
Dom4j解析和生成XML文档
source: http://blog.csdn.net/chenghui0317/article/details/11486271
作者: 永恒の_☆ 地址: http://blog.csdn.net/chenghui0317/article/details/11486271
一、前言
dom4j是一套非常优秀的Java开源api,主要用于读写xml文档,具有性能优异、功能强大、和非常方便使用的特点。 另外xml经常用于数据交换的载体,像调用webservice传递的参数,以及数据做同步操作等等, 所以使用dom4j解析xml是非常有必要的。
二、准备条件
dom4j.jar
下载地址:http://sourceforge.net/projects/dom4j/
三、使用Dom4j实战
1、解析xml文档
实现思路:
<1>根据读取的xml路径,传递给SAXReader之后 返回一个Document文档对象;
<2>然后操作这个Document对象,获取下面的节点以及子节点的信息;
具体代码如下:
另外上面的xml在src下面,module01.xml具体如下:
接下来执行该类的main方法,console效果如下:

由此以知:
<1>dom4j读取xml文件方式有很多样;
<2>取出element对象的文本和标签名称都非常简单;
<3>并且修改元素的文本和标签名称都非常方便,但是不会写入到磁盘xml文件中。
上面只是简单的获取了xml的根目录的元素,接下来使用Iterator 迭代器循环document文档对象。
具体代码如下:
另外上面的xml在src下面,module02.xml具体如下: 接下来执行该类的main方法,console效果如下:
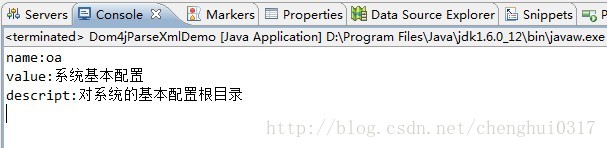
由此以知:
<1>dom4j迭代xml子元素非常的效率和便捷;
但是上面只是简单的迭代了xml的子节点元素,但是如果xml规则比较复杂,比如接下来要测试的module03.xml,具体如下:
因为他们的结构不一样,直接迭代的话 会报错:
java.lang.NullPointerException
所以这个时候需要小心使用了,每次都不能把元素直接放进去迭代。具体实现代码如下:
接下来执行该类的main方法,console效果如下:
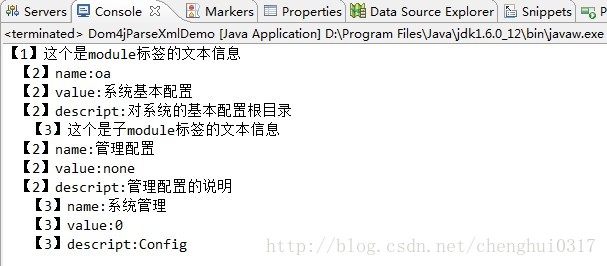
好了,这下可以解决迭代文档出现空引用的情况了。
另外代码其实可以重构一下,因为循环里面取出子元素的操作都是重复的,可以利用递归改善,但是可读性会变差一点。
如果有些时候需要获取xml中所有的文本信息,又或者别人传递的xml格式不规范,比如标签内名称大小写,虽然xml不区分大小写,但是必须成对出现,所以为了避免这种情况,索性可以将全部的标签名称换为大写,具体代码如下:
运行之后效果图如下:

2、生成xml文档
dom4j能够解析xml,同样肯定能生成xml,而且使用起来更加简单方便。
实现思路:
<1>DocumentHelper提供了创建Document对象的方法;
<2>操作这个Document对象,添加节点以及节点下的文本、名称和属性值;
<3>然后利用XMLWriter写入器把封装的document对象写入到磁盘中;
具体代码如下:
运行代码效果如下:
然后去c盘下面查看是否创建成功,结果发现在xml文件中的内容与控制台输出的内容一样。
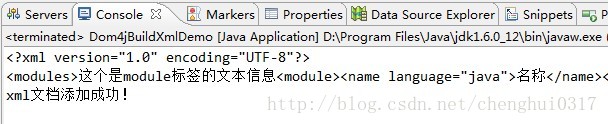
另外上面生成xml并没有指定编码格式,但是还是显示了UTF-8,说明这个是默认的编码格式,如果想重新指定可以在写入到磁盘之前加上document.setXMLEncoding("GBK");就好了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号