PostgreSQL 架构
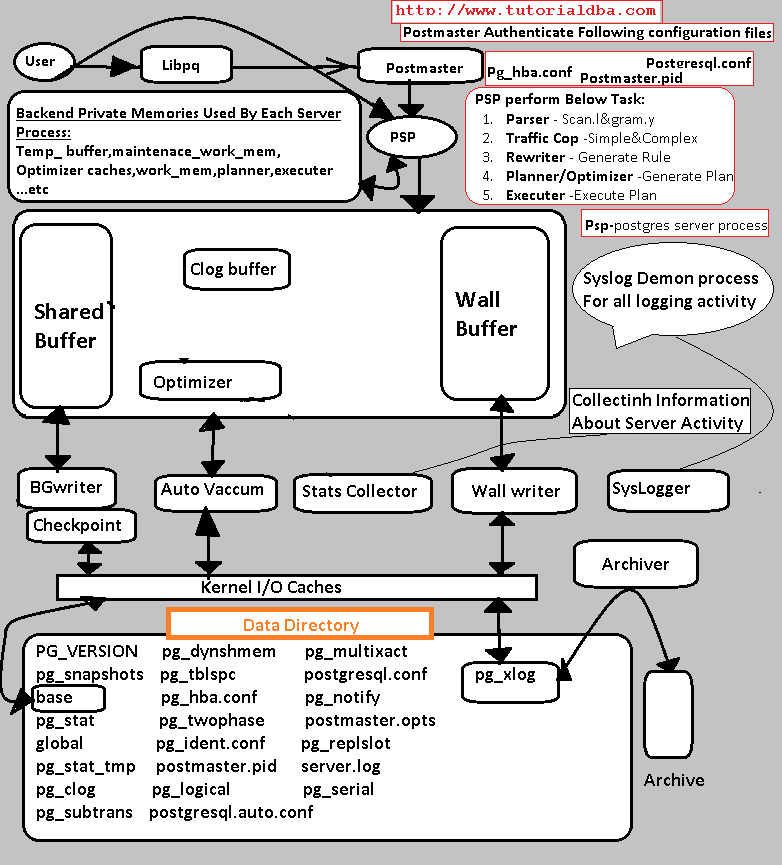
LIBPQ-图书馆池配额
![]()
- 关于已连接用户使用工具的详细信息
- libpq 是C 应用程序员与 PostgreSQL 的接口。libpq 是一组库函数,允许客户端程序将查询传递给 PostgreSQL 后端服务器并接收这些查询的结果。
- 使用 libpq 的客户端程序必须包含头文件 libpq-fe.h,并且必须与 libpq 库链接
- 源代码分发中的 src/test/examples 目录下还有 libpq 应用程序的几个完整示例。
- 每当我们发出查询或我们(客户端)所做的操作都称为客户端进程
- 它是前端。
- 前端可以是文本应用程序、图形应用程序或 Web 服务器页面。
- 通过 TCP/IP 客户端访问服务器
- 许多用户可以同时访问数据库
- FORKS – 此过程使多用户访问成为可能。它不会干扰 postgres 进程
- postmaster的工作是对端口(5432)进行认证,并为用户分配进程。
- 它也被称为postgres。它接受来自客户端(我们)的连接,如数据库文件并管理数据库操作。
Postgresql 10 naming updates:
9.6 Directory | 10 Directory
--------------+-------------
pg_xlog | pg_wal
pg_clog | pg_xact
pg_log | log
Postgres 服务器分为两部分
实例
二、贮存
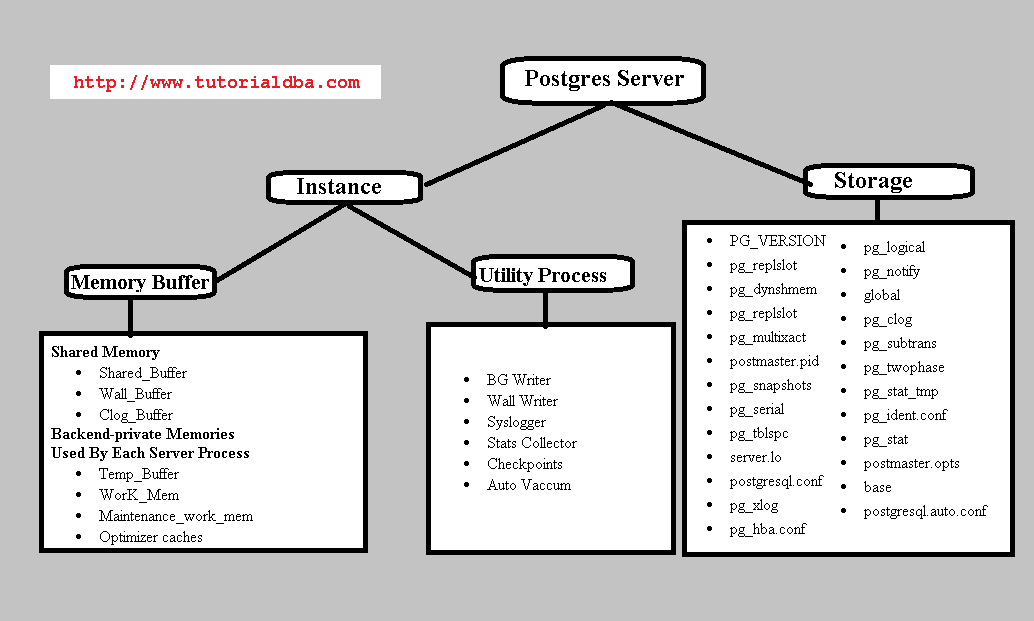
一、实例 分为两种类型
1.内存缓冲区
2.实用程序进程1.内存缓冲区:a)Shared_buffer:
- 设置数据库服务器用于共享内存缓冲区的内存量。默认值通常为 128 兆字节 (128MB),但如果您的内核设置不支持(在 initdb 期间确定),则默认值可能会更少。此设置必须至少为 128 千字节。(BLCKSZ 的非默认值会更改最小值。)但是,通常需要设置远高于最小值的设置才能获得良好的性能。此参数只能在服务器启动时设置。
- 如果您拥有一台具有 1GB 或更多 RAM 的专用数据库服务器,shared_buffers 的合理起始值是系统内存的 25%。在某些工作负载下,即使较大的 shared_buffers 设置也是有效的,但由于 PostgreSQL 还依赖于操作系统缓存,因此为 shared_buffers 分配超过 40% 的 RAM 不太可能比分配较小的 RAM 效果更好。较大的 shared_buffers 设置通常需要相应增加 checkpoint_segments,以便在更长的时间内分散写入大量新数据或更改数据的过程。
- 在 RAM 小于 1GB 的系统上,较小的 RAM 百分比是合适的,以便为操作系统留出足够的空间。此外,在 Windows 上,shared_buffers 的较大值效果不佳。您可能会发现将设置保持在相对较低水平并更多地使用操作系统缓存会获得更好的效果。
- Windows系统上shared_buffers的有用范围一般是64MB到512MB。
b)墙缓冲区:
- 用于尚未写入磁盘的 WAL 数据的共享内存量。默认设置 -1 选择的大小等于 shared_buffers 的 1/32(约 3%),但不小于 64kB,也不大于一个 WAL 段的大小,通常为 16MB。如果自动选择太大或太小,可以手动设置此值,但任何小于 32kB 的正值都将被视为 32kB。
- 此参数只能在服务器启动时设置。
- 每次事务提交时,WAL 缓冲区的内容都会写入磁盘, 因此过大的值不太可能带来显著的好处。但是,将此值设置为至少几兆字节可以提高繁忙服务器上的写入性能,因为许多客户端同时提交。默认设置 -1 选择的自动调整在大多数情况下应该会给出合理的结果。
c)CLOG缓冲液:
- CLOG BUFFERS 是面向循环数据“环”的 SLRU 样式缓冲区之一,例如 哪些事务号已提交或已回滚。
d)临时缓冲区:
- 设置每个数据库会话使用的临时缓冲区的最大数量。
- 这些是会话本地缓冲区,仅用于访问临时表。默认值为 8 兆字节 (8MB)。
- 可以在各个会话内更改该设置,但只能在会话内第一次使用临时表之前更改;后续尝试更改该值将不会对该会话产生影响。
- 会话将根据需要分配临时缓冲区,直至达到 temp_buffers 给出的限制。在实际上不需要很多临时缓冲区的会话中设置较大的值的成本仅为缓冲区描述符,即 temp_buffers 中每个增量约 64 个字节。但是,如果实际使用缓冲区,则会为其消耗额外的 8192 个字节(或一般为 BLCKSZ 字节)。
e)工作内存:
- 指定在写入临时磁盘文件之前 内部排序操作和哈希表要使用的内存量 。该值默认为 4 兆字节 (4MB)。
- 请注意,对于复杂查询,可能会并行运行多个排序或哈希操作;在开始将数据写入临时文件之前,每个操作将被允许使用此值指定的内存量。
- 此外,多个正在运行的会话可能会同时执行此类操作。因此,使用的总内存可能是 work_mem 值的很多倍;在选择值时必须牢记这一事实。排序操作用于 ORDER BY、DISTINCT 和合并连接。
- 哈希表用于哈希连接、基于哈希的聚合以及基于哈希的 IN 子查询处理。
f)维护工作内存:
- 指定维护操作(例如 VACUUM、CREATE INDEX 和 ALTER TABLE ADD FOREIGN KEY)使用的最大内存量 。默认为 64 兆字节 (64MB)。
- 由于数据库会话一次只能执行其中一个操作,并且安装通常不会同时运行多个操作,因此可以安全地将此值设置为远大于 work_mem。
- 更大的设置可能会提高清理和恢复数据库转储的性能。
请注意 ,当 autovacuum 运行时,最多可分配 autovacuum_max_workers 倍的内存,因此请注意不要将默认值设置得太高。通过单独设置 autovacuum_work_mem 来控制这一点可能会很有用。2 . 实用程序(后台)进程:a)BGWriter:
- 有一个单独的服务器进程称为后台写入器,其功能是发出“脏”(新的或修改的)共享缓冲区的写入。
- 它写入共享缓冲区,因此处理用户查询的服务器进程很少或永远不需要等待写入发生。
- 但是,后台写入器确实会导致 I/O 负载的总体净增加,因为虽然重复弄脏的页面可能在每个检查点间隔内仅被写入一次,但后台写入器可能会在同一间隔内将其写入多次。
- 本小节讨论的参数可用于根据当地需求调整行为。
b)WallWriter:
- 每次事务提交时, WAL 缓冲区都会 写入磁盘,因此过大的值不太可能带来显著的好处。但是,将此值设置为至少几兆字节可以提高繁忙服务器上的写入性能,因为许多客户端同时提交。默认设置 -1 选择的自动调整在大多数情况下应该会给出合理的结果。
- 指定 WAL 写入器活动轮次之间的延迟。在每一轮中,写入器都会将 WAL 刷新到磁盘。然后它会休眠 wal_writer_delay 毫秒,然后重复。
- 默认值为 200 毫秒 (200ms)。
- 请注意,在许多系统上,睡眠延迟的有效分辨率为 10 毫秒;将 wal_writer_delay 设置为非 10 的倍数的值可能会产生与将其设置为下一个更高的 10 的倍数相同的结果。此参数只能在 postgresql.conf 文件或服务器命令行中设置。
c)SysLogger:错误报告和日志记录

- 根据该图,可以清楚地看到,所有实用程序进程 + 用户后端 + Postmaster Daemon 都连接到 syslogger 进程,用于记录有关其活动的信息。每个进程信息都记录在 $PGDATA/pg_log 下的 .log 文件中。
- 调试更多进程信息将导致服务器开销。始终建议进行最低限度的调整。但是,必要时可以增加调试级别。单击此处了解有关日志记录参数的更多信息
- 日志收集器,这是一个后台进程,用于捕获发送到 stderr 的日志消息并将其重定向到日志文件
- log_directory- 数据目录
- log_filename-默认为postgresql-%Y-%m-%d_%H%M%S.log
- 默认权限为 0600
d)检查点:
检查点将发生在以下场景:
- pg_start_backup,
- 创建数据库,
- pg_ctl 停止|重新启动,
- pg_stop_备份,
- 提交问题,
- 页面很脏
- 以及其他一些。
- 它将内存中的所有脏页写入磁盘并清理 shared_buffers 区域。
- 如果您的 Postgres 服务器崩溃,您可以测量上次检查点值时间和 PostgreSQL 停止时间之间的数据丢失。您还可以使用此信息恢复您的系统。
- 如果我们增加 checkpoint_segments,则检查点出现的次数就会减少,并且 I/O 也会减少,因为需要写入磁盘的内容更少。
- 如果插入大量数据,则会生成更多检查点。
- 预写日志 (WAL) 会时不时地在事务日志中放置一个检查点。
- CHECKPOINT 命令在发出时强制立即进行检查点,而无需等待计划的检查点。
- 检查点是事务日志序列中的一个点,在该点处,所有数据文件都已更新以反映日志中的信息。所有数据文件都将刷新到磁盘。
- 如果在恢复期间执行,CHECKPOINT 命令将强制重新启动点而不是写入新的检查点。
- 只有超级用户可以调用 CHECKPOINT。此命令不适用于正常操作期间。
- 强制切换到新的事务日志文件(仅限于超级用户)或 切换到新的 xlog 文件pg_switch_xlog()
-
如果要强制切换日志文件,可以在 Postgres 上执行以下查询:
SELECT pg_switch_xlog();
e)统计收集器:
- PostgreSQL 的统计收集器是一个子系统,支持收集和报告 有关服务器活动的信息,然后将信息更新到优化器(pg_catalog),优化器使用 pg_catalog 生成查询计划。
- 收集器可以按磁盘块和单个行来统计对表和索引的访问。它还可以 跟踪每个表中的总行数 以及有关每个表的清理和分析操作的信息。
- 它还可以计算用户定义函数的调用次数以及每个函数所花费的总时间。
- PostgreSQL 还支持报告其他服务器进程当前正在执行的确切命令。此功能独立于收集器进程。
- 统计信息收集器通过临时文件将收集到的信息传输给其他 PostgreSQL 进程,这些文件存储在 stats_temp_directory 参数指定的目录中,默认为 pg_stat_tmp。
- 为了获得更好的性能,stats_temp_directory 可以指向基于 RAM 的文件系统,从而降低物理 I/O 要求。
- 当服务器正常关闭时,统计数据的永久副本将存储在 pg_stat 子目录中,以便在服务器重启后可以保留统计数据。
- 当服务器启动时执行恢复时(例如立即关闭、服务器崩溃和时间点恢复后),所有 统计计数器都将被重置。
f)存档:
- Achiver 进程是可选进程,默认为 OFF。
- 以存档模式设置数据库意味着在每个段文件写满后捕获其 WAL 数据,并在段文件被回收再利用之前将该数据保存在某个地方。
- 在数据库 Archivelog 模式下,一旦 WAL 数据填充到 WAL 段中,WAL Writer 就会在 PGDATA/pg_xlog/archive_status 下创建该填充段的文件,并将文件命名为“.ready”。文件命名将为“segment-filename.ready”。
- 当找到由 WAL Writer 进程创建的 处于“.ready”状态的文件时,Archiver Process 会触发。
- 归档进程选择 .ready 文件的“segment-file_number”,并将该文件从 $PGDATA/pg_xlog 位置复制到“archive_command”参数(postgresql.conf)中给出的相关归档目标。
- 从源复制到目标成功完成后,归档进程将“segment-filename.ready”重命名为“segment-filename.done”。这样就完成了归档过程。
- 可以理解的是,如果在 $PGDATA/pg_xlog/archive_status 中找到任何名为“segement-filename.ready”的文件。它们是尚未复制到存档目标的待处理文件。
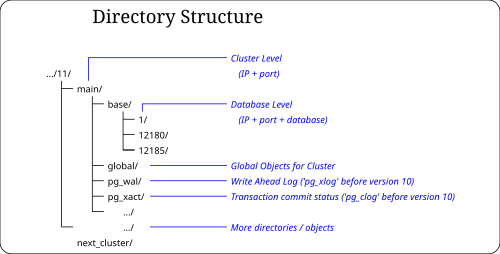
- 1.对于默认表空间中的文件:关系的 base/database_oid/filenode id
- 2.对于非默认表空间中的文件:关系的 pg_tblspc / tablespace_oid / tablespace_version_subdir / database_oid / filenode id
- 3.对于共享关系(见下文):关系的全局/文件节点 ID
1.对于默认表空间中的文件:
表的文件名不一定与 pg_class 中的 oid 相同,并且在运行 VACUUM FULL、TRUNCATE 等时可能会发生变化。
例如:
billing_db=# \dt+ List of relations Schema | Name | Type | Owner | Size | Description --------+------+-------+----------+---------+------------- public | t1 | table | postgres | 0 bytes | (1 row) billing_db=# SELECT pg_relation_filepath('t1'); pg_relation_filepath ---------------------- base/18144/18146 (1 row) billing_db=# insert into t1 values(2); INSERT 0 1 billing_db=# insert into t1 values(2); INSERT 0 1 billing_db=# insert into t1 values(2); INSERT 0 1 billing_db=# SELECT pg_relation_filepath('t1'); pg_relation_filepath ---------------------- base/18144/18146 (1 row) billing_db=# update t1 set id=1; UPDATE 3 billing_db=# SELECT pg_relation_filepath('t1'); pg_relation_filepath ---------------------- base/18144/18146 (1 row) billing_db=# vacuum t1; VACUUM billing_db=# SELECT pg_relation_filepath('t1'); pg_relation_filepath ---------------------- base/18144/18146 (1 row) billing_db=# vacuum full t1; VACUUM billing_db=# SELECT pg_relation_filepath('t1'); pg_relation_filepath ---------------------- base/18144/18149 (1 row)
注意,在 vacuum full 之后,此表 ID 从 18146 更改为 18149
2.非默认表空间路径:
SELECT pg_relation_filepath('t1'); pg_relation_filepath ---------------------- pg_tblspc / 16709 / PG_9.3_201306121 / 16499/19401
因此文件名模式可以分解为:
- pg_tblspc:它位于非默认表空间中
- 16709:它位于 oid 为 16709 的表空间中
- PG_9.3_201306121:由 PostgreSQL 9.3 使用,目录版本为 201306121。
- 16499:在数据库中,oid 为 16499
- 19401 relfilenode id 为 19401 的表
例如:
data_directory:
- 指定用于数据存储的目录。此参数只能在服务器启动时设置。
配置文件:
- 指定主服务器配置文件(通常称为 postgresql.conf)。此参数只能在 postgres 命令行上设置。
hba_文件:
- 指定基于主机的认证的配置文件(通常称为pg_hba.conf)。此参数只能在服务器启动时设置。
ident_file(识别文件):
- 指定用户名映射的配置文件(通常称为 pg_ident.conf)。这个参数只能在服务器启动时设置。
外部进程号文件:
- 指定服务器应创建供服务器管理程序使用的附加进程 ID (PID) 文件的名称。此参数只能在服务器启动时设置。
PG_日志:
- 它不是一个实际的 postgres 目录,而是 RHEL 存储实际文本 LOG 的目录。
PG_XLOG:
- 预写日志存储于此。它是日志文件,其中存储了已提交和未提交事务的所有日志。它最多包含 6 个日志,最后一个日志将被覆盖。如果存档器处于打开状态,它会移动到此处。
PG_CLOG:
- 它包含提交日志文件,用于实例崩溃后的恢复
PG_版本:
- 包含 PostgreSQL 主版本号的文件
Base:
- Subdirectory containing per-database subdirectories
Global:
- Subdirectory containing cluster-wide tables, such as pg_database
PG_MULTIXACT:
- Subdirectory containing multitransaction status data (used for shared row locks)
PG_SUBTRANS:
- Subdirectory containing subtransaction status data
PG_TBLSPC:
- Subdirectory containing symbolic links to tablespaces
PG_TWOPHASE:
- Subdirectory containing state files for prepared transactions
POSTMASTER.OPTS:
- A file recording the command-line options the postmaster was last started with
POSTMASTER.PID:
- A lock file recording the current postmaster PID and shared memory segment ID (not present after postmaster shutdown)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号