nodejs实现一个简单的爬虫
nodejs是js语言,实现一个爬出非常的方便。
步骤
1. 使用nodejs的request模块,获取目标页面的html代码;
https://github.com/request/request
2. 使用cheerio模块对html代码做处理(cheerio类似jQuery的语法,所以好用又方便)
https://github.com/cheeriojs/cheerio
下面我们借助exprerss来做一个简单的nodejs爬虫系统。
http://www.expressjs.com.cn/
具体实现
1. 安装依赖模块
$ npm init
初始化一个项目
npm install express request cheerio --save
安装所需的模块
express用于搭建node服务
request类似于ajax的方式获取一个url里的html代码
cheerio类似于jQuery那样对所获取的html代码进行处理
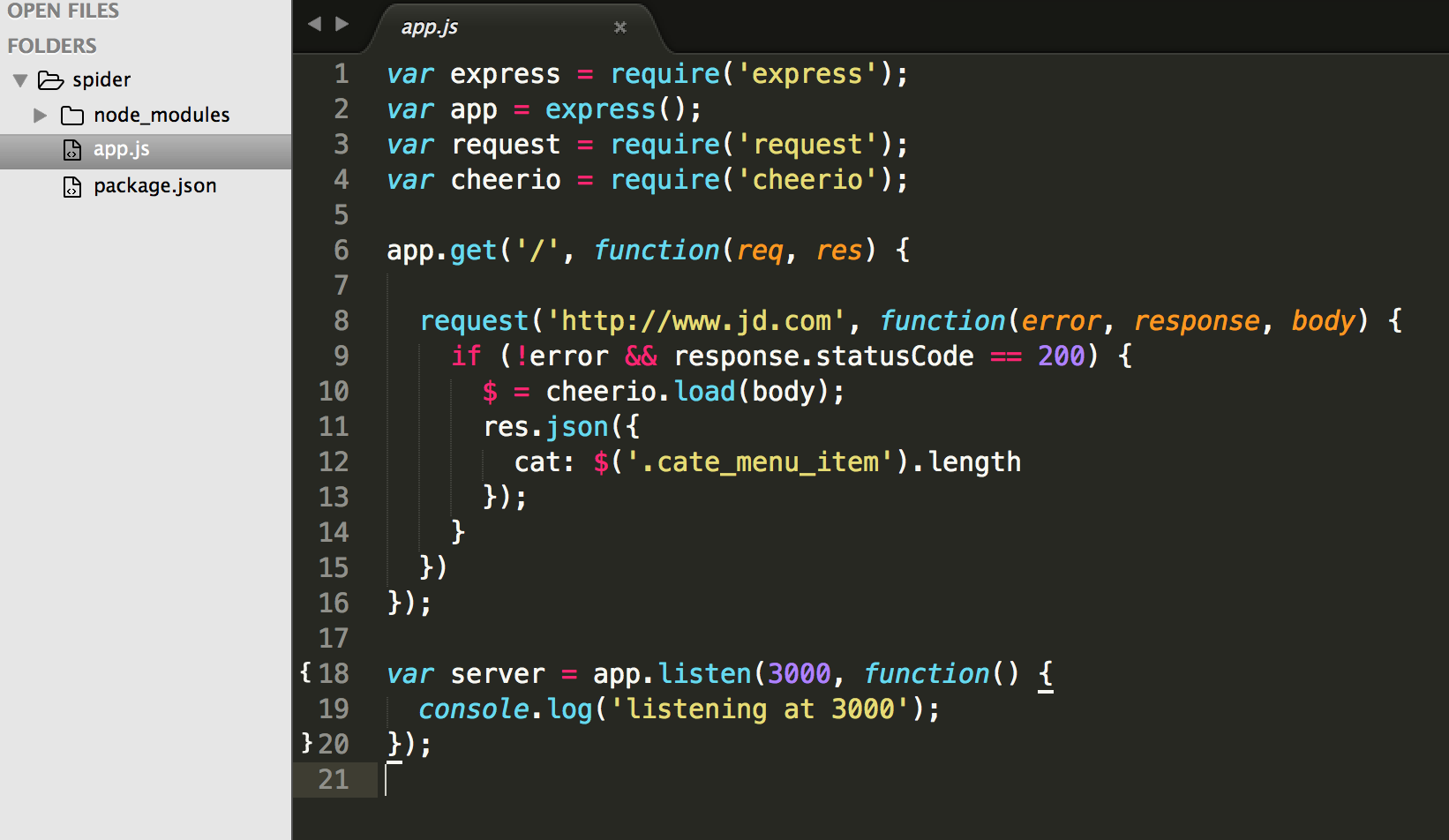
2. 根目录新建一个app.js
var express = require('express'); var app = express(); var request = require('request'); var cheerio = require('cheerio'); app.get('/', function(req, res) { request('http://www.jd.com', function(error, response, body) { if (!error && response.statusCode == 200) { $ = cheerio.load(body); res.json({ cat: $('.cate_menu_item').length }); } }) }); var server = app.listen(3000, function() { console.log('listening at 3000'); });
项目结构:
这里,我们以京东网站为例子:

统计边栏的类目数量,可以看到$('.cate_menu_item') 的用法完全就像是jQuery的语法,更多例子可以在它的官网查看。
查看结果
运行(我们可以全局安装一个node-dev模块来对我们的nodejs程序监听热刷新)
node-dev app
然后访问http://localhost:3000
返回了 {cat:15}
基础部分就是这样,可以借助这几个模块很方便地开发爬虫系统。
另外比如每天几点去爬,获取失败时的处理,也都有相应的node模块可以去实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号