CLIP 读书笔记
论文:Learning Transferable Visual Models From Natural Language Supervision
CLIP: Contrastive Language-Image Pre-training
文中27个数据集简介:
| 数据集 | 简要描述 | 数据集类型 |
|---|---|---|
| StanfordCars | 196类小汽车, 16185张图片 | 细粒度分类 |
| Country211 | 211个国家的带有GPS信息的图片,以评估视觉预测地理定位能力 | ? |
| Food101 | 101种食物,101k张图片 | 细粒度分类 |
| Kinetics700 | 700种人类动作,每个动作700个视频片段 | 细粒度分类 |
| SST2 | 文本情感分析数据集 | ? |
| SUN397 | 场景理解数据集,899个场景130k张图片 | 粗分类 |
| UCF101 | 101种人类行为动作数据集 | 细粒度分类 |
| HatefulMemes | 可引起仇恨多模态图文对数据集 | ? |
| CIFAR10 | 10种类别数据集 | 粗分类 |
| CIFAR100 | 100中类别数据集 | 粗分类 |
| STL10 | 类似cifar数据集,每个类别有大量无标注图片 | 粗分类 |
| FER2013 | 7分类表情数据集 | 细粒度分类 |
| Caltech101 | 101种类别数据集 | 粗分类 |
| ImageNet | 1000种类别数据集 | 粗分类 |
| OxfordPets | 猫狗数据集 | 细粒度 |
| PascalVOC2007 | 物体检测数据集 | 粗分类 |
| Birdsnap | 500种鸟类数据集49k张图片 | 细粒度 |
| MNIST | 10个数字分类 | 粗分类 |
| FGVCAircraft | 102种飞机数据集,每一类100张图片 | 细粒度 |
| RESISC45 | 45种遥感场景图片数据集 | 粗分类 |
| Flower102 | 102种花朵数据集,每种40-258张 | 细粒度 |
| DTD | 纹理数据集 | 粗分类 |
| CLEVRCounts | 合成的视觉问答数据集 | 粗分类 |
| GTSRB | 德国交通信号灯分类数据集 | 粗分类 |
| PatchCamelyon | 淋巴切片组织病理学扫描 | 粗分类 |
| KITTI Distance | 移动机器人和自动驾驶距离预测 | 回归 |
| EuroSAT | 遥感卫星图片10种类别 | 粗分类 |
论文针对27个数据集,关于零样本CLIP与全监督ResNet50基准模型进行对比。参考下图
(1)在细粒度分类数据集上,在有的数据集如StandfordCars和Food101上明显由于基准ResNet50 20个百分点;而在有些数据集上如Flowers102和FGVCAircraft上则明显低于基准10个百分点。论文猜测是由于不同监督任务的数据量有很大区别,但是结合上面粗略统计这4个细粒度数据集,类别的数量和每个类别下图片的数量都没有太大区别。
(2)Kinetic700和UCF101是人类动作分类数据集,零样本学习CLIP方法比基准方法高 10百分点上下。论文解释自然语言为涉及动词的视觉概念提供了更广泛的监督,而单纯的视觉监督任务主要以名称为主。
(3)零样本学习CLIP方法在更专业的复杂的抽象的任务上如遥感图像分类如EuroSAT和RESISC45,淋巴结肿瘤检测如PatchCamelyon,合成场景物体计数CLEVRCounts,自动驾驶相关的交通信号识别GTSRB,最近汽车距离识别KITTI Distance这些任务上,该方法表现比基准方法差很多。但是非专业人员在如卫星图片分类、计数、交通信号灯识别变现很稳健,说明零样本学习CLIP方法还有很大的改进空间。但是对于一些专业性很强的任务中,如淋巴结肿瘤辨别,即使是非专业人员也很难识别。零样本学习方法相比小样本学习方式,哪个更合适还有待进一步讨论。
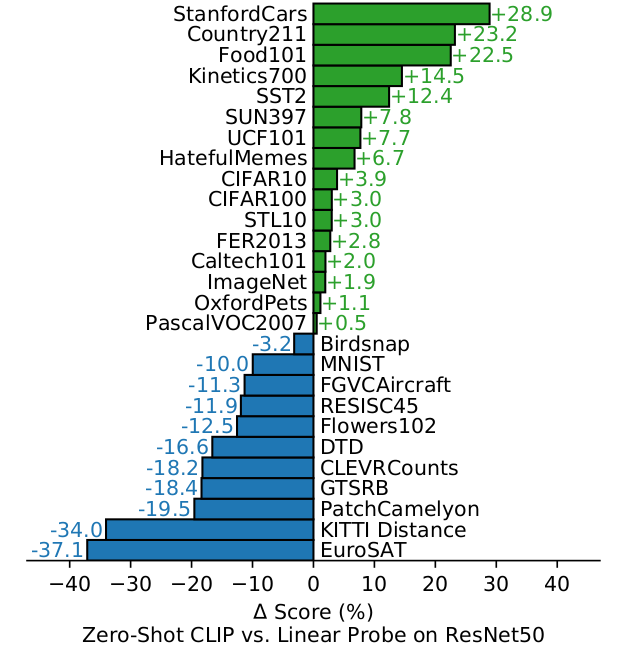
Fig. 1
Zero-CLIP方法与few-shot方法对比
直觉认为Zero-shot方法会比few-shot方法性能差,实际表现是Zero-CLIP方法相当于基于相同特征空间 4-shot 线性分类方法。之所以如此,是由于这两种方法的区别。基于CLIP 的Zero-shot分类器,具备自然语言和视觉区分能力,还学习到了语言域和视觉域之间的关联。而常规的监督学习方法,并不能直接从训练样本中学习到概念(分类任务都会把类别标签都转换为0,1,2,……这些数字),另外图片中,经常包含多个不同视觉主体,而标签仅仅给出的其中的一个。
Linear probe CLIP:指基于CLIP特征,进行分类器单独训练。基于上述分析,Linear Probe CLIP 在开始1-shot,2-shot时还不如 Zero-Shot CLIP,单独训练分类器反而更差了。当每个类别变多时,效果才逐渐超过Zero-shot CLIP方法。在20个数据集上验证了,Zero-CLIP方法相当于基于相同特征空间 4-shot 线性分类方法。而基于其它Backbone提取的特征进行16-shot 分类,都不如Zero-Shot CLIP 方法。而16-shot CLIP 比16-shot 其它backbone方法高出10个百分点。
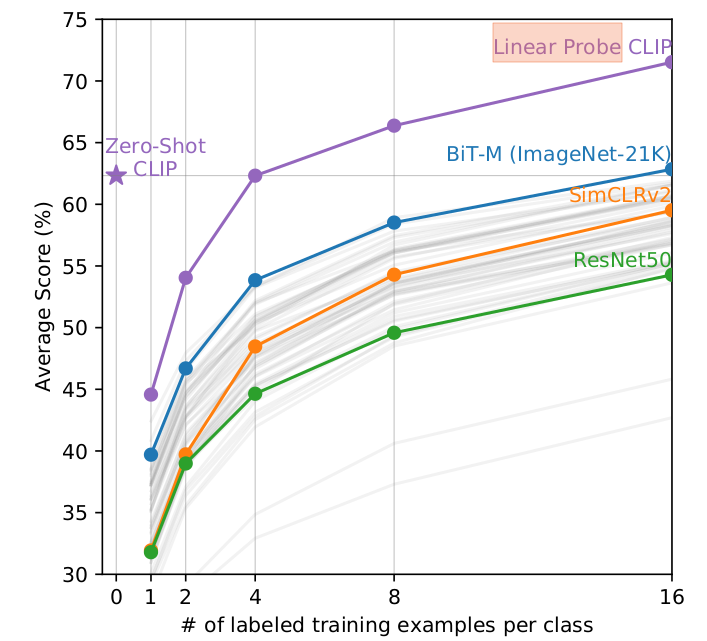
Fig. 2
Fig1是 Zero-CLIP方法与ResNet50监督方法进行对比,而Fig3是Zero-CLIP方法与基于CLIP特征空间的few-shot性能对比,这个对比是要求few-shot达到Zero-CLIP方法一样性能下数据集每个类别所需要的最少数量。Fig2表明基于CLIP特征的few-shot 并未都超过了Zero-CLIP,只有few-shot的每个类别数量超过一定数量如4-shot,才超过Zero-CLIP。
从Fig.3看出,达到Zero-CLIP的性能,在不同数据集上,基于CLIP特征训练分类器,不同数据集每个类别样本数量是不相同,从不到1个到最大的要求184个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号