
多种模态数据集
图像描述 Image Captioning
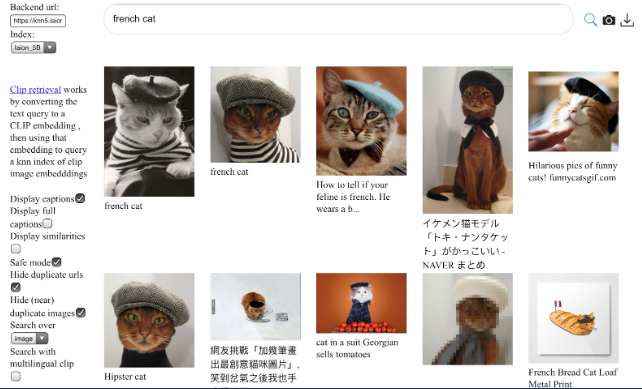
LAION-5B
- 2022.3发布的迄今为止最大规模的图文对的多模态数据集。共计约5.85B数据,是基于CLIP过滤的。基于这个大型数据集,作者也发布不同侧重的子集。LAION2B-en是包含英文注释文本的,LAION2B-multi是包含100多种的其它注释文本语言的,LAION2B-nolang其中文本注释至少包含一种无法准确检测识别的语言等等。
- 示例 https://laion.ai/blog/laion-5b/
COCO-700M
- 图文对数据集,包含约747M条数据。从HTML文档中提取约10B对数据清理后得到的
- 示例 https://github.com/kakaobrain/coyo-dataset https://en.wikipedia.org/wiki/Napoleon

COCO
- 微软发布的上下文通用物体数据集,该数据集涵盖了目标检测、分隔、关键点检测、图文注释这4个方面,共计有328k张图片。
- 示例 https://cocodataset.org/#home
NoCaps
- 从OpenImages数据集中验证与测试集中挑选出15k张图片,并为这些图片以人工方式,生成166k个与图片内容效能相关的文本描述语句。
- 示例 https://nocaps.org/

Flickr30K
- 从Flickr上收集的30k张图片,并人工为每张图片提供5条与图片内容相关文本描述语句。
- 示例 https://paperswithcode.com/dataset/flickr30k

TextCaps
- 28k张图片,共计145k条文本描述语句。该数据集要求模型识别文本并与视觉上下文建立联系。并决定复制或者解释句子中的某个部分,对文本中实体与视觉中实体之间进行空间位置、语义、和视觉推理。
- 示例 https://arxiv.org/pdf/2003.12462.pdf https://textvqa.org/textcaps/

视觉问答类 Visual Question Answering (VQA)
依据图片中展示出的视觉信息,提出若干个问题,并给于每个问题正确的答案。
VQAv2
- 根据图片提供一个问题,以及对应的相关答案。回答这些问题,需要看懂图片、理解文本和掌握常识。265k张图片、每张图片至少3个问题、每个问题10个相关答案与3个不相关答案。
- 示例 https://paperswithcode.com/dataset/visual-question-answering-v2-0
OKVQA
- 需要外部知识才能回答的问题。14k个开放性问题,每个问题5个相关答案,
- 示例 https://okvqa.allenai.org/

TextVQA
- 基于图片中文字信息进行视觉问答。要求可以读取识别图片中的文本信息,并回答与之相关的问题。来自OpenImage的28k张图片,45k个问题及453k个答案。
- 示例 https://textvqa.org/

VizWiz-VQA
- 回答盲人的视觉问答
- 示例 https://vizwiz.org/tasks-and-datasets/vqa/
![]()


OCR-VQA
- 基于图片中文字信息进行视觉问答
- 示例 https://anandmishra22.github.io/files/mishra-OCR-VQA.pdf

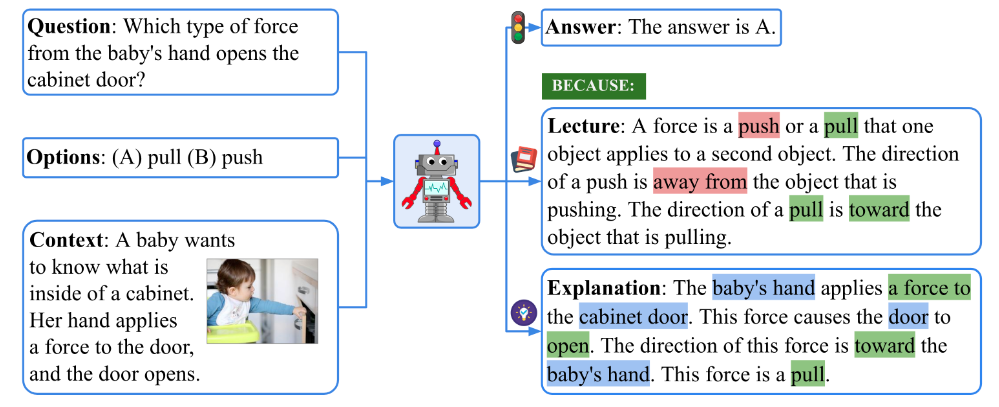
ScienceQA
- 21208个不同科学主题的多模态多项选择题,大多数问题都有答案及对应的讲座或者详细解释。
- 示例 https://scienceqa.github.io/
TDIUC
- 任务导向的视觉问答。170k张图片160万个问题,数据集分成12个不同任务相关问题类型
- 示例 https://kushalkafle.com/projects/tdiuc.html

Visual Grounding
根据文本问题,定位出图片中与之相关的物体
Visual7W
- 视觉问答多选题,每个问题是7W中一个,根据问题定位出图片中的物体
- 示例 https://paperswithcode.com/dataset/visual7w https://ai.stanford.edu/~yukez/visual7w/

RefCOCO/RefCOCO+
- RefCOCO对描述语言没有什么限制;而RefCOCO+则对描述语言进行了限制,更多从视觉特征来描述
- 示例 https://paperswithcode.com/dataset/refcoco


 浙公网安备 33010602011771号
浙公网安备 33010602011771号