DDPM [diffusers] 保姆级代码解释 (1)
UNet2DModel 整体网络结构
block_out_channels: 参考UNet的思路,收缩阶段图像空间尺寸在变小但特征通道则增加;扩张阶段则相反。
- conv_in: 对输入的像素空间图像进行卷积处理,获得指定通道且与原始图像相同尺寸的第一层特征图
- down_blocks:依次对应收缩阶段的模块
- mid_block:对应中间模块
- up_blocks: 依次对应扩张阶段的模块
- conv_out: 后处理得到像素空间输出
点击查看 UNet2DModel
class UNet2DModel(ModelMixin, ConfigMixin):
r"""
A 2D UNet model that takes a noisy sample and a timestep and returns a sample shaped output.
This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
for all models (such as downloading or saving).
Parameters:
sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
Height and width of input/output sample. Dimensions must be a multiple of `2 ** (len(block_out_channels) -
1)`.
in_channels (`int`, *optional*, defaults to 3): Number of channels in the input sample.
out_channels (`int`, *optional*, defaults to 3): Number of channels in the output.
center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
time_embedding_type (`str`, *optional*, defaults to `"positional"`): Type of time embedding to use.
freq_shift (`int`, *optional*, defaults to 0): Frequency shift for Fourier time embedding.
flip_sin_to_cos (`bool`, *optional*, defaults to `True`):
Whether to flip sin to cos for Fourier time embedding.
down_block_types (`Tuple[str]`, *optional*, defaults to `("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D")`):
Tuple of downsample block types.
mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2D"`):
Block type for middle of UNet, it can be either `UNetMidBlock2D` or `UnCLIPUNetMidBlock2D`.
up_block_types (`Tuple[str]`, *optional*, defaults to `("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D")`):
Tuple of upsample block types.
block_out_channels (`Tuple[int]`, *optional*, defaults to `(224, 448, 672, 896)`):
Tuple of block output channels.
layers_per_block (`int`, *optional*, defaults to `2`): The number of layers per block.
mid_block_scale_factor (`float`, *optional*, defaults to `1`): The scale factor for the mid block.
downsample_padding (`int`, *optional*, defaults to `1`): The padding for the downsample convolution.
downsample_type (`str`, *optional*, defaults to `conv`):
The downsample type for downsampling layers. Choose between "conv" and "resnet"
upsample_type (`str`, *optional*, defaults to `conv`):
The upsample type for upsampling layers. Choose between "conv" and "resnet"
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
attention_head_dim (`int`, *optional*, defaults to `8`): The attention head dimension.
norm_num_groups (`int`, *optional*, defaults to `32`): The number of groups for normalization.
norm_eps (`float`, *optional*, defaults to `1e-5`): The epsilon for normalization.
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
for ResNet blocks (see [`~models.resnet.ResnetBlock2D`]). Choose from `default` or `scale_shift`.
class_embed_type (`str`, *optional*, defaults to `None`):
The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
`"timestep"`, or `"identity"`.
num_class_embeds (`int`, *optional*, defaults to `None`):
Input dimension of the learnable embedding matrix to be projected to `time_embed_dim` when performing class
conditioning with `class_embed_type` equal to `None`.
"""
@register_to_config
def __init__(
self,
sample_size: Optional[Union[int, Tuple[int, int]]] = None,
in_channels: int = 3,
out_channels: int = 3,
center_input_sample: bool = False,
time_embedding_type: str = "positional",
freq_shift: int = 0,
flip_sin_to_cos: bool = True,
down_block_types: Tuple[str] = ("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D"),
up_block_types: Tuple[str] = ("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D"),
block_out_channels: Tuple[int] = (224, 448, 672, 896),
layers_per_block: int = 2,
mid_block_scale_factor: float = 1,
downsample_padding: int = 1,
downsample_type: str = "conv",
upsample_type: str = "conv",
act_fn: str = "silu",
attention_head_dim: Optional[int] = 8,
norm_num_groups: int = 32,
norm_eps: float = 1e-5,
resnet_time_scale_shift: str = "default",
add_attention: bool = True,
class_embed_type: Optional[str] = None,
num_class_embeds: Optional[int] = None,
):
super().__init__()
self.sample_size = sample_size
time_embed_dim = block_out_channels[0] * 4
# Check inputs
if len(down_block_types) != len(up_block_types):
raise ValueError(
f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
)
if len(block_out_channels) != len(down_block_types):
raise ValueError(
f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
)
# input
self.conv_in = nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
# time
if time_embedding_type == "fourier":
self.time_proj = GaussianFourierProjection(embedding_size=block_out_channels[0], scale=16)
timestep_input_dim = 2 * block_out_channels[0]
elif time_embedding_type == "positional":
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
timestep_input_dim = block_out_channels[0]
self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
# class embedding
if class_embed_type is None and num_class_embeds is not None:
self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
elif class_embed_type == "timestep":
self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
elif class_embed_type == "identity":
self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
else:
self.class_embedding = None
self.down_blocks = nn.ModuleList([])
self.mid_block = None
self.up_blocks = nn.ModuleList([])
# down
output_channel = block_out_channels[0]
for i, down_block_type in enumerate(down_block_types):
input_channel = output_channel
output_channel = block_out_channels[i]
is_final_block = i == len(block_out_channels) - 1
down_block = get_down_block(
down_block_type,
num_layers=layers_per_block,
in_channels=input_channel,
out_channels=output_channel,
temb_channels=time_embed_dim,
add_downsample=not is_final_block,
resnet_eps=norm_eps,
resnet_act_fn=act_fn,
resnet_groups=norm_num_groups,
attention_head_dim=attention_head_dim if attention_head_dim is not None else output_channel,
downsample_padding=downsample_padding,
resnet_time_scale_shift=resnet_time_scale_shift,
downsample_type=downsample_type,
)
self.down_blocks.append(down_block)
# mid
self.mid_block = UNetMidBlock2D(
in_channels=block_out_channels[-1],
temb_channels=time_embed_dim,
resnet_eps=norm_eps,
resnet_act_fn=act_fn,
output_scale_factor=mid_block_scale_factor,
resnet_time_scale_shift=resnet_time_scale_shift,
attention_head_dim=attention_head_dim if attention_head_dim is not None else block_out_channels[-1],
resnet_groups=norm_num_groups,
add_attention=add_attention,
)
# up
reversed_block_out_channels = list(reversed(block_out_channels))
output_channel = reversed_block_out_channels[0]
for i, up_block_type in enumerate(up_block_types):
prev_output_channel = output_channel
output_channel = reversed_block_out_channels[i]
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
is_final_block = i == len(block_out_channels) - 1
up_block = get_up_block(
up_block_type,
num_layers=layers_per_block + 1,
in_channels=input_channel,
out_channels=output_channel,
prev_output_channel=prev_output_channel,
temb_channels=time_embed_dim,
add_upsample=not is_final_block,
resnet_eps=norm_eps,
resnet_act_fn=act_fn,
resnet_groups=norm_num_groups,
attention_head_dim=attention_head_dim if attention_head_dim is not None else output_channel,
resnet_time_scale_shift=resnet_time_scale_shift,
upsample_type=upsample_type,
)
self.up_blocks.append(up_block)
prev_output_channel = output_channel
# out
num_groups_out = norm_num_groups if norm_num_groups is not None else min(block_out_channels[0] // 4, 32)
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=num_groups_out, eps=norm_eps)
self.conv_act = nn.SiLU()
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, kernel_size=3, padding=1)
时间步特征化
- time_embed_dim: timestep特征维度是block_out_channels[0]的4倍,为什么?
- time_proj():采用正余弦或者傅里叶等对位置/时间步编码
- 正余弦时间步编码 Timesteps
- 傅里叶时间步编码 GaussianFourierProjection
- time_embedding(): 时间步特征模块TimestepEmbedding,本质上是有线性层和激活层构成的。对编码后的时间步再编码或提取特征。
- TimestepEmbedding
Timesteps
Timesteps类按照正余弦位置编码方式对时间步step进行编码,当然还有其它编码方式如傅里叶位置编码等。
点击展开 Timesteps
class Timesteps(nn.Module):
def __init__(self, num_channels: int, flip_sin_to_cos: bool, downscale_freq_shift: float):
super().__init__()
self.num_channels = num_channels
self.flip_sin_to_cos = flip_sin_to_cos
self.downscale_freq_shift = downscale_freq_shift
def forward(self, timesteps):
t_emb = get_timestep_embedding(
timesteps,
self.num_channels,
flip_sin_to_cos=self.flip_sin_to_cos,
downscale_freq_shift=self.downscale_freq_shift,
)
return t_emb
def get_timestep_embedding(
timesteps: torch.Tensor,
embedding_dim: int,
flip_sin_to_cos: bool = False,
downscale_freq_shift: float = 1,
scale: float = 1,
max_period: int = 10000,
):
"""
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
:param timesteps: a 1-D Tensor of N indices, one per batch element.
These may be fractional.
:param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
embeddings. :return: an [N x dim] Tensor of positional embeddings.
"""
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
half_dim = embedding_dim // 2
exponent = -math.log(max_period) * torch.arange(
start=0, end=half_dim, dtype=torch.float32, device=timesteps.device
)
exponent = exponent / (half_dim - downscale_freq_shift)
emb = torch.exp(exponent)
emb = timesteps[:, None].float() * emb[None, :]
# scale embeddings
emb = scale * emb
# concat sine and cosine embeddings
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
# flip sine and cosine embeddings
if flip_sin_to_cos:
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
# zero pad
if embedding_dim % 2 == 1:
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
return emb
GaussianFourierProjection
UNet2DModel 前向过程
- 输入前处理
- 收缩阶段
- 中间阶段
- 扩张阶段
- 输出后处理
点击展开 UNet2DModel forward
def forward(
self,
sample: torch.FloatTensor,
timestep: Union[torch.Tensor, float, int],
class_labels: Optional[torch.Tensor] = None,
return_dict: bool = True,
) -> Union[UNet2DOutput, Tuple]:
r"""
The [`UNet2DModel`] forward method.
Args:
sample (`torch.FloatTensor`):
The noisy input tensor with the following shape `(batch, channel, height, width)`.
timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
class_labels (`torch.FloatTensor`, *optional*, defaults to `None`):
Optional class labels for conditioning. Their embeddings will be summed with the timestep embeddings.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~models.unet_2d.UNet2DOutput`] instead of a plain tuple.
Returns:
[`~models.unet_2d.UNet2DOutput`] or `tuple`:
If `return_dict` is True, an [`~models.unet_2d.UNet2DOutput`] is returned, otherwise a `tuple` is
returned where the first element is the sample tensor.
"""
# 0. center input if necessary
if self.config.center_input_sample:
sample = 2 * sample - 1.0
# 1. time
timesteps = timestep
if not torch.is_tensor(timesteps):
timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device)
elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
timesteps = timesteps[None].to(sample.device)
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
timesteps = timesteps * torch.ones(sample.shape[0], dtype=timesteps.dtype, device=timesteps.device)
t_emb = self.time_proj(timesteps)
# timesteps does not contain any weights and will always return f32 tensors
# but time_embedding might actually be running in fp16. so we need to cast here.
# there might be better ways to encapsulate this.
t_emb = t_emb.to(dtype=self.dtype)
emb = self.time_embedding(t_emb)
if self.class_embedding is not None:
if class_labels is None:
raise ValueError("class_labels should be provided when doing class conditioning")
if self.config.class_embed_type == "timestep":
class_labels = self.time_proj(class_labels)
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
emb = emb + class_emb
# 2. pre-process
skip_sample = sample
sample = self.conv_in(sample)
# 3. down
down_block_res_samples = (sample,)
for downsample_block in self.down_blocks:
if hasattr(downsample_block, "skip_conv"):
sample, res_samples, skip_sample = downsample_block(
hidden_states=sample, temb=emb, skip_sample=skip_sample
)
else:
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
down_block_res_samples += res_samples
# 4. mid
sample = self.mid_block(sample, emb)
# 5. up
skip_sample = None
for upsample_block in self.up_blocks:
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
if hasattr(upsample_block, "skip_conv"):
sample, skip_sample = upsample_block(sample, res_samples, emb, skip_sample)
else:
sample = upsample_block(sample, res_samples, emb)
# 6. post-process
sample = self.conv_norm_out(sample)
sample = self.conv_act(sample)
sample = self.conv_out(sample)
if skip_sample is not None:
sample += skip_sample
if self.config.time_embedding_type == "fourier":
timesteps = timesteps.reshape((sample.shape[0], *([1] * len(sample.shape[1:]))))
sample = sample / timesteps
if not return_dict:
return (sample,)
return UNet2DOutput(sample=sample)
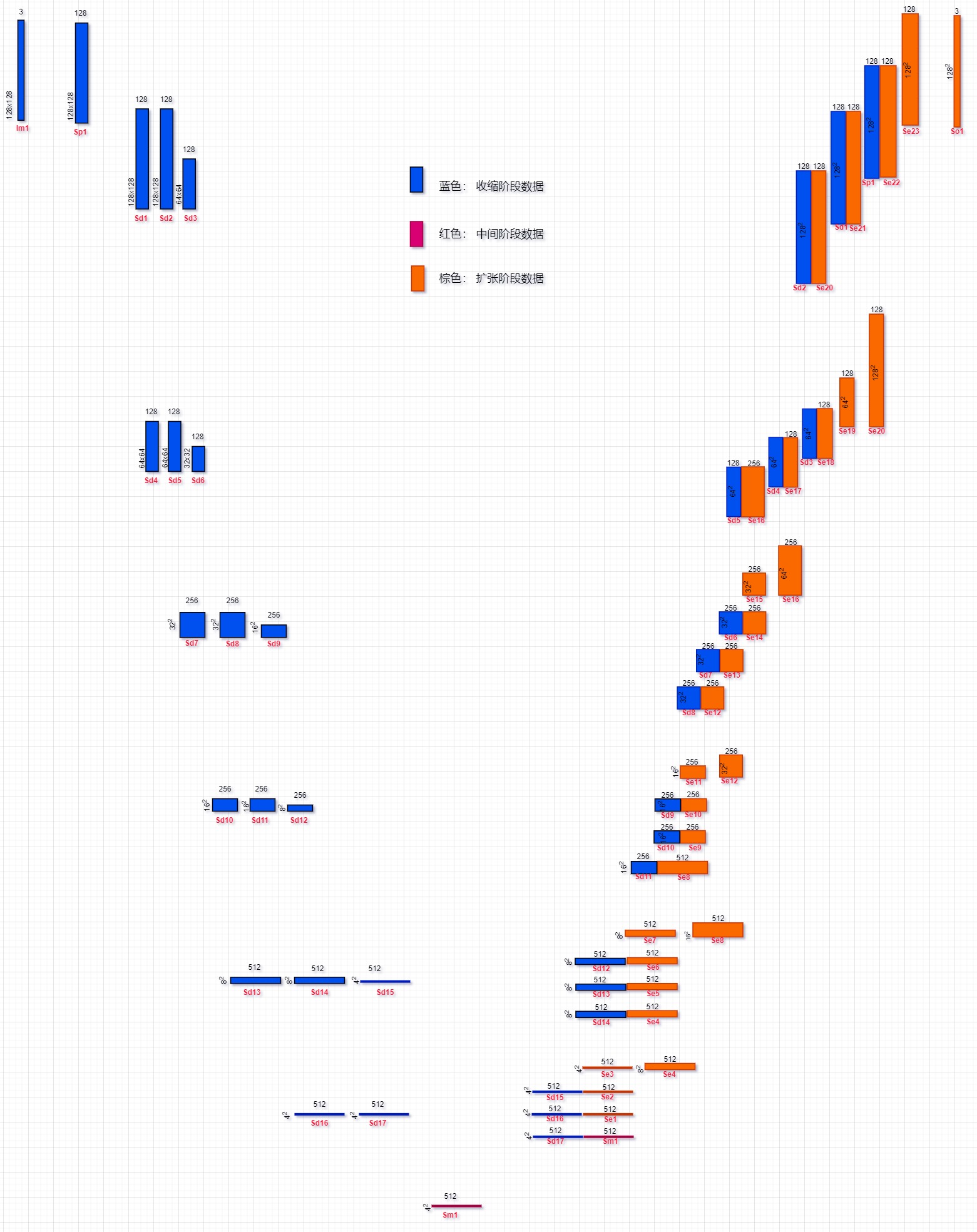
UNet2DModel 网络结构图
以diffuser中examples/unconditional_image_generation/train_unconditional.py为例,绘制UNet2DModel的网络结构图。
模型参数配置
按照下面UNet2DModel的配置,整个网络分成4个部分
- 输入预处理
- 单个卷积Conv
- 收缩阶段
- 6个子模块,依次为:DownBlock2D, DownBlock2D, DownBlock2D, DownBlock2D, AttnDownBlock2D, DownBlock2D
- 中间转折
- UNetMidBlock2d
- 扩张阶段
- 6个子模块,依次为:UpBlock2D, AttnUpBlock, UpBlock2D, UpBlock2D, UpBlock2D, UpBlock2D
- 输出后处理
点击查看 UNet2DModel配置
model = UNet2DModel(
sample_size=config.image_size, # the target image resolution
in_channels=3, # the number of input channels, 3 for RGB images
out_channels=3, # the number of output channels
layers_per_block=2, # how many ResNet layers to use per UNet block
block_out_channels=(128, 128, 256, 256, 512, 512), # the number of output channels for each UNet block
down_block_types=(
"DownBlock2D", # a regular ResNet downsampling block
"DownBlock2D",
"DownBlock2D",
"DownBlock2D",
"AttnDownBlock2D", # a ResNet downsampling block with spatial self-attention
"DownBlock2D",
),
up_block_types=(
"UpBlock2D", # a regular ResNet upsampling block
"AttnUpBlock2D", # a ResNet upsampling block with spatial self-attention
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
"UpBlock2D",
),
)
各模块输入输出
在UNet2DModel组成的各个子模块的forward中打印出中间输入及输出的shape
点击展开 输入输出shape
Input shape: torch.Size([1, 3, 128, 128])
[intput] sample shape: torch.Size([1, 128, 128, 128])
DownBlock2D [resnet]--> input torch.Size([1, 128, 128, 128]), output torch.Size([1, 128, 128, 128])
DownBlock2D [resnet]--> input torch.Size([1, 128, 128, 128]), output torch.Size([1, 128, 128, 128])
DownBlock2D [downsampler]--> input torch.Size([1, 128, 128, 128]), output torch.Size([1, 128, 64, 64])
[output] sample shape: torch.Size([1, 128, 64, 64]) [output] res_sample len 3 [output] down_block_res_samples len 4
[intput] sample shape: torch.Size([1, 128, 64, 64])
DownBlock2D [resnet]--> input torch.Size([1, 128, 64, 64]), output torch.Size([1, 128, 64, 64])
DownBlock2D [resnet]--> input torch.Size([1, 128, 64, 64]), output torch.Size([1, 128, 64, 64])
DownBlock2D [downsampler]--> input torch.Size([1, 128, 64, 64]), output torch.Size([1, 128, 32, 32])
[output] sample shape: torch.Size([1, 128, 32, 32]) [output] res_sample len 3 [output] down_block_res_samples len 7
[intput] sample shape: torch.Size([1, 128, 32, 32])
DownBlock2D [resnet]--> input torch.Size([1, 128, 32, 32]), output torch.Size([1, 256, 32, 32])
DownBlock2D [resnet]--> input torch.Size([1, 256, 32, 32]), output torch.Size([1, 256, 32, 32])
DownBlock2D [downsampler]--> input torch.Size([1, 256, 32, 32]), output torch.Size([1, 256, 16, 16])
[output] sample shape: torch.Size([1, 256, 16, 16]) [output] res_sample len 3 [output] down_block_res_samples len 10
[intput] sample shape: torch.Size([1, 256, 16, 16])
DownBlock2D [resnet]--> input torch.Size([1, 256, 16, 16]), output torch.Size([1, 256, 16, 16])
DownBlock2D [resnet]--> input torch.Size([1, 256, 16, 16]), output torch.Size([1, 256, 16, 16])
DownBlock2D [downsampler]--> input torch.Size([1, 256, 16, 16]), output torch.Size([1, 256, 8, 8])
[output] sample shape: torch.Size([1, 256, 8, 8]) [output] res_sample len 3 [output] down_block_res_samples len 13
[intput] sample shape: torch.Size([1, 256, 8, 8])
DownBlock2D [resnet+attn] --> input torch.Size([1, 256, 8, 8]), output torch.Size([1, 512, 8, 8]).
DownBlock2D [resnet+attn] --> input torch.Size([1, 512, 8, 8]), output torch.Size([1, 512, 8, 8]).
[output] sample shape: torch.Size([1, 512, 4, 4]) [output] res_sample len 3 [output] down_block_res_samples len 16
[intput] sample shape: torch.Size([1, 512, 4, 4])
DownBlock2D [resnet]--> input torch.Size([1, 512, 4, 4]), output torch.Size([1, 512, 4, 4])
DownBlock2D [resnet]--> input torch.Size([1, 512, 4, 4]), output torch.Size([1, 512, 4, 4])
[output] sample shape: torch.Size([1, 512, 4, 4]) [output] res_sample len 2 [output] down_block_res_samples len 18
------------------ mid --------------------------
[intput] sample shape: torch.Size([1, 512, 4, 4])
[output] sample shape: torch.Size([1, 512, 4, 4])
------------------ up ------------------------
[intput] sample shape: torch.Size([1, 512, 4, 4])
UpBlock2D [resnet]--> input1 torch.Size([1, 512, 4, 4]), input2 torch.Size([1, 512, 4, 4]), input1+input2 torch.Size([1, 1024, 4, 4])output torch.Size([1, 512, 4, 4])
UpBlock2D [resnet]--> input1 torch.Size([1, 512, 4, 4]), input2 torch.Size([1, 512, 4, 4]), input1+input2 torch.Size([1, 1024, 4, 4])output torch.Size([1, 512, 4, 4])
UpBlock2D [resnet]--> input1 torch.Size([1, 512, 4, 4]), input2 torch.Size([1, 512, 4, 4]), input1+input2 torch.Size([1, 1024, 4, 4])output torch.Size([1, 512, 4, 4])
UpBlock2D [upsampler]--> input torch.Size([1, 512, 4, 4]), output torch.Size([1, 512, 8, 8])
[output] sample shape: torch.Size([1, 512, 8, 8])
[intput] sample shape: torch.Size([1, 512, 8, 8])
AttnUpBlock2D [resnet+atten]--> input1 torch.Size([1, 512, 8, 8]), input2 torch.Size([1, 512, 8, 8]), input1+input2 torch.Size([1, 1024, 8, 8]), output torch.Size([1, 512, 8, 8])
AttnUpBlock2D [resnet+atten]--> input1 torch.Size([1, 512, 8, 8]), input2 torch.Size([1, 512, 8, 8]), input1+input2 torch.Size([1, 1024, 8, 8]), output torch.Size([1, 512, 8, 8])
AttnUpBlock2D [resnet+atten]--> input1 torch.Size([1, 512, 8, 8]), input2 torch.Size([1, 256, 8, 8]), input1+input2 torch.Size([1, 768, 8, 8]), output torch.Size([1, 512, 8, 8])
AttnUpBlock2D [upsampler]--> input torch.Size([1, 512, 8, 8]), output torch.Size([1, 512, 16, 16])
[output] sample shape: torch.Size([1, 512, 16, 16])
[intput] sample shape: torch.Size([1, 512, 16, 16])
UpBlock2D [resnet]--> input1 torch.Size([1, 512, 16, 16]), input2 torch.Size([1, 256, 16, 16]), input1+input2 torch.Size([1, 768, 16, 16])output torch.Size([1, 256, 16, 16])
UpBlock2D [resnet]--> input1 torch.Size([1, 256, 16, 16]), input2 torch.Size([1, 256, 16, 16]), input1+input2 torch.Size([1, 512, 16, 16])output torch.Size([1, 256, 16, 16])
UpBlock2D [resnet]--> input1 torch.Size([1, 256, 16, 16]), input2 torch.Size([1, 256, 16, 16]), input1+input2 torch.Size([1, 512, 16, 16])output torch.Size([1, 256, 16, 16])
UpBlock2D [upsampler]--> input torch.Size([1, 256, 16, 16]), output torch.Size([1, 256, 32, 32])
[output] sample shape: torch.Size([1, 256, 32, 32])
[intput] sample shape: torch.Size([1, 256, 32, 32])
UpBlock2D [resnet]--> input1 torch.Size([1, 256, 32, 32]), input2 torch.Size([1, 256, 32, 32]), input1+input2 torch.Size([1, 512, 32, 32])output torch.Size([1, 256, 32, 32])
UpBlock2D [resnet]--> input1 torch.Size([1, 256, 32, 32]), input2 torch.Size([1, 256, 32, 32]), input1+input2 torch.Size([1, 512, 32, 32])output torch.Size([1, 256, 32, 32])
UpBlock2D [resnet]--> input1 torch.Size([1, 256, 32, 32]), input2 torch.Size([1, 128, 32, 32]), input1+input2 torch.Size([1, 384, 32, 32])output torch.Size([1, 256, 32, 32])
UpBlock2D [upsampler]--> input torch.Size([1, 256, 32, 32]), output torch.Size([1, 256, 64, 64])
[output] sample shape: torch.Size([1, 256, 64, 64])
[intput] sample shape: torch.Size([1, 256, 64, 64])
UpBlock2D [resnet]--> input1 torch.Size([1, 256, 64, 64]), input2 torch.Size([1, 128, 64, 64]), input1+input2 torch.Size([1, 384, 64, 64])output torch.Size([1, 128, 64, 64])
UpBlock2D [resnet]--> input1 torch.Size([1, 128, 64, 64]), input2 torch.Size([1, 128, 64, 64]), input1+input2 torch.Size([1, 256, 64, 64])output torch.Size([1, 128, 64, 64])
UpBlock2D [resnet]--> input1 torch.Size([1, 128, 64, 64]), input2 torch.Size([1, 128, 64, 64]), input1+input2 torch.Size([1, 256, 64, 64])output torch.Size([1, 128, 64, 64])
UpBlock2D [upsampler]--> input torch.Size([1, 128, 64, 64]), output torch.Size([1, 128, 128, 128])
[output] sample shape: torch.Size([1, 128, 128, 128])
[intput] sample shape: torch.Size([1, 128, 128, 128])
UpBlock2D [resnet]--> input1 torch.Size([1, 128, 128, 128]), input2 torch.Size([1, 128, 128, 128]), input1+input2 torch.Size([1, 256, 128, 128])output torch.Size([1, 128, 128, 128])
UpBlock2D [resnet]--> input1 torch.Size([1, 128, 128, 128]), input2 torch.Size([1, 128, 128, 128]), input1+input2 torch.Size([1, 256, 128, 128])output torch.Size([1, 128, 128, 128])
UpBlock2D [resnet]--> input1 torch.Size([1, 128, 128, 128]), input2 torch.Size([1, 128, 128, 128]), input1+input2 torch.Size([1, 256, 128, 128])output torch.Size([1, 128, 128, 128])
[output] sample shape: torch.Size([1, 128, 128, 128])
整理输入输出流
输入预处理
- 输入图像数据流 用Im1表示
- 预处理阶段用Sp前缀表示,数字序号表示不同阶段的输入或输出
点击展开 输入预处理
- 图像
- [Im1] input/output: 1x3x128x128
- 输入预处理 Sp
- [Im1]input: 1x3x128x128
- [Sp1]output: 1x128x128x128
收缩阶段
- 收缩阶段用Sd前缀表示,数字序号表示不同阶段的输入或输出
点击展开 收缩阶段
- 收缩阶段 Sd
-
DownBlock2D
- resnet
- [Sp1] input: 1x128x128x128
- [Sd1] output: 1x128x128x128
- resnet
- [Sd1] input: 1x128x128x128
- [Sd2] output: 1x128x128x128
- downsampler
- [Sd2] input: 1x128x128x128
- [Sd3] output: 1x128x64x64
- resnet
-
DownBlock2D
- resnet
- [Sd3] input: 1x128x64x64
- [Sd4] output: 1x128x64x64
- resnet
- [Sd4] input: 1x128x64x64
- [Sd5] output: 1x128x64x64
- downsampler
- [Sd5] input: 1x128x64x64
- [Sd6] output: 1x128x32x32
- resnet
-
DownBlock2D
- resnet
- [Sd6] input: 1x128x32x32
- [Sd7] output: 1x256x32x32
- resnet
- [Sd7] input: 1x256x32x32
- [Sd8] output: 1x256x32x32
- downsampler
- [Sd8] input: 1x256x32x32
- [Sd9] output: 1x256x16x16
- resnet
-
DownBlock2D
- resnet
- [Sd9] input: 1x256x16x16
- [Sd10] output: 1x256x16x16
- resnet
- [Sd10] input: 1x256x16x16
- [Sd11] output: 1x256x16x16
- downsampler
- [Sd11] input: 1x256x16x16
- [Sd12] output: 1x256x8x8
- resnet
-
AttnDownBlock2D
- resnet+atten
- [Sd12] input: 1x256x8x8
- [Sd13] output: 1x512x8x8
- resnet+atten
- [Sd13] input: 1x512x8x8
- [Sd14] output: 1x512x8x8
- downsampler
- [Sd14] input: 1x512x8x8
- [Sd15] output: 1x512x4x4
- resnet+atten
-
DownBlock2D
- resnet
- [Sd15] input: 1x512x4x4
- [Sd16] output: 1x512x4x4
- resnet
- [Sd16] input: 1x512x4x4
- [Sd17] output: 1x512x4x4
- resnet
-
中间阶段
- 收缩阶段用Sm前缀表示,数字序号表示不同阶段的输入或输出
点击展开 中间阶段
- UNetMiddle2D
- [Sd17] input: 1x512x4x4
- [Sm1] output: 1x512x4x4
扩张阶段
- 扩张阶段用Se前缀表示,数字序号表示不同阶段的输入或输出
点击展开 扩张阶段
-
扩张阶段 Se
-
UpBlock2D
- resnet
- [Sm1] input: 1x512x4x4
- [Sd17] input: 1x512x4x4
- [Se1] output: 1x512x4x4
- resnet
- [Se1] input: 1x512x4x4
- [Sd16] input: 1x512x4x4
- [Se2] input: 1x512x4x4
- resnet
- [Se2] input: 1x512x4x4
- [Sd15] input: 1x512x4x4
- [Se3] output: 1x512x4x4
- upsample
- [Se3] input: 1x512x4x4
- [Se4] output: 1x512x8x8
- resnet
-
AttnUpBlock2D
- resnet+atten
- [Se4] input: 1x512x8x8
- [Sd14] input: 1x512x8x8
- [Se5] output: 1x512x8x8
- resnet+atten
- [Se5] input: 1x512x8x8
- [Sd13] input: 1x512x8x8
- [Se6] input: 1x512x8x8
- resnet+atten
- [Se6] input: 1x512x8x8
- [Sd12] input: 1x256x8x8
- [Se7] output: 1x512x8x8
- upsample+atten
- [Se7] input: 1x512x8x8
- [Se8] output: 1x512x16x16
- resnet+atten
-
UpBlock2D
- resnet
- [Se8] input: 1x512x16x16
- [Sd11] input: 1x256x16x16
- [Se9] output: 1x256x16x16
- resnet
- [Se9] input: 1x256x16x16
- [Sd10] input: 1x256x16x16
- [Se10] input: 1x256x16x16
- resnet
- [Se10] input: 1x256x16x16
- [Sd9] input: 1x256x16x16
- [Se11] output: 1x256x16x16
- upsample
- [Se11] input: 1x256x16x16
- [Se12] output: 1x256x32x32
- resnet
-
UpBlock2D
- resnet
- [Se12] input: 1x256x32x32
- [Sd8] input: 1x256x32x32
- [Se13] output: 1x256x32x32
- resnet
- [Se13] input: 1x256x32x32
- [Sd7] input: 1x256x32x32
- [Se14] input: 1x256x32x32
- resnet
- [Se14] input: 1x256x32x32
- [Sd6] input: 1x128x32x32
- [Se15] output: 1x256x32x32
- upsample
- [Se15] input: 1x256x32x32
- [Se16] output: 1x256x64x64
- resnet
-
UpBlock2D
- resnet
- [Se16] input: 1x256x64x64
- [Sd5] input: 1x128x64x64
- [Se17] output: 1x128x64x64
- resnet
- [Se17] input: 1x128x64x64
- [Sd4] input: 1x128x64x64
- [Se18] input: 1x128x64x64
- resnet
- [Se18] input: 1x128x64x64
- [Sd3] input: 1x128x64x64
- [Se19] output: 1x128x64x64
- upsample
- [Se19] input: 1x128x64x64
- [Se20] output: 1x128x128x128
- resnet
-
UpBlock2D
- resnet
- [Se20] input: 1x128x128x128
- [Sd2] input: 1x128x128x128
- [Se21] output: 1x128x128x128
- resnet
- [Se21] input: 1x128x128x128
- [Sd1] input: 1x128x128x128
- [Se22] input: 1x128x128x128
- resnet
- [Se22] input: 1x128x128x128
- [Sp1] input: 1x128x128x128
- [Se23] output: 1x128x128x128
- resnet
-
输出后处理
- 预处理阶段用So前缀表示,数字序号表示不同阶段的输入或输出
点击展开 输出后处理
- 输出后处理 So
- [Se23]input: 1x128x128x128
- [So1]output: 1x3x128x128
图表展示UNet2DModel网络结构
UNet2DModel 各个模块介绍
UNet2DModel 收缩模块
DownBlock2D
- ResnetBlock2D:r 个
- Downsample2D: 0/1 个
r个ResnetBlock2D,之后跟着Downsample,Downsample根据情况有或者没有,有则尺寸减小,没有则尺寸保持不变,
点击展开 DownBlock2D
class DownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
output_scale_factor=1.0,
add_downsample=True,
downsample_padding=1,
):
super().__init__()
resnets = []
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
else:
self.downsamplers = None
self.gradient_checkpointing = False
def forward(self, hidden_states, temb=None):
output_states = ()
for resnet in self.resnets:
if self.training and self.gradient_checkpointing:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
if is_torch_version(">=", "1.11.0"):
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb, use_reentrant=False
)
else:
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb
)
else:
hidden_states = resnet(hidden_states, temb)
output_states = output_states + (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
AttnDownBlock2D
- ResnetBlock2D:r 个
- Attention: r 个
- Downsample2D: 0/1 个
每个ResnetBlock2D 之后跟着 Attention;最后跟着Downsample,Downsample根据情况有或者没有,有则尺寸减小,没有则尺寸保持不变,
点击展开 AttnDownBlock2D
class AttnDownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim=1,
output_scale_factor=1.0,
downsample_padding=1,
downsample_type="conv",
):
super().__init__()
resnets = []
attentions = []
self.downsample_type = downsample_type
if attention_head_dim is None:
logger.warn(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {out_channels}."
)
attention_head_dim = out_channels
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
attentions.append(
Attention(
out_channels,
heads=out_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=resnet_groups,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if downsample_type == "conv":
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
elif downsample_type == "resnet":
self.downsamplers = nn.ModuleList(
[
ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
down=True,
)
]
)
else:
self.downsamplers = None
def forward(self, hidden_states, temb=None, upsample_size=None):
output_states = ()
for resnet, attn in zip(self.resnets, self.attentions):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(hidden_states)
output_states = output_states + (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
if self.downsample_type == "resnet":
hidden_states = downsampler(hidden_states, temb=temb)
else:
hidden_states = downsampler(hidden_states)
output_states += (hidden_states,)
return hidden_states, output_states
UNet2DModel 中间模块
- ResnetBlock2D: 1个
- Attention: r个
- ResnetBlock2D: r个
第1个resnetBlock2D之后,每个Attention后面跟着1个ResnetBlock2D
点击展开 UNetMideBlock2D
class UNetMidBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default", # default, spatial
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
add_attention: bool = True,
attention_head_dim=1,
output_scale_factor=1.0,
):
super().__init__()
resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
self.add_attention = add_attention
# there is always at least one resnet
resnets = [
ResnetBlock2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
]
attentions = []
if attention_head_dim is None:
logger.warn(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {in_channels}."
)
attention_head_dim = in_channels
for _ in range(num_layers):
if self.add_attention:
attentions.append(
Attention(
in_channels,
heads=in_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=resnet_groups if resnet_time_scale_shift == "default" else None,
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
else:
attentions.append(None)
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
def forward(self, hidden_states, temb=None):
hidden_states = self.resnets[0](hidden_states, temb)
for attn, resnet in zip(self.attentions, self.resnets[1:]):
if attn is not None:
hidden_states = attn(hidden_states, temb=temb)
hidden_states = resnet(hidden_states, temb)
return hidden_states
UNet2DModel 扩张模块
Up2DBlock
- 组成
- ResnetBlock2D: r个
- Upsample: 0/1
- 输入
- 上一层输出
- 对应收缩阶段的输出
r个ResnetBlock2D,之后跟着Upsample,Upsample根据情况有或者没有,有则尺寸增加,没有则尺寸保持不变,
点击展开 Up2DBlock
class UpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
prev_output_channel: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
output_scale_factor=1.0,
add_upsample=True,
):
super().__init__()
resnets = []
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.resnets = nn.ModuleList(resnets)
if add_upsample:
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
else:
self.upsamplers = None
self.gradient_checkpointing = False
def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None):
for resnet in self.resnets:
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
if self.training and self.gradient_checkpointing:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
if is_torch_version(">=", "1.11.0"):
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb, use_reentrant=False
)
else:
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb
)
else:
hidden_states = resnet(hidden_states, temb)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
AttnUp2DBlock
- 组成
- ResnetBlock2D: r个
- Upsample: 0/1
- 输入
- 上一层输出
- 对应收缩阶段的输出
每个ResnetBlock2D 之后跟着 Attention;最后跟着Upsample,Upsample根据情况有或者没有,有则尺寸增加,没有则尺寸保持不变,
点击展开 AttnUp2DBlock
class AttnUpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
prev_output_channel: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim=1,
output_scale_factor=1.0,
upsample_type="conv",
):
super().__init__()
resnets = []
attentions = []
self.upsample_type = upsample_type
if attention_head_dim is None:
logger.warn(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {out_channels}."
)
attention_head_dim = out_channels
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
attentions.append(
Attention(
out_channels,
heads=out_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=resnet_groups,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if upsample_type == "conv":
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
elif upsample_type == "resnet":
self.upsamplers = nn.ModuleList(
[
ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
up=True,
)
]
)
else:
self.upsamplers = None
def forward(self, hidden_states, res_hidden_states_tuple, temb=None, upsample_size=None):
for resnet, attn in zip(self.resnets, self.attentions):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(hidden_states)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
if self.upsample_type == "resnet":
hidden_states = upsampler(hidden_states, temb=temb)
else:
hidden_states = upsampler(hidden_states)
return hidden_states
UNet2DModel 基础模块
ResnetBlock2D
-
组成
- 归一化层:对时间步特征 time_embedding 进行归一化 norm1()/norm2()
- 卷积层
- 激活层
- dropout层
-
输入
- 中间特征
- 时间步特征
-
过程
- 对中间特征进行归一化 norm1()
- 过激活函数 nonlinearity()
- 上采样/下采样 (可选)
- 对中间特征进行卷积操作 conv1()
- 时间特征归一化及投影处理(可配置)
- 依据时间步特征归一化方式,对中间特征进行差异化处理(可配置)
- 过激活函数 nonlinearity()
- 过dropout dropout()
- 对中间特征进行卷积操作 conv2()
代办项:
- 时间步特征的不同归一化方式,不同提取特征方式,不同编码方式
点击展开 ResnetBlock2D
class ResnetBlock2D(nn.Module):
r"""
A Resnet block.
Parameters:
in_channels (`int`): The number of channels in the input.
out_channels (`int`, *optional*, default to be `None`):
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
groups (`int`, *optional*, default to `32`): The number of groups to use for the first normalization layer.
groups_out (`int`, *optional*, default to None):
The number of groups to use for the second normalization layer. if set to None, same as `groups`.
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
non_linearity (`str`, *optional*, default to `"swish"`): the activation function to use.
time_embedding_norm (`str`, *optional*, default to `"default"` ): Time scale shift config.
By default, apply timestep embedding conditioning with a simple shift mechanism. Choose "scale_shift" or
"ada_group" for a stronger conditioning with scale and shift.
kernel (`torch.FloatTensor`, optional, default to None): FIR filter, see
[`~models.resnet.FirUpsample2D`] and [`~models.resnet.FirDownsample2D`].
output_scale_factor (`float`, *optional*, default to be `1.0`): the scale factor to use for the output.
use_in_shortcut (`bool`, *optional*, default to `True`):
If `True`, add a 1x1 nn.conv2d layer for skip-connection.
up (`bool`, *optional*, default to `False`): If `True`, add an upsample layer.
down (`bool`, *optional*, default to `False`): If `True`, add a downsample layer.
conv_shortcut_bias (`bool`, *optional*, default to `True`): If `True`, adds a learnable bias to the
`conv_shortcut` output.
conv_2d_out_channels (`int`, *optional*, default to `None`): the number of channels in the output.
If None, same as `out_channels`.
"""
def __init__(
self,
*,
in_channels,
out_channels=None,
conv_shortcut=False,
dropout=0.0,
temb_channels=512,
groups=32,
groups_out=None,
pre_norm=True,
eps=1e-6,
non_linearity="swish",
skip_time_act=False,
time_embedding_norm="default", # default, scale_shift, ada_group, spatial
kernel=None,
output_scale_factor=1.0,
use_in_shortcut=None,
up=False,
down=False,
conv_shortcut_bias: bool = True,
conv_2d_out_channels: Optional[int] = None,
):
super().__init__()
self.pre_norm = pre_norm
self.pre_norm = True
self.in_channels = in_channels
out_channels = in_channels if out_channels is None else out_channels
self.out_channels = out_channels
self.use_conv_shortcut = conv_shortcut
self.up = up
self.down = down
self.output_scale_factor = output_scale_factor
self.time_embedding_norm = time_embedding_norm
self.skip_time_act = skip_time_act
if groups_out is None:
groups_out = groups
if self.time_embedding_norm == "ada_group":
self.norm1 = AdaGroupNorm(temb_channels, in_channels, groups, eps=eps)
elif self.time_embedding_norm == "spatial":
self.norm1 = SpatialNorm(in_channels, temb_channels)
else:
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
if temb_channels is not None:
if self.time_embedding_norm == "default":
self.time_emb_proj = torch.nn.Linear(temb_channels, out_channels)
elif self.time_embedding_norm == "scale_shift":
self.time_emb_proj = torch.nn.Linear(temb_channels, 2 * out_channels)
elif self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
self.time_emb_proj = None
else:
raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
else:
self.time_emb_proj = None
if self.time_embedding_norm == "ada_group":
self.norm2 = AdaGroupNorm(temb_channels, out_channels, groups_out, eps=eps)
elif self.time_embedding_norm == "spatial":
self.norm2 = SpatialNorm(out_channels, temb_channels)
else:
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
self.dropout = torch.nn.Dropout(dropout)
conv_2d_out_channels = conv_2d_out_channels or out_channels
self.conv2 = torch.nn.Conv2d(out_channels, conv_2d_out_channels, kernel_size=3, stride=1, padding=1)
self.nonlinearity = get_activation(non_linearity)
self.upsample = self.downsample = None
if self.up:
if kernel == "fir":
fir_kernel = (1, 3, 3, 1)
self.upsample = lambda x: upsample_2d(x, kernel=fir_kernel)
elif kernel == "sde_vp":
self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
else:
self.upsample = Upsample2D(in_channels, use_conv=False)
elif self.down:
if kernel == "fir":
fir_kernel = (1, 3, 3, 1)
self.downsample = lambda x: downsample_2d(x, kernel=fir_kernel)
elif kernel == "sde_vp":
self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
else:
self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
self.use_in_shortcut = self.in_channels != conv_2d_out_channels if use_in_shortcut is None else use_in_shortcut
self.conv_shortcut = None
if self.use_in_shortcut:
self.conv_shortcut = torch.nn.Conv2d(
in_channels, conv_2d_out_channels, kernel_size=1, stride=1, padding=0, bias=conv_shortcut_bias
)
def forward(self, input_tensor, temb):
hidden_states = input_tensor
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
hidden_states = self.norm1(hidden_states, temb)
else:
hidden_states = self.norm1(hidden_states)
hidden_states = self.nonlinearity(hidden_states)
if self.upsample is not None:
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
if hidden_states.shape[0] >= 64:
input_tensor = input_tensor.contiguous()
hidden_states = hidden_states.contiguous()
input_tensor = self.upsample(input_tensor)
hidden_states = self.upsample(hidden_states)
elif self.downsample is not None:
input_tensor = self.downsample(input_tensor)
hidden_states = self.downsample(hidden_states)
hidden_states = self.conv1(hidden_states)
if self.time_emb_proj is not None:
if not self.skip_time_act:
temb = self.nonlinearity(temb)
temb = self.time_emb_proj(temb)[:, :, None, None]
if temb is not None and self.time_embedding_norm == "default":
hidden_states = hidden_states + temb
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
hidden_states = self.norm2(hidden_states, temb)
else:
hidden_states = self.norm2(hidden_states)
if temb is not None and self.time_embedding_norm == "scale_shift":
scale, shift = torch.chunk(temb, 2, dim=1)
hidden_states = hidden_states * (1 + scale) + shift
hidden_states = self.nonlinearity(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.conv2(hidden_states)
if self.conv_shortcut is not None:
input_tensor = self.conv_shortcut(input_tensor)
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
return output_tensor

 浙公网安备 33010602011771号
浙公网安备 33010602011771号