
第一次接触终极事务处理——Hekaton
在这篇文章里,我想给出如何与终极事务处理(Extreme Transaction Processing (XTP) )的第一次接触,即大家熟知的Hakaton。如果你想对XTP有个很好的概况认识,我推荐Kalen Delaney写的关于它的白皮书,中文版本点此下载,另外微软研究院也发布了题为“对于内存数据库的高性能并发控制机制(High-Performance Concurrency Control Mechanisms for Main-Memory Databases)”的研究白皮书,点此下载。
XTP明确为你指出:对于你的SQL Server数据库,在后台是存储在文件流(FILESTREAM) 文件组里。因此当你想要使用XTP,首先你要做的是,增加一个新的文件流(FILESTREAM) 文件组到你对应的数据库。新的文件组也必须标上MEMORY_OPTIMIZED_DATA属性。以下脚本请在64位系统里的SQL Server 2014里运行。
1 -- Create new database 2 CREATE DATABASE TestDatabase 3 GO 4 5 --Add MEMORY_OPTIMIZED_DATA filegroup to the database. 6 ALTER DATABASE TestDatabase 7 ADD FILEGROUP XTPFileGroup CONTAINS MEMORY_OPTIMIZED_DATA
点击【数据库属性】【文件组】,可以看到【内存优化数据】。
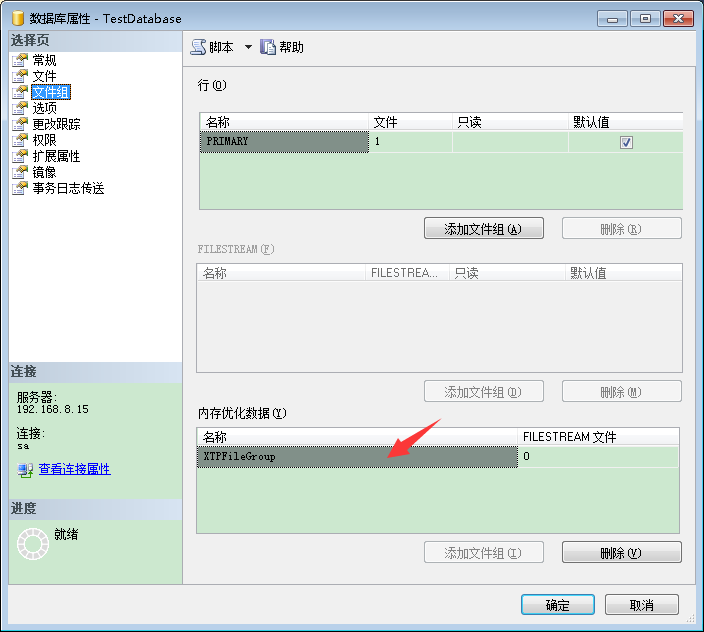
在你创建新FILESTREAM文件组后,你还需要添加一个新的文件到这个文件组。
1 -- Add a new file to the previous created file group 2 ALTER DATABASE TestDatabase ADD FILE 3 ( 4 NAME = N'HekatonFile1', 5 FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\HekatonFile1' 6 ) 7 TO FILEGROUP [XTPFileGroup] 8 GO
在我们已经准备好用于XTP的数据库后,最后我们可以添加我们的内存优化表(Memory Optimized Table)——这个名字就是SQL Server所指的XTP表:

看到这个截屏,估计你很期待一个非常酷的表创建向导,但事实上我们只看到一个T-SQL脚本模板——没别啥东东。希望微软对此在后续版本会有所改进……下面是创建一个XTP表的必需脚本:

1 USE TestDatabase 2 -- Let's create a new Memory Optimized Table 3 CREATE TABLE TestTable 4 ( 5 Col1 INT NOT NULL, 6 Col2 VARCHAR(100) NOT NULL, 7 Col3 VARCHAR(100) NOT NULL 8 CONSTRAINT chk_PrimaryKey PRIMARY KEY NONCLUSTERED HASH (Col1) WITH (BUCKET_COUNT = 1024) 9 ) WITH (MEMORY_OPTIMIZED = ON) 10 GO

哎呀,报错了。因为俺们用的是中文版本的SQL Server 2014,排序规则是:Chinese_PRC_CI_AS
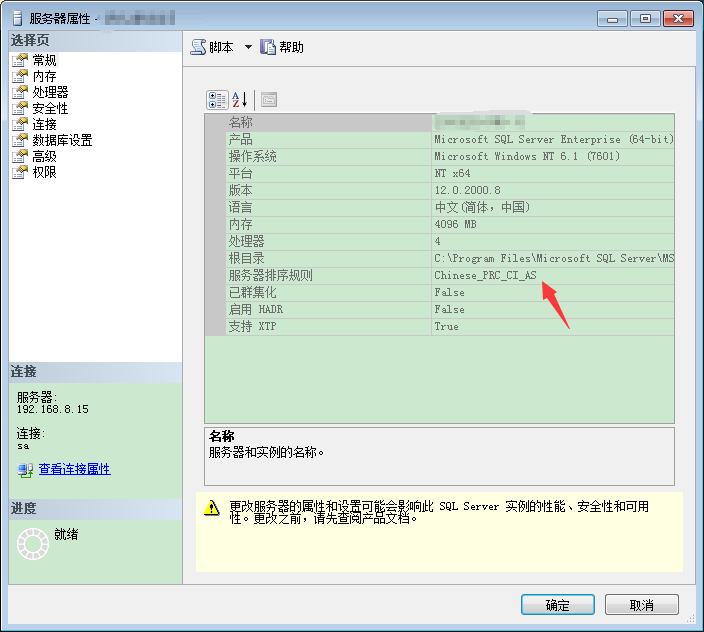
看来对中文字符的支持还不是很好,我们可以换用数据类型 nchar(n) 或 nvarchar(n)。
1 USE TestDatabase 2 -- Let's create a new Memory Optimized Table 3 CREATE TABLE TestTable 4 ( 5 Col1 INT NOT NULL, 6 Col2 NVARCHAR(100) NOT NULL, 7 Col3 NVARCHAR(100) NOT NULL 8 CONSTRAINT chk_PrimaryKey PRIMARY KEY NONCLUSTERED HASH (Col1) WITH (BUCKET_COUNT = 1024) 9 ) WITH (MEMORY_OPTIMIZED = ON) 10 GO
在XTP里额每个表都必须要有一个非聚集哈希索引(Non-Clustered Hash Index)的约束。聚集哈希索引(Clustered Hash Index)目前尚不支持。你还要用BUCKET_COUNT子句来指定桶数。最后你要为数据库标上MEMORY_OPTIMIZED。恭喜您,你已经创建了您的第一个内存优化表——这个一点都不难!
使用这个新表非常简单。我们来插入几条记录:
1 -- Let's insert a simple record into the new table 2 INSERT INTO TestTable (Col1, Col2, Col3) VALUES (1, 'Woody', 'Tu') 3 GO
但是XTP的真正威力是在处理并发用户的时候,因为没有锁/阻塞/封锁(Locking/Blocking/Latching)。连排它锁(Exclusive Locks (X) )也米有了。平常当我们在“普通”表上运行INSERT语句时,在表上会有IX锁,在数据页,在记录本身会有一个X锁。但在XTP里,这些锁全不见了。来看下面的查询:
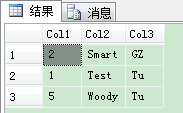
1 -- Make an insert in an explicit transaction 2 BEGIN TRANSACTION 3 4 INSERT INTO TestTable (Col1, Col2, Col3) VALUES (2, 'Smart', 'GZ') 5 6 -- No IX, X locks anymore! 7 SELECT * FROM sys.dm_tran_locks 8 WHERE request_session_id = @@SPID 9 10 COMMIT 11 GO

从sys.dm_tran_locks的输出结果可以看到,只有在表本身有一个模式稳定锁(Schema Stability Lock (Sch-S) ),但IX和X锁都消失了——非常酷!
当你运行刚才的脚本不马上提交事务:
1 BEGIN TRANSACTION 2 3 INSERT INTO TestTable (Col1, Col2, Col3) VALUES (3, 'Cn', 'Blog')
你仍然可以从另外一个会话通过SELECT语句无锁的获得最新数据,在执行查询之前,我们在工具栏点击显示实际的执行计划:
1 SELECT * FROM dbo.TestTable
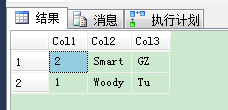
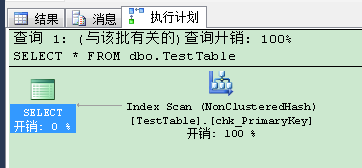
SQL Server在执行计划里使用了Index Scan (NonClusteredHash) 运算符。
在XTP之前,这个行为在数据库里只能通过启用乐观并发控制(Optimistic Concurrency)来建立——在SQL Server 2005后才引入了Read Committed Snapshot Isolation、Snapshot Isolation。
我们来试下UPDATE语句:
1 UPDATE TestTable SET Col2 = 'Test' WHERE Col1 = 1 2 GO
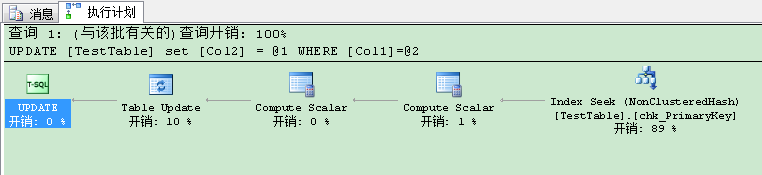
当我们看UPDATE执行计划时,除了Index Seek (NonClusteredHash)运算符,这里没啥特别的地方。因此XTP能扫描和查找哈希索引(Hash Indexes)。我们来试下显示事务里的UPDATE语句:
1 -- Let's try the UPDATE statement in an explicit transaction 2 BEGIN TRANSACTION 3 4 UPDATE TestTable SET Col2 = 'Test' WHERE Col1 = 1 5 6 SELECT * FROM sys.dm_tran_locks 7 WHERE request_session_id = @@SPID 8 9 COMMIT 10 GO
这一次,SQL Server给我们了下列错误信息:

因此当你使用显示事务时,我们要提示SQL Server。但是WITH (SNAPSHOT)和SNAPSHOT事务隔离级别(Transaction Isolation Level)不一样,因为当我更改隔离级别为SNAPSHOT,并尝试回滚事务时:
1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; 2 BEGIN TRANSACTION 3 4 UPDATE TestTable SET Col2 = 'Test' WHERE Col1 = 1 5 6 ROLLBACK
我会收到如下的错误信息:

因此,我们给查询本身加上查询提示:
1 BEGIN TRANSACTION 2 3 UPDATE TestTable WITH (SNAPSHOT) SET Col2 = 'Test' WHERE Col1 = 1 4 5 SELECT * FROM sys.dm_tran_locks 6 WHERE request_session_id = @@SPID 7 8 COMMIT 9 GO

现在事务已经提交,sys.dm_tran_locks 再一次只显示了Sch-S锁。下一步我想做的是尝试并行执行2个UPDATE语句,但不提交第1个事务。因此我们在2个不同的会话执行下列语句,并确保2个事务都不提交。
1 BEGIN TRANSACTION 2 3 UPDATE TestTable WITH (SNAPSHOT) SET Col2 = 'Test' WHERE Col1 = 1
没有XTP,第2个事务会阻塞,因为X锁正被第1个事务拿着:
很遗憾SQL Server在第2个会话里给我们下列的错误信息:

我们的执行进入更新冲突(Update Conflict),SQL Server回滚了第2个事务。我并没有料到这点,但我需要对此仔细思考下。
在当前SQL Server 2014 CTP1版本里,XTP提供给你的另一个东西叫做 本机编译的存储过程(Natively Compiled Stored Procedures):

又一次,没有向导,只有你要用到的T-SQL脚本模板。本机编译(Native Compilation)意味这SQL Server在后台将整个存储过程编译至C/C++代码——这个性能将会是卓越的,因为现在我们在SQL Server内部直接执行本机代码(native code)。下面脚本展示了一个简单的XTP存储过程是啥样的:
1 CREATE PROCEDURE HekatonProcedure 2 ( 3 @Param INT 4 ) 5 WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER 6 AS 7 BEGIN 8 ATOMIC WITH 9 ( 10 TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english' 11 ) 12 13 INSERT INTO dbo.TestTable (Col1, Col2, Col3) VALUES (@param, N'Woody', N'Tu') 14 15 SELECT Col1, Col2, Col3 FROM dbo.TestTable 16 END 17 GO
有几个属性必须要知道:
- 存储过程必须用SCHEMABINDING和EXECUTE AS来创建;
- 存储过程必须标记为NATIVE_COMPILATION;
- 你必须指定ATOMIC代码块,这里设置事务隔离级别和所用语言。
当你完成存储过程创建后,你就可以执行它了:
1 EXEC HekatonProcedure 5 2 GO
因为现在你用的是本机代码,那就没有执行计划了!好好享受这执行速度……ALTER PROCEDURE也不支持了(没意义,因为是本地生成代码(native generated code)),意味如果你想修改这个存储过程的话,你还不能再次DROP和CREATE。
这是我第一次安装SQL Server 2014体验XTP的简短过程。更多的信息和内容,我定会在接下来的文章里和大家一起分享。请继续关注!
参考文章:
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?