
人脸大规模分类—plsc
下面主要注释了百度开源人脸大规模分类训练PLSC代码细节
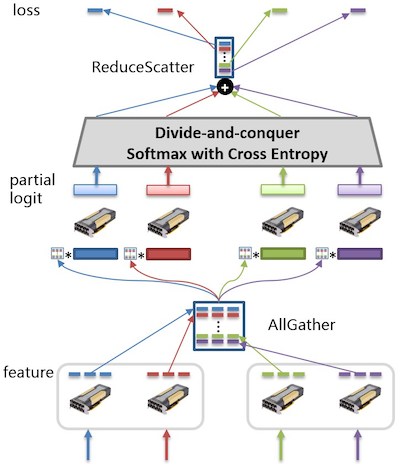
(1)下面代码softmax_with_cross_entropy之前部分主要是使用allgather将每个gpu上计算的特征聚合在一起,每块gpu上都存放了相同的全体特征。
def softmax_classify(self,
x,
label,
param_attr=None,
use_bias=True,
bias_attr=None):
flatten_dim = reduce(lambda a, b: a * b, x.shape[1:], 1)
weight, bias = self.create_parameter(
dtype=x.dtype,
in_dim=flatten_dim,
param_attr=param_attr,
bias_attr=bias_attr,
use_bias=use_bias)
x_all = collective._c_allgather(
x, nranks=self.nranks, use_calc_stream=True)
label_all = collective._c_allgather(
label, nranks=self.nranks, use_calc_stream=True)
label_all.stop_gradient = True
shard_fc = nn.mul(x_all, weight, x_num_col_dims=1)
if use_bias:
shard_fc = nn.elementwise_add(shard_fc, bias)
shard_label = nn.shard_index(
label_all,
index_num=self.nclasses,
nshards=self.nranks,
shard_id=self.rank_id,
ignore_value=-1)
shard_label.stop_gradient = True
global_loss, shard_prob = self.softmax_with_cross_entropy(shard_fc,
shard_label)
avg_loss = nn.mean(global_loss)
avg_loss._set_info('shard_logit', shard_fc)
avg_loss._set_info('shard_prob', shard_prob)
avg_loss._set_info('shard_label', shard_label)
avg_loss._set_info('shard_dim', self.shard_dim)
return avg_loss
(2) shard_logit, shard_one_hot表示当前gpu上的logit和label值,下面第1行代码表示,求当前gpu上最大logit值,第3行代码是使用MPI中all_reduce操作,从各个进程中获取数据经过max函数就得到,再取communicator中所有进程上这个max值的最大值(可以这么理解)
shard_max = paddle.max(shard_logit, axis=1, keepdim=True)
global_max = shard_max
paddle.distributed.all_reduce(
global_max, op=paddle.distributed.ReduceOp.MAX)
(3)实际计算过程中,是每个logit值都要减去最大的logit值,然后再求exp,否则很容易出现溢出。
shard_logit_new = paddle.subtract(shard_logit, global_max)
shard_exp = paddle.exp(shard_logit_new)
(4)下面是求指数和,由于涉及多个进程,所有先求每个进程/gpu上的和,然后使用MPI中all_reduce操作再求全局和,最后广播给所有进程。
shard_demon = paddle.sum(shard_exp, axis=1, keepdim=True)
global_demon = shard_demon
paddle.distributed.all_reduce(
global_demon, op=paddle.distributed.ReduceOp.SUM)
(5)下面三行代码采用了小技巧来求分类层各个类别下的概率值
\(p_k = \frac{e^{x_k-x_{m}}}{\sum{e^{x_j-x_m}}},其中 x_k表示某个logit值,x_m表示最大的logit值,分母下面就是指数值求和。\)
\(两边取log,logp_k = x_k-x_m - log(\sum{e^{x_j-x_m}})\),这就是下面头两行代码的含义。
global_log_demon = paddle.log(global_demon)
shard_log_prob = shard_logit_new - global_log_demon
shard_prob = paddle.exp(shard_log_prob)
(6)shard_log_prob 都是负值, shard_one_hot中只有目标类别位置为1, 其它都是0,相乘只有一个负值。因此取min值就得到对目标类别概率对数值。乘以-1就是交叉熵损失值。
target_log_prob = paddle.min(shard_log_prob * shard_one_hot,
axis=1,
keepdim=True)
shard_loss = paddle.scale(target_log_prob, scale=-1.0)
为了解释下面两行代码,需要再捋一下大规模分类的拆分逻辑。
(1)将num_classes类别均匀分成N份(N块gpu,假设可以均分),那么gpu0 存放[0,num_classes/N],gpu1存放[num_classes/N+1, 2num_classes/N],以此类推
(2)比如gpu0某次迭代,很有可能加载到 图片的类别不在[0, num_classes/N]范围内,但是这些图片在[0, num_classes/N]这些类别的概率计算不受影响。即每块gpu仅计算加载的图片在此卡上部分的分类类别上的概率值,而先不管这些图片真实类别权重是否存储在这个gpu上。
(3)当前gpu0上计算,针对某个图片类别标签值不在gpu0存储范围内的,就无法计算出这个图片的交叉熵值,但是使用reduce操作就可以获得这张图片的交叉熵值。
(4)plsc中将所有gpu上的特征表示聚合在一起,然后在每个gpu上进行局部计算,涉及要用到全局值,就使用MPI中op获取。如上述计算图片损失值时,图片的真实类别概率值不存储在计算当前gpu上。reduce将完成这种计算,然后scatter将损失值分拆到不同gpu上。
shard_loss = paddle.scale(target_log_prob, scale=-1.0)
global_loss = paddle.fluid.layers.collective._c_reducescatter(
shard_loss, nranks=self.nranks, use_calc_stream=True)
完整计算softmax 交叉熵代码:
def softmax_with_cross_entropy(self, shard_logit, shard_one_hot):
shard_max = paddle.max(shard_logit, axis=1, keepdim=True)
global_max = shard_max
paddle.distributed.all_reduce(
global_max, op=paddle.distributed.ReduceOp.MAX)
shard_logit_new = paddle.subtract(shard_logit, global_max)
shard_exp = paddle.exp(shard_logit_new)
shard_demon = paddle.sum(shard_exp, axis=1, keepdim=True)
global_demon = shard_demon
paddle.distributed.all_reduce(
global_demon, op=paddle.distributed.ReduceOp.SUM)
global_log_demon = paddle.log(global_demon)
shard_log_prob = shard_logit_new - global_log_demon
shard_prob = paddle.exp(shard_log_prob)
target_log_prob = paddle.min(shard_log_prob * shard_one_hot,
axis=1,
keepdim=True)
shard_loss = paddle.scale(target_log_prob, scale=-1.0)
#TODO paddle.distributed.reducescatter not found
global_loss = paddle.fluid.layers.collective._c_reducescatter(
shard_loss, nranks=self.nranks, use_calc_stream=True)
return global_loss, shard_prob
下图展示了整个前向计算过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号