终极事务处理(XTP,Hekaton)——万能大招?
在SQL Server 2014里,微软引入了终极事务处理(Extreme Transaction Processing),即大家熟知的Hekaton。我在网上围观了一些文档,写这篇文章,希望可以让大家更好的理解Hekaton,它的局限性,还有它惊艳的全新内存数据库技术。这篇文章会通过下面几个方面来讲解Hekaton:
- 概况
- 可扩展性(Scalability)
- 局限性(Limitations)
1.概况
让我们从XTP的简洁概况开始。像XTP这样的内存数据库技术首要目标非常明确:尽可能高效的使用我们现有的服务器硬件。我们来看当下的现代服务器系统硬件,你会发现下列问题/局限性:
- 传统存储(机械硬盘)非常缓慢,企业若准备SSD存储非常昂贵。另一方面主要内存(RAM)却非常便宜,只要花100美元就可以配置到64GB内存,这可是标准版的SQL Server的最大支持内存数。
- CPU速度很难再提升。现在我们困在了3-4GHZ,再快点不太可能(当你尝试超频时你就会有这个体会)。
- 传统的关系型数据库管理系统(RDBMS)不能线性扩展,主要是因为内部的锁,阻塞和封锁(Locking, Blocking, and Latching)机制(数据结构的内存里锁,当它们被读写访问时)。
因此为了克服这些限制,你需要这样的技术:
- 使用RAM将数据全部存在内存里来克服传统旋转硬盘(机械硬盘)的速度限制。
- 尽可能划算的使用当下有速度限制的CPU,使用尽可能少的CPU指令数,来实现近可能快的去执行关系数据库管理系统(RDBMS)的查询。
- 当对你的关系数据库管理系统(RDBMS)执行读/写操作时,完全避免锁/阻塞,和闩锁(Locking/Blocking, and Latching)。
这3点就是SQL Server 2014里终极事务处理(Extreme Transaction Processing )的3大支柱:

使用XTP你可以在内存里缓存整个表(即所谓的内存优化表(Memory Optimized Tables)),存储过程可以编译为本机C代码,而且对于内存优化表,锁/阻塞和闩锁(Locking/Blocking, and Latching)这些机制都是完全没有的,因为XTP是基于乐观的多版本并发控制(Multi Version Concurrency Control ,MVCC)的。我们来详细看下这3大支柱。
内存中的存储(In-Memory Storage)
对于服务器系统,内存越来越便宜了。你只要花几百美元就可以装备你的服务器为64G内存,64GB内存可是SQL Server标准版本支持的最大内存。因此XTP表(即内存优化表)是完全存在内存里的。从SQL Server角度来看,内存表的所有数据存在于FILESTREAM文件组,在SQL Server启动时,它们从文件组读取,然后在起飞时重建你的所有索引。
这也给你的目标恢复时间(Recovery Time Objective,RTO)带来巨大压力,因为一启动你所有索引都被重建完成后,你的数据库才是在线状态。你的FILESTREAM文件组所存储的存储系统速度,因此也会直接影响目标恢复时间。因此你可以在FILESTREAM文件组里放置多个容器,这样的话你可以在启动期间分散I/O到多个存储系统,从而让你的数据库尽快进入在线状态。
在CTP1里,XTP只支持所谓的Hash-Indexes,它是在内存里完全存储在哈希表里。SQL Server目前能查找和扫描Hash-Indexes。从CTP2起,微软会引入所谓的Range Indexes,这样可以是你的范围查询非常,非常快。Range Indexes是基于所谓的Bw-Tree。
每个内存优化表也是编译为本地C代码。对每个表你都会得到一个DLL,这个是通过cl.exe编译的(微软C语言编译器,SQL Server 2014 自带)。生成的DLL然后载入sqlservr.exe 的进程空间,这个可以在sys.dm_os_loaded_modules里看到。编译本身在独立的线程里完成,这就是说你眼疾手快的话,你可以在任务管理器里看到cl.exe。下面代码给你展示了描述你的表的典型C语言代码:
1 struct hkt_277576027 2 { 3 struct HkSixteenByteData hkc_1; 4 __int64 hkc_5; 5 long hkc_2; 6 long hkc_3; 7 long hkc_4; 8 }; 9 struct hkis_27757602700002 10 { 11 struct HkSixteenByteData hkc_1; 12 }; 13 struct hkif_27757602700002 14 { 15 struct HkSixteenByteData hkc_1; 16 }; 17 __int64 CompareSKeyToRow_27757602700002( 18 struct HkSearchKey const* hkArg0, 19 struct HkRow const* hkArg1) 20 { 21 struct hkis_27757602700002* arg0 = ((struct hkis_27757602700002*)hkArg0); 22 struct hkt_277576027* arg1 = ((struct hkt_277576027*)hkArg1); 23 __int64 ret; 24 ret = (CompareKeys_guid((arg0->hkc_1), (arg1->hkc_1))); 25 return ret; 26 } 27 __int64 CompareRowToRow_27757602700002( 28 struct HkRow const* hkArg0, 29 struct HkRow const* hkArg1) 30 { 31 struct hkt_277576027* arg0 = ((struct hkt_277576027*)hkArg0); 32 struct hkt_277576027* arg1 = ((struct hkt_277576027*)hkArg1); 33 __int64 ret; 34 ret = (CompareKeys_guid((arg0->hkc_1), (arg1->hkc_1))); 35 return ret; 36 }
可以看到,代码本身并不直观,但你可以通过C的结构使用来看出你的表结构是如何被描述的。XTP的好处是内存优化表是完全自然集成到SQL Server关系引擎的其余部分。因此你可以使用传统的T-SQL代码查询这些表,可以进行备份/还原,还有集成HA/DR技术——微软在集成领域做了大量的伟大工作。除了内存中存储外,内存优化表也完全锁/阻塞,和闩锁,因为XTP是基于乐观的多版本并发控制(MVCC)原则。在无锁/闩锁数据结构部分我们会继续讨论这个。
你需要注意的最重要事实是:你应该将性能最重要的表移入内存,不是你所有的数据库。在接下来可扩展性部分里,我们会谈到哪些情况使用XTP是有意义的。通常你会把你数据库的95%使用基于传统磁盘的表存储,剩下的5%可以用内存优化表存储。
本地编译(Native Compilation)
微软申明当前硬件系统的第一个问题是:传统的,旋转的存储太慢。对此将表数据在内存中存储。第2个问题需要申明的是:当下处理器的时钟频率卡在了3-4GHz。我们不能再快了,因为会引入散热问题。因此当前时钟周期必须尽可能有效的管理。这是当下T-SQL实现的巨大问题,因为T-SQL只是一个解释性的语言。
在查询优化期间,SQL Server的查询优化器生成所谓的查询树,在执行期间,查询树从头运算符到所有的树节点被解读。这会引入大量的额外CPU指令,会在SQL Server里的每个执行计划里执行。另外每个运算符(即所谓的迭代器(Iterator))是以C++类实现的,这就意味在执行各个运算符时,会用到所谓的虚拟函数调用(Virtual Function Calls )。虚拟方法调用根据需要执行的CPU指令又是很占资源的。总之,在运行期间,执行计划被解读时,生成大量的CPU指令,即意味着当前的CPU没有高效的使用。你在浪费宝贵的CPU周期,可以用另外更好的方式来使用,从而提速你的整个工作。
因为查询引擎内的这些原因和限制,SQL Server引入XTP所谓的 本机编译的存储过程(Natively Compiled Stored Procedures)。背后的思路很简单:存储过程的整体编译为本地C语言代码,结果又是生成DLL,然后载入sqlservr.exe 的进程空间。因此在执行期间不需要解读,虚拟函数调用完全消除。这样的话做同样数量的工作却需要很少的CPU指令,这就意味着你的工作输出量会更高,因为在可用的CPU周期里可以做更多的工作。
在2013年的北美TechEd上指出,对于一些特定的存储过程,需要的CPU指令可以从1000000下降到近4000。想象下这个性能提升:25倍的性能提升!当我们谈到当前XPT里的局限时,你会发现,这个提升并不是免费的……下面的代码展示的是一个简单存储过程的典型C语言代码:
1 HRESULT hkp_309576141( 2 struct HkProcContext* context, 3 union HkValue valueArray[], 4 unsigned char* nullArray) 5 { 6 unsigned long yc = 0; 7 long var_2 = (-2147483647 - 1); 8 unsigned char var_isnull_2 = 1; 9 HRESULT hr = 0; 10 { 11 var_2 = 0; 12 var_isnull_2 = 0; 13 } 14 yc = (yc + 1); 15 { 16 while (1) 17 { 18 unsigned char result_7; 19 unsigned char result_isnull_7; 20 result_7 = 0; 21 result_isnull_7 = 0; 22 if ((! var_isnull_2)) 23 { 24 result_7 = (var_2 < 10000); 25 } 26 else 27 { 28 result_isnull_7 = 1; 29 } 30 if ((result_isnull_7 || (! result_7))) 31 { 32 goto l_5; 33 } 34 hr = (YieldCheck(context, yc, 18)); 35 if ((FAILED(hr))) 36 { 37 goto l_1; 38 } 39 yc = 0; 40 { 41 long expr_9; 42 long expr_10; 43 long expr_11; 44 __int64 expr_12; 45 struct hkt_277576027* rec2_17 = 0; 46 unsigned char freeRow_17 = 0; 47 short rowLength; 48 static wchar_t const hkl_18[] = 49 { 50 73, 51 78, 52 83, 53 69, 54 82, 55 84, 56 }; 57 static wchar_t const hkl_19[] = 58 { 59 91, 60 79, 61 114, 62 100, 63 101, 64 114, 65 115, 66 93, 67 }; 68 static wchar_t const hkl_20[] = 69 { 70 91, 71 79, 72 114, 73 100, 74 101, 75 114, 76 73, 77 68, 78 93, 79 }; 80 static wchar_t const hkl_21[] = 81 { 82 73, 83 78, 84 83, 85 69, 86 82, 87 84, 88 }; 89 static wchar_t const hkl_22[] = 90 { 91 91, 92 79, 93 114, 94 100, 95 101, 96 114, 97 115, 98 93, 99 }; 100 static wchar_t const hkl_23[] = 101 { 102 91, 103 67, 104 117, 105 115, 106 116, 107 111, 108 109, 109 101, 110 114, 111 73, 112 68, 113 93, 114 }; 115 static wchar_t const hkl_24[] = 116 { 117 73, 118 78, 119 83, 120 69, 121 82, 122 84, 123 }; 124 static wchar_t const hkl_25[] = 125 { 126 91, 127 79, 128 114, 129 100, 130 101, 131 114, 132 115, 133 93, 134 }; 135 static wchar_t const hkl_26[] = 136 { 137 91, 138 80, 139 114, 140 111, 141 100, 142 117, 143 99, 144 116, 145 73, 146 68, 147 93, 148 }; 149 static wchar_t const hkl_27[] = 150 { 151 73, 152 78, 153 83, 154 69, 155 82, 156 84, 157 }; 158 static wchar_t const hkl_28[] = 159 { 160 91, 161 79, 162 114, 163 100, 164 101, 165 114, 166 115, 167 93, 168 }; 169 static wchar_t const hkl_29[] = 170 { 171 91, 172 81, 173 117, 174 97, 175 110, 176 116, 177 105, 178 116, 179 121, 180 93, 181 }; 182 static wchar_t const hkl_30[] = 183 { 184 73, 185 78, 186 83, 187 69, 188 82, 189 84, 190 }; 191 static wchar_t const hkl_31[] = 192 { 193 91, 194 79, 195 114, 196 100, 197 101, 198 114, 199 115, 200 93, 201 }; 202 static wchar_t const hkl_32[] = 203 { 204 91, 205 80, 206 114, 207 105, 208 99, 209 101, 210 93, 211 }; 212 goto l_16; 213 l_16:; 214 expr_9 = 1; 215 expr_10 = 1; 216 expr_11 = 1; 217 expr_12 = 2045; 218 goto l_15; 219 l_15:; 220 rowLength = sizeof(struct hkt_277576027); 221 hr = (HkRowAlloc((context->Transaction), (Tables[0]), rowLength, ((struct HkRow**)(&rec2_17)))); 222 if ((FAILED(hr))) 223 { 224 goto l_8; 225 } 226 freeRow_17 = 1; 227 if ((! (nullArray[1]))) 228 { 229 (rec2_17->hkc_1) = ((valueArray[1]).SixteenByteData); 230 } 231 else 232 { 233 hr = -2113929186; 234 if ((FAILED(hr))) 235 { 236 { 237 CreateError((context->ErrorObject), hr, 5, 18, hkl_20, 16, hkl_19, hkl_18); 238 } 239 if ((FAILED(hr))) 240 { 241 goto l_8; 242 } 243 } 244 } 245 (rec2_17->hkc_2) = expr_9; 246 (rec2_17->hkc_3) = expr_10; 247 (rec2_17->hkc_4) = expr_11; 248 (rec2_17->hkc_5) = expr_12; 249 freeRow_17 = 0; 250 hr = (HkTableInsert((Tables[0]), (context->Transaction), ((struct HkRow*)rec2_17))); 251 if ((FAILED(hr))) 252 { 253 goto l_8; 254 } 255 goto l_13; 256 l_13:; 257 goto l_14; 258 l_14:; 259 hr = (HkRefreshStatementId((context->Transaction))); 260 if ((FAILED(hr))) 261 { 262 goto l_8; 263 } 264 l_8:; 265 if ((FAILED(hr))) 266 { 267 if (freeRow_17) 268 { 269 HkTableReleaseUnusedRow(((struct HkRow*)rec2_17), (Tables[0]), (context->Transaction)); 270 } 271 SetLineNumberForError((context->ErrorObject), 18); 272 goto l_1; 273 } 274 } 275 yc = (yc + 1); 276 { 277 __int64 temp_34; 278 if ((! var_isnull_2)) 279 { 280 temp_34 = (((__int64)var_2) + ((__int64)1)); 281 if ((temp_34 < (-2147483647 - 1))) 282 { 283 hr = -2113929211; 284 { 285 hr = (CreateError((context->ErrorObject), hr, 2, 23, 0)); 286 } 287 if ((FAILED(hr))) 288 { 289 goto l_33; 290 } 291 } 292 if ((temp_34 > 2147483647)) 293 { 294 hr = -2113929212; 295 { 296 hr = (CreateError((context->ErrorObject), hr, 2, 23, 0)); 297 } 298 if ((FAILED(hr))) 299 { 300 goto l_33; 301 } 302 } 303 var_2 = ((long)temp_34); 304 var_isnull_2 = 0; 305 } 306 else 307 { 308 var_isnull_2 = 1; 309 } 310 l_33:; 311 if ((FAILED(hr))) 312 { 313 SetLineNumberForError((context->ErrorObject), 28); 314 goto l_1; 315 } 316 } 317 yc = (yc + 1); 318 } 319 l_5:; 320 } 321 yc = (yc + 1); 322 ((valueArray[0]).SignedIntData) = 0; 323 l_1:; 324 return hr; 325 }
你可以看到有很多的GOTO语句,很容易让人想到是面条式代码(spaghetti code)。但这个不是我们讨论的范围……

无锁/闩锁数据结构(Lock/Latch Free Data Structures)
在我们刚才讨论XTP里的内存存储数据时,我已经说过对内存优化表,SQL Server是以无锁/闩锁数据结构实现的。这意味着当想要读写你的数据时,没有锁/闩锁涉及到的等待。在传统的像SQL Server这样关系数据库管理系统(RDBMS)里,写操作需要排它锁(Exclusive Locks (X) ),读操作需要共享锁(Shared Locks (S) )。2个锁是互斥的。
这就是说读阻塞写,写阻塞读。共享锁能把持多久是通过不同的事务隔离级别控制的。这个方式称为悲观并发控制(Pessimistic Concurrency)。随着SQL Server 2005的发布,微软引入了新的并发模式:乐观并发控制(Optimistic Concurrency)。使用乐观并发控制,读操作不再需要共享锁。直接从TempDb永驻的版本存储里读取。
使用新的隔离级别Read Committed Snapshot Isolation (RCSI) ,你回退到语句开始后不再有效的记录版本;使用隔离级别Snapshot Isolation,你回退到事务开始后不再有效的记录版本,这意味这在Snapshot Isolation里你可以重复的读。

设置这些新的隔离级别会大大促进你的整个工作量。但还有问题必须解决:
写还是需要排它锁,意味这并行写操作还是会相互阻塞。
当访问内存中的数据时(数据页,索引页),这些结构必须被闩锁,意味着它们只能被单线程访问。那是传统多线程并发问题,需要以此方式(闩锁)来解决。
因此XTP引入了基于多版本并发控制(Multi Version Concurrency Control ,MVCC)原则。使用MVCC就没有锁(甚至没有排它锁)和闩锁。写不会相互阻塞,因为哈希索引不是建立在页上的,数据访问是无闩锁的(内部是用哈希桶的哈希表来存储的)。在内存里不再有阻塞。当你使用XTP时,意味着卓越的吞吐量保证。但你的内存里访问没有闩锁时,你的性能瓶颈将转移,主要移向事务日志,在下个讨论XTP扩展性时我们会谈到。
MVCC的一个副作用是所谓的写-写冲突(Writer-Writer conflict)。你可以在XTP里对同个记录进行多个写操作,它们不会阻塞。第一个写会胜出,其他所有并发的写事务会失败。这意味着你需要修改你的代码来捕获这个特定错误,然后重试你的事务。这和死锁处理是一样的。如果在你程序里已经有死锁的实现方式,应该很容易对你的终端用户处理写-写冲突。
2.可扩展性(Scalability)
现在你应该大致理解了XTP的主要概念和背后的原因,但最大的问题是,在哪些情况下才可以使用XTP呢。我认为XTP不是一个随处可以部署的技术。你需要一个特殊情景来使用XTP才有意义。请相信我:我们现在所面临的大多数SQL Server问题,基本是索引问题,或者是硬件的错误配置问题(尤其是SANS领域)。
当你面对这样的问题时,我绝不推荐升级到XTP。一定要先分析下根源,在第一步就从根源解决问题。XTP应该是你最后才考虑的解决方法,因为当你的部分数据库使用XTP时,你的问题分析方法就会完全不一样了。对于XTP,你会遇到大量的各种限制。XTP是贼快(我可以说是TMD的快),但不是个历史奇迹(all-time wonder),不是每个地方都适用的。
微软推出XTP主要是为了克服加锁竞争(Latch Contention)问题。刚才你已经看到,当你访问数据页进行读写活动时,加锁竞争在内存里总会发生。当你的工作量越来越大,到了某个时间点,你就引入了加锁竞争,因为单线程访问内存里的这些页。这里最常见的例子就是最后页插入加锁竞争(Last Page Insert Latch Contention)。
这个问题很容易重现:按照最佳实践创建一个聚集键,这个键使用自增长来避免在聚集索引里的硬页分裂。你的工作量不会延伸——相信我!这里的问题是:在INSERT语句期间,在你的聚集索引里只有一个热块——最后页。下图展示了这个现象:
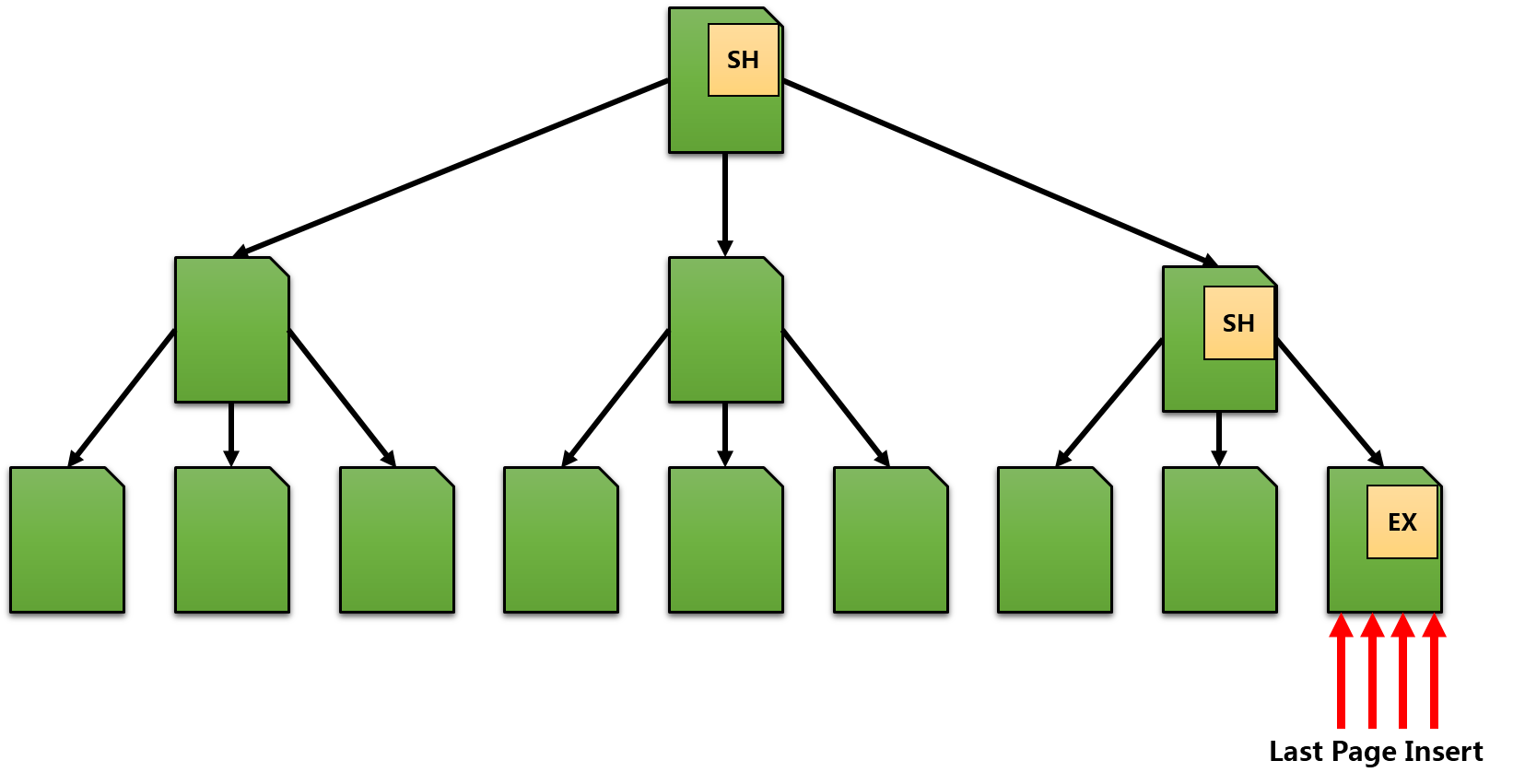
从图中可以看到,SQL Server需要横穿聚集索引的右手,从索引根页下至叶子层来在聚集索引的机翼后缘插入新的记录。因此在叶子层你有单线程访问叶子页,这就意味着单线程插入(Single-Thread INSERT)操作。这会大大伤及你的性能。下图展示了使用INT IDENTITY列的表里的简单INSERT语句(自增长,导致最后页插入加锁竞争!),我使用ostress.exe程序(来自微软RML工具的一部分)模拟不同用户在16核的机器上的不同性能表现。

从图中可以看到,随着用户的增加,工作量在逐步下降,你的闩锁等待增加——这就是使用自增长值的最后页插入加锁竞争(Last Page Insert Latch Contention)。当访问在内存里的索引页和数据页时,这个竞争就会发生,因为闩锁。
有几个方式可以克服最后页插入加锁竞争:
- 使用随机聚集键,例如UNIQUEIDENTIFIER 在整个聚集索引叶子层分布式插入
- 实行哈希分区(Implement Hash Partitioning)
当你使用UNIQUEIDENTIFIER 作为你的聚集键时,首先你就会觉得自己做错了,但你的工作吞吐量却大幅度上升了。哈希分区是你另一个可以部署的选项。哈希分区意味着你为每个CPU内核创建不同的分区,使用取模运算符在不同的分区间,你的配分函数(Partition Function)分发记录。下图展示了这个方法:

你通过在不同分区里的不同B-Tree结构分发INSERT语句,因此你就可以并行在表里执行INSERT语句。但这个也是有缺点的,你需要SQL Server的企业版,用了这个分区,你的表就不能重新分区,你就不能有效使用分区消除(Partition Elimination)。下图是对应的性能提升展示:

从图中可以看到,当用户达到64个前都是平稳延伸的,在128个用户后,再次发生最后页插入加锁竞争,吞吐量再次下降。
现在假设我们启用内存优化表,性能会发生如何的改变?表的生产力会贼快——XTP真是的TMD的快!因为没有锁和闩锁!我们可以看下SQL Server批量请求时资源使用情况:

在这个情况下,我可以执行200个用户的本地编译存储过程里的INSERT语句,可以接收25500批量请求/秒——0工作等待,0数据I/O!所有的一切都在内存里发生。但是:这次测试都是在虚拟机里执行。虚拟机有8个内核,分配了20G的内存,虚拟机和相关的SQL Server文件都存储在PCI-E上的SSD上。
我现在碰到的XTP的生产力瓶颈在哪里呢?这个不容易马上知道答案。首先你要考虑的是还是你的聚集键。使用XTP并不支持IDENTITY列。因此微软建议使用序列对象(Sequence Object)。序列是完美的,你可以使用缓存,但是XTP是TMD的太快了,你马上就碰上了SQL Server里的序列生成器(Sequence Generator)的竞争。SQL Server在你主数据文件的第132页保存序列值。第132也是系统表sysobjvalues的一部分。当你读写那个页时,SQL Server又会闩锁那个页,你的闩锁竞争又回来了,但只在你的数据酷的不同领域上。你不能避免这个页的闩锁竞争,因为系统表还是存储在传统磁盘的表上。因此从这个角度来说序列并不是XTP的最佳解决方法,如果你想无限延伸你的工作量。
因此让我们再次回到老朋友UNIQUEIDENTIFIER 这里。当生成UNIQUEIDENTIFIER 不会有任何竞争,因为生成是通过算法的。不好的是:函数NEWID()在SQL Server 2014的CTP1里并不支持。但这个也没关系,你可以在存储过程里写入,在存储过程里生成UNIQUEIDENTIFIER ,通过变量值传给本地编译的存储过程。问题解决,这样的话我可以把工作量提升至25500 批量请求/秒。从我的测试可以看出,UNIQUEIDENTIFIER 比序列更好,因为没有需要协调和闩锁的共享资源。这个是我的最大收获。
因此现在的问题就是什么限制了25500 批量请求/秒的工作量?2个主要东西:事务日志和CPU使用率!我们首先来看看事务日志。在XTP里,微软对此做了大量的优化工作,例如没有UNDO记录。微软尝试使事务日志量最小化来优化事务日志的写入。写得少,做得快。为了克服事务日志限制,XTP提供给你2类不同的内存优化表:
- SCHEMA_AND_DATA
- SCHEMA_ONLY
SCHEMA_AND_DATA意味着表架构和数据都永驻,因此只要你的事务一提交,XTP就要把事务日志记录写入事务日志。在事务执行期间,XTP从不把事务日志记录写入事务日志,因为你随时可能回滚事务。SCHEMA_ONLY表数据的修改不进行日志记录,并且表中的数据不保留在磁盘上:当你重启你的SQL Server,只有空表,嗯???你要慎重考虑使用这个选项,什么时候是可以用的,什么时候是不行的。微软建议下列2个场景可以使用这个选项:
- ASP.NET会话状态数据库
- 提取转换加载(ETL)场景
ASP.NET会话状态数据库可以使用SCHEMA_ONLY选项,因为你这里不保存关键数据。会话状态是关于你网站用户的信息。对于ETL场景也同样可以使用SCHEMA_ONLY选项,因为即使失败也很容易重建数据。使用SCHEMA_ONLY选项,我可以获得25500 批量请求/秒的工作量。使用SCHEMA_AND_DATA就成为了主要瓶颈,只能获得15000 批量请求/秒。我说过,我的测试环境的虚拟机是运行在PCI-E上的SSD上(事务日志,数据文件,虚拟机),换做实体的纯金属服务器会更好。
当你使用SCHEMA_AND_DATA部署你的内存优化表,你还有一个东西:极快的事务日志——和往常一样!当你使用SCHEMA_AND_DATA,CPU会称为你的瓶颈,因为没别的了。从刚才的图中你可以看到虚拟机里CPU基本运行在85%。当我把所有都部署在实体服务器上是,我觉得会加倍它的工作量。因为我只分配16核中的8核给虚拟机。在主机有50%的平均CPU占用,因此加倍工作量应该不是问题。那应该是在很低成本机器上却有50000批量请求/秒的工作量……
3.局限性(Limitations)
到目前位置,XTP的一切都看起来很棒,它应该是SQL Server里特定问题的最佳解决方案。但是XTP也有很大的代价——一大堆的局限性,尤其是现在的CTP1。下面列出部分,更多可以查看微软在线帮助:
- 差异备份不支持
- 行大小限制为8kb
- 内存优化表不能truncate
- NEWID()尚未实现
- 用SCHEMA_AND_DATA部署的内存优化表必须要有主键
- ALTER TABLE/ALTER PROCEDURE不支持
- 外键(Foreign-Keys)不支持
- LOB数据类型不支持
- 本地编译的存储过程不会重编译。由于统计信息改变,不重编译会导致很糟的性能
- 在内存优化的存储过程里不能访问存放在传统硬盘(机械硬盘)里的表
- 整个表的定义只能在一个CREATE TABLE里描述(包括索引和约束)
- 你不能从别的数据库往内存优化表里直接插入数据,你需要一个中间表。这在刚才提到的ETL场景里会是个大问题
- ……
除了这些局限性外,目前的CTP1版本里的XTP还是有BUG的,数据库居然崩溃了,也不能进行还原……不要问我如何重现这个BUG。
结论
XTP在SQL Server里的确是快速发展起来的技术。你需要考虑的唯一事情就是:当你基于XTP部署解决方案时,为你的事务日志准备尽可能快的存储系统吧,这个会大幅度降低系统瓶颈!希望这篇文章可以帮你很好的了解XTP,也希望你在阅读的时候,和我一样享受这个撰写过程。感谢您的阅读!
参考文章:
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号