
极客时间运维进阶训练营第十九周作业
1、总结 prometheus 服务发现实现过程
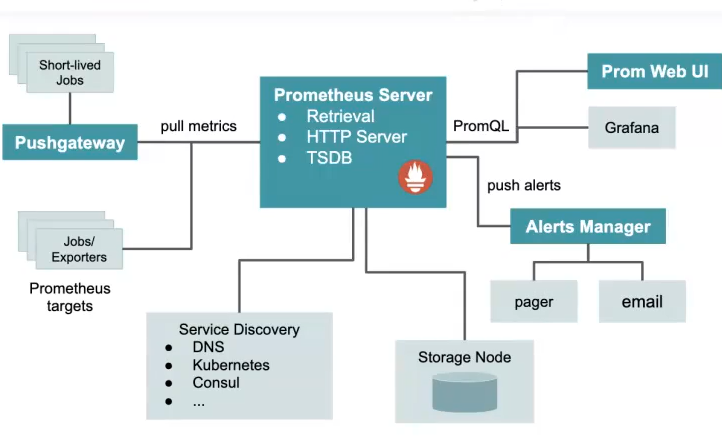
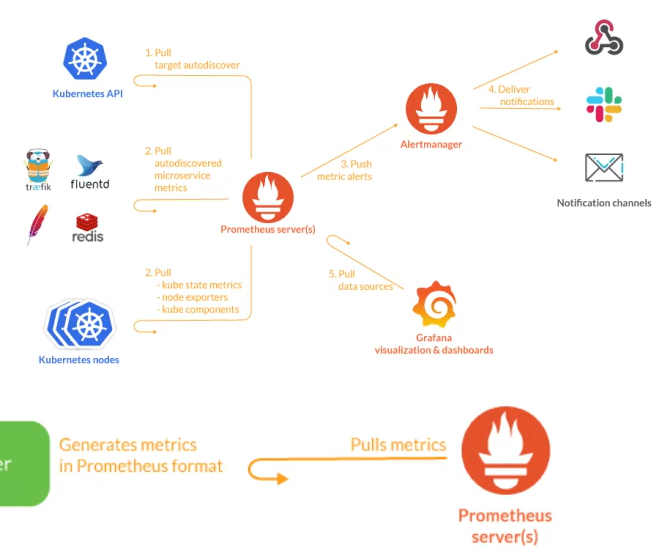

prom监听-》发现暴露的metrics-》自动加载-》抓取数据
2、总结 prometheus 标签重写 relabel_configs
replace: 替换标签,根据regex正则匹配源标签的值,使用replacement来应用表达式匹配的分组
keep:满足regex正在条件的实例进行采集,把sourc_labels中没有匹配到regex正则内容的target实例丢掉
drop: 满足regex正则条件的实例不采集
labelmap:匹配regex所有标签名称,然后复制匹配标签的值进行分组,可以通过replacement分组应用替代 labelkeep: 匹配regex所有标签的名称,不匹配的标签都将从标签集中删除
labeldrop:匹配regex所哦呦标签名称,匹配到的标签都将从标签集中删除
hashmod:使用hashmod计算source_labels的hash值并进行对吧,基于自定义的模数取模,实现对目标分类、重新赋值等功能
_scheme__://__address__/__metrics__path__
__scheme__,默认是http,不特别指明,就是http;
__address__,不特别说明也是抓取到源标签中的指标值;
__metrics__path__,默认是/metrics,除非特别指明;
source_labels:字面意思是源标签,没有经过relabel处理之前的标签名;
target_label:目标标签,通过action动作处理之后的新的标签名;
regex:正则表达式,用于匹配源标签值使用的;
replacement:replacement指定的替换后的标签(target_label)对应的数值;
scheme: https、http等代表获取指标数据时使用的协议类型;
3、kubernetes 环境中部署 prometheus 并基于 kubernetes_sd_config 实现 pod、node、endpoint 等监控目标动态发现


# 环境准备 root@k8s-master1:~/1.prometheus-case-files# cat case3-4-nginx.yaml kind: Deployment apiVersion: apps/v1 metadata: labels: app: magedu-nginx-deployment-label name: magedu-nginx-deployment namespace: magedu spec: replicas: 1 selector: matchLabels: app: magedu-nginx-selector template: metadata: labels: app: magedu-nginx-selector annotations: ## pod 服务发现此处做注解 prometheus.io/port: "9913" prometheus.io/scrape: "true" spec: containers: - name: magedu-nginx-container image: gaciaga/nginx-vts:1.11.12-alpine-vts-0.1.14 #imagePullPolicy: IfNotPresent imagePullPolicy: Always ports: - containerPort: 80 protocol: TCP name: http - containerPort: 443 protocol: TCP name: https env: - name: "password" value: "123456" - name: "age" value: "20" #resources: # limits: # cpu: 500m # memory: 512Mi # requests: # cpu: 500m # memory: 256Mi - name: magedu-nginx-exporter-container image: sophos/nginx-vts-exporter args: - '-nginx.scrape-uri=http://127.0.0.1/status/format/json' ports: - containerPort: 9913 --- kind: Service apiVersion: v1 metadata: labels: app: magedu-nginx-service-label name: magedu-nginx-service namespace: magedu spec: ## 通过servie发现,此处做注解 type: NodePort ports: - name: http port: 80 protocol: TCP targetPort: 80 nodePort: 30092 - name: https port: 443 protocol: TCP targetPort: 443 nodePort: 30093 selector: app: magedu-nginx-selector - name: metrics port: 9913 protocol: TCP targetPort: 9913 nodePort: 39913 selector: app: magedu-nginx-selector root@k8s-master1:~/1.prometheus-case-files# kubectl apply -f case3-4-nginx.yaml deployment.apps/magedu-nginx-deployment created service/magedu-nginx-service created root@k8s-master1:~/1.prometheus-case-files# root@k8s-master1:~/1.prometheus-case-files# cat case3-1-prometheus-cfg.yaml --- kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: monitoring data: prometheus.yml: | global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kube-state-metrics' static_configs: - targets: ['172.31.7.111:31666'] - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - job_name: 'kubernetes-nginx-pods' kubernetes_sd_configs: - role: pod namespaces: #可选指定namepace,如果不指定就是发现所有的namespace中的pod names: - myserver - magedu relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name root@k8s-master1:~/1.prometheus-case-files# kubectl apply -f case3-1-prometheus-cfg.yaml configmap/prometheus-config configured root@k8s-master1:~/prometheus-case-files# cat case3-2-prometheus-deployment.yaml --- apiVersion: apps/v1 kind: Deployment metadata: name: prometheus-server namespace: monitoring labels: app: prometheus spec: replicas: 1 selector: matchLabels: app: prometheus component: server #matchExpressions: #- {key: app, operator: In, values: [prometheus]} #- {key: component, operator: In, values: [server]} template: metadata: labels: app: prometheus component: server annotations: prometheus.io/scrape: 'false' spec: #nodeName: 172.31.7.113 serviceAccountName: monitor containers: - name: prometheus image: registry.cn-hangzhou.aliyuncs.com/zhangshijie/prometheus:v2.42.0 imagePullPolicy: IfNotPresent command: - prometheus - --config.file=/etc/prometheus/prometheus.yml - --storage.tsdb.path=/prometheus - --storage.tsdb.retention=720h resources: limits: memory: "512Mi" cpu: "500m" requests: memory: "512Mi" cpu: "500m" ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /etc/prometheus/prometheus.yml name: prometheus-config subPath: prometheus.yml - mountPath: /prometheus/ name: prometheus-storage-volume volumes: - name: prometheus-config configMap: name: prometheus-config items: - key: prometheus.yml path: prometheus.yml mode: 0644 - name: prometheus-storage-volume nfs: server: 172.31.7.109 path: /data/k8sdata/prometheusdata root@k8s-master1:~/1.prometheus-case-files# kubectl delete -f case3-2-prometheus-deployment.yaml ; kubectl apply -f case3-2-prometheus-deployment.yaml deployment.apps "prometheus-server" deleted deployment.apps/prometheus-server created
4、kubernetes 环境外部署 prometheus 并基于 kubernetes_sd_config 实现 pod、node、endpoint 等监控目标动态发现
# k8s 中授权 root@k8s-master1:~/1.prometheus-case-files# cat case4-prom-rbac.yaml apiVersion: v1 kind: ServiceAccount metadata: name: prometheus namespace: monitoring --- apiVersion: v1 kind: Secret type: kubernetes.io/service-account-token metadata: name: prometheus-token namespace: monitoring annotations: kubernetes.io/service-account.name: "prometheus" --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus rules: - apiGroups: - "" resources: - nodes - services - endpoints - pods - nodes/proxy verbs: - get - list - watch - apiGroups: - "extensions" resources: - ingresses verbs: - get - list - watch - apiGroups: - "" resources: - configmaps - nodes/metrics verbs: - get - nonResourceURLs: - /metrics verbs: - get --- #apiVersion: rbac.authorization.k8s.io/v1beta1 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: monitoring root@k8s-master1:~/1.prometheus-case-files# kubectl apply -f case4-prom-rbac.yaml serviceaccount/prometheus created secret/monitoring-token created clusterrole.rbac.authorization.k8s.io/prometheus created clusterrolebinding.rbac.authorization.k8s.io/prometheus created root@k8s-master1:~/1.prometheus-case-files# kubectl get secrets -n monitoring NAME TYPE DATA AGE default-token-4r85n kubernetes.io/service-account-token 3 6d4h monitor-token-bp6kk kubernetes.io/service-account-token 3 6d4h prometheus-token kubernetes.io/service-account-token 3 5s prometheus-token-wglwp kubernetes.io/service-account-token 3 5s root@k8s-master1:~/1.prometheus-case-files# kubectl describe secrets prometheus-token -n monitoring Name: prometheus-token Namespace: monitoring Labels: <none> Annotations: kubernetes.io/service-account.name: prometheus kubernetes.io/service-account.uid: 3d18adc2-99bb-4856-b136-79607ab5389f Type: kubernetes.io/service-account-token Data ==== ca.crt: 1302 bytes namespace: 10 bytes token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkZncDZ1bjlDRGRSMnBGWENBRFo3ZnNSZkRXVXhUSFltelMwUm9zamc1XzAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtb25pdG9yaW5nIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjNkMThhZGMyLTk5YmItNDg1Ni1iMTM2LTc5NjA3YWI1Mzg5ZiIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDptb25pdG9yaW5nOnByb21ldGhldXMifQ.JEpCAVRPOB1e-TXnLJ6Bi25L8Jxe1NQx31KMY8mju7BpfOEx7sF3kFIHAZPocOxGmE9IwbdtqnkwnhR_uzpQjlvFvHB6JJZBpzvzvMR9msHUbcTCeETqMN29dSqoun8fq4b8x3oGbszD0-E4PL2mNlC9u8_ysDbM3TYZsCE6V2BfKc1N-Ccl8s6CtW6sFQh2Z-0209YT4xBB6SW51pynI7igpFRTm35X87bew-q2NQFLd0_ByIoRLewhlsyn79waYUQ2KhJCfrSisgPT5Fm7Ryyd4UtClOb69BM0ELPvZeEIsMxcKL0pbmpJRnX9IZ8hnXIW-ylTQQEEvrEFj6jDeQ root@prometheus-server01:/apps/prometheus# cat /apps/prometheus/k8s.token eyJhbGciOiJSUzI1NiIsImtpZCI6IkZncDZ1bjlDRGRSMnBGWENBRFo3ZnNSZkRXVXhUSFltelMwUm9zamc1XzAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtb25pdG9yaW5nIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjNkMThhZGMyLTk5YmItNDg1Ni1iMTM2LTc5NjA3YWI1Mzg5ZiIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDptb25pdG9yaW5nOnByb21ldGhldXMifQ.JEpCAVRPOB1e-TXnLJ6Bi25L8Jxe1NQx31KMY8mju7BpfOEx7sF3kFIHAZPocOxGmE9IwbdtqnkwnhR_uzpQjlvFvHB6JJZBpzvzvMR9msHUbcTCeETqMN29dSqoun8fq4b8x3oGbszD0-E4PL2mNlC9u8_ysDbM3TYZsCE6V2BfKc1N-Ccl8s6CtW6sFQh2Z-0209YT4xBB6SW51pynI7igpFRTm35X87bew-q2NQFLd0_ByIoRLewhlsyn79waYUQ2KhJCfrSisgPT5Fm7Ryyd4UtClOb69BM0ELPvZeEIsMxcKL0pbmpJRnX9IZ8hnXIW-ylTQQEEvrEFj6jDeQ # 修改配置文件 root@prometheus-server01:/apps/prometheus# cat /apps/prometheus/prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] - job_name: "prometheus-federate-132" scrape_interval: 10s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' - '{__name__=~"node.*"}' static_configs: - targets: - "192.168.56.132:9090" - job_name: "prometheus-federate-133" scrape_interval: 10s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' - '{__name__=~"node.*"}' static_configs: - targets: - "192.168.56.133:9090" - job_name: "coredns" static_configs: - targets: ["172.31.7.112:30090"] #node节点发现 - job_name: 'kubernetes-nodes-monitor' scheme: http tls_config: insecure_skip_verify: true bearer_token_file: /apps/prometheus/k8s.token kubernetes_sd_configs: - role: node api_server: https://172.31.7.101:6443 tls_config: insecure_skip_verify: true bearer_token_file: /apps/prometheus/k8s.token relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region] regex: '(.*)' replacement: '${1}' action: replace target_label: LOC - source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region] regex: '(.*)' replacement: 'NODE' action: replace target_label: Type - source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region] regex: '(.*)' replacement: 'K8S-test' action: replace target_label: Env - action: labelmap regex: __meta_kubernetes_node_label_(.+) root@prometheus-server01:/apps/prometheus# systemctl restart prometheus.service # 自动发现pod root@prometheus-server01:/apps/prometheus# cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] - job_name: "prometheus-federate-132" scrape_interval: 10s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' - '{__name__=~"node.*"}' static_configs: - targets: - "192.168.56.132:9090" - job_name: "prometheus-federate-133" scrape_interval: 10s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' - '{__name__=~"node.*"}' static_configs: - targets: - "192.168.56.133:9090" - job_name: "coredns" static_configs: - targets: ["172.31.7.112:30090"] #node节点发现 - job_name: 'kubernetes-nodes-monitor' scheme: http tls_config: insecure_skip_verify: true bearer_token_file: /apps/prometheus/k8s.token kubernetes_sd_configs: - role: node api_server: https://172.31.7.101:6443 tls_config: insecure_skip_verify: true bearer_token_file: /apps/prometheus/k8s.token relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region] regex: '(.*)' replacement: '${1}' action: replace target_label: LOC - source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region] regex: '(.*)' replacement: 'NODE' action: replace target_label: Type - source_labels: [__meta_kubernetes_node_label_failure_domain_beta_kubernetes_io_region] regex: '(.*)' replacement: 'K8S-test' action: replace target_label: Env - action: labelmap regex: __meta_kubernetes_node_label_(.+) #指定namespace 的pod - job_name: 'kubernetes-发现指定namespace的所有pod' kubernetes_sd_configs: - role: pod api_server: https://172.31.7.101:6443 tls_config: insecure_skip_verify: true bearer_token_file: /apps/prometheus/k8s.token namespaces: names: - myserver - magedu relabel_configs: - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name root@prometheus-server01:/apps/prometheus# systemctl restart prometheus.service # 此时prom 可以发现但无法采集 # 与k8s 的prom 搭建联邦集群 root@prometheus-server01:/apps/prometheus# cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] - job_name: "prometheus-federate-132" scrape_interval: 10s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' - '{__name__=~"node.*"}' static_configs: - targets: - "192.168.56.132:9090" - job_name: "prometheus-federate-133" scrape_interval: 10s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' - '{__name__=~"node.*"}' static_configs: - targets: - "192.168.56.133:9090" - job_name: "coredns" static_configs: - targets: ["172.31.7.112:30090"] - job_name: "prometheus-federate-k8s-7.111" scrape_interval: 10s honor_labels: true metrics_path: '/federate' params: 'match[]': - '{job="prometheus"}' - '{__name__=~"job:.*"}' - '{__name__=~"node.*"}' static_configs: - targets: - "172.31.7.111:30090" root@prometheus-server01:/apps/prometheus# systemctl restart prometheus.service
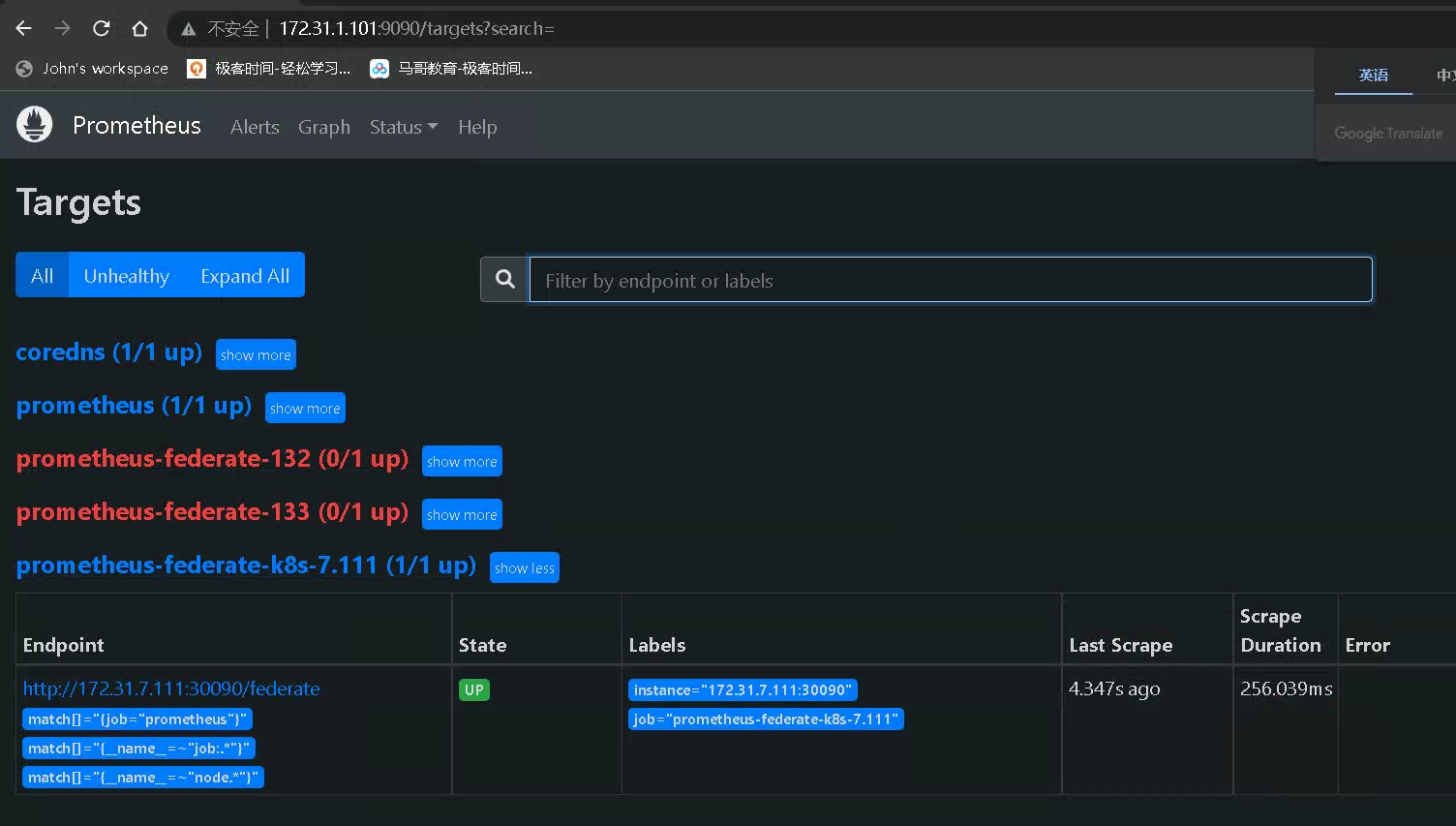
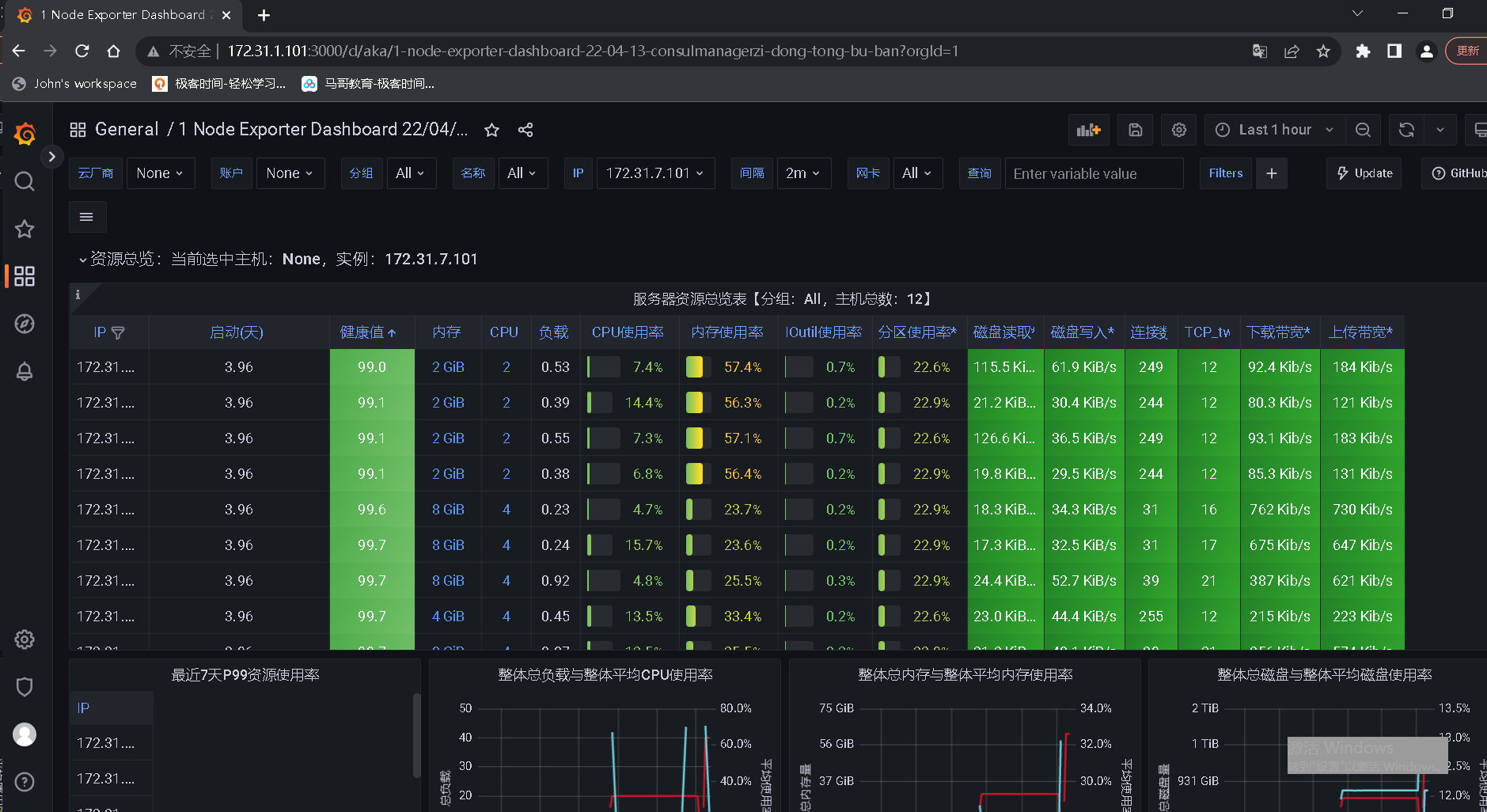
5、基于 HPA 控制器对 pod 副本实现弹性伸缩
# 手工扩容 root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl get pod -n magedu NAME READY STATUS RESTARTS AGE magedu-jenkins-deployment-67678599c-6nxbk 1/1 Running 6 (3d23h ago) 13d magedu-nginx-deployment-ddd6886bb-7sfp2 2/2 Running 0 76m magedu-nginx-deployment-ddd6886bb-bvznw 2/2 Running 0 76m magedu-nginx-deployment-ddd6886bb-jb7qh 2/2 Running 0 76m magedu-nginx-deployment-ddd6886bb-jhcnh 2/2 Running 0 85m magedu-nginx-deployment-ddd6886bb-qwds6 2/2 Running 0 76m zookeeper1-77d9cdc8c5-4894p 1/1 Running 4 (2d23h ago) 5d3h zookeeper2-74d59c877d-5lvxj 1/1 Running 4 (2d23h ago) 5d3h zookeeper3-6775684d7c-jqvjv 1/1 Running 4 (2d23h ago) 5d3h root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl scale deployments magedu-nginx-deployment --replicas=8 -n magedu deployment.apps/magedu-nginx-deployment scaled root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl get pod -n magedu NAME READY STATUS RESTARTS AGE magedu-jenkins-deployment-67678599c-6nxbk 1/1 Running 6 (3d23h ago) 13d magedu-nginx-deployment-ddd6886bb-2zwmv 0/2 ContainerCreating 0 5s magedu-nginx-deployment-ddd6886bb-7sfp2 2/2 Running 0 80m magedu-nginx-deployment-ddd6886bb-bvznw 2/2 Running 0 80m magedu-nginx-deployment-ddd6886bb-jb7qh 2/2 Running 0 80m magedu-nginx-deployment-ddd6886bb-jhcnh 2/2 Running 0 88m magedu-nginx-deployment-ddd6886bb-m6mr6 0/2 ContainerCreating 0 5s magedu-nginx-deployment-ddd6886bb-mqm9t 0/2 ContainerCreating 0 5s magedu-nginx-deployment-ddd6886bb-qwds6 2/2 Running 0 80m # 自动扩缩容 root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# cat hpa-autoscaling-v2.yaml apiVersion: autoscaling/v2 #定义API版本 kind: HorizontalPodAutoscaler #定义资源对象类型为HorizontalPodAutoscaler metadata: #定义元数据 namespace: magedu #创建到指定的namespace name: magedu-tomcat-app1-podautoscaler #HPA控制器名称 labels: #自定义标签 app: magedu-tomcat-app1 #标签1 version: v2 #标签2 spec: #定义对象具体信息 scaleTargetRef: #定义水平伸缩的目标对象,Deployment、ReplicationController/ReplicaSet kind: Deployment #指定伸缩目标类型为Deployment控制器 apiVersion: apps/v1 #Deployment API版本 name: magedu-tomcat-app1-deployment #目标Deployment名称 minReplicas: 3 #最小pod副本数 maxReplicas: 10 #最大pod副本数 metrics: #基于指定的指标数据进行pod副本自动伸缩 - type: Resource #定义指标资源 resource: #定义指标资源具体信息 name: memory #资源名称为memory target: #目标阈值 type: Utilization #触发类型为利用率 averageUtilization: 50 #平均利用率50% - type: Resource #定义指标资源 resource: #定义指标资源具体信息 name: cpu #资源名称为cpu target: ##目标阈值 type: Utilization #触发类型为利用率 averageUtilization: 40 #平均利用率50% # (75+60+80)/3/50 对比和1的差异 差异值*pod总数 取整就是扩容的数量 # 验证metrics server root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl top pod error: Metrics API not available # 此处表示没有安装 root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# cat metrics-server-v0.6.1.yaml apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server rbac.authorization.k8s.io/aggregate-to-admin: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-view: "true" name: system:aggregated-metrics-reader rules: - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server name: system:metrics-server rules: - apiGroups: - "" resources: - nodes/metrics verbs: - get - apiGroups: - "" resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: v1 kind: Service metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: ports: - name: https port: 443 protocol: TCP targetPort: https selector: k8s-app: metrics-server --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: selector: matchLabels: k8s-app: metrics-server strategy: rollingUpdate: maxUnavailable: 0 template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --secure-port=4443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --metric-resolution=15s image: registry.cn-hangzhou.aliyuncs.com/zhangshijie/metrics-server:v0.6.1 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 4443 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS initialDelaySeconds: 20 periodSeconds: 10 resources: requests: cpu: 100m memory: 200Mi securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100 root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl apply -f metrics-server-v0.6.1.yaml serviceaccount/metrics-server unchanged clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrole.rbac.authorization.k8s.io/system:metrics-server unchanged rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader unchanged clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator unchanged clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server unchanged service/metrics-server unchanged deployment.apps/metrics-server configured apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl top pod NAME CPU(cores) MEMORY(bytes) net-test1 0m 3Mi root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% 172.31.7.101 141m 3% 1205Mi 33% 172.31.7.102 114m 5% 1149Mi 69% 172.31.7.103 116m 5% 1069Mi 64% 172.31.7.111 128m 3% 1754Mi 23% 172.31.7.112 150m 3% 2645Mi 34% 172.31.7.113 145m 3% 1905Mi 24% # 创建测试容器 root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# cat tomcat-app1.yaml kind: Deployment #apiVersion: extensions/v1beta1 apiVersion: apps/v1 metadata: labels: app: magedu-tomcat-app1-deployment-label name: magedu-tomcat-app1-deployment namespace: magedu spec: replicas: 2 selector: matchLabels: app: magedu-tomcat-app1-selector template: metadata: labels: app: magedu-tomcat-app1-selector spec: containers: - name: magedu-tomcat-app1-container #image: harbor.magedu.local/magedu/tomcat-app1:v7 image: tomcat:7.0.93-alpine #image: lorel/docker-stress-ng #args: ["--vm", "2", "--vm-bytes", "256M"] ##command: ["/apps/tomcat/bin/run_tomcat.sh"] imagePullPolicy: IfNotPresent ##imagePullPolicy: Always ports: - containerPort: 8080 protocol: TCP name: http env: - name: "password" value: "123456" - name: "age" value: "18" resources: limits: # 注意此处一定要做资源限制,否则弹性伸缩无法生效 cpu: 1 memory: "512Mi" requests: cpu: 500m memory: "512Mi" --- kind: Service apiVersion: v1 metadata: labels: app: magedu-tomcat-app1-service-label name: magedu-tomcat-app1-service namespace: magedu spec: type: NodePort ports: - name: http port: 80 protocol: TCP targetPort: 8080 #nodePort: 40003 selector: app: magedu-tomcat-app1-selector root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl apply -f tomcat-app1.yaml root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl get pod -n magedu NAME READY STATUS RESTARTS AGE magedu-jenkins-deployment-67678599c-6nxbk 1/1 Running 6 (4d11h ago) 13d magedu-nginx-deployment-ddd6886bb-2zwmv 2/2 Running 0 12h magedu-nginx-deployment-ddd6886bb-jhcnh 2/2 Running 0 14h magedu-tomcat-app1-deployment-6bf7b7bf7d-92wdl 1/1 Running 0 63s magedu-tomcat-app1-deployment-6bf7b7bf7d-f25cf 1/1 Running 0 63s zookeeper1-77d9cdc8c5-4894p 1/1 Running 4 (3d12h ago) 5d15h zookeeper2-74d59c877d-5lvxj 1/1 Running 4 (3d12h ago) 5d15h zookeeper3-6775684d7c-jqvjv 1/1 Running 4 (3d12h ago) 5d15h # 创建hpa deployment.apps/magedu-tomcat-app1-deployment created service/magedu-tomcat-app1-service created root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# cat hpa-autoscaling-v2.yaml apiVersion: autoscaling/v2 #定义API版本,语法与其他版本不通用 kind: HorizontalPodAutoscaler #定义资源对象类型为HorizontalPodAutoscaler metadata: #定义元数据 namespace: magedu #创建到指定的namespace name: magedu-tomcat-app1-podautoscaler #HPA控制器名称 labels: #自定义标签 app: magedu-tomcat-app1 #标签1 version: v2 #标签2 spec: #定义对象具体信息 scaleTargetRef: #定义水平伸缩的目标对象,Deployment、ReplicationController/ReplicaSet kind: Deployment #指定伸缩目标类型为Deployment控制器 apiVersion: apps/v1 #Deployment API版本 name: magedu-tomcat-app1-deployment #目标Deployment名称 minReplicas: 3 #最小pod副本数 maxReplicas: 10 #最大pod副本数 metrics: #基于指定的指标数据进行pod副本自动伸缩 - type: Resource #定义指标资源 resource: #定义指标资源具体信息 name: memory #资源名称为memory target: #目标阈值 type: Utilization #触发类型为利用率 averageUtilization: 50 #平均利用率50% - type: Resource #定义指标资源 resource: #定义指标资源具体信息 name: cpu #资源名称为cpu target: ##目标阈值 type: Utilization #触发类型为利用率 averageUtilization: 40 #平均利用率50% root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl apply -f hpa-autoscaling-v2.yaml horizontalpodautoscaler.autoscaling/magedu-tomcat-app1-podautoscaler created root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl get hpa -n magedu NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE magedu-tomcat-app1-podautoscaler Deployment/magedu-tomcat-app1-deployment <unknown>/50%, <unknown>/40% 3 10 0 12s # unknown 表示没有采集到数据,过一会儿就会采集到,如果持续不能采集到则为出现异常 root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl get hpa -n magedu NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE magedu-tomcat-app1-podautoscaler Deployment/magedu-tomcat-app1-deployment 28%/50%, 0%/40% 3 10 3 45s root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl get pod -n magedu NAME READY STATUS RESTARTS AGE magedu-jenkins-deployment-67678599c-6nxbk 1/1 Running 6 (4d12h ago) 13d magedu-nginx-deployment-ddd6886bb-2zwmv 2/2 Running 0 12h magedu-nginx-deployment-ddd6886bb-jhcnh 2/2 Running 0 14h magedu-tomcat-app1-deployment-6bf7b7bf7d-92wdl 1/1 Running 0 4m33s magedu-tomcat-app1-deployment-6bf7b7bf7d-f25cf 1/1 Running 0 4m33s magedu-tomcat-app1-deployment-6bf7b7bf7d-qwkr9 1/1 Running 0 107s # 此时发现已经增加了pod,从一个调整到3个最小值 # 打开压测进程 root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# cat tomcat-app1.yaml kind: Deployment #apiVersion: extensions/v1beta1 apiVersion: apps/v1 metadata: labels: app: magedu-tomcat-app1-deployment-label name: magedu-tomcat-app1-deployment namespace: magedu spec: replicas: 2 selector: matchLabels: app: magedu-tomcat-app1-selector template: metadata: labels: app: magedu-tomcat-app1-selector spec: containers: - name: magedu-tomcat-app1-container #image: harbor.magedu.local/magedu/tomcat-app1:v7 #image: tomcat:7.0.93-alpine image: lorel/docker-stress-ng args: ["--vm", "2", "--vm-bytes", "256M"] ##command: ["/apps/tomcat/bin/run_tomcat.sh"] imagePullPolicy: IfNotPresent ##imagePullPolicy: Always ports: - containerPort: 8080 protocol: TCP name: http env: - name: "password" value: "123456" - name: "age" value: "18" resources: limits: cpu: 1 memory: "512Mi" requests: cpu: 500m memory: "512Mi" --- kind: Service apiVersion: v1 metadata: labels: app: magedu-tomcat-app1-service-label name: magedu-tomcat-app1-service namespace: magedu spec: type: NodePort ports: - name: http port: 80 protocol: TCP targetPort: 8080 #nodePort: 40003 selector: app: magedu-tomcat-app1-selector root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl apply -f tomcat-app1.yaml deployment.apps/magedu-tomcat-app1-deployment configured service/magedu-tomcat-app1-service unchanged root@k8s-master1:~/2.hpa-metrics-server-0.6.1-case# kubectl get pod -n magedu NAME READY STATUS RESTARTS AGE magedu-jenkins-deployment-67678599c-6nxbk 1/1 Running 6 (4d12h ago) 13d magedu-nginx-deployment-ddd6886bb-2zwmv 2/2 Running 0 12h magedu-nginx-deployment-ddd6886bb-jhcnh 2/2 Running 0 14h magedu-tomcat-app1-deployment-7594ccd998-2444n 1/1 Running 0 14s magedu-tomcat-app1-deployment-7594ccd998-4kwrr 1/1 Running 0 14s magedu-tomcat-app1-deployment-7594ccd998-9tt4w 1/1 Running 0 14s magedu-tomcat-app1-deployment-7594ccd998-fz456 1/1 Running 0 14s magedu-tomcat-app1-deployment-7594ccd998-hjbql 1/1 Running 0 70s magedu-tomcat-app1-deployment-7594ccd998-jz7jz 1/1 Running 0 59s magedu-tomcat-app1-deployment-7594ccd998-lbp9c 1/1 Running 0 14s magedu-tomcat-app1-deployment-7594ccd998-mpdc6 1/1 Running 0 66s magedu-tomcat-app1-deployment-7594ccd998-mwpg7 1/1 Running 0 29s magedu-tomcat-app1-deployment-7594ccd998-rhpr2 1/1 Running 0 29s # 此时发现已经到了最大的数量10个,通常 小应用 3-10,通常大应用5-20个

 浙公网安备 33010602011771号
浙公网安备 33010602011771号