
Mysql 窗口函数
- MySQL从8.0版本开始支持窗口函数。
- 窗口函数的作用类似于
在查询中对数据进行分组,不同的是,分组操作会把分组的结果聚合成一条记录,而窗口函数是将分组的结果置于每一条数据记录中。
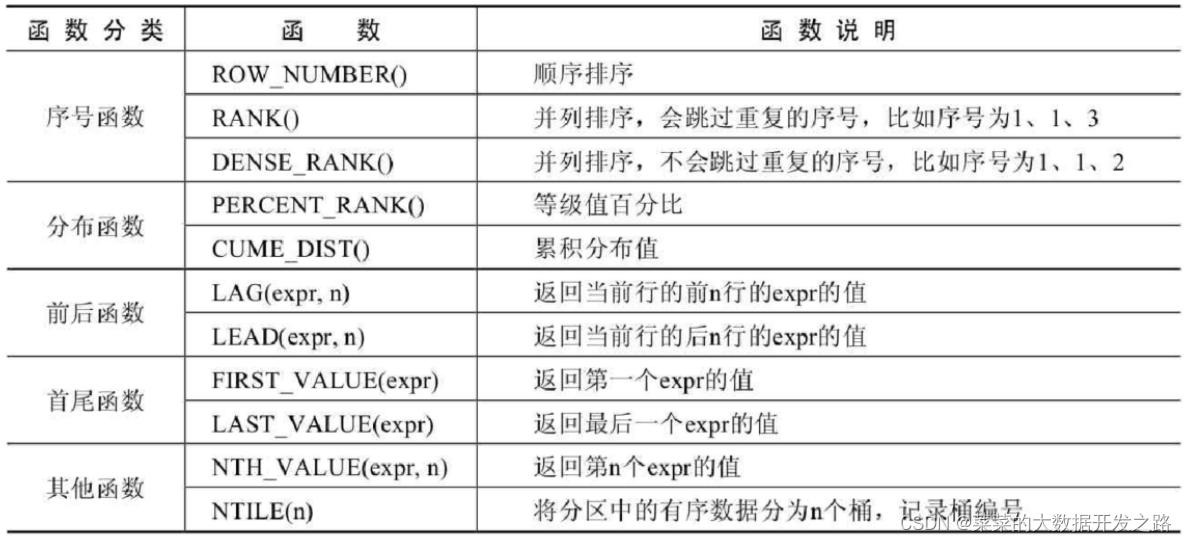
窗口函数总体上可以分为序号函数, 分布函数, 前后函数, 首尾函数和其他函数;
语法结构:
窗口函数的语法结构:
(1)函数 OVER ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
(2)函数 OVER 窗口名 … WInDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
OVER 关键字指定窗口的范围;
如果省略后面括号中的内容,则窗口会包含满足WHERE条件的所有记录,窗口函数会基于所有满足WHERE条件的记录进行计算。
如果OVER关键字后面的括号不为空,则可以使用如下语法设置窗口。
PARTITION BY 子句: 指定窗口函数按照哪些字段进行分组, 分组后, 窗口函数可以在每个分组中分别执行;
ORDER BY 子句: 指定窗口函数按照哪些字段进行排序, 执行排序操作使窗口函数按照排序后的数据记录的顺序进行编号;
FRAME 子句: 为分区中的某个子集定义规则, 可以用来作为滑动窗口使用;
1、序号函数:
序号函数是按照一定的分组规则对每一组的数据排序并创建一个序号列,
row_number() - 单纯的对每一组数据编号
1.1 查询 goods 数据表中每个商品分类下价格降序排列的各个商品信息。
SELECT *,
ROW_NUMBER() OVER (PARTITION BY category ORDER BY price DESC) AS row_num
FROM goods;
rank() - 对序号进行并列排序, 指定字段数值相同(同一等级),则会产生相同序号记录,且产生序号间隙,
如, 1,1,3,4 而不会是 1,2,3,4(row_number的结果), 也不是 1,1,2,3,4 (dense_rank的结果)
使用RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息。
SELECT *,
RANK() OVER (PARTITION BY category ORDER BY price DESC) AS top4Price
FROM goods
WHERE category = '女装/女士精品' LIMIT 4;
dense_rank() - 对序号进行并列排序, 指定字段数值相同(同一等级),则会产生相同序号记录,且产生序号间隙,
#使用DENSE RANK()函数获取goods数据表中类别为"女装/女士精品"的价格最高的4款商品信息。
SELECT *,
DENSE RANK()OVER(PARTITION BY category ORDER BY price) AS price_rank FROM goods where category = "女装/女士精品";
2、分布函数:
percent_rank() - 等级值百分比, (rank - 1)/ (rows - 1);计算分区或结果集中行的百分位数排名;
每行按照公式(rank-1)/ (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口(当前组)的总行数
SELECT
RANK() oVER (PARTITION BY category_id ORDER BY price DESC) AS r,
PERCENT_RANK( ) OVER (PARTITION BY category_id ORDER BY price DESC) As pr,id,
category_id, category,NAME,price,stock
FROM goods WHERE category_id = 1;
cume_dist() - 累积分布值, <=当前rank值的行数 / 分组内总行数;分组内<=当前rank值的行数 / 分组内总行数
#查询goods数据表中小于或等于当前价格的比例。
SELECT CUME_DIST()0VER(PARTITION BY category_id 0RDER BY price ASC) AS cd, id, category,NAME,price
FROM goods;
3、前后函数:
LAG(expr, n) - 返回当前行的前n行(本组内)的expr值;lag允许你在每一个分组内, 从当前行向前看n行数据;
n(也叫offset)是从当前行偏移的行数,以获取值。offset必须是一个非负整数。如果offset为零,则LAG()函数计算当前行的值。
如果省略 offset,则LAG()函数默认使用n=1, 向前看一个数据。
#查询goods数据表中前一个商品价格与当前商品价恰的差值###1.先得到前一个商品的价格
SELECT *,
LAG(price,1)OVER(PARTITION BY category ORDER BY price DESC) AS pre_price FROM goods;
select *, price-pre_price from (
SELECT *, LAG(price,1)OVER(PARTITION BY category ORDER BY price DESC) AS pre_price
FROM goods ) as t
LEAD(expr, n):返回当前行的后n行(本组)的expr值;同上理解
4、首位函数:
first_value(expr) , last_value(expr);first_value 取分组内排序后,截止到当前行,第一个值
select *,
first_value(price) over(partition by category_id order by price desc) as first_val_in_window from goods;
测试数据:

CREATE TABLE goods( id INT PRIMARY KEY AUTO_INCREMENT, category_id INT, category VARCHAR(15), NAME VARCHAR(30), price DECIMAL(10,2), stock INT, upper_time DATETIME ); INSERT INTO goods(category_id,category,NAME,price,stock,upper_time) VALUES (1, '女装/女士精品', 'T恤', 39.90, 1000, '2020-11-10 00:00:00'), (1, '女装/女士精品', '连衣裙', 79.90, 2500, '2020-11-10 00:00:00'), (1, '女装/女士精品', '卫衣', 89.90, 1500, '2020-11-10 00:00:00'), (1, '女装/女士精品', '牛仔裤', 89.90, 3500, '2020-11-10 00:00:00'), (1, '女装/女士精品', '百褶裙', 29.90, 500, '2020-11-10 00:00:00'), (1, '女装/女士精品', '呢绒外套', 399.90, 1200, '2020-11-10 00:00:00'), (2, '户外运动', '自行车', 399.90, 1000, '2020-11-10 00:00:00'), (2, '户外运动', '山地自行车', 1399.90, 2500, '2020-11-10 00:00:00'), (2, '户外运动', '登山杖', 59.90, 1500, '2020-11-10 00:00:00'), (2, '户外运动', '骑行装备', 399.90, 3500, '2020-11-10 00:00:00'), (2, '户外运动', '运动外套', 799.90, 500, '2020-11-10 00:00:00'), (2, '户外运动', '滑板', 499.90, 1200, '2020-11-10 00:00:00');
参考:https://blog.csdn.net/nmsLLCSDN/article/details/123287490


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律