
SQL Server 2014,表变量上的非聚集索引
从Paul White的推特上看到,在SQL Server 2014里,对于表变量(Table Variables),它是支持非唯一聚集索引(Non-Unique Clustered Indexes)和非聚集索引(Non-Clustered Indexes)的。看到这个,我决定在自己的虚拟机里尝试下,因为这将是个卓越的功能。表变量很棒,因为用它可以避免过多的重编译(excessive recompilations)。当你创建它们时,它们是没有统计信息,你不会改变数据库架构。它们只是变量,但在TempDb里还是常驻的。
表变量的一个缺点是,你不能在上面创建非聚集索引,这个在处理大量数据集时是不好的。但SQL Server 2014 CTP1已经修正了这个缺点。来看下面的代码(点击工具栏的 显示包含实际的执行计划):
显示包含实际的执行计划):

1 DECLARE @tempTable TABLE 2 ( 3 ID INT IDENTITY(1, 1) PRIMARY KEY, 4 FirstName CHAR(100) INDEX idx_FirstName, 5 LastName CHAR(100) 6 ) 7 8 INSERT INTO @TempTable (FirstName, LastName) 9 SELECT TOP 100000 name, name FROM master.dbo.syscolumns 10 11 SELECT FirstName FROM @TempTable 12 WHERE FirstName = 'cid' 13 GO

我们来看下SELECT语句的执行计划,SQL Server执行了非聚集索引扫描运算符(Non-Clustered Index Seek operator)。也就是说,我们可以在表变量上定义额外的非聚集索引。每个创建的非聚集索引是没有统计信息。这个功能很酷哦,在常规数据库表的简单语法(easy syntax)也支持。我们来看下面的表定义:
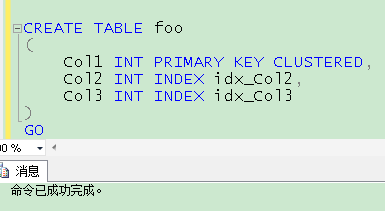
1 CREATE TABLE foo 2 ( 3 Col1 INT PRIMARY KEY CLUSTERED, 4 Col2 INT INDEX idx_Col2, 5 Col3 INT INDEX idx_Col3 6 ) 7 GO
这个在SQL Server 2008R2上会提示如下错误:

在SQL Server 2014上却能成功执行!
更进一步,我们还可以用新语法创建复合索引(composite indexes):
1 -- Inline creation of Indexes 2 CREATE TABLE foo2 3 ( 4 Col1 INT PRIMARY KEY CLUSTERED, 5 Col2 INT INDEX idx_Col2 (Col2, Col3), 6 Col3 INT 7 ) 8 GO
之前的版本(我这里是SQL Server 2008R2)只能如下出错提示:


真是酷炫叼炸天了,大家赶紧都去体验下!
参考文章:
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?