
大规模分布式训练并行模式
大规模分布式训练并行模式
数据并行 Data Parallelism
模型在不同GPU上具有完全一致的副本,包括模型参数、模型梯度、模型优化器状态,这些都是完全相同的。唯一不同的是不同GPU上处理的数据是不同的,在每次梯度更新时,对所有数据产生梯度之和求平均,然后更新。
管道并行 Pipeline Parallelism
当模型参数量较大时,单张卡无法存放模型参数,一种方式就是将模型各个层分拆到N张GPU卡上,这样就解决了模型过大,单张GPU卡无法存放模型所有参数的问题了。
当采用管道并行时,最原始的使用方式,如Fig.1上半部分所示,保持原始的batch_size,会导致GPU大量空闲,每个时刻仅有单张GPU卡在工作,而其余的都处于空闲状态。一种解决办法如Fig.1下半部分所示,拆分原始的batch_size为若干份更小的micro_batchsize。之所以如此是更小的batchsize,位于计算过程前面的如device0 相对就计算更快,位于计算流程后面的如device1相对等待时间更短。

张量并行 Tensor Parallelism
Fig.2这张图很好的解释了张量并行模型。之所以可以如此,本质上是矩阵乘法定义所决定的。将矩阵乘法的两个矩阵A和B中一个或两个拆分成子矩阵,分块计算最后在合并,并不改变最终结果。
- 拆分方式一
设\(X \in \mathbb{R}^{n\times d}, A \in \mathbb{R}^{d \times m}, m=r+s\),这样就可以对矩阵\(A\)按列拆分为两部分,前r列\(A_1 \in \mathbb{R}^{d \times r}\),后s列\(A_2 \in \mathbb{R}^{d \times s}\), \(A = (A_1, A_2)\),于是
至此可以看出,数学上保证了矩阵乘法,将第二个乘法项按列拆分两个子矩阵,分别计算与子矩阵的乘法,与未拆分矩阵的乘法是等效的。
- 拆分方式二
设\(X \in \mathbb{R}^{n\times d}, A \in \mathbb{R}^{d \times m}, d=d_1+d_2\),也可以对矩阵按行拆分为两部分,前\(d_1\)行\(A_1 \in \mathbb{R}^{d_1 \times m}\),后\(d_2\)行\(A_2 \in \mathbb{R}^{d_2 \times m}\),\(A = \begin{pmatrix} A_1 \\ A_2 \end{pmatrix}\)。为了矩阵乘法进行,必须将\(X\)按照\(d=d_1+d_2\)按列方式进行拆分,即\(X = (X_1, X_2), X_1 \in \mathbb{R}^{n \times d_1}, X_2 \in \mathbb{R}^{n \times d_2}\)。于是
至此可以看出,数学上保证了矩阵乘法,将第二个乘法项按行拆分两个子矩阵,将第一个乘法项按列拆分为两个子矩阵,分别计算对于子矩阵的乘法,与未拆分矩阵的乘法是等效的。
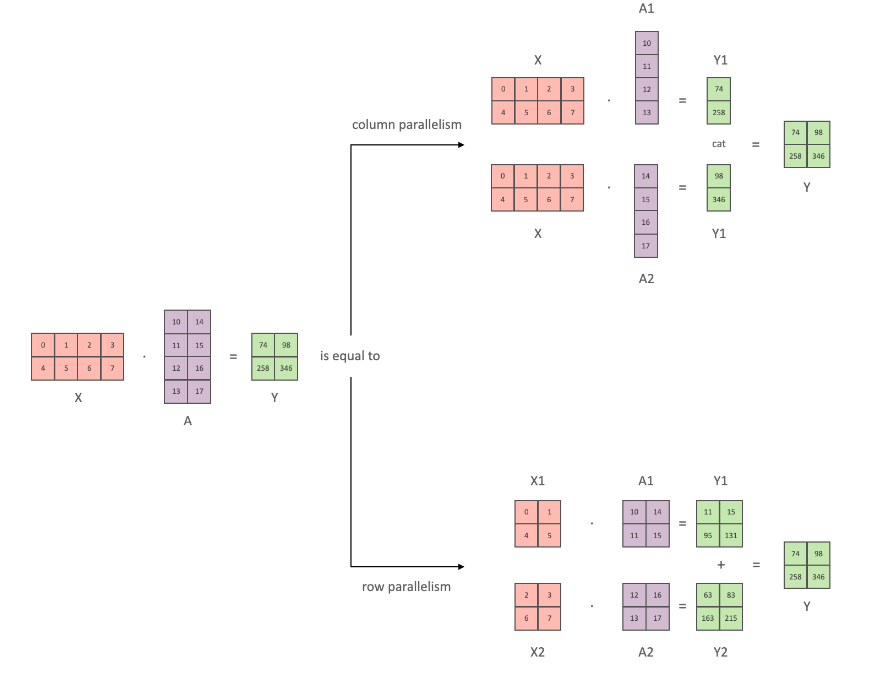
应用上面的分块矩阵操作,就可以对MLP操作进行改写。如下图所示,先按照拆分方式一对矩阵A进行按列拆分,得到对应结果后\((GeLU(XA_1), GeLU(XA_2))\),然后按照拆分方式二对矩阵B按行拆分,可以得到最终的\(Z\)

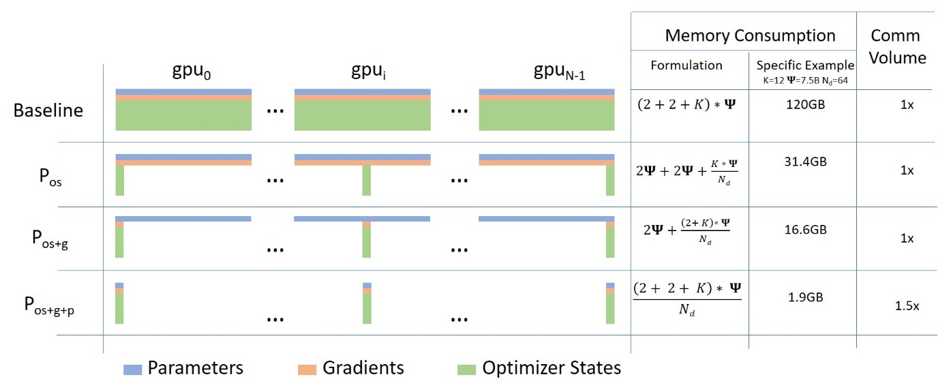
ZeRO
ZeRO 是Zero Redundancy Optimizer的简称。训练模型显存被下面的数据所占用
- 模型参数 \(weight\)
- 模型梯度 \(gradient\)
- 优化器状态量 \(optimizer \ states\)
- 输入的中间特征 \(hidden \ states\)
如下图所示
参考
https://huggingface.co/docs/transformers/v4.18.0/en/parallelism

 浙公网安备 33010602011771号
浙公网安备 33010602011771号