大规模人脸分类—allgather操作(2)
腾讯开源人脸识别训练代码TFace 中关于all_gather层的实现如下。接下来解释为什么backward要进行reduce相加操作。
https://github.com/Tencent/TFace
class AllGatherFunc(Function):
""" AllGather op with gradient backword
"""
@staticmethod
def forward(ctx, tensor, *gather_list):
gather_list = list(gather_list)
dist.all_gather(gather_list, tensor)
return tuple(gather_list)
@staticmethod
def backward(ctx, *grads):
grad_list = list(grads)
rank = dist.get_rank()
grad_out = grad_list[rank]
dist_ops = [
dist.reduce(grad_out, rank, ReduceOp.SUM, async_op=True) if i == rank else
dist.reduce(grad_list[i], i, ReduceOp.SUM, async_op=True) for i in range(dist.get_world_size())
]
for _op in dist_ops:
_op.wait()
grad_out *= len(grad_list) # cooperate with distributed loss function
return (grad_out, *[None for _ in range(len(grad_list))])
AllGather = AllGatherFunc.apply
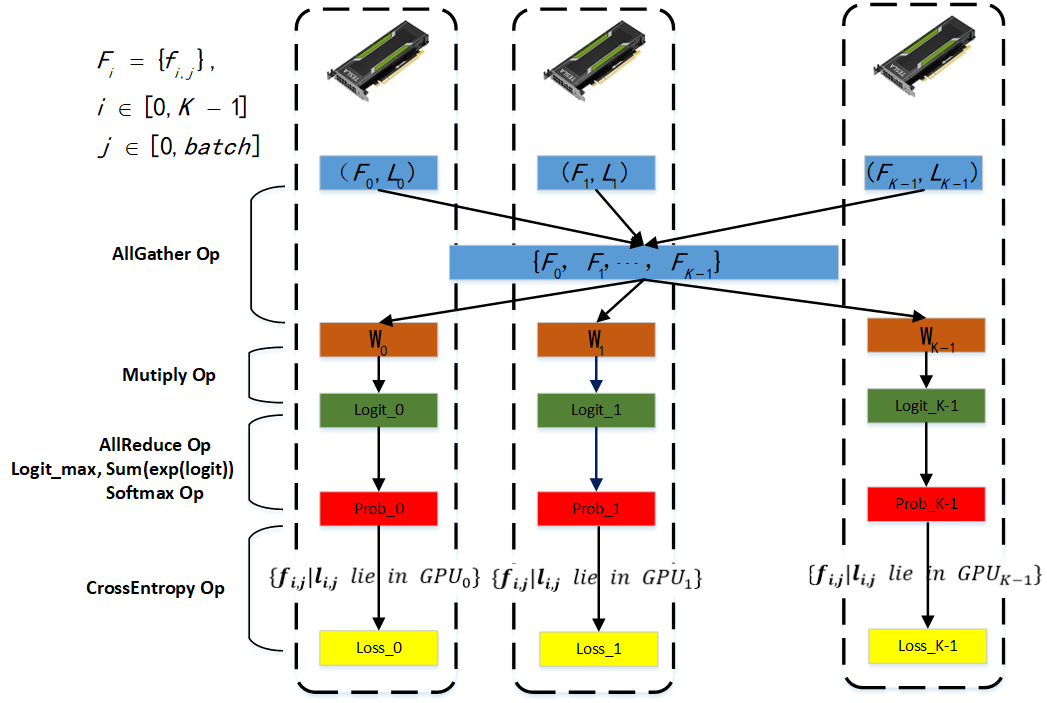
下面用示意图来描述大规模人脸分类的过程,如下图。
结合下面示意图和公式表达来理解。
B: batch size, d: feature dimension, K: gpu number, C: class number, \(c_j\): class number of j-th gpu
(1)\(F_j \in R^{B*d}\): 第j块GPU上特征
(2)\(F_{total} = torch.cat((F_0, F_1, ^, F_{K-1} )) \in R^{KB*d}\): 表示所有的K个GPU上特征合并在一起
(3)\(W_j \in R^{d*c_j}\):第j块GPU上的分类权重
(4)\(logit_j=F_{total}W_j \in R^{KB*c_j}\): 这里简化分类层为常规线性变换。(下面的公式中\(y_j\)就表示\(logit_j\))
\(\frac {\partial L_j}{\partial F_{total}} = \frac{\partial L_j}{\partial y_j}* \frac{\partial y_j}{\partial F_{total}}=\frac{\partial L_j}{\partial y_j}*W_j^T\),(\(R^{KB*c_j}*R^{c_j*d}=R^{KB*d}\),数据维度是可以对应上的)。
可以看出每块GPU上产生的对全体特征向量的梯度维度都是一样(这个是肯定的),每块GPU上产生梯度是通过上述链式法则得到的,得到梯度的公式中,分两个部分相乘,一个是对logit值的导数,一个是当前卡上局部分类权重W的导数。对于每块卡而言这两部分都不一样。也就是每块gpu都对全体特征向量\(F_{total}\)都产生梯度。总的loss是各个GPU上loss先求和再归约,因此在求对logit梯度时,也除以了总的样本数量(KB),然后对全体特征向量\(F_{total}\)在allgather层要进行相加。\(\frac{\partial L}{\partial F_{total}}=\frac{1}{KB}\sum _{j=0}^{j=K-1}\frac {\partial L_j}{\partial F_{total}} =\frac{1}{KB}\sum _{j=0}^{j=K-1}\frac{\partial L_j}{\partial y_j}*W_j^T=\sum _{j=0}^{j=K-1}\frac{1}{KB}\frac{\partial L_j}{\partial y_j}*W_j^T\)。
可是不明白上述代码为什么要乘以GPU的数量,对应代码为:grad_out *= len(grad_list) 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号