Java之美[从菜鸟到高手演变]之集合类【吐血推荐!讲得太好了!!!】
source: http://blog.csdn.net/zhangerqing/article/details/8122075
最近在找工作,目前还没有定下来,拿到了一个公司的offer,不过被当白菜了,正在商量薪资方面的事情。随着百度面试的失败,梦想再次破灭。想想这一年来的奋斗,别是一番滋味在心头。突然想起一句话:踏歌长行,梦想永在!
说程序员是幸福的,因为我们每天都会和大脑过意不去,故意去挑战,因为我们总是在与IDE经历了一系列的战斗后,露出欣喜的表情,也因为我们总是以自己从事复杂的、高智商的工作而骄傲、自豪!
本章是Java之美[从菜鸟到高手演变]系列之集合类。集合类是Java语言中非常重要的一类知识,Java很多的应用都离不开它。我们有必要认真研究一下。
本博客永久更新,如有转载,
请说明出处:http://blog.csdn.NET/zhangerqing
如有问题,请联系本人: egg
邮箱:xtfggef@gmail.com
微博:http://weibo.com/xtfggef
一、集合类简介
数组是很常用的一种的数据结构,我们用它可以满足很多的功能,但是,有时我们会遇到如下这样的问题:
1、我们需要该容器的长度是不确定的。
2、我们需要它能自动排序。
3、我们需要存储以键值对方式存在的数据。
如果遇到上述的情况,数组是很难满足需求的,接下来本章将介绍另一种与数组类似的数据结构——集合类,集合类在Java中有很重要的意义,保存临时数据,管理对象,泛型,Web框架等,很多都大量用到了集合类。
常见的集合类有这些种:
实现Collection接口的:Set、List以及他们的实现类。
实现Map接口的:HashMap及其实现类,我们常用的有Map及其实现类HashMap,HashTable,List、Set及其实现类ArrayList、HashSet,因为集合类是很大的一块内容,我们不方便把它的全部内容写出来,只能慢慢的增加,希望各位读者有自己想法的,踊跃向我提出,我们共同打造精美的博客,供广大编程爱好者学习,下面我我们通过一个图来整体描述一下:
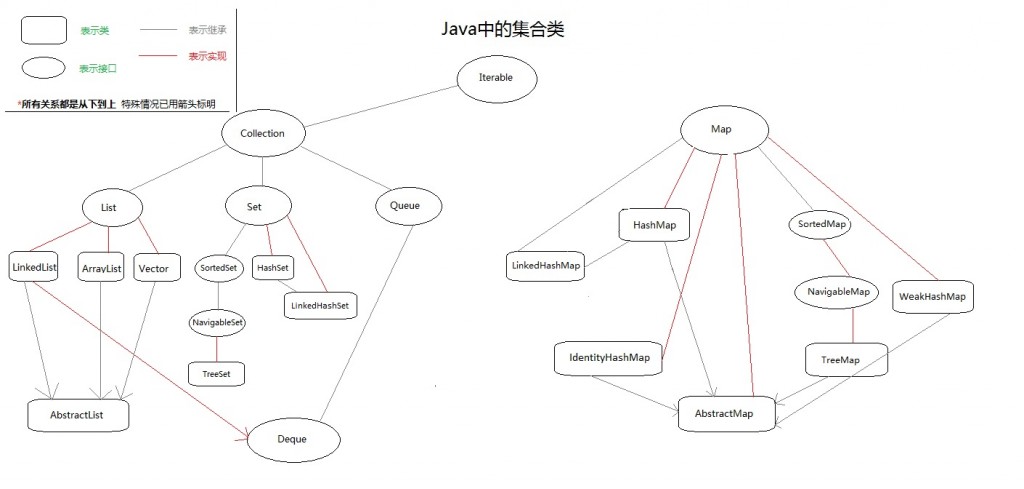
这个图片没法显示的很清楚,所以我将原始图片上传到了我的资源里:http://download.csdn.Net/detail/zhangerqing/4711389。愿意看清楚的就去下吧。
下面的表格也许可以更直接的表现出他们之间的区别和联系:
| 接口 | 简述 | 实现 | 操作特性 | 成员要求 |
| Set | 成员不能重复 | HashSet | 外部无序地遍历成员 | 成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 |
| TreeSet | 外部有序地遍历成员;附加实现了SortedSet, 支持子集等要求顺序的操作 | 成员要求实现caparable接口,或者使用 Comparator构造TreeSet。成员一般为同一类型。 | ||
| LinkedHashSet | 外部按成员的插入顺序遍历成员 | 成员与HashSet成员类似 | ||
| List | 提供基于索引的对成员的随机访问 | ArrayList | 提供快速的基于索引的成员访问,对尾部成员的增加和删除支持较好 | 成员可为任意Object子类的对象 |
| LinkedList | 对列表中任何位置的成员的增加和删除支持较好,但对基于索引的成员访问支持性能较差 | 成员可为任意Object子类的对象 | ||
| Map | 保存键值对成员,基于键找值操作,compareTo或compare方法对键排序 | HashMap | 能满足用户对Map的通用需求 | 键成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 |
| TreeMap | 支持对键有序地遍历,使用时建议先用HashMap增加和删除成员,最后从HashMap生成TreeMap;附加实现了SortedMap接口,支持子Map等要求顺序的操作 | 键成员要求实现caparable接口,或者使用Comparator构造TreeMap。键成员一般为同一类型。 | ||
| LinkedHashMap | 保留键的插入顺序,用equals 方法检查键和值的相等性 | 成员可为任意Object子类的对象,但如果覆盖了equals方法,同时注意修改hashCode方法。 | ||
| IdentityHashMap | 使用== 来检查键和值的相等性。 | 成员使用的是严格相等 | ||
| WeakHashMap | 其行为依赖于垃圾回收线程,没有绝对理由则少用 |
|
(上图来源于网友的总结,已不知是哪位的原创,恕不贴出地址,如原作者看到请联系我,必将贴出链接!)
实现Collection接口的类,如Set和List,他们都是单值元素(其实Set内部也是采用的是Map来实现的,只是键值一样,从表面理解,就是单值),不像实现Map接口的类一样,里面存放的是key-value(键值对)形式的数据。这方面就造成他们很多的不同点,如遍历方式,前者只能采用迭代或者循环来取出值,但是后者可以使用键来获得值得值。
二、基本方法及使用
---------------------------
实现Map接口的
HashMap
Set的实现类HashSet,底层还是调用Map接口来处理,所以,此处,我将说下Map接口及其实现类的一些方法。Map接口中的原始方法有:
public abstract int size();
public abstract boolean isEmpty();
public abstract boolean containsKey(Object paramObject);
public abstract boolean containsValue(Object paramObject);
public abstract V get(Object paramObject);
public abstract V put(K paramK, V paramV);
public abstract V remove(Object paramObject);
public abstract void putAll(Map<? extends K, ? extends V> paramMap);
public abstract void clear();
public abstract Set<K> keySet();
public abstract Collection<V> values();
public abstract Set<Entry<K, V>> entrySet();
public abstract boolean equals(Object paramObject);
public abstract int hashCode();
此处细心的读者会看到,每个方法前都有abstract关键字来修饰,其实就是说,接口中的每个方法都是抽象的,有的时候我们写的时候不加abstract关键字,但是在编译的过程中,JVM会给加上的,所以这点要注意。抽象的方法意味着它没有方法实现体,同时必须在实现类中重写,接下来我们依次分析一下他们的实现类HashMap中是怎么做的。
HashMap的设计复杂而又巧妙,用处广泛,值得我们深究一下,因为HashMap是一块很大很重要的知识点,而在这儿我们重点介绍集合类,所以请看这篇文章,关于【深入解读HashMap内部结构】的文章。
重点方法介绍:
首先是构造方法,大多数情况下,我们采取无参的构造函数来构造哈希表,
此处先介绍三个重要的变量:loadFactor、threshold、table,loadFactor是一个加载因子,threshold是临界值,table说明哈希表的底层,其实是个数组。可以看看他们的声明方式:
transient Entry[] table;;
int threshold;
final float loadFactor;
细心的读者似乎又发现一个新问题,为什么table前面采用的是transient关键字呢,那我们得闲来研究下声明为transient关键字的含义:变量如果被声明为transient类型的话,那么在序列化的时候,忽略其的值,就是说此处的table,如果将要进行持久化的话,是不会对table的值进行处理的,直接忽略,为什么此处table会这样处理呢?因为HashMap的存储结构,其实就是一个数组+多个链表,数组里存放对象的地址,链表存放数据,所以对地址进行持久化是没有任何意义的。关于这块知识,我会在另一篇文章【深入解读HashMap内部结构】中重点介绍。
HashMap的初始容量为0,每增加一对值,容量曾1,这点好理解,我们通过一个小的例子,来看看HashMap的基本使用方法。
输出:
HashMap的初始值:0
HashMap是否为空:是
3
HashMap是否为空:否
niuniu 2 hashcode:-1045196352
egg 3 hashcode:100357
erqing 1 hashcode:-1294670850
true
true
1955200455
此处附一个利用HashMap来简单处理问题的例子,需求在注释中已经给出,希望读者好好看看,代码不难,但是很多的面试及面试题都用到这个思路,笔者曾经面试的时候,经常会被问题这题的思想,但是就是没有去亲自实现一下,以致在hashmap的操作上被难住了。
关于HashMap的一些其他底层的东西及与HashTable的区别和联系,我会在另一篇文章里介绍,此处暂不多说。
实现Collection接口的
ArrayList
后面的博文,我会以分析和例子为主,毕竟源码这种东西,不适合大量的贴出来,大家都会自己去看,有些不好懂的地方或者容易忽略的知识,我会贴出来,其它的建议读者自己去看JDK源码。ArrayList底层采用数组实现,具有较高的查询速度。
boolean isEmpty():如果容器里面没有保存任何元素,就返回true。
boolean contains(Object):如果容器持有参数Object,就返回true。
Iterator iterator():返回一个可以在容器的各元素之间移动的Iterator。
Object[] toArray():返回一个包含容器中所有元素的数组。
Object[] toArray(Object[] a):返回一个包含容器中所有元素的数组,且这个数组不是普通的Object数组,它的类型应该同参数数组a的类型相同(要做类型转换)。
void clear():清除容器所保存的所有元素。(“可选”)
boolean remove(Object o);
boolean add(Object):确保容器能持有你传给它的那个参数。如果没有把它加进去,就返回false。(这是个“可选”的方法,本章稍后会再作解释。)
boolean addAll(Collection):加入参数Collection所含的所有元素。只要加了元素,就返回true。
boolean containsAll(Collection):如果容器持有参数Collection所含的全部元素,就返回true
boolean removeAll(Collection):删除容器里面所有参数Collection所包含的元素。只要删过东西,就返回true。(“可选”)
boolean retainAll(Collection):只保存参数Collection所包括的元素(集合论中“交集”的概念)。如果发生过变化,则返回true。(“可选”)
boolean equals(Object o);
int hashCode();
int size():返回容器所含元素的数量。
这些方法也就是Set和List及它们的实现类里有的方法。
List接口在Collection接口的基础上,有添加了自己的一系列方法:
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);
List<E> subList(int fromIndex, int toIndex);
先看一下构造函数,和Map一样,我们同样习惯使用默认的无参构造函数,
此处elementData就是它底层用来存放数据的数组元素,仔细看一下,无论采用无参还有有参的构造
函数,最终都归结于一句话:this.elementData = new Object[paramInt];如果没有传入参数的话,会默认开辟一个10个字节大小的空间,可是当我们用的时候,我们写下如下的语句:
List<String> list = new ArrayList<String>( );
List<String> list = new ArrayList<String>(5);
当我们输出它的size值时:System.out.println(list.size());我们发现,输出的都是0.这让人貌似有一丝迷惑,明明是10或者5,这儿应该用清楚,elementData数组的长度并不是size的值,size是里面元素的个数,上面的10或者是5,意思是向内容开辟10个大小的空间,初始化的时候开辟一定数量的内存,但是里面并没有放任何对象,所以用size()计算得到的结果仍为0.
这时,我们又有新问题了,因为我们知道List是可以自动扩容的,这个功能就取决于如下的方法:
ensureCapacity(int paramInt)用来初始化或者扩大ArrayList的空间。
从上述代码中可以看出,数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
ArrayList还给我们提供了将底层数组的容量调整为当前列表保存的实际元素的大小的功能。它可以通过trimToSize方法来实现。代码如下:
通过ensureCapacity(int paramInt)方法可以提高ArrayList的初始化速度,请看下面的代码:
输出:
没有调用ensureCapacity()方法所用时间:102ms
调用ensureCapacity()方法所用时间:46ms
很明显,使用ensureCapacity()能提高不少效率!
下面实现一个简单的例子,来展现下ArrayList的基本使用。
ArrayList基于数组实现,所以它具备数组的特点,即查询速度较快,但是修改、插入的速度却有点儿慢,但是,下面将要介绍的LinkedList就是来解决这个问题的,LinkedList基于链表,与ArrayList互补,所以实际开发中我们应该按照自己的需求来定到底用哪一个。
Where there is a will,there is a way.With the boat burned,Qin's territory final belonged to Chu.
The God won't cheat the hard working people.As the undergo self-imposed hardships
so as to strengthen his resolve,three thousand soldiers from Yue destroyed the country of Wu!
LinkedList
LinkedList底层采用双向循环列表实现,进行插入和删除操作时具有较高的速度,我们还可以使用LinkedList来实现队列和栈。
这是LinkedList的原始存储模型,因为是双向循环列表,我们可以回忆一下数据结构中双向列表是什么情况:一个数据data,两个指针,一个指向前一个节点,名为previous,一个指向下一个节点,名为next,但是循环怎么体现了,来看下她的无参构造函数:
头尾相等,就是说初始化的时候就已经设置成了循环的。仔细观察源码,不难理解,如果熟悉数据结构的读者,一定很快就能掌握她的原理。下面我简单分析一个操作,就是LinkedList的add()。读者可以通过这个自己去理解其他操作。
我们先来观察下上面给出的Entity类,构造方法有三个参数,第二个是她的next域,第三个是她的previous域,所以上述代码1行处将传进来的entry实体,即header对象作为newEntry的next域,而将entry.previous即header.previous作为previous域。也就是说在header节点和header的前置节点之间插入新的节点。看下面的图:
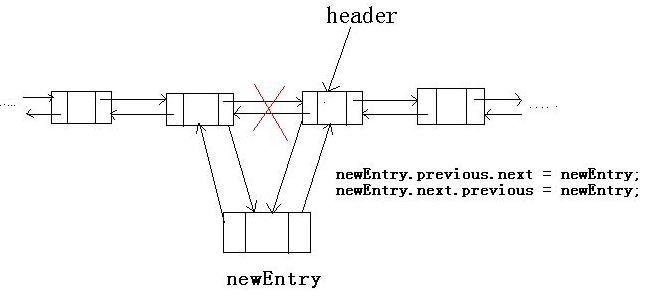
一目了然。
欢迎广大读者进行建议、反馈,笔者定会及时改正,更新!
其他的道理一样,下面我会给出一个LinkedList使用的例子,需要注意的地方,我会特别说明。
比较简单,其他的方法,请读者自己去尝试,结合源码。
实现Map接口的
HashMap
关于HashMap的详细介绍,请看深入解析HashMap章节
WeakHashMap
理解该集合类之前,建议先去了解Java的垃圾回收机制,WeakHashMap多用于缓存系统,就是说在系统内存紧张的时候可随时进行GC,但是如果内存不紧张则可以用来存放一些缓存数据。因为如果使用HashMap的话,它里面的值基本都是强引用,即使内存不足,它也不会进行GC,这样系统就会报异常。看一下WeakHashMap中Entry的实现:
Entry继承了WeakReference类,且在构造函数中构造了Key的弱引用,当进行put或者get操作时,都会调用一个函数叫expungeStaleEntries(),如下:
就是用来判断,如果key存在弱引用,则进行垃圾回收,所以这个就是WeakHashMap的工作原理。它与HashMap的区别就是:数据量大的时候,它可根据内存的情况,自动进行垃圾回收。如果手动将key置为强引用,那么它将和HashMap变得一样,失去其功能。
三、比较(性能,功能方面)
这一块主要就是对我们平时接触的这些集合类做一个简单的总结,一方面有助于自己整理思路,再者面试的时候,面试官总喜欢问一些他们之间的区别,凡是Java面试,几乎都要问到集合类的东西,问的形式有两种:一、总体介绍下集合类有哪些。这个问题只要把我上文中的图介绍一下就行了。二、比较一下XXX和XXXX。当然了,肯定包括相同点和不同的地方。这个稍微麻烦一点,需要我们彻底理解了,才能回答的比较准确。以下是我对常被比较的一些类的分析:
1、HashMap和HashTable
相同点:二者都实现了Map接口,因此具有一系列Map接口提供的方法。
不同点:
1、HashMap继承了AbstractMap,而HashTable继承了Dictionary。
2、HashMap非线程安全,HashTable线程安全,到处都是synchronized关键字。
3、因为HashMap没有同步,所以处理起来效率较高。
4、HashMap键、值都允许为null,HashTable键、值都不允许有null。
5、HashTable使用Enumeration,HashMap使用Iterator。
这些就是一些比较突出的不同点,实际上他们在实现的过程中会有很多的不同,如初始化的大小、计算hash值的方式等等。毕竟这两个类包含了很多方法,有很重要的功能,所以其他不同点,请感兴趣的读者自己去看源码,去研究。笔者推荐使用HashMap,因为她提供了比HashTable更多的方法,以及较高的效率,如果大家需要在多线程环境中使用,那么用Collections类来做一下同步即可。
2、Set接口和List接口
相同点:都实现了Collection接口
不同点:
1、Set接口不保证维护元素的顺序,而且元素不能重复。List接口维护元素的顺序,而且元素可以重复。
2、关于Set元素如何保证元素不重复,我将在下面的博文中给出。
3、ArrayList和LinkList
相同点:都实现了Collection接口
不同点:ArrayList基于数组,具有较高的查询速度,而LinkedList基于双向循环列表,具有较快的添加或者删除的速度,二者的区别,其实就是数组和列表的区别。上文有详细的分析。
4、SortedSet和SortedMap
二者都提供了排序的功能。 来看一个小例子:
输出:5 2 3 0 1
从结果看得出:SortedMap具有自动排序功能
5、TreeMap和HashMap
HashMap具有较高的速度(查询),TreeMap则提供了按照键进行排序的功能。
6、HashSet和LinkedHashSet
HashSet,为快速查找而设计的Set。存入HashSet的对象必须实现hashCode()和equals()。
LinkedHashSet,具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序),于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
7、TreeSet和HashSet
TreeSet: 提供排序功能的Set,底层为树结构 。相比较HashSet其查询速度低,如果只是进行元素的查询,我们一般使用HashSet。
8、ArrayList和Vector
同步性:Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步的。
数据增长:当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半
9、Collection和Collections
Collection是一系列单值集合类的父接口,提供了基本的一些方法,而Collections则是一系列算法的集合。里面的属性和方法基本都是static的,也就是说我们不需要实例化,直接可以使用类名来调用。下面是Collections类的一些功能列表:
生成单元素集合
Collections中的单元素集合指的是集合中只有一个元素而且集合只读。
Collections.singletonList——用来生成只读的单一元素的List
Collections.singletonMap——用来生成只读的单Key和Value组成的Map
Collections.singleton——用来生成只读的单一元素的Set
如下面的例子:
Collections.singletonMap(1, 1)生成一个单元素的map,如果加上1处的代码,会报异常。
Checked集合
Checked集合具有检查插入集合元素类型的特性,例如当我们设定checkedList中元素的类型是String的时候,如果插入其他类型的元素就会抛出ClassCastExceptions异常,Collections中提供了以下生成Checked集合的方法checkedCollection,checkedList,checkedMap,checkedSet,checkedSortedMap,checkedSortedSet
同步集合
Collections类提供一系列同步方法,为一些非线程安全的集合类提供同步机制。
查找替换
fill——使用指定元素替换指定列表中的所有元素。
frequency——返回指定 collection 中等于指定对象的元素数。
indexOfSubList—— 返回指定源列表中第一次出现指定目标列表的起始位置,如果没有出现这样的列表,则返回 -1。
lastIndexOfSubList——返回指定源列表中最后一次出现指定目标列表的起始位置,如果没有出现这样的列表,则返回-1。
max—— 根据元素的自然顺序,返回给定 collection 的最大元素。
min——根据元素的自然顺序 返回给定 collection 的最小元素。
replaceAll——使用另一个值替换列表中出现的所有某一指定值。
附一个小例子:
集合排序
Collections还提供了集中对集合进行排序的方法。
reverse——对List中的元素进行转置
shuffle——对List中的元素随即排列
sort——对List中的元素排序
swap——交换List中某两个指定下标位元素在集合中的位置。
rotate——循环移动
输出:
排序前:
5 2 1 9 0
排序后
0 1 2 5 9
下面是关于rotate(List<?> list, int distance)的一个例子:
读者可以多次换换第二个参数,来观察它的变化。
总结一下,带Tree的集合类,底层一般是基于二叉树的,所以具有自动排序功能。有些功能方面差别不大,具体开发的时候需根据实际情况选择使用哪个类。
本博客持久更新,欢迎大家积极建议、补充!如有转载,敬请说明出处!
四、常见问题
这块内容,我讲就一些常见的问题做一下分析,欢迎广大读者提出更多的问题,我们一起讨论,解决!
1、Set集合如何保证对象不重复
这儿我采用HashSet来实现Set接口,先看个例子:
输出:
size:1
hello
说明,Set集合不允许有重复出现的对象,且最终的判断是根据equals()的。其实原理是这样的:HashSet的底层采用HashMap来存放数据,HashMap的put()方法是这样的:
当向HashMap中添加元素的时候,首先计算元素的hashcode值,然后根据1处的代码计算出Hashcode的值,再根据2处的代码计算出这个元素的存储位置,如果这个位置为空,就将元素添加进去;如果不为空,则看3-4的代码,遍历索引为i的链上的元素,如果key重复,则替换并返回oldValue值。<关于这部分内容,请看另一篇文章:《深入解读HashMap》有详细介绍>
2、集合类排序问题
一种情况是集合类本身自带排序功能,如前面说过的TreeSet、SortedSet、SortedMap等,另一种就是本身不带排序功能,我们通过为需要排序的类实现Comparable或者Comparator接口来实现。
先来看两个例子,一个是实现Comparable的,一个是实现Comparator的,为了方便,我将类都写在了一个文件中。
下面是实现Comparator接口的:
通过上面的这两个小例子,我们可以看出,Comparator和Comparable用于不同的场景,实现对对象的比较从而进行排序。
总结为:
相同点:
1、二者都可以实现对象的排序,不论用Arrays的方法还是用Collections的sort()方法。
不同点:
1、实现Comparable接口的类,似乎是预先知道该类将要进行排序,需要排序的类实现Comparable接口,是一种“静态绑定排序”。
2、实现Comparator的类不需要,设计者无需事先为需要排序的类实现任何接口。
3、Comparator接口里有两个抽象方法compare()和equals(),而Comparable接口里只有一个方法:compareTo()。
4、Comparator接口无需改变排序类的内部,也就是说实现算法和数据分离,是一个良好的设计,是一种“动态绑定排序”。
5、Comparator接口可以使用多种排序标准,比如升序、降序等。
3、使用for循环删除元素陷阱
先来看看下面这个程序:
读者朋友们可以先猜猜这个程序输出什么?按我们的思路,应该是输不出什么,但是执行它,输出的却是:B。这是为什么呢?我们分部分析下这个程序,当地一步remove完后,集合内还剩2个元素,此时i为1,而list.size()的值为2,从0开始的话,i为1时,正好指向第二个元素,也就是说当remove完A后,直接就跳到C,将B漏了。
解决办法:
欢迎广大读者不断建议,指出不足,我们一起学习,一起进步!
五、应用示例
本博客永久更新,如有转载,
请说明出处:http://blog.csdn.net/zhangerqing
如有问题,请联系本人: egg
邮箱:xtfggef@gmail.com
微博:http://weibo.com/xtfggef
具体应用方面我会不断更新,如果读者有建议,请及时提出!
未完,待续。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号