
视频生成-OpenAI Sora
Video generation models as world simulators
我们探索了视频数据生成模型的大规模训练方法。具体来说,在不同时长、分辨率和纵横比的视频和图片数据上联合训练的文本条件扩散模型。利用transformer架构操作视频的时空块(patches)和图像隐编码(latent codes)。我们最大的模型Sora可以生成一分钟的高保真视频。结果表明扩大视频生成模型的规模是建立通用世界模拟器的一种有前途的路径。

本篇技术报告关注两个方面
- 将所有类型的视觉数据转化成统一表示形式的方法,以便大规模训练生成模型
- 定性地评估Sora方法的能力与局限
大多数先前的工作研究视频生成模型,涉及的多种不同的方法,有循环网络、生成对抗网络、自回归transformer,和扩散模型。然后这些工作通常关注一小类视觉数据,较短的视频或者固定尺寸的视频。Sora是一个视觉数据通用模型,它可以生成视频或者图片,具有不同时长/分辨率/纵横比,能生成一分钟的高清晰度视频。
将视觉数据转成块
受到大语言模型的启发,其能够通过训练互联网级别的数据获取通用能力。LLM范式的成功部分在于使用token,这种方式优雅地统一不同模态文本,包括不同自然语言、代码和数学。在这项工作中,也考虑如何使得视觉数据,使得生成模型也可以继承这种优点。正如LLM采用文本token那样,类似地Sora采用了视觉patch(块)。Patch概念已经展示出是视觉数据模型的一个有效表示。我们也发现在训练不同类型的视频和图片数据的生成模型,patch也是一种高度可扩展和有效的表示方式。
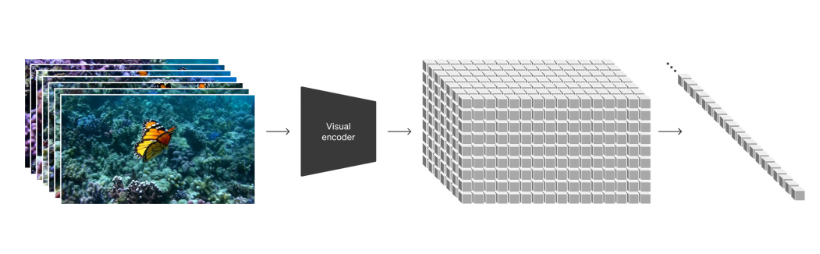
视频压缩网络
我们训练一个网络来压缩视觉数据的维度。这个网络输入的是原始视频数据,输出是隐变量表示,并在时间和空间上都进行了压缩。Sora训练和生成视频都是基于这个压缩后的隐变量空间。同时也训练的一个视觉解码器来将生成的隐变量值转化到像素空间
时空隐块
给定一个压缩的视频,提取得到时空块序列,这个序列就扮演着transformer tokens的角色,类比LLM的文本token。这种方式对图片也是有用的,因为图片是单帧的视频。我们基于块的表示方式,使得Sora可以联合训练具有不同时长、分辨率和纵横比的视频和图片。在推理阶段,通过设置适当尺寸的网格来控制生成视频的尺寸。
为视频生成扩展transformer
Sora是一个扩散模型,给定一个输入噪音或者还可以条件依赖其它信息如文本提示,然后训练其预测出原始无噪音的块patch。重要的是,Sora是一个扩散transformer。Transformer已经展示出显著的扩展能力,横跨不同的域,包括语言建模、计算机视觉和图像生成。

通过本项工作,可以发现扩散transformer也可以扩展到视频,下面是一组使用固定随机种子随着训练进行的视频样本取样比较。可以看出视频样本的质量随着训练计算增加而显著提升。

Base compute

4x compute

32x compute
不同时长,分辨率,纵横比
过去的图片和视频生成方法一般调整尺寸、裁剪视频到标准尺寸,比如256x256分辨率的4秒时长视频。我们发现对原始尺寸的视觉数据进行训练有较多好处。
取样灵活
Sora方法可以生成宽屏1920x1080p视频,竖屏1080x1920视频和任意介于之间尺寸的视频。这就使得Sora可以为不同的设备直接生成其原始纵横比的视频。也可以在生成全分辨率之前快速生成低分辨率原型内容。所有这些都是使用相同的模型。



改善框架和构图
我们经验地发现,使用视频原始的纵横比进行训练,可以改善框架和构图。使用Sora方法训练两个不同的模型,一个是使用裁剪为方形的视频数据,这种方式是通常采用的方法;另一个是采用视频原始纵横比训练。参考下面两个视频,左侧是方形训练的模型生成的视频,可以看出目标仅部分可见;右侧是使用原始纵横比训练的模型生成的视频,可以看出这种情况得到改善。


语言理解
训练T2V生成系统,需要大量带有文本字幕/注释的视频。我们应用DALL-E 3中介绍的字幕/注释信息再生成技术为视频生成对应的文本字幕/注释。首先训练一个高度描述字幕/注释模型,然后为训练集中所有视频生成对应文本字幕/注释信息。我们发现,对高度描述性的视频字幕/注释进行训练可以提高文本保真度以及视频的整体质量。
类似DALL-E 3,我们也利用GPT将短的用户提示词转换为长的详细的描述信息,然后输入给视频模型。使得Sora可以生成高质量的视频而且准确地遵循用户的提示。
用图像和视频提示
上面展示了基于文本提示生成的视频。此外Sora也可以使用其它形式的输入提示,比如预先存在的图片和视频。这就使得Sora可以进行各种图像和视频编辑人物,比如创建循环视频、使用静态图片制作动画,沿着时间轴向前向后扩展视频。
使用DALL-E图片生成动画
下面展示的是基于DALL-E 2 和DALLE 3图片生成的视频样例。


A Shiba Inu dog wearing a beret and black turtleneck.


Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.
扩展视频
Sora可以对视频进行扩展,沿着时间轴向前或者向后扩展。下面是4个视频,分别从一个相同的生成视频片段向后进行扩展。结果这四个视频是以不同的视频片段开始,最后以相同的视频片段结束。
生成循环视频
基于这个方法向前向后扩展视频,产生一个无限循环的视频

视频到视频编辑
由扩散模型出发提出了多种基于文本提示词的编辑图片和视频的方法。下面展示了将SDEdit方法应用到Sora中。这项技术使得Sora方法通过零样本方式转变输入视频的风格和环境。

input video

change the setting to the 1920s with an old school car. make sure to keep the red color
连接视频
我们可以使用Sora方法逐渐地对两个输入视频进行插值,使得这个两个视频之间的过渡没有痕迹,尽管这两个视频中的主体和场景构成完全不同。下面的示例 左右两侧是输入的视频,中间的视频是合成的连接视频



图像生成能力
Sora也具备图像生成能力。对空间网格中的块使用高斯噪音进行赋值,并设置时间轴方向是单帧,这样模型就可以生成不同尺寸的图像,最大到2048x2048分辨率。

Close-up portrait shot of a woman in autumn, extreme detail, shallow depth of field

Vibrant coral reef teeming with colorful fish and sea creatures
涌现的模拟能力
我们发现大规模训练时,视频模型展现出有趣的新兴能力。这些能力使得Sora可以从物理世界模拟人、动物和环境的某些方面。这些属性的出现没有对3D,物体等产生明显的归纳偏置。因为这是纯粹是规模化后的现象。
3D一致性 Sora可以生成的视频具有动态的镜头运动,随着镜头的移动和旋转,人物和场景原始在三维空间中也保持一致。


长范围的连贯性和物体持久性 视频生成任务的一个重要的挑战是在生成较长视频时,维持时间上的一致性。我们发现Sora经常但并不总是,可以优先建模短范围和长范围依赖。例如,我们的模型可以持久化人物、动物和物体,即使当他们被遮挡或者跳过一些视频帧,之前帧的人物、动画和物体仍延续下来没有发生跳变。


讨论
Sora当前作为一个模拟器也展示出了很多限制。例如其不能精确地建模物理世界中的许多交互,如玻璃破碎。其它交互,如吃东西,并不能一直产生正确的物体状态的改变。也存在其他常见的失败模式,比如生成的长视频中不一致问题或者物体自发出现。


我们相信Sora今天所展示的能力表明,继续扩展视频模型是通向开发具备模拟物理世界和数字世界、以及其中存在的物体、动物和人类的能力的有前途的途径。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号