视频生成-AnimateDiff快读
预备知识
视频生成依赖的技术点:Stable Diffusion,Latent Diffusion Model,DreamBooth, LoRA。此处不进行相关知识点介绍,如需请查阅相关资料
个性化动画生成
目标
生成个性化动画的图像模型,一般要求用对应的视频训练集进行额外的微调。而这将使事情变得困难。本文目标就是构建一个生成个性化的动画模型。更具体来说就是,给定一个已有的个性化T2I模型,比如一个DreamBooth或者LoRA模型参数检查点文件,将其转化为动画生成器。这个转化过程不进行训练或者进行很小的训练,但仍能保留模型原有的域知识和生成质量。比如T2I模型是针对某种类型2D动画风格进行优化训练,那么相应的动画生成器也能够生成具有适当运动的刚才风格的动画片段。
思路
一种实现路径,扩展T2I模型,通过添加时间感知的结构和从大规模的视频片段中学习合理的运动先验。然而对于特定的个性化场景,收集大量充足的视频是昂贵的,而有限的数据则无法学习到特定域知识。因此,才选择拆分为两部分:通用运动建模 + 个性化T2I生成。 这样就可以避免收集大量个性化的视频数据,而且不用修改个性T2I模型权重。而且通用运动建模完成,可以应用到任何个性化T2I模型。
运动建模模块
模块设计
原始SD模型仅处理批图片,尺寸为\(b \times c \times h \times w\),现在要处理视频即图片序列即多出一个维度,要处理批图片序列,尺寸为\(b \times c \times f \times h \times w\)。为了SD模型可以兼容这种数据,而且运动模块能够有效地进行视频帧之间的信息交互。运动模块采用普通的Temporal Transformer结构可以实现。输入特征\(z \in \mathbb R^{b \times c \times f \times h \times w}\),通过tensor reshape操作将特征\(z\)的\(h,w\)轴合并到\(b\)轴,得到\(z \in \mathbb R^{(b \times h \times w) \times f \times c}\)。这个类似\(b \times h \times w\)个token序列,每个token序列的长度是\(f\),token的特征维度是\(c\)。这样调整后的特征\(z\)就可以应用attention操作了。
这种操作可以在相同的空间位置处,沿着时间轴抓住不同视频帧之间的依赖关系。另一方面,为了扩大运动模块的感受野,在扩散模型U-Net模块中的每一个分辨率层级,都加入该运动模块。此外,还为视频帧添加了正余弦位置编码,从而使得动画片段每帧可以感知其在整个片段中的位置。
整体流程图如图Fig.1所示
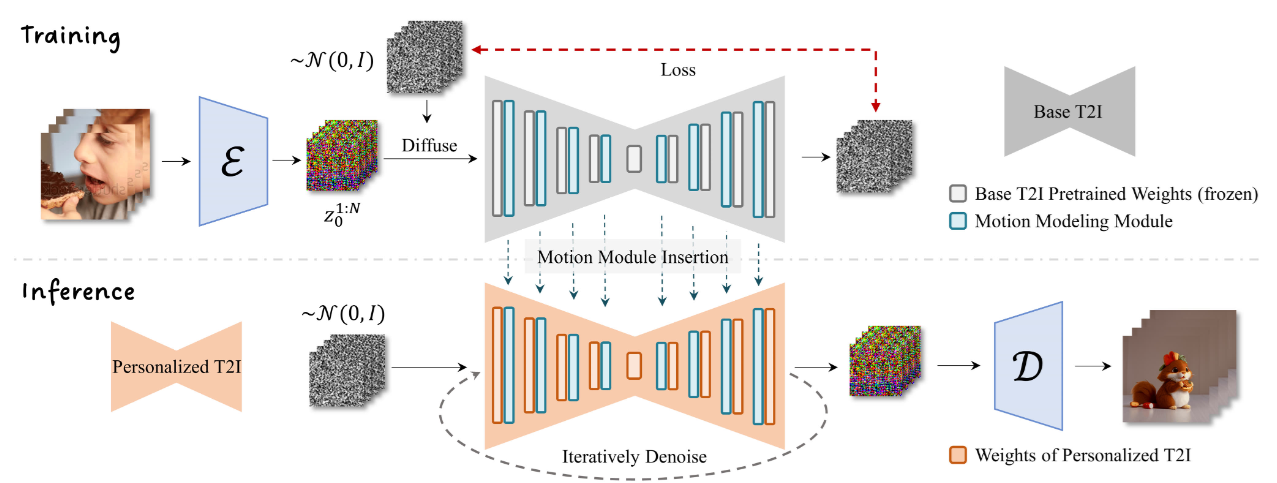
损失函数
损失函数设计本质上与LDM是一致的,唯一区别是后者输入单张图片对应隐变量\(z_0\),前者输入是输入图片序列对应的隐变量序列\(z_0^{1:N}\)。详细理解可以参考[2]或者扩散模型 Diffusion Model
实验
实验细节
- SD v1作为运动建模模块的基础模型(因为大量开源个性化生成模型都是基于此)
- 文-视频 训练数据集 WebVid-10M
- 视频片段每隔4帧进行抽样,然后缩放及中心裁剪到256x256,共计达到16帧长度.(256x256是为了兼顾效率和效果)
- 扩散系数设定有别与原始SD模型,寻找线性\(\beta\)机制,\(\beta_{start}=0.00085, \beta_{end}=0.012\),实验验证此种调整有利于生成更好的视觉质量,避免低饱和闪烁等问题。
评估
为了验证方法的有效性和泛化性,论文从CivitAi中收集多个个性化SD模型(参考Tab.1),模型生成的图像域从动漫、2D卡通到真实场景图片,以便全面地评估本论文提出的方面能力。一旦运动模块建模完成,就可以和个性化I2V集成,使用合适的text prompt就可以生成动画。

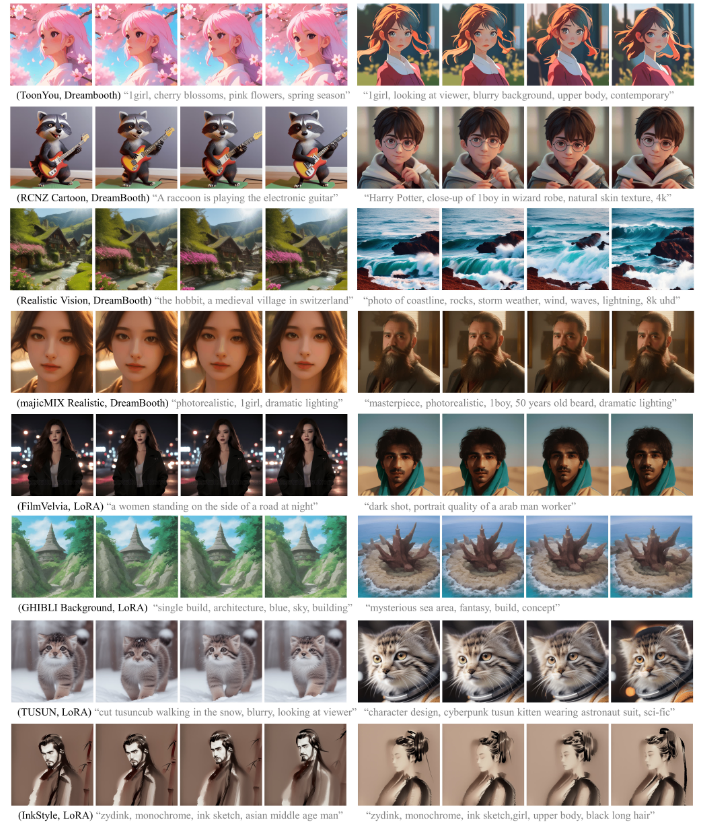
定性评估结果
Fig.2 展示了多个不同模型定性分析结果,最佳视觉对比参考论文主页 。图片中展示了具有不同域知识的T2I生成的动画,从第一行的动漫风格,到第四行的写实风格。 得益于从视频数据集学习到的运动先验,运动建模模块可以根据文本提示,为每个像素分配适当的运行。例如第三行的海浪运动,第七行猫的腿部动作。此外还可以区分图片中的主体与背景。
论文也是基于对这些不同I2V模型生成的视频定性的判断,得出通过插入运动建模模块可以生成高质量的动画,而且动画域可以适应于各种具有各种域知识的I2V模型。
与基线对比结果
选择对比的基线是Text2Video-Zero,该方法是免训练的。作者采用无任何参数微调的,按照Text2Video-Zero提供的默认参数生成512x512的16帧动画片段。通过限定相同的I2V模型和相同的prompt("A forbidden castle high up in the mountains, pixel art, intricate details2, hdr, intricate details") 定性对比这两种方法,生成视频的内容连贯性。
参考Fig.3,图片中左下角或者右下角是对图片中局部区域进行放大。通过对比,这两种方法都保留了I2V模型域知识,然后T2V-Zero方法生成的帧之间是很相似的,帧之前连贯性相比较差些。例如第1行中前景中的岩石形状和第3行中的杯子会随着时间的推移而变化,这种不连贯随着视频播放,表现比较明显。而本论文中的方法,第2行和第4行中展示的,表现出内容上更连贯。

问题
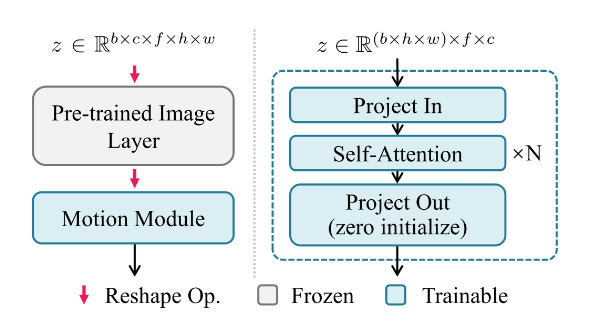
问题1:常规Transformer与Temporal Transformer在处理视频时是否有冲突呢?
SD模型训练输入的图片批次,其形状为\(b \times c \times h \times w\),进行attention建模是对同一张图片的不同空间位置关系进行的;而当前运动模块输入的批序列图片,其形状是\(b \times c \times f \times h \times w\) 而实际参与Temporal Transformer运算前,进行的reshape操作,变形为\({(b \times h \times w) \times f \times c}\),建模关系变成了相同空间位置不同视频帧之间的关系。这两种attention建模关系是完全不同的。为了融合这两种Transformer,对进入Temporal Transformer模块时进行上述reshape操作,输出时再进行相反的reshape操作,这样就可以解决这个问题了。可以从运动建模模块示意图Fig.4看出其中包含多次reshape操作。
问题2:训练和推理时,SD模块参数不一致是否有性能的损失呢
论文选择SD V1作为基础模型训练运行模块参数,而生成过程则使用基于此微调的各种个性化模型。运动模块训练时配合的SD模块的参数与推理时SD模块的参数是不一致的,这种不一致是否会导致性能的下降呢?
参考
[1]. AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning.
[2]. Understanding Diffusion Models: A Unified Perspective.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号