ".png"))
strcpy(filetype, "image/png");
else if (strstr(filename, ".jpg"))
strcpy(filetype, "image/jpeg");
else
strcpy(filetype, "text/plain");
}
在serve_static中,首先通过Rio_writen函数将HTTP响应内容输出到已连接描述符connfd中,将其发送给浏览器。然后通过调用mmap函数使用内存映射的方式来读取静态文件内容,将文件描述符srcfd偏移0的filesize个字节内容映射到虚拟内存中,并且设置该虚拟内存段中的虚拟页都是可读的,且是私有的写时复制的,尽可能节约物理内存空间。然后调用Rio_writen函数将这个虚拟内存中的内容输出给connfd,然后通过munmap函数来删除该虚拟内存段。
注意:这里的Content-Length只是文件的字节数,不包含响应头部的字节数。
复习:通过
mmap函数将文件内容内存映射到一个虚拟内存段后,并未将其保存到物理内存中,而Rio_writen函数是将物理内存中的内容写出来,所以这里会首先触发一个缺页异常,然后在缺页异常处理处理程序中将对应缺少的虚拟页复制到物理页中,由此按需地将文件中的内容保存在物理内存中。
void serve_dynamic(int fd, char *filename, char *cgiargs)
{
char buf[MAXLINE], *emptylist[] = { NULL };
/* Return first part of HTTP response */
sprintf(buf, "HTTP/1.0 200 OK\r\n");
Rio_writen(fd, buf, strlen(buf));
sprintf(buf, "Server: Tiny Web Server\r\n");
Rio_writen(fd, buf, strlen(buf));
if (Fork() == 0) { /* Child */ //line:netp:servedynamic:fork
/* Real server would set all CGI vars here */
setenv("QUERY_STRING", cgiargs, 1); //line:netp:servedynamic:setenv
Dup2(fd, STDOUT_FILENO); /* Redirect stdout to client */ //line:netp:servedynamic:dup2
Execve(filename, emptylist, environ); /* Run CGI program */ //line:netp:servedynamic:execve
}
Wait(NULL); /* Parent waits for and reaps child */ //line:netp:servedynamic:wait
}
在serve_dynamic函数中,会首先发送一个表示正确的HTTP响应。然后创建一个子进程来执行该可执行目标文件,首先对于CGI程序,需要先通过setenv函数将参数保存到CGI环境变量QUERY_STRING中,然后将子进程的标准输出重定位到已连接描述符connfd,使得子进程的标准输出都能直接发送到浏览器,然后通过execve函数来执行CGI程序。
注意:
- 可以发现这里只返回了表示成功的HTTP响应,而其他的比如
Content-Length和Content-type信息只有真正运行的CGI程序知道,所以这两个响应信息是由CGI程序来填写的。 execve函数将保留之前打开的文件和环境变量。
tiny程序运行实例
下载地址:tiny
下载后参考readme文件,解压后执行make编译,执行tiny 8000命令运行tiny在8000端口,打开浏览器输入地址http://127.0.0.1:8000/和http://127.0.0.1:8000/cgi-bin/adder?1&5即可访问
ics@sjtu-ics:~/桌面/tiny$ ./tiny 8000
Accepted connection from (localhost, 47440)
GET / HTTP/1.1
Host: 127.0.0.1:8000
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Response headers:
HTTP/1.0 200 OK
Server: Tiny Web Server
Connection: close
Content-length: 120
Content-type: text/html
Accepted connection from (localhost, 47442)
GET /godzilla.gif HTTP/1.1
Host: 127.0.0.1:8000
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0
Accept: image/webp,*/*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Referer: http://127.0.0.1:8000/
Sec-Fetch-Dest: image
Sec-Fetch-Mode: no-cors
Sec-Fetch-Site: same-origin
Response headers:
HTTP/1.0 200 OK
Server: Tiny Web Server
Connection: close
Content-length: 12155
Content-type: image/gif
Accepted connection from (localhost, 47444)
GET /favicon.ico HTTP/1.1
Host: 127.0.0.1:8000
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0
Accept: image/webp,*/*
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Referer: http://127.0.0.1:8000/
Sec-Fetch-Dest: image
Sec-Fetch-Mode: no-cors
Sec-Fetch-Site: same-origin
Accepted connection from (localhost, 47462)
GET /cgi-bin/adder?1&2 HTTP/1.1
Host: 127.0.0.1:8000
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1


本文来自博客园,作者:O_fly_O,转载请注明原文链接:https://www.cnblogs.com/world-explorer/p/16157277.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号