
SQL Server里PIVOT运算符的”红颜祸水“
在今天的文章里我想讨论下SQL Server里一个特别的T-SQL语言结构——自SQL Server 2005引入的PIVOT运算符。我经常引用这个与语言结构是SQL Server里最危险的一个——很快你就会知道为什么。在我们进入特定问题和陷阱前,首先我想给你下使用SQL Server里的PIVOT能实现什么的一个基本概述。
概述
SQL Server里PIVOT运算符背后的基本思想是在T-SQL查询期间,你可以旋转行为列。运算符本身是SQL Server 2005后引入的,主要用在基于建立在实体属性值模型(Entity Attribute Value model (EAV))原则上的数据库。EAM模型背后的想法是你可以扩展数据库实体,而不需要进行数据库架构的修改。因此EAV模型存储实体的所有属性以键/值对存储在一个表里。我们来看下面一个简单的键/值对模型的表。

CREATE TABLE EAVTable ( RecordID INT NOT NULL, Element CHAR(100) NOT NULL, Value SQL_VARIANT NOT NULL, PRIMARY KEY (RecordID, Element) ) GO -- Insert some records INSERT INTO EAVTable (RecordID, Element, Value) VALUES (1, 'FirstName', 'Woody'), (1, 'LastName', 'Tu'), (1, 'City', 'Linhai'), (1, 'Country', 'China'), (2, 'FirstName', 'Bill'), (2, 'LastName', 'Gates'), (2, 'City', 'Seattle'), (2, 'Country', 'USA') GO
如你所见,我们插入2个数据库实体到表里,每个实体包含多个属性。在表里每个属性只是额外的记录。如果你像扩展实体更多的属性,你只插入额外的记录到表里,而没有必要进行数据库架构修改——这就是开放数据库架构的“威力”……
查询这样的EAV表显然很困难,因为你处理的是平键/值对的数据结构。因此你要旋转表内容,行旋转为列。你可以进行用自带的PIVOT运算符进行这个旋转,或者通过传统的CASE表达式进行纯手工来实现。在我们进入PIVOT细节前,我想给你展示下通过手工使用T-SQL和一些CASE表达式来实现。如果你手工进行旋转,你的T-SQL查询需要实现3个阶段:
- 分组阶段(Grouping Phase)
- 摊开阶段(Spreading Phase)
- 聚合阶段(Aggregation Phase)
在分组阶段(Grouping Phase)我们压缩我们的EAV表为不同的数据库实体。在这里我们在RecordID列进行一个GROUP BY。在第2阶段的,摊开阶段(Spreading Phase),我们使用多个CASE表达式来旋转行为列。最后在聚合阶段(Aggregation Phase)我们使用MAX表达式来为每个行和列返回不同值。我们来看下列T-SQL代码。
1 -- Pivot the data with a handwritten T-SQL statement. 2 -- Make sure you have an index defined on the grouping column. 3 SELECT 4 RecordID, 5 -- Spreading and aggregation phase 6 MAX(CASE WHEN Element = 'FirstName' THEN Value END) AS 'FirstName', 7 MAX(CASE WHEN Element = 'LastName' THEN Value END) AS 'LastName', 8 MAX(CASE WHEN Element = 'City' THEN Value END) AS 'City', 9 MAX(CASE WHEN Element = 'Country' THEN Value END) AS 'Country' 10 FROM EAVTable 11 GROUP BY RecordID -- Grouping phase 12 GO
从代码里可以看到,很容易区分每个阶段,还有它们如何映射到T-SQL查询。下图给你展示了查询结果,最后我们把行转为了列。
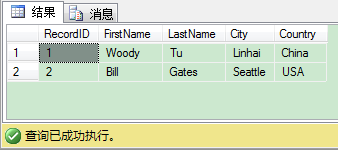
PIVOT运算符
自SQL Server 2005起(差不多10年前了!),微软在T-SQL里引入PIVOT运算符。使用那个运算符你可以进行同样的转换(行到列),只要一个原生运算符即可。听起来很简单,很有前景,不是么?下列代码显示了使用原生PIVOT运算符进行同样的转换。
1 -- Perform the same query with the native PIVOT operator. 2 -- The grouping column is not specified explicitly, it's the remaining column 3 -- that is not referenced in the spreading and aggregation elements. 4 SELECT 5 RecordID, 6 FirstName, 7 LastName, 8 City, 9 Country 10 FROM EAVTable 11 PIVOT(MAX(Value) FOR Element IN (FirstName, LastName, City, Country)) AS t 12 GO
当你执行那个查询时,你会收到和刚才图片一样的结果。但当你看PIVOT运算符语法时,和手动方法相比,你会看到一个很大的区别:
你只能指定分摊和聚合元素!不能明确定义分组元素!
分组元素是你在PIVOT运算符里没有引用的剩下列。在我们的例子里,我们没有在PIVOT运算符里没有引用RecordID列,因此这个列在分组阶段(Grouping Phase)被使用。如果我们随后修改数据库架构,这会带来有趣的副作用,例如对基本表增加额外列:
1 -- Add a new column to the table 2 ALTER TABLE EAVTable ADD SomeData CHAR(1) 3 GO
然后我们对其赋值:
1 UPDATE dbo.EAVTable SET SomeData=LEFT(CAST(Value AS VARCHAR(1)),1)
现在当你执行用PIVOIT运算符的同个查询时(在那somedata列都有非NULL值),你会拿回完全不同的结果,因为排序阶段现在是在RecordID和SomeData列(我们刚加的)上。
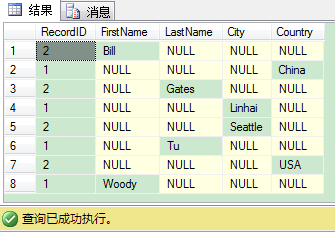
相比如果我们重新执行我们刚开始写的手工T-SQL查询会发生什么。它还是返回同样正确的结果。这是在SQL Server里,PIVOT运算符的其中一个最大的副作用:分组元素不能明确定义。为了克服这个问题,最佳实践是使用只返回需要列的表表达式。使用这个方法,如果你随后修改表架构还是没有问题,因从表表达式默认情况下额外的列还是没有返回。我们来看下列的代码:
1 -- Use a table expression to state explicitly which columns you want to 2 -- return from the base table. Therefore you can always control on which 3 -- columns the PIVOT operator is performing the grouping. 4 SELECT 5 RecordID, 6 FirstName, 7 LastName, 8 City, 9 Country 10 FROM 11 ( 12 -- Table Expression 13 SELECT RecordID, Element, Value FROM EAVTable 14 ) AS t 15 PIVOT(MAX(Value) FOR Element IN (FirstName, LastName, City, Country)) AS t1 16 GO
从代码里可以看到,我通过一个表表达式输送给PIVOT运算符。而且在表表达式里,你从表里只选择需要的列。这就意味着以后你可以修改表架构也会破坏PIVOT查询的结果。
小结
我希望这篇文章已向你展示了在SQL Server里,为什么PIVOT运算符是非常危险的。这个语法本身带来了非常高效的代码,但作为副作用你不能直接指定分组元素。因次你应该确保使用一个表表达式来定义输送给PIVOT运算符的列来保证给出结果的确定性。
用PIVOT运算符你有什么经历?你是否喜欢它?如果你不喜欢它,你想要什么改变?
感谢关注!
参考文章:
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?