非结构化数据存储总复习
非结构化数据存储
常见的NoSQL数据库
- MongoDB(文档存储数据库)
- Redis(key/value database)
- HBase(列存储 database)
- Neo4j(图存储database)
NoSQL定义及特点
- 定义:NOSQL的全称是Not Only Sql,是非关系型数据存储的广义定义。它存储的不再是结构化的数据,即数据再没有固定的长度,类型和固定的格式等,比较主流的是以key-value键值对存储
数据表→ JDBC读取→ POJO(VO、PO)→控制层转化为JSON数据→客户端
-
特点:
-
易扩展
- NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间,在架构的层面上带来了可扩展的能力。
-
大数据量、高性能
-
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。
一般MySQL使用Query Cache。NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说性能就要高很多。
-
-
灵活的数据类型
- NoSQL无须事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是——个噩梦。这点在大数据量的Web 2.0时代尤其明显。
-
高可用
- NoSQL在不太影响性能的情况,就可以方便地实现高可用的架构。比如Cassandra、HBase模型,通过复制模型也能实现高可用。
-
缺点:
- 不提供对sql的支持
- 支持的特性不够丰富(不支持事务,不支持多表联查)
- 现有的NOSQL产品,相对于已有的Mysql,Oracle等关系型数据库来说成熟度不高。
-
优点:
- 灵活的数据模型
- 可伸缩性强
- 自动分片
- 自动复制
-
非结构化数据库类型
- HBase列结构
- Redis键/值
- Virtoso图结构
- MongoDB文档结构
NoSQL中的概念与关系数据库的对应关系
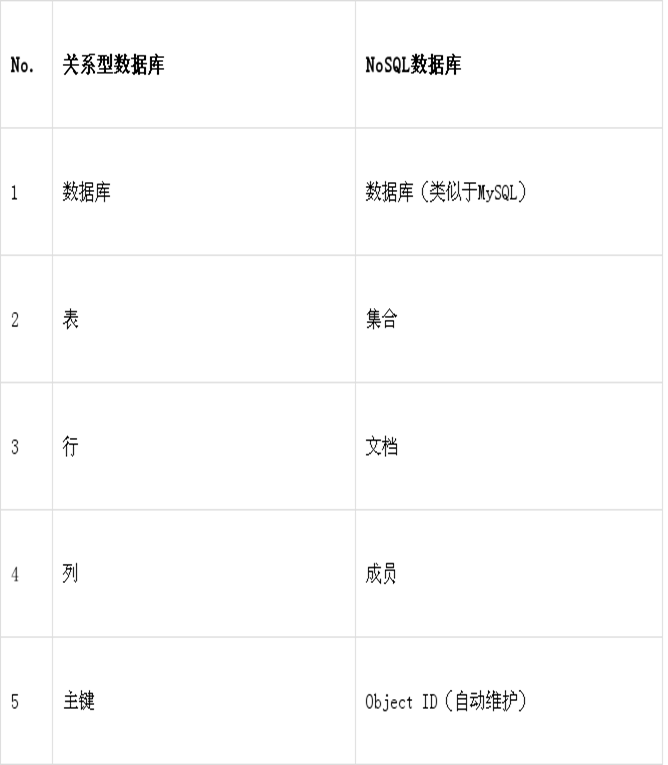
数据库、集合、文档

数据库mongodb
drop和delete的区别
- drop和delete 都是删除数据库的数据的命令;
- 但是drop会删除表、库的结构;delete不会删除表的结构,只会删除里面的数据,更安全一些。
drop和remove的区别
- remove用于将集合中的文档删除,但不删除集合本身,也不删除集合的索引
- drop不仅删除集合的文档,也会删除集合本身,同时也会删除在集合上创建的索引
save与insert的区别与联系
-
save完成保存操作 insert完成插入操作
-
当数据集中_id不存在时,save与insert功能是插入,即相同
-
当数据集中_id相同时,save的功能会变为更新,insert则会报错



集合

基本方法






文档
insert


save

remove

查询并修改

update



修改器



find



设置字段“0”或“1”,让字段不显示或显示

运算符
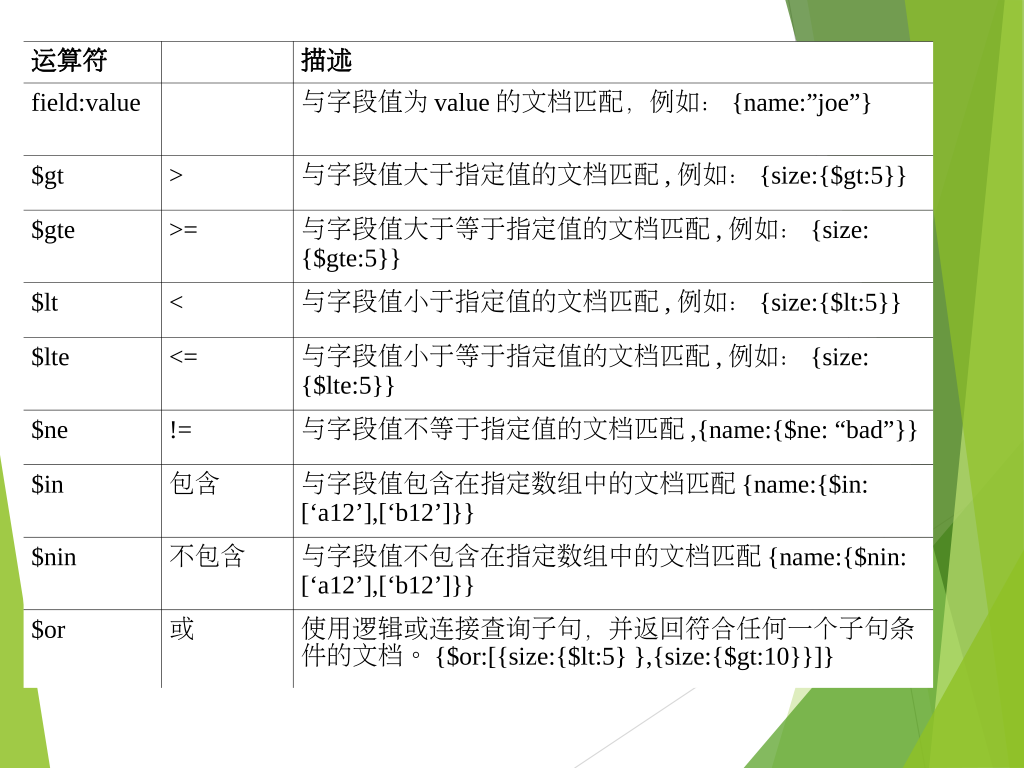
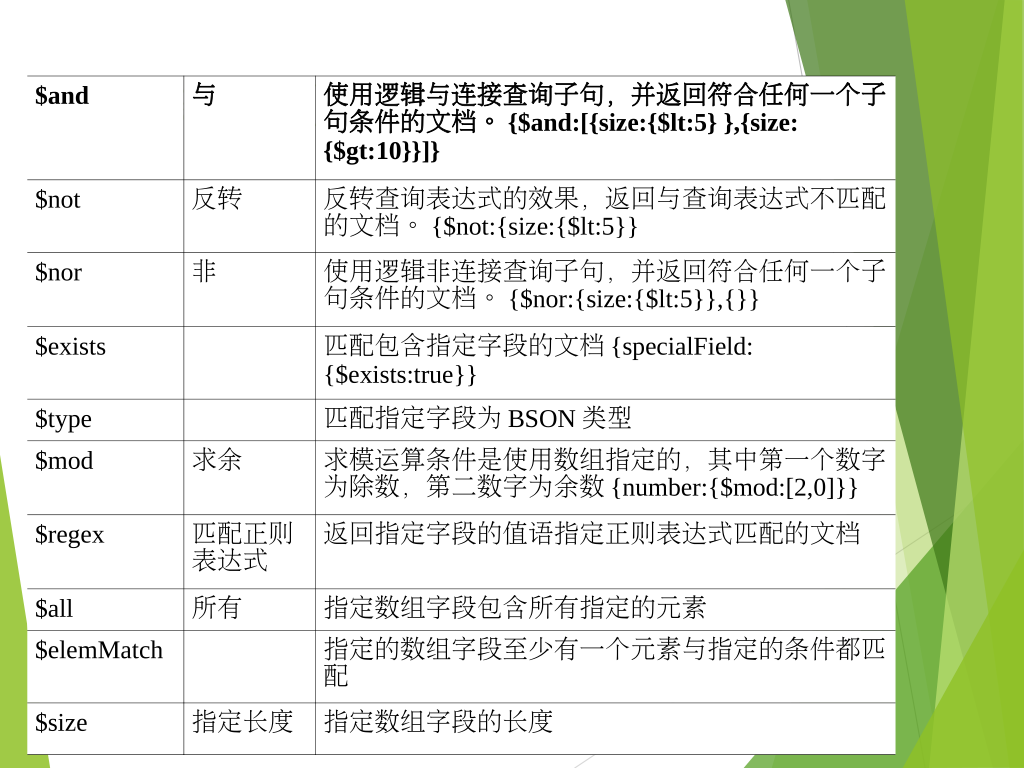
关系运算

逻辑运算


求模

查询条件

查询范围

OR查询


Limit、Skip、Sort

$where查询

example

什么是固定集合
固定集合需要事先创建好,而且它的大小是固定的。
当固定集合被占满时,如果再插入新文档,固定集合会自动将最老的文档从集合中删除。
固定集合与普通集合的区别
//TTL(生存时间值)
集合创建不同:“普通”集合是动态创建的,而且可以自动增长以容纳更多的数据。固定集合需要事先创建好,而且它的大小是固定的。
访问模式不同:数据被顺序写入磁盘上的固定空间。因此它们在碟式磁盘 (spinning disk ) 上的写入速度非常快,尤其是集合拥有专用磁盘时(这样就不会因为其他集合的一些随机性的写操作而“中断”)。
普通集合:集合里的文档可以是多种多样的;没有表头,无结构,自动识别每个字段的类型
固定集合:是性能出色且有着固定大小的集合,事先创建好了,大小固定的集合;固定集合很像环形队列,如果空间不足,最早的文档就会被删除,为新的文档腾出空间。
顺序访问和随机访问运行之间的差异
随机跟顺序运行的对比是一种用来评估磁盘使用方面程序效率的方式。因为磁盘硬件工作的方式,顺序访问数据比随机访问快很多。查找操作,是当磁头本身的位置正好在正确的盘面上以访问需要的数据时才发生,因而比输入输出过程的任何其他部分都要花费更多的时间。因为随机读取比顺序读取包含更多的查询操作,随机读取的生产量更低一些。随机写入也是同样的道理。
什么是内嵌文档
- 普通内嵌文档
- 把整个MongoDB文档作为另一个文档中键的值称为内嵌文档
分片
- 是MongoDB用来将大型集合分割到不同服务器(或者说一个集群)上所有采用的方法。
- 定义:将数据进行拆分,将数据分散地保存到不同机器上地过程。MongoDB实现了自动分片功能,能够自动地切换数据和做负载均衡。
- 简单讲:数据库服务分布在多台服务器上的机制就叫分片
- 缺点:配置和运维变得复杂且困难,一旦建立后在想改变架构变得很困难
片键
- 在分片前,需要通过配置让Mongo DB知道数据分配的功能,然后根据这些规则,以数据块的形式,分布存储到各个分片上,这个规则就是片键
分片的目的
1.有了副本集,为什么还需要分片?
复制所有的写入操作到主节点
延迟的敏感数据会在主节点查询
单个副本集限制在12个节点
当请求量巨大时会出现内存不足。
本地磁盘不足
垂直扩展价格昂贵
解决资源耗尽的两个基本方法:垂直在扩展和水平扩展
- 垂直扩展:增加更多的CPU和存储资源来扩展容量。
- 水平扩展:将数据集分布在多个服务器上,水平扩展即分片。
分片设计思想
- 分片为应对高吞吐量与大数据提供了方法。使用分片减少了每个分片需要处理的请求数,因此,通过水平扩展,集群可以提高增加的存储容量和吞吐量,举例来说,当插入一条数据时,应用只需访问存储这条数据的分片
- 使用分片减少了每个分片存储的数据
分片的工作原理
- MongoDB实现了自动分片
- 分片是MongoDB数据库的核心内容,内置了多种分片逻辑,不需要用户之间设计外置分片方案和框架,不需要再应用程序上做处理。
- 再数据库需要启用分片框架时,或增加新的分片结点时,应用程序不需要改动。
- 主要通过三部分实现分片:数据的分流、块的拆分、块的迁移。
MongoDB的存储原理?
- MongoDB的所有数据实际上是存放在硬盘上的,然后把部分或者全部要操作的数据通过内存映射存储引擎映射到内存中。
- 读操作:直接从内存中取数据(尽可能的放在内存中)
- 写操作:修改内存中对应的数据( OS的虚拟内存管理器把数据重新保存到硬盘中)只修改内存中的数据
MapReduce的三个过程和功能?
- map阶段:切片、分区、进行映射
- shuffle阶段:重新分牌洗牌,合并、分区、排序、组合等,将相同的k合并之后对应的value组成一个value list
- reduce阶段:归并,汇总整理的阶段
- 将key/value/Partition写入到内存缓冲区中
- 当缓冲区使用量达到一定阀值,将其spill到disk上,spill前,需要进行排序
- 排序时先按照Partition进行排序,再按照key进行排序,默认排序算法是快速排序
注意: 在内存中进行排序时,数据本身不用移动,仅对索引排序即可
部署一个分片集群需要几大部分?

简述Mongo DB布署分片的集群的步骤
例题
| 主机 | IP | 服务器和端口 |
|---|---|---|
| mongodb0 | 192.168.199.8 | Shard1 28000 |
| Config Server 40000 | ||
| mongos 60000 | ||
| mongodb1 | 192.168.199.9 | Shard2 28000 |
| Config Server 40000 | ||
| mongos 60000 | ||
| mongodb2 | 192.168.199.10 | Shard3 28000 |
| Config Server 40000 | ||
| mongos 60000 |
1.创建目录 mkdir
mongodb0
/data/shard1
/data/shard1/log
mongodb1
/data/shard2
/data/shard2/log
mongodb2
/data/shard3
/data/shard3/log
2.以分片Shard Server模式启动 mongod
mongodb0
mongod –dbpath = /data/shard1 –port 28000
logpath=/data/shard1/log/shard1.log –logappend –fork –shardsvr
mongodb1
mongod –dbpath = /data/shard2 –port 28000
logpath=/data/shard1/log/shard2.log –logappend –fork –shardsvr
mongodb2
mongod –dbpath = /data/shard3 –port 28000
logpath=/data/shard1/log/shard3.log –logappend –fork –shardsvr
3.启动Config Serve
1.创建目录
mongodb0
/data/shard/configdb1
mongodb1
/data/shard/configdb2
mongodb3
/data/shard/configdb3
2.以分片Config Server模式启动
mongodb0
mongod –dbpath /data/shard/configdb1 –port 40000 -logpath =/data/shard1/log/config1.log –fork –configsver –replSet replsetConfig
mongodb1
mongod –dbpath /data/shard/configdb2 –port 40000 -logpath =/data/shard1/log/config2.log –fork –configsver –replSet replsetConfig
mongodb2
mongod –dbpath /data/shard/configdb3 –port 40000 -logpath =/data/shard1/log/config3.log –fork –configsver –replSet replsetConfig
在mongodb0的mongo客户端初始化副本集,需要注意的是,连接mongo时应该连接端口4000的mongod实例:
mongo –port 40000
初始化副本集:
rs.initiate();
稍等主节点启动成功后分别添加其他两个config Server 节点为副节点,使用命令
rs.add(“192.168.199.9:40000”)
rs.add(“192.168.199.10:40000”)
4.启动Route Process
Route Process 路由服务是使用mongos来启动的,需要设置-configdb参数和chunkSize参数。
-configdb是指定与mongos交互的Config Server
-chunkSize参数可选,默认64MB,为了测试分片和块的查分,可以设置的小一些
5.mongos启动
mongos启动命令分别:
mongod0:
mongos –configdb replsetConfig/192.168.199.8:40000, 192.168.199.9:40000, 192.168.199.10:40000 –port 60000 –logpath = /data/shard1/log/mongos.log –fork
mongod1:
mongos –configdb replsetConfig/192.168.199.8:40000, 192.168.199.9:40000, 192.168.199.10:40000 –port 60000 –logpath = /data/shard2/log/mongos.log –fork
mongod2:
mongos –configdb replsetConfig/192.168.199.8:40000, 192.168.199.9:40000, 192.168.199.10:40000 –port 60000 –logpath = /data/shard3/log/mongos.log –fork
查看分片结果
use config
db.setting.find()
6.配置sharding
sh.addShard(“192.168.199.8:28000”)
sh.addShard(“192.168.199.9:28000”)
sh.addShard(“192.168.199.10:28000”)
7.启动mongo shell客户端
启动mongo shell客户端,切换到admin数据库,对mytest数据库设置分片。
use admin
db.runCommand({enableSharding(“mytest”)})
此时分片集群config数据库中多了一个databases集合,记录了数据库分片的元数据。
主从复制集群
-
定义:主从复制集群,即一主多,主从复制MongoDB中比较常用的一种方式,如果要实现主从复制至少应该有两个MongoDB实例,一个作为主节点负责客户端请求,另一个作为从节点负责主节点映射数据,提供数据备份,客户端读取等,推荐一主多从模式。
-
特点:
- 每个从节点必须知晓其对应的主节点地址
- 只允许主节点进行数据更新
- 主节点宕机(死机)服务不可用
-
MongoDB提供了两种复制部署方案:主从复制(Master-Slave)和副本集(ReplicaSets)
-
两种方式的共同点:都是在一个主节点上进行写操作,然后写入的数据会异步地同步到所有地从节点上。主从复制和副本集都是使用了相同地复制机制
-
主从复制只有一个主节点,至少有一个从节点,可以有多个从节点,在启动MongoDB数据库服务时需要制定,所有的从节点都会自动地去主节点获取最新数据,做到主从节点数据保持一致
注意:主节点是不会去从节点拿数据,只会输出数据到从节点,MongoDB地集群中不能超过12个从节点
-
区别:主从复制集群的过程中有一个缺陷,当主节点出现故障,整个MongoDB服务集群不能正常运行,需要人工处理,修复主节点之后再重启服务,当主节点一时难以修复时,我们可以把其中一个从节点启动为主节点,需要人工操作
-
副本集群是为了解决主从复制集群的容灾性而产生的,副本集群具有自动故障功恢复功能的主从集群。副本集是对主从复制的一种完善,它跟主从群最明显的区别就是副本集没有固定的主节点,也就是主节点的身份不需要我们去指明,而是整个集群自己会选举其它的节点作为主节点。
-
副本集中总会有一个活跃节点和一个或多个备份节点
-
MongoDB3.0以后的副本集成员提升到了50个
-
仲裁节点:是副本集的一个实例,不保存数据,只负责选举时投票
副本集群
- 在计算机中,拥有自动故障恢复功能的集群,称为副本集群。包含三种角色:主节点、副本节点、仲裁节点。
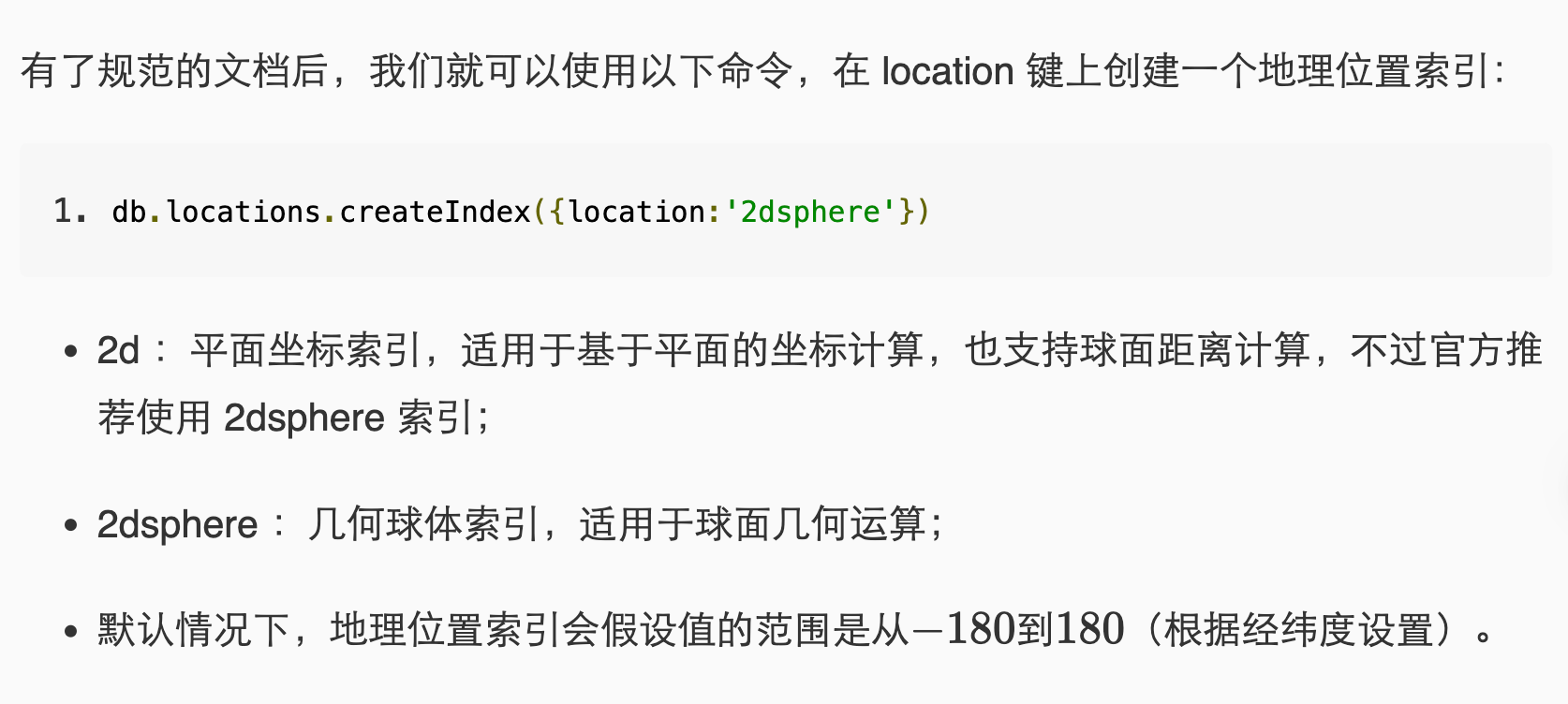
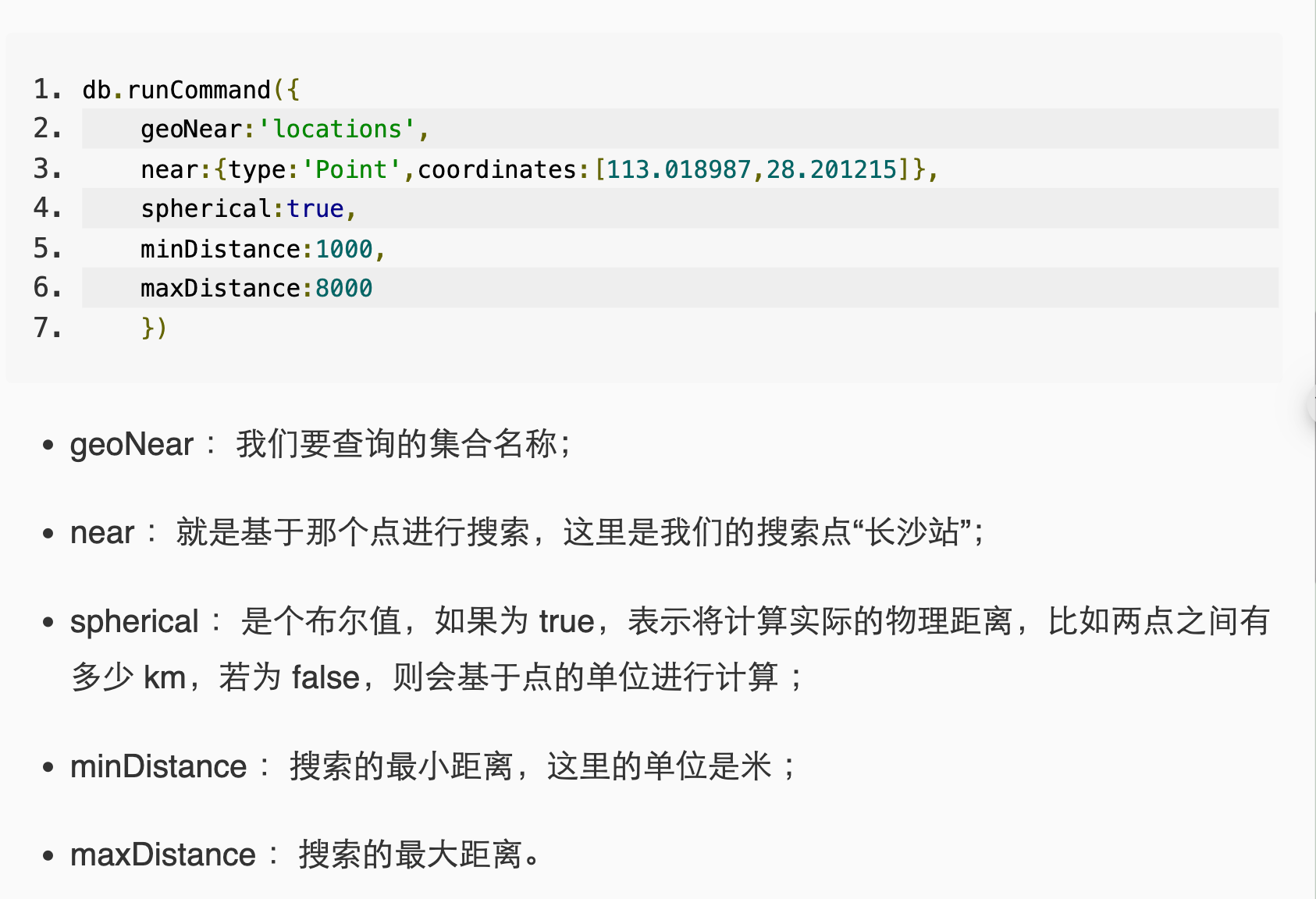
地理空间索引
- 定义:找到距离当前位置最近的N个场所,为坐标查询提供的专门索引:基于位置服务.能够帮助我们在包含地理空间形状和点集的结合上高效地执行空间查询的索引,称为地理空间索引。
MongoDB提供了两种表面类型:平面和球面
- 平面:按照正常坐标对的形式存储位置数据使用2d索引
- 球面:如果需要计算地理数据就像在一个类似于地球的球形表面上,选择球星表面来存储数据,这样就可以使用2dsphere索引
- 说明:MongoDB支持创建二维坐标或二维球面坐标的地理空间索引。
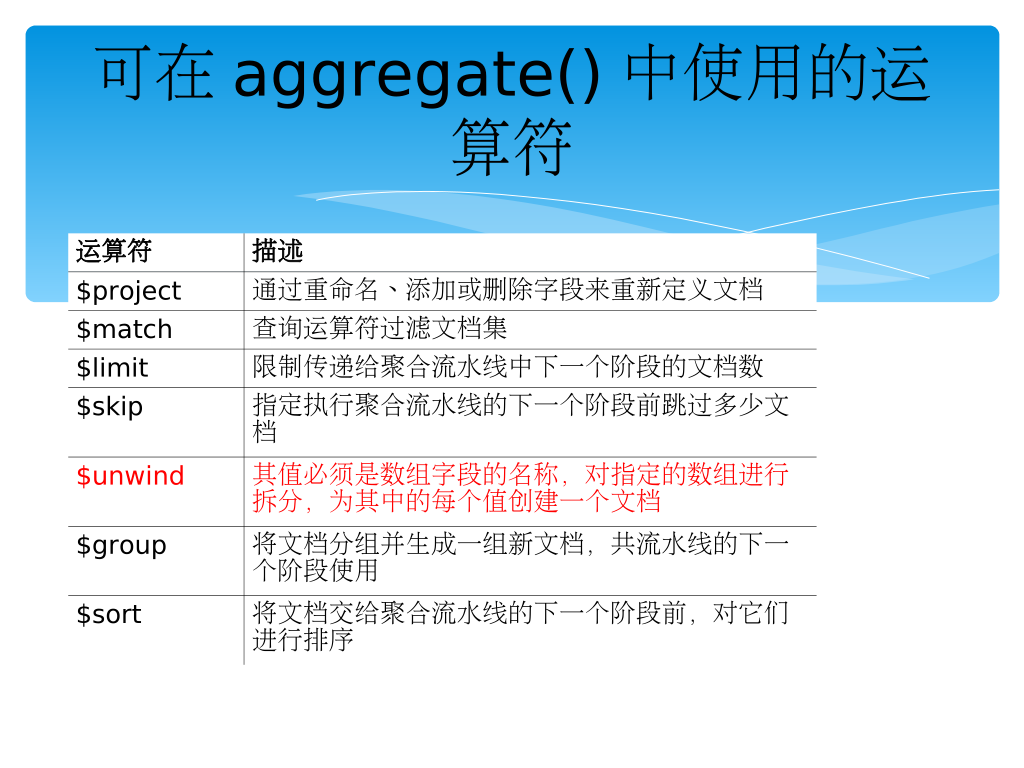
聚合管道
-
定义:通过数据处理管道来实现,一次操作可以使用多个管道来处理数据文档,使用管道是有顺序的,将依序将管道的结果传递给下一个中继处理,进而显示最终的结果
-
功能:
- 对文档进行过滤,查询出符合条件的文档
- 对文档进行变换,改变文档的输出形式
-
语法:
- aggregate(operator,[operator],[...])
-
说明:参数operator是一系列聚合运算符,能够指定在流水线的各个阶段对数据执行哪种聚合操作。执行第一个运算符后,结果将传递给下一个运算符,后者对数据进行处理并将结果传递给下一个运算符,整个过程不断重复,直到到达流水线按末尾。
GridFS
MongoDB GridFS | 菜鸟教程 (runoob.com)
- 用于存储和恢复那些超过16M(BSON文件限制s)的文件(如:图片、音频、视频等)。
- 也是文件存储的一种方式,但是它是存储在MonoDB的集合中。
- 可以更好的存储大于16M的文件。
- 会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中。
- 用两个集合来存储一个文件:fs.files与fs.chunks。
- 每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
请为三台主机配置分片,并对某数据库启用分片,设置_id为片键
- 创建三个shard server,命令代表mkdir
- 创建配置文件 :分别为三台服务器配置,其内容中shard server为准
- 利用配置文件启用mongod实例
- 启用mongo shell对集群进行初始化
- 导入数据集
- 添加分片,启动mongos并对分片进行初始化
- 验证分片,对数据集设置_id为片键
设计题
使用mapreduce对编号>20的文档中相同的weight求和
Var mapFunction()
{ emit ( this.ProductMode,this.weigh ) }
Var reduceFunction = Function(key,value)
{ var total = 0;
for ( var i=0; i < values.length; i++ )
{ total +=values[i]; }
return total
}
db.product.mapReduce( {
mapFunction;
reduceFunction;
{ query: {Sysno: {$gt:20} };
Out: ”project_MapReduce”
})
代码题
- 查询出persons数据集中所有数据,不显示_id
- db.persons.find ( {},
- 查询persons数据集中年龄大于25岁的信息
- db.persons.find ( {sage: {$gt:25 }} )
- 利用聚合管道aggregate方法操作persons数据集,统计范明硕 books中的元素个数
- db.persons.aggregate ( [{$match: { name: “范明硕” }} , {$project: {$size: ‘$books’ }} ] )
- 统计persons数据集中 年龄大于25岁的学生年龄和人数
- db.persons.aggregate ( [ {$match: {sage: {$gt25 } } } , {$project: {_id: “ sage”, ‘人数’ : {count:1} } } ] )
- 修改persons中所有男同学的年龄-1
- db.persons.update( {sex: ‘男’ } , {$inc : {sgae : -1} } )
例子



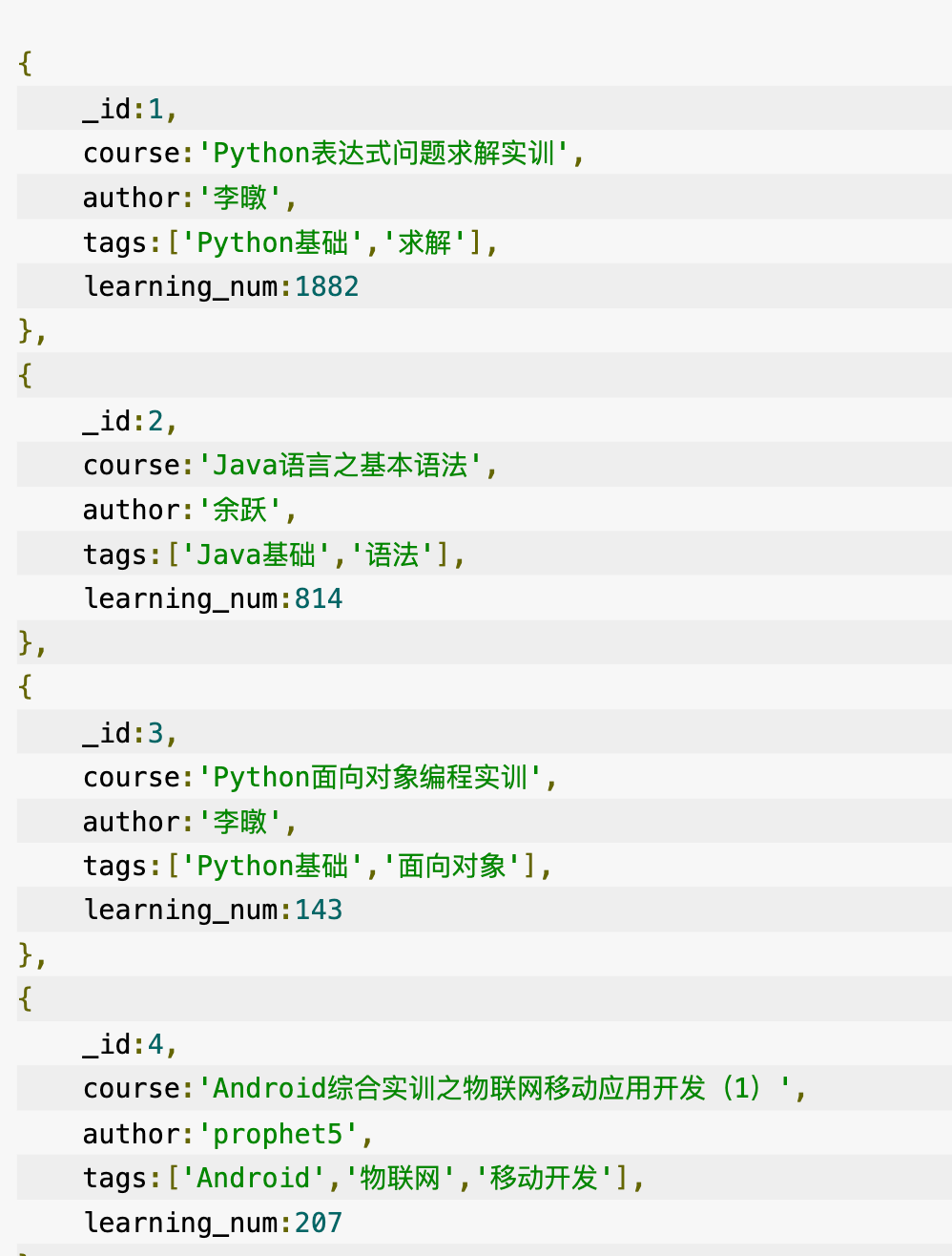
db.educoder.aggregate([{$group:{_id:'$author',learning_sum:{$sum:'$learning_num'}}}])
只输出所给的



1.查询出persons数据集中的所有数据,不显示_id;
2.查询出persons集合中的年龄大于25岁同学的信息;
3.利用聚合管道aggregate方法操作persons数据集,统计出“范明硕”books中的元素个数;
4.统计persons数据集合中年龄大于23岁学生的年龄和人数;
5.修改persons数据集合中所有男同学的年龄减少1岁;
6.在persons数据集合中,给姓”王”的同学追加一本“语文”书籍;
7.删除persons数据集合中sname是“徐金鑫”的文档;
8.查询出jim的最后一本书
db.persons.find({name:'jim'},{books:{$slice:-1}})


 浙公网安备 33010602011771号
浙公网安备 33010602011771号