
分布式训练——Ring-AllReduce
在早期tensorflow框架进行多机多卡分布式训练采用的Parameter Server方式进行梯度的同步,但是这种方式随着GPU卡数的增加,通信效率问题凸显出来。后来百度硅谷提出在《Bring HPC techniques to Deep Learning》中提出Ring-AllReduce 技术使得分布式训练过程中通信时间是一个常量与GPU卡数的数量没有关系,从而极大地提升大规模训练的速度。
在开始介绍该技术前,先梳理一下MPI技术中常见的名词。下面博客使用图表简要的表达了不同名词的含义。
https://blog.csdn.net/aiwanghuan5017/article/details/102147821
Broadcast:是将同一数据广播分发到所有的进程;
Scatter:是将不同的数据分发到不同的进程中;
前者是所有进程共享相同的数据,后者是不同进程所获取的数据是不同的
Reduce:将不同进程中数据经过某个映射函数映射后将结果存放在一个进程中
AllReduce:是在Reduce的基础上,将最后结果也分发给其它进程。
Gather:是将不同进程中的数据合并在一起
下面来看Ring-AllReduce过程。设N块GPU(GPU0,GPU1,……),每个GPU存放相同的数据量k,将每个GPU存储的数据顺序切分为N块(Chunk0,Chunk1,……),每块的数据量是k/N.将N块GPU收尾相连构成一个逻辑环。每个GPU都有一个左右邻居。Ring-AllReduce的数据流转图如下所示:
第一列:表示每次迭代前的状态,黑色箭头上表示该次迭代每块GPU将其哪个Chunk进行传递。
第二列:表示迭代后,GPU中数据状态,会从左邻居获取数据
可以看出N块GPU,N-1次迭代后,每个GPU中某一个分块Chunk中存放了所有GPU中对应分块中的全部数据。
针对每条边/箭头,其通信量为\((N-1)\frac{k}{N}\)
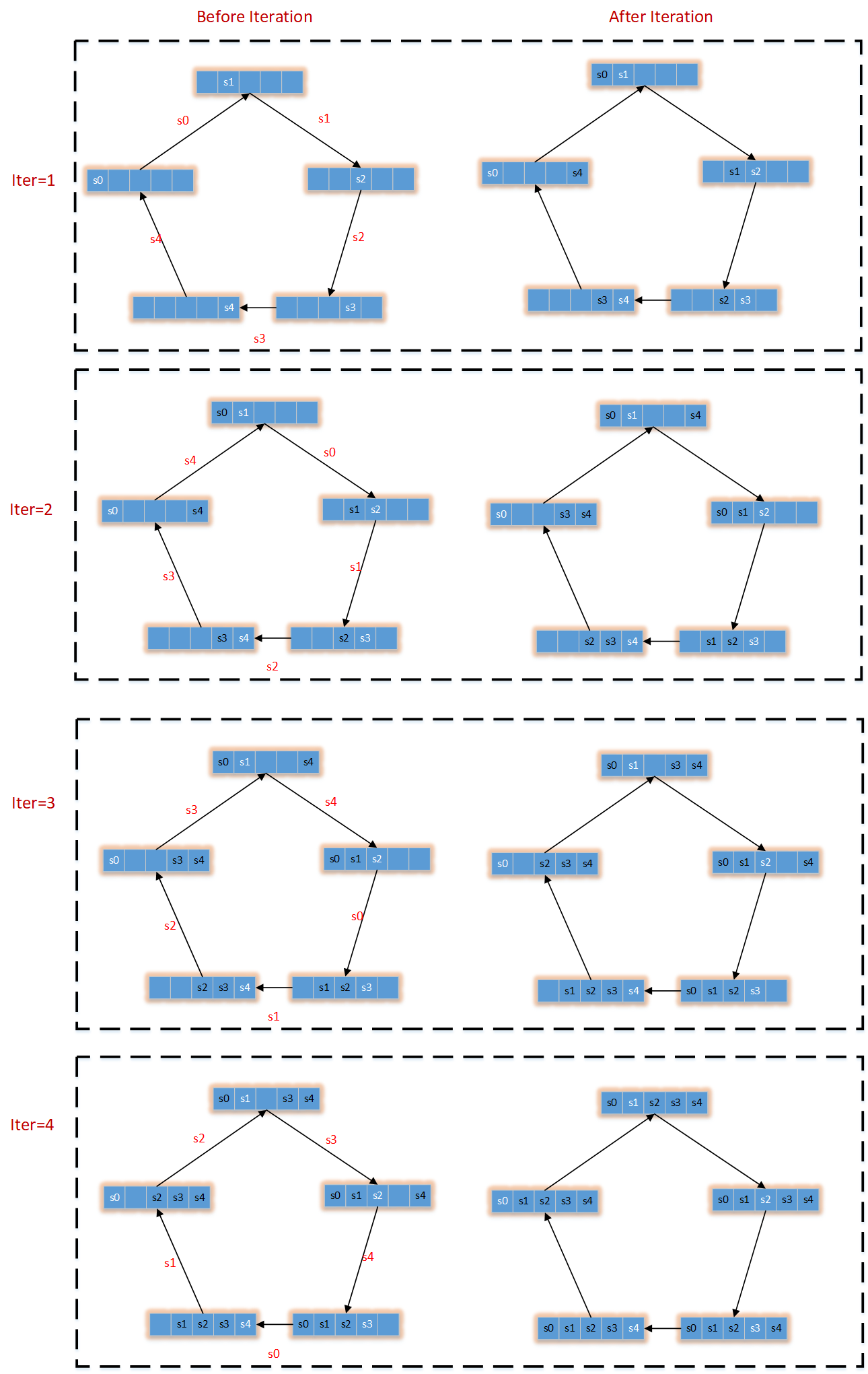
接下来的操作,是将每个GPU中存放有全体GPU某个局部分块的数据,再复制给剩余GPU。同样针对每条边/箭头,其通信量为\((N-1)\frac{k}{N}\)。
这样经过2(N-1)次迭代,就可以实现每个GPU获取其它GPU中的数据,而且每条边的通信量为\(2(N-1)\frac{k}{N}\)
下图是展示如何将GPU分块,以及每次如何将数据传递给相邻的GPU,实现gpu分块中某一块对所有gpu该位置处数据的求和操作。
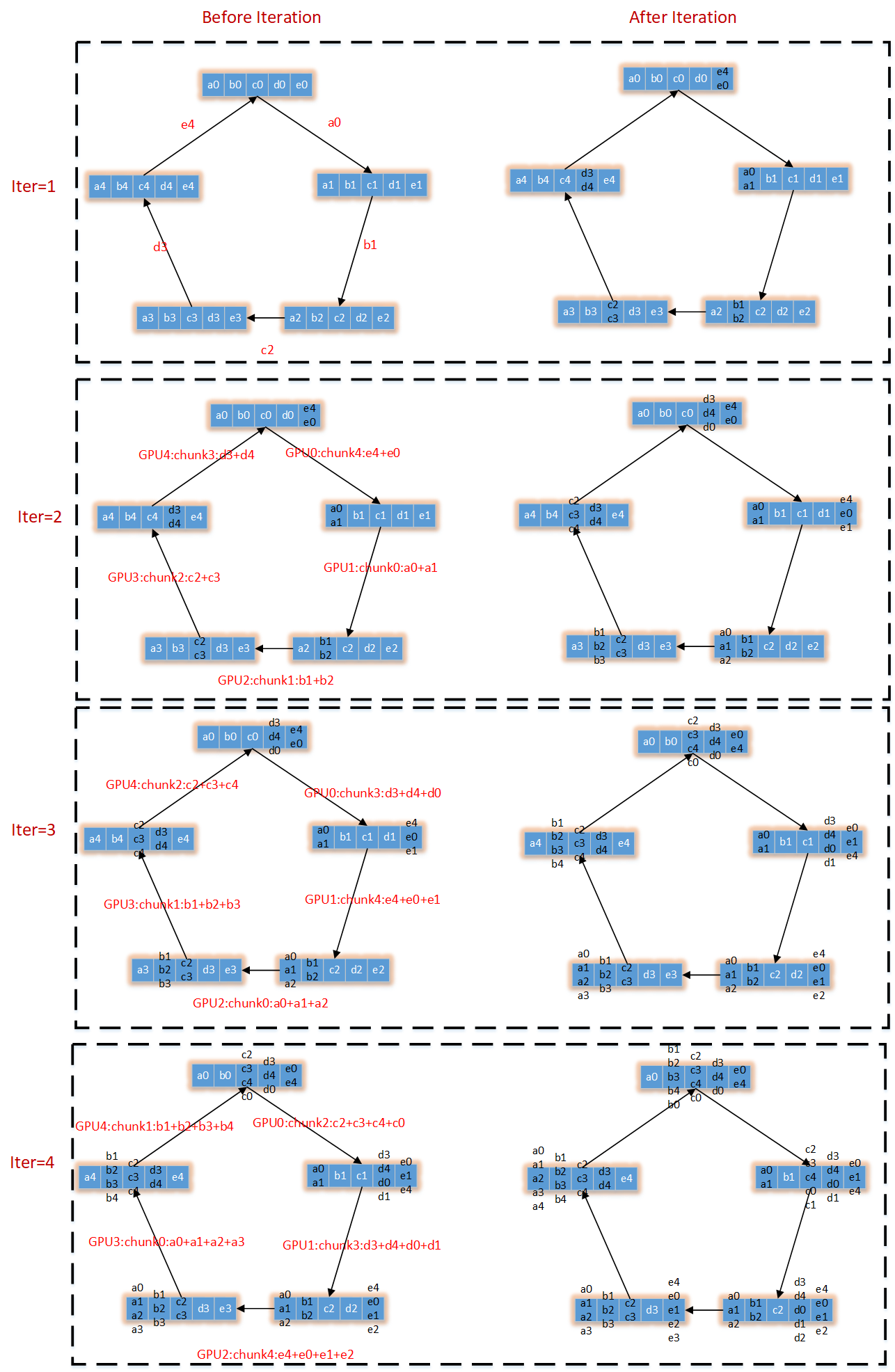
下图展示了,对应每个gpu某块区域求和的结果,如何同步给其它GPU,最终实现每块gpu上存储的是对所有GPU的上数据的求和。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号