
VIT论文笔记
VIT
An image is worth 16x16 words: transformers for image recognition at scale 将transformer首次应用在视觉任务中,并取得了超过CNN方法的性能。
标准的transformer接收一维的向量序列如 \((x_1, x_2, ..., x_N), x_i \in R^{D}\)。为了处理2D图像,将图像 \(X\in R^{H \times W \times C}\) 拆分成若干个小patch \({\bf x}_p \in R^{P \times P \times C}\),并将patch展平 \({\bf x}_p \in R^{P^2 C}\),其中patch的数量 \(N=HW/P^2\)。裁剪展平的图像块patch的维度是 \(P^2C\),一般经过线性投影变换将其映射为统一的维度D,参考公式1
类似于BERT的 class token,本文将一个可学习的embedding放置在表示过的图像块特征序列的首位(\({\bf z}_0^0 ={\bf z}_{cls}\)),这样有N+1 个Embedding token,经过transformer编码后得到的首位特征(\({\bf z}_L^0\)) 作为图像特征
为了将图像拆分序列后仍保留图像块间的位置信息,在图像块patch embedding基础上添加可以训练的位置特征,本文采用可学习的1维位置表示position embedding。因为对比了其它2D 位置表示没有达到更好的性能,故而就采用了1D 位置表示方式。
transformer编码包含了多头自注意MSA模块, MLP模块,归一化LN模块,每个模块后都有residual连接。公式表达上述过程如下:
\({\bf z}_0=[{\bf z}_{cls}; {\bf x}_p^1 \bf E; ...; {\bf x}_p^N \bf E]+{\bf E}_{pos}\), \({\bf E} \in R^{(P^2C) \times D},{\bf E}_{pos} \in R^{(N+1) \times D}\)
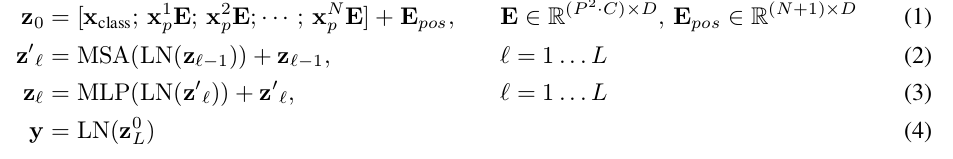
Token Labeling
常规图像分类任务是,经过backbone表示为一个向量\(x\in R^d\),再通过一个分类器得到在各个类别上的概率值,取概率值最大的类别作为该图片预测的类别。往往上述backbone若干layers,通常是将中间的feature map \(x\in R^{h \times w \times d}\) 经过某种池化得到最终的一维向量。而Token Label则是对池化前的feature map预测每个空间特征点的类别信息,而预测用的分类器仍使用原分类器。这种得到池化前的特征图各个空间点对应特征图片级语义类别的方法,叫做Token Labeling。
以ImageNet训练为例,除了图片本身的类别信息外;使用预训练的模型可以预测ImageNet数据池化前的特征图的各个空间点特征的语义类别,可以辅助训练分类任务(图片中目标物可能未占据整张图片,而池化前的特征图空间点特征也对应一个图片中局部区域)
上述表述是按照CNN思路,对于Transformer亦是如此,基于Transformer也是将图像拆分为若干的patch再生成Token。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号