Hadoop JVM调整解决 MapReduce 作业超时问题
2016-10-18 18:30 牛仔裤的夏天 阅读(1069) 评论(0) 收藏 举报MR汇总报错
在mr程序跑job时,reduce到一个点就卡住直到超时时间反馈超时再重试,一般都失败,如下图:
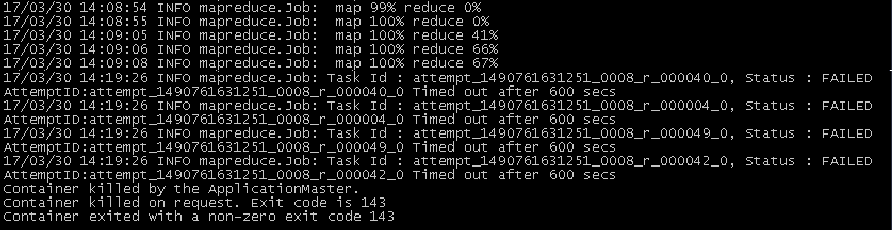
超时时间是在配置文件的默认配置:
这里的提示是Container killed by the ApplicationMaster,并没有具体参数提示。查找一些资料后发现,需要调整opts的值mapreduce.reduce.java.opts,默认4G,调试为6G测试,即值为"-Djava.net.preferIPv4Stack=true -Xmx6442450944" ,报错如下:
Container [pid=7830,containerID=container_1397098636321_27548_01_000297] is running beyond physical memory limits. Current usage: 2.1 GB of 2 GB physical memory used; 2.7 GB of 4.2 GB virtual memory used. Killing container.
这里的错误就比较明显了,物理内存不够,虚拟内存还可以(默认情况下:虚拟内存是物理内存的2.1倍)。这里是在reduce阶段有问题,所以需要调整reduce运行时的物理内存,mapreduce.reduce.memory.mb这个参数默认值为4G,调整为6144 (即6G)后,执行mr作业,正常结束。
总结了如下相关jvm设置:
参数 默认值 描述
yarn.scheduler.minimum-allocation-mb 1024 每个container请求的最低jvm配置,单位m。如果请求的内存小于该值,那么会重新设置为该值。
yarn.scheduler.maximum-allocation-mb 8192 每个container请求的最高jvm配置,单位m。如果大于该值,会被重新设置。
yarn.nodemanager.resource.memory-mb 8192 每个nodemanager节点准备最高内存配置,单位m
mapreduce.{map,reduce}.memory.mb 1024 设置运行map/reduce container的内存大小,单位m
mapreduce.{map,reduce}.java.opts -Xmx 设置执行map/reduce任务的JVM参数,值小于上一行设置的值,是在container中建立的jvm堆内存
mapreduce.map.memory.mb = (1~2倍) * yarn.scheduler.minimum-allocation-mb
mapreduce.reduce.memory.mb = (1~4倍) * yarn.scheduler.minimum-allocation-mb
总结:最终运行参数给定的jvm堆大小必须小于参数指定的map和reduce的memory大小,最好为70%以下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号