
Kafka 基础知识
在数据事件流方面,Apache Kafka 是事实上的标准。它是一个由服务器和客户端组成的开源分布式系统。Apache Kafka 主要用于构建实时数据流管道。
Apache Kafka 被全球数以千计的领先组织用于高性能数据管道、流分析、数据集成和许多其他重要应用程序。
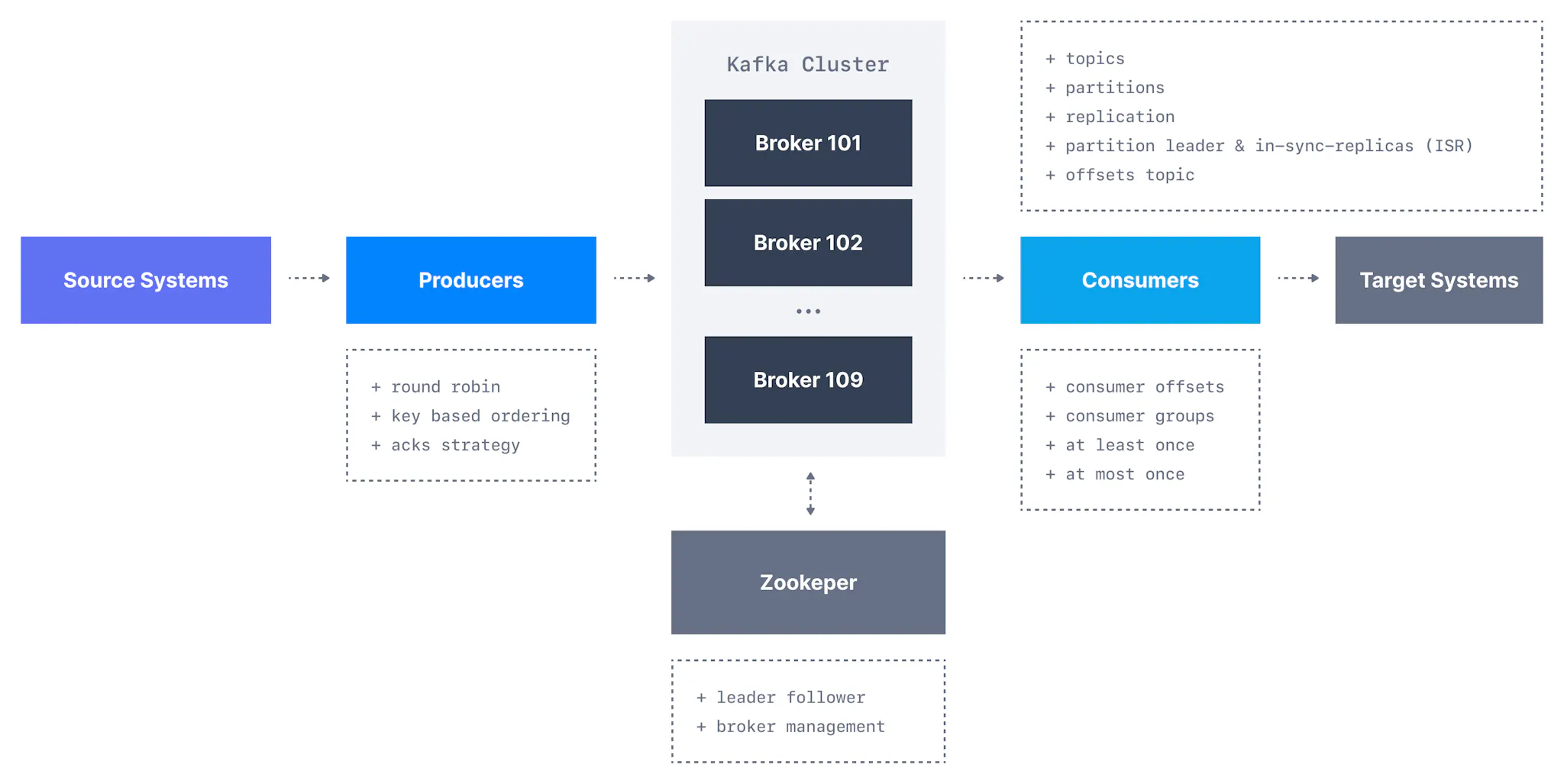
在本节中,我们将学习所有基础知识并了解各种 Apache Kafka 组件,例如:
-
Kafka 主题
-
Kafka 生产者
-
Kafka 消费者
-
Kafka 消费者组和消费者偏移
-
Kafka 经纪人
-
Kafka 主题复制
-
Zookeeper
-
KRaft 模式
什么是 Kafka 主题?
Apache Kafka 被全球数以千计的领先组织用于高性能数据管道、流分析、数据集成和许多其他重要应用程序。
主题由其名称标识。例如,我们可能有一个名为日志的主题,其中可能包含来自我们应用程序的日志消息,还有另一个名为购买的主题,其中可能包含来自我们应用程序的购买数据。
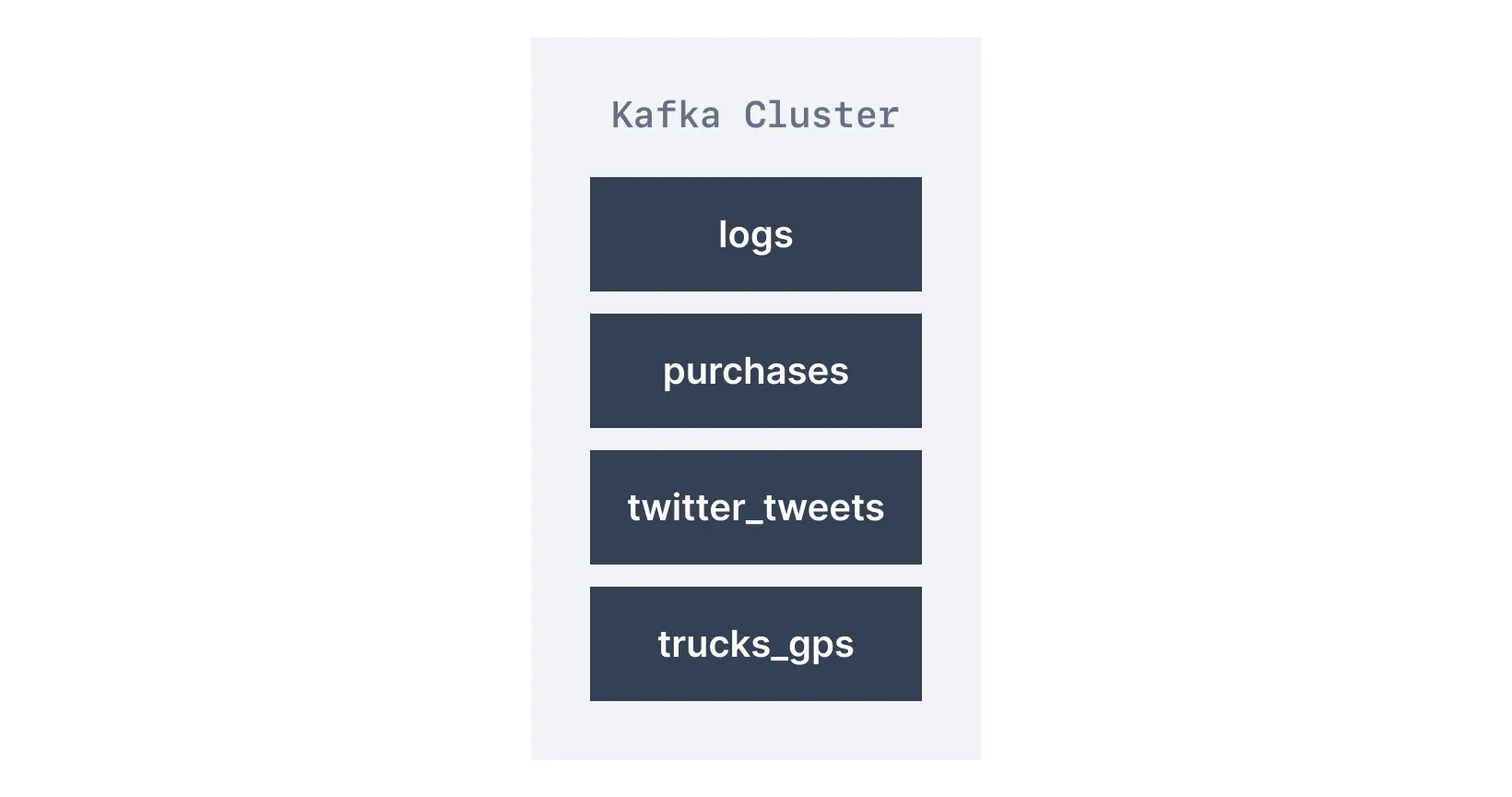
Kafka 主题可以包含任何格式的任何类型的消息,所有这些消息的序列称为数据流。
Kafka 主题中的数据默认在一周后删除(也称为默认消息保留期),此值是可配置的。这种删除旧数据的机制可确保 Kafka 集群不会因随着时间的推移回收主题而耗尽磁盘空间。
什么是 Kafka 分区?
主题被划分为多个分区。单个主题可能有多个分区,通常有 100 个分区。
主题的分区数是在创建主题时指定的。分区编号从 到 开始0,N-1其中N是分区数。下图显示了一个包含三个分区的主题,每个分区的末尾都附加了消息。
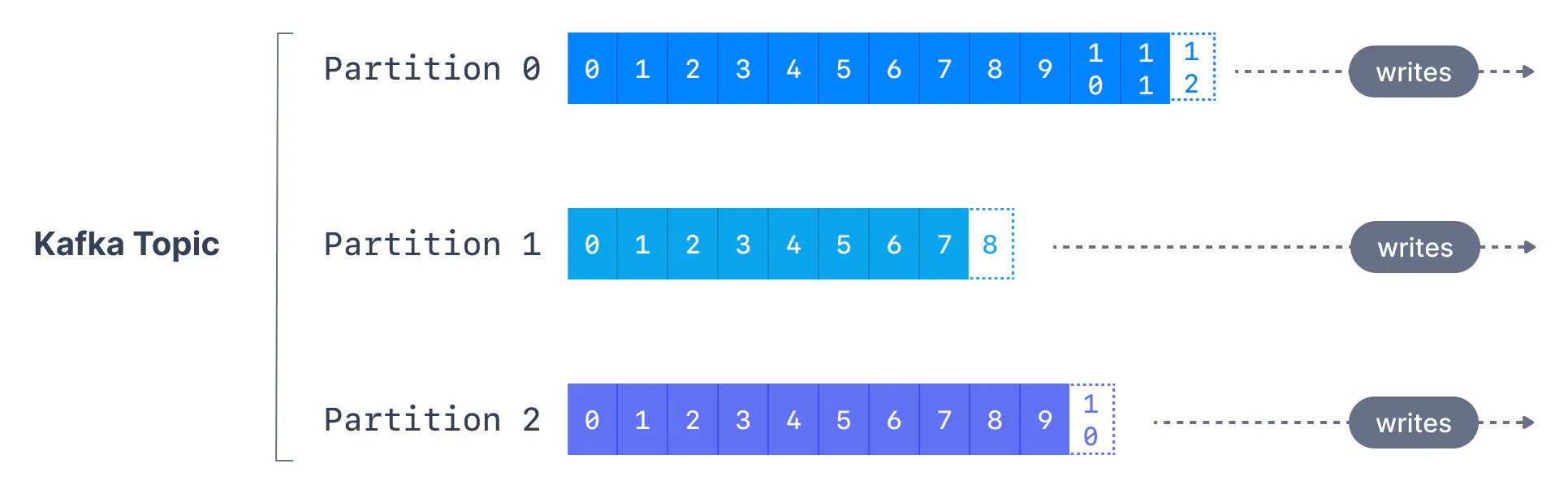
偏移量是 Kafka 在将每条消息写入分区时为其添加的一个整数值。给定分区中的每条消息都有一个唯一的偏移量。
Kafka 主题示例
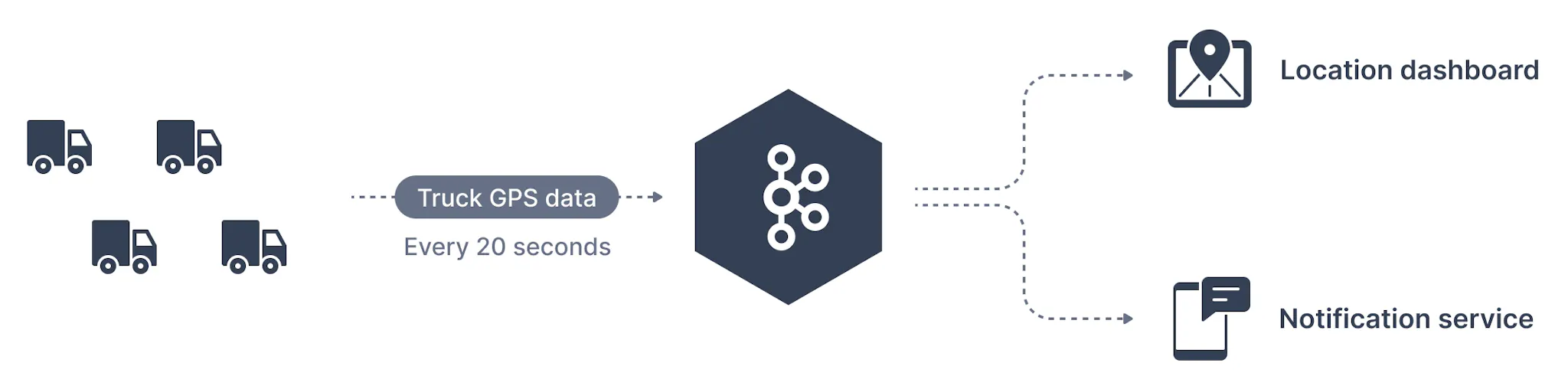
一家交通公司想要跟踪其卡车车队。每辆卡车都配备了 GPS 定位器,可将其位置报告给 Kafka。我们可以创建一个名为trucks_gps的主题,卡车会向该主题发布其位置。每辆卡车可以每 20 秒向 Kafka 发送一条消息,每条消息将包含卡车 ID 和卡车位置(纬度和经度)。该主题可以分成适当数量的分区,比如 10 个。该主题可能有不同的消费者。例如,一个在仪表板上显示卡车位置的应用程序或另一个在发生感兴趣的事件时发送通知的应用程序。
什么是 Kafka 偏移量?
Apache Kafka 偏移量表示消息在 Kafka 分区中的位置。每个分区的偏移量编号从开始,0并随着发送到特定 Kafka 分区的每条消息而递增。这意味着 Kafka 偏移量仅对特定分区有意义,例如,分区 0 中的偏移量 3 并不表示与分区 1 中的偏移量 3 相同的数据。
尽管我们知道 Kafka 主题中的消息会随着时间的推移而被删除(如上所示),但偏移量不会被重复使用。它们会以永无止境的序列不断增加。
Kafka 生产者
使用 Kafka 创建主题后,下一步就是将数据发送到主题。这就是 Kafka 生产者发挥作用的地方。
Kafka 生产者
将数据发送到主题的应用程序称为 Kafka 生产者。应用程序通常集成 Kafka 客户端库来写入 Apache Kafka。几乎所有当今流行的编程语言(包括 Python、Java、Go 等)都有出色的客户端库。
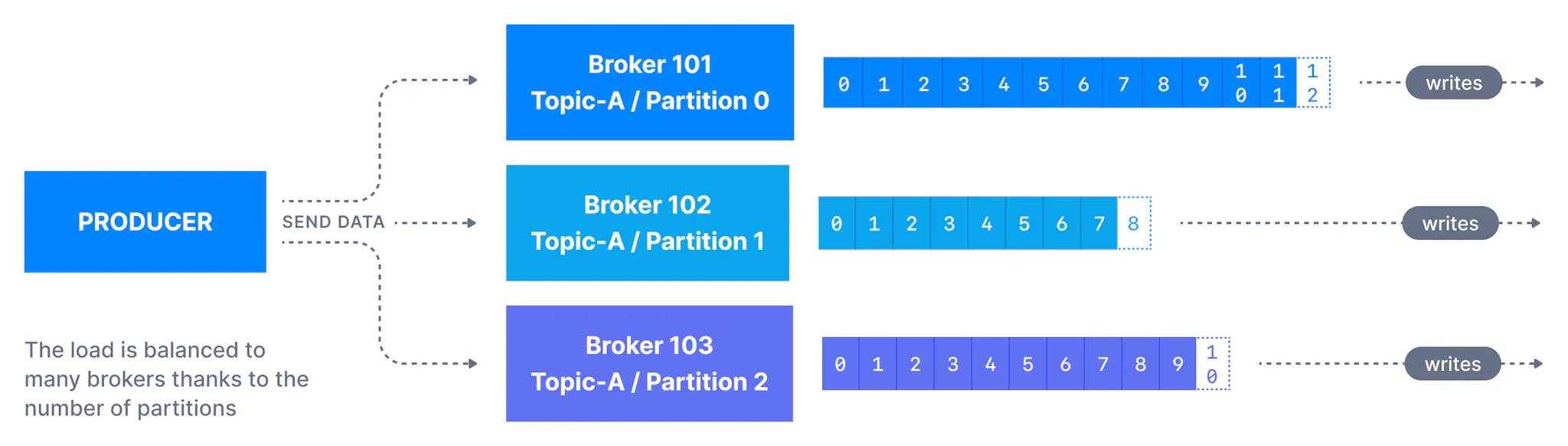
消息键
每个事件消息包含一个可选的键和一个值。
如果生产者未指定密钥 ( key=null),则消息将均匀分布在主题的各个分区中。这意味着消息以循环方式发送(分区p0,然后是p1 ,然后是p2,等等...然后返回p0等等...)。
如果发送了密钥(key != null),则共享同一密钥的所有消息将始终发送并存储在同一个 Kafka 分区中。密钥可以是任何用于标识消息的内容 - 字符串、数值、二进制值等。
当需要对共享同一字段的所有消息进行消息排序时,通常使用 Kafka 消息键。例如,在跟踪车队中的卡车的场景中,我们希望卡车的数据在单个卡车级别上按顺序排列。在这种情况下,我们可以选择键为truck_id。在下面显示的示例中,ID 为truck_id_123 的卡车的数据将始终进入分区p0。

您将在本页底部了解密钥散列的过程(确定哪个密钥属于哪个分区的过程)。
Kafka 消息剖析
Kafka 消息由生产者创建。Kafka 消息由以下元素组成:

-
Key。Kafka 消息中的 Key 是可选的,可以为空。Key 可以是字符串、数字或任何对象,然后 Key 被序列化为二进制格式。
-
值。值表示消息的内容,也可以为空。值的格式是任意的,然后也会序列化为二进制格式。
-
压缩类型。Kafka 消息可能被压缩。压缩类型可以作为消息的一部分指定。选项包括
none、gzip、lz4、snappy和zstd -
标头。可以以键值对的形式列出可选的 Kafka 消息标头。添加标头以指定有关消息的元数据是很常见的,尤其是对于跟踪而言。
-
分区 + 偏移量。一旦消息被发送到 Kafka 主题,它就会收到一个分区号和一个偏移量 ID。主题+分区+偏移量的组合唯一地标识了该消息
-
时间戳。时间戳由用户或系统添加到消息中。
Kafka 消息序列化器
在许多编程语言中,键和值都表示为对象,这大大提高了代码的可读性。但是,Kafka 代理希望将字节数组作为消息的键和值。将生产者对对象的编程表示转换为二进制的过程称为消息序列化。
如下所示,我们有一条包含Integer键和String值的消息。由于键是整数,因此我们必须使用IntegerSerializer将其转换为字节数组。对于值,由于它是一个字符串,因此我们必须利用StringSerializer。
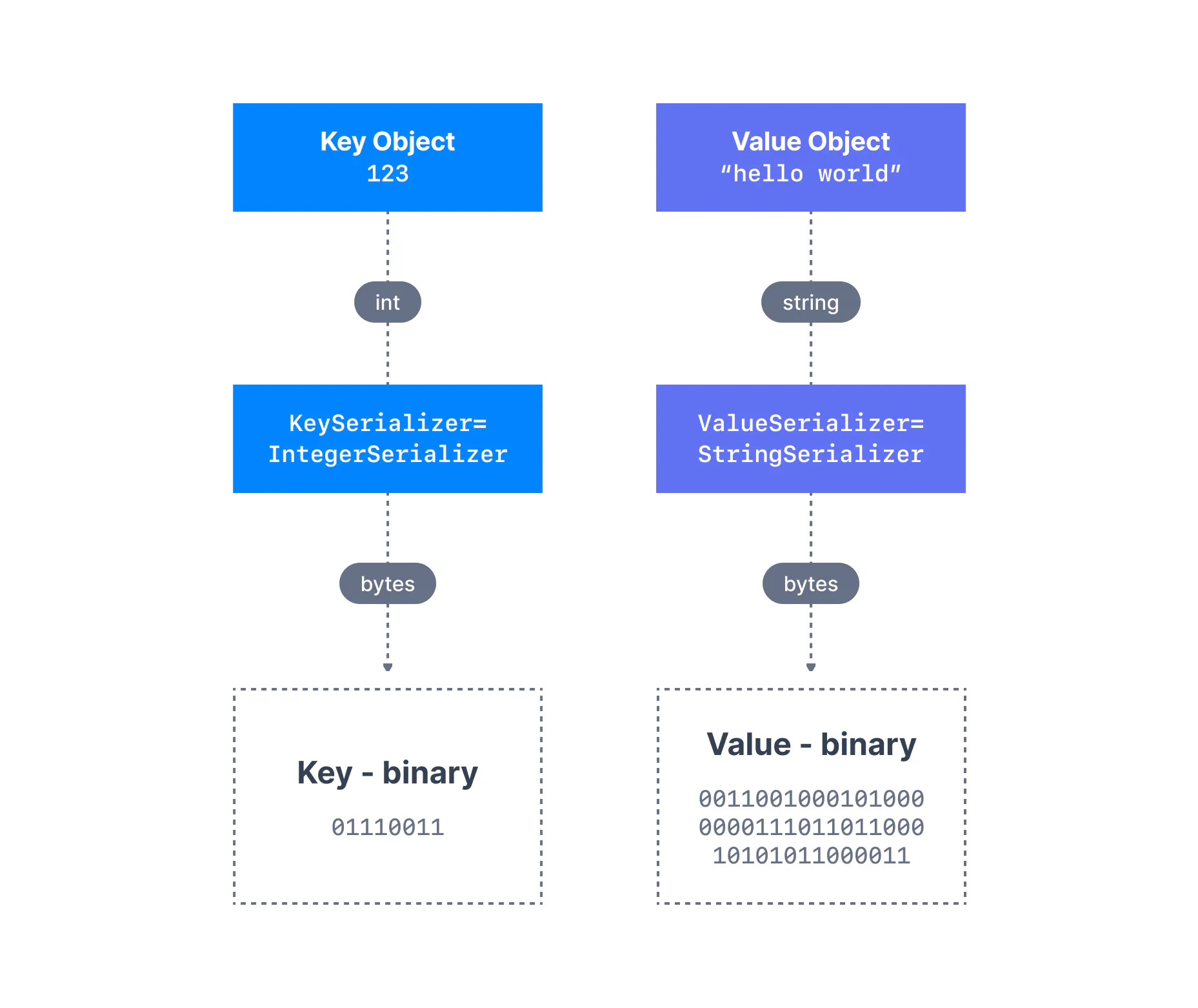
作为 Apache Kafka 的 Java 客户端 SDK 的一部分,已经存在多个序列化器,例如字符串(取代 JSON)、整数、浮点数。其他序列化器可能必须由用户编写,但常见的分布式 Kafka 序列化器已经存在,并且由于 Confluent Schema Registry 的存在,可以高效地为JSON-Schema、Apache Avro和Protobuf等格式编写。
好奇者:Kafka 消息密钥哈希
Kafka 分区器是一种代码逻辑,它获取记录并确定将其发送到哪个分区。

因此,分区器通常会利用 Kafka 消息键将消息路由到特定主题分区。提醒一下,所有具有相同键的消息都将发送到同一个分区。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号